真 离线强化学习《An Optimistic Perspective on Offline Reinforcement Learning》阅读笔记
真 离线强化学习《An Optimistic Perspective on Offline Reinforcement Learning》阅读笔记
文章目录
- 真 离线强化学习《An Optimistic Perspective on Offline Reinforcement Learning》阅读笔记
- 前言:
- 和TD3作者对线
- 咨询作者:同配置,在线vs离线,到底谁更好?
- 强化的分类,不仅是off-policy 和 on-policy
- 参考链接:
- 一. 论文简介
- 1. 作者:
- 2. 期刊杂志:
- 3. 引用数:
- 4. 论文背景,领域
- 离线强化学习(off-line RL)
- 集成DQN(ensemble RL)
- 应用场景
- 5. 一句话介绍论文解决的问题:
- 二. 创新点和贡献:
- 三. 相关领域的概述(related work)
- 1. 离线强化
- Batch-RL
- c. 作者的方案
- 主要的信息流(approach)
- 总结:
前言:
好久没有完整的看一篇paper了,在实验室的效率竟然也不高…
昨天去一个没有手机,没有网的实验室,两个小时就看完了,感觉还是得去一个合适的环境,才能产生合适的动作…
看这篇文章起源还是很有意思的,我在做机器人实验的时候,由于数据采集需要大量时间,因此每次实验的数据都非常宝贵。
我就想着能不能把这些数据都存到本地,等下一次实验开始的时候,加载到buffer中,然后发现效果会比随机初始化,好一些。我就想着,是不是这是一条好的路子,能不能水一篇文章,,,,
然后就发现了一个叫offline-RL的东西。
然后还发现了一个上个月Levien组发了一个离线预训练,在线调优的东西。
大佬们比我更努力,我还能怎么办…
和TD3作者对线
至于这篇文章,感觉就是对线现场,多次cue TD3的作者 Fujimoto,fujimoto大佬在19年的时候,有一篇工作,说离线强化训练的结果,比在线训练的结果要差很多,不建议大家这么做。
而这篇工作就有意思了,他的核心观点是:
离线强化中最强的设置(包括算法和数据),可以比在线强化的基线要好很多
所以离线强化是可以做的
这个逻辑是没问题的,尽管第一眼看上去,给人的感觉就是:
只要我的基线足够低(认真看了一下,其实也不是最低的基线),那么我的算法就是state of art
For instance, offline QR-DQN (Dabney et al., 2018) trained on the DQN replay dataset outperforms the best policy in the DQN replay dataset. This discrepancy is attributed to the differences in offline dataset size and diversity as well as the choice of RL algorithm.
这篇文章的工作,至少表明,离线强化,可以通过调节数据集大小、多样性和不同的算法,就能“调”出离线比在线好的结果,就像标题说的,前景乐观。
咨询作者:同配置,在线vs离线,到底谁更好?
为了满足我的好奇心我还特地发邮件问了一作,同样的设置,同样的算法,同样的数据,离线的都会比在线的差.
Me:
Basically, it can be considered that the online algorithm is better than the offline algorithm with the same settings?
At least in the comparison of powerful REM and DQN(Nature)?
Rishabh:
Yeah, this is likely to be true for most standard algorithms including distributional RL methods too.
不管是powerful的REM,还是基线DQN(Nature).
但是论文里就不用提这个,学到了~
强化的分类,不仅是off-policy 和 on-policy
上面可以再分一次:
| Model-free RL | On-policy | Off-policy |
|---|---|---|
| Online | PPO | DQN, DDPG, TD3, SAC |
| Offline | NAN | Offline-DQN, Offline-REM, Offline-DDPG, Offline-TD3, Offline-SAC |
显而易见,只有off-policy,有buffer的RL算法才有可能离线学习。
参考链接:
好像没有找到中文关于这篇paper的阅读笔记,好在官方写了一个博客,以及介绍文档。
论文链接
离线强化学习的乐观看法-blog
codes
这个项目的工作量,真的是谷歌大脑的传统艺能,动不动就跑一遍雅他利游戏,简直恐怖
一. 论文简介
1. 作者:
Rishabh Agarwal
My long-term goal is to create robust artificial agents that can meaningfully interact with their environments and I am mainly interested in the field of Deep RL. Applying tabula rasa RL on complex real-world problems is extremely challenging and sample inefficient. One research direction I find interesting is to develop better techniques for incorporating prior information into RL algorithms, which could be in the form of imperfect demonstrations, differentiable physics, priors acquired via meta-learning etc. Another obstacle to applying RL algorithms to real-world tasks is the lack of suitable reward functions. I am also fascinated by the research direction of improving off-policy RL. In general, I believe that deep RL can be improved by inheriting ideas from supervised learning.
