自学Python-11 模块
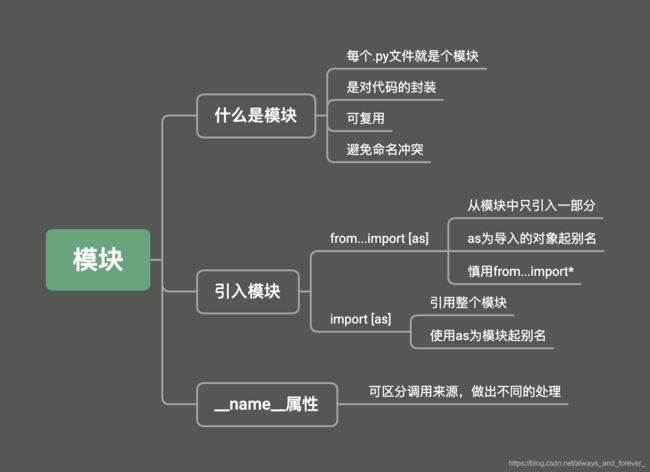
什么是模块
python中每个文件就是一个模块,模块是对程序代码的一种封装,可以方便重用,使用模块可以避免函数名与变量名的冲突。
实例1:
#module1.py中定义了printStr函数
def printStr():
print('I am module1')
#module2.py中也定义了printStr函数
def printStr():
print('I am module2')
#test.py中引用
from module1 import printStr
printStr() #I am module1
from module2 import printStr
printStr() #I am module2
#如果这样写呢?
from module1 import printStr
from module2 import printStr
printStr() #I am module2
printStr() #I am module2
#输出结果是一样的。这说明后导入的会覆盖先导入的。
实例2:
#用这种方式来区分到底使用哪个模块的函数
import module1
import module2
module1.printStr()
module2.printStr()
引入模块
1.from…import[as]
从模块中只导入一部分,例如一个函数、一个变量。as可以给导入的精确对象起个别名。
实例1:
#刚才上面的一个例子,两个模块中都有个名字叫printStr的函数,给他们分别区别别名就可以区分开了
from module1 import printStr as p1
from module2 import printStr as p2
p1() #I am module1
p2() #I am module2
2.import [as]
导入整个模块的内容。这种方式必须用 模块名.对象名调用。as可以给模块起个别名。
例如 import module1 as m1,当模块名较长时,用as起个别名就很方便了。
还有一种比较极端的方式:from…import *
这种方式简单粗暴,写起来比较省事,可以直接使用模块中的所有对象而不需要再使用模块名作为前缀。但一般并不推荐这样使用。一方面这样会降低代码的可读性,有时候很难区分自定义函数和从模块中导入的函数;另一方面,这种导入对象的方式将会导致命名空间的混乱。如果多个模块中有同名的对象,只有最后一个导入的模块中的对象是有效的,而之前导入的模块中的同名对象都将无法访问,不利于代码的理解和维护。
__name__属性
如果我们导入的模块除了定义函数之外还中有可以执行代码,那么Python解释器在导入这个模块时就会执行这些代码,事实上我们可能并不希望如此,因此如果我们在模块中编写了执行代码,最好是将这些执行代码放入如下所示的条件中,这样的话除非直接运行该模块,if条件下的这些代码是不会执行的,因为只有直接执行的模块的名字才是"main"。
#module1.py
def printStr():
print('I am module1')
# __name__是Python中一个隐含的变量它代表了模块的名字
# 只有被Python解释器直接执行的模块的名字才是__main__
if __name__ == '__main__':
print('call printStr()')
printStr()
#test.py
import module1
#没有输出东西,因为此时的__name__是module1
我们用python3 module1.py 执行一下看输出什么:
#call printStr()
#I am module1
总结
从现在开始我们可以将Python代码按照下面的格式进行书写,这一点点的改进其实就是在我们理解了函数和作用域的基础上跨出的巨大的一步。
def main():
# Todo: Add your code here
pass
if __name__ == '__main__':
main()
pass语句:空语句,什么都不做。当你没想好代码怎么写,就可以加个pass占位,保持程序完整。