主要工作偏向于提高强化对数据的利用效率。
2. 期刊杂志:
ICML2020
PMLR2020
大佬果然又是期刊会议两开花。
3. 引用数:
23
4. 论文背景,领域
离线强化学习(off-line RL)
离线强化学习,19年左右,有不少大佬都讨论过,普遍的观点都是:不靠谱,性能不够好。
完全不交互,全靠之前采集的数据集,训练一个RL模型,这玩意儿听起来就不是那么的靠谱。
实际上面临主要几个问题:
- 数据集的多样性必须得保证,然而随机动作和单一策略擦采集到的数据,都会面临数据质量比较差的问题。
- 数据集的分布得尽量一致,由于离线强化没有在线交互,如果离线的数据分布和真实的数据分布不一致,那就直接凉凉。
- 强化算法对离线数据的利用效果要比较好。其中DQN和DDPG(正是前人常用的两个算法,)的利用效果就不是很好,我觉得主要是这两个算法本身就不稳定。
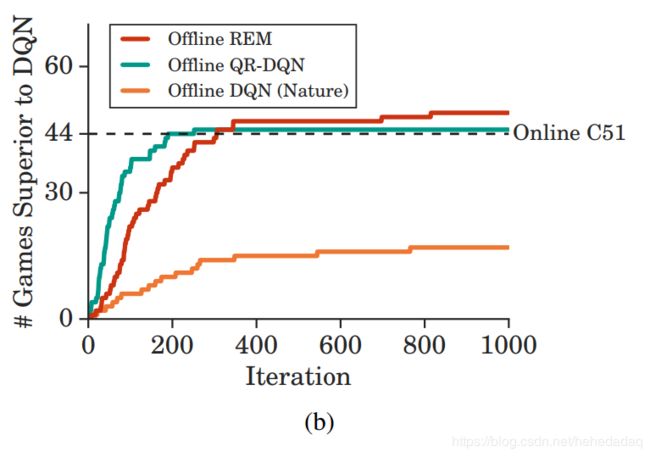
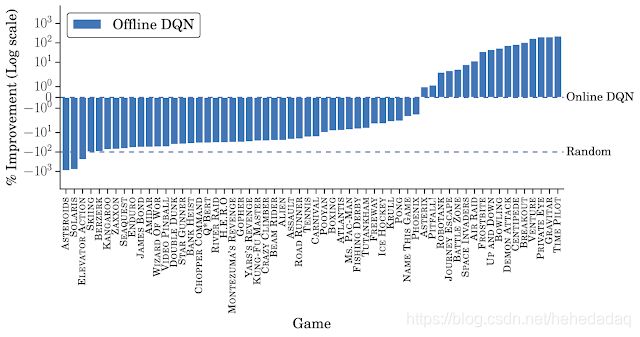
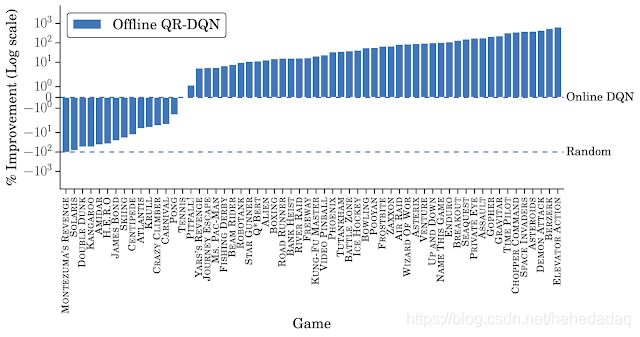
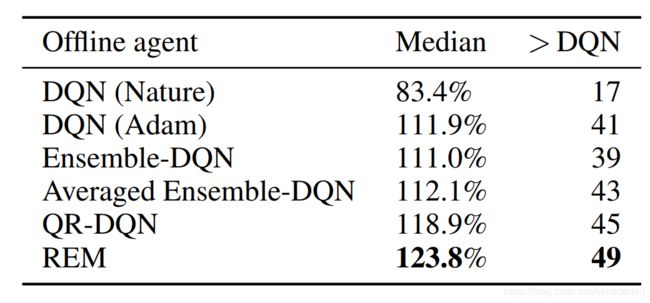
至于结果的话,直接挂两张图就好了:
可见,虽然同样的DQN,离线的打不过在线的,但是我换成了厉害的QRDQN,那么离线的QR-DQN就能打败在线的DQN。
其实已经很不容易了~
集成DQN(ensemble RL)
对于普通的DQN,有两个骚操作,一个是普通多头,最后一个全连接,接五个(文中用的)不同的输出权值初始化(这个权值更新我有点没理解。)这个不配有名字
一个是随机集成混合(REM),借用dropout的思想,对于五个输出,随机赋予权重,咦,这种操作,竟然会提高算法的采样性能,简直太花哨了。
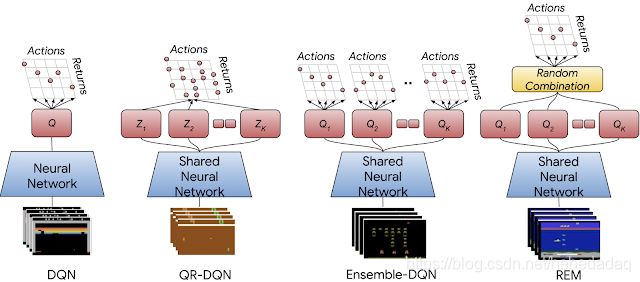
当然为了证明“随机”的重要性,论文里还加了一个平均集成,然后结果果然没有随机的好。
应用场景
非常适合机器人领域。
我就很是喜欢这种离线加速操作,期望接下来有机会做点微小的工作。
5. 一句话介绍论文解决的问题:
离线强化学习,可以通过一系列调整,主要是增加数据集的多样性,算法的稳定性,实现和普通在线强化更好的效果。
二. 创新点和贡献:
- 提出了一个随机集成混合REM的DQN算法,简直惊呆了,我也希望能做这样的工作。
- 做了大量的实验,证明离线训练时,标准RL对连续控制任务无效。但是,作者发现,当对大型多样的离线数据集进行训练时,最近的连续控制代理(例如TD3)的性能与复杂的离线RL相当。再一次惊叹工作量的恐怖。
三. 相关领域的概述(related work)
1. 离线强化
已经说过了
Batch-RL
其定义是RL算法在一个固定的经验池中进行学习。在该问题下比较典型的应用是模仿学习( Imitation learning). 在模仿学习中,给定专家采集的样本作为一个经验池,RL算法从该经验池中学习,而不直接与环境进行交互。
c. 作者的方案
- 提高数据的多样性 — 利用五个不同随机种子的DQN采集。
惊了,深度强化学习的不稳定性竟然恐怖如斯,同样的网络结构,就因为随机种子的原因,就能提高样本的多样性。 - 测试不同的算法对离线数据的利用效率,可以发现REM的利用效果最好。
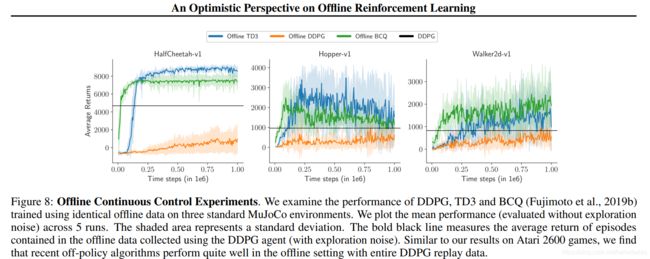
- 同时验证了连续控制,TD3对离线数据的使用效果也不错:
这张图很有意思的,作者的描述是
Offline-TD3 also performs comparably to BCQ
(BCQ的介绍博客,写的非常好!)。
第一张图TD3明显比BCQ好,第23,就不好说了,二者波动性那么大,随机种子的挑选就是一个很微妙的事情。
总之TD3直接整离线数据,效果就已经很不错了!
这个现象我是看到过的。
主要的信息流(approach)
不写了。
总结:
离线强化学习,蛮有意思的,借用强化的模型壳子,利用大量有监督学习的数据,获得比模仿学习、有监督学习,在线强化等,更好更快的性能,还是蛮香的。
我还是得多调研,多看大佬们的工作,多总结,多思考,看看到底有哪些剩下的,并且凭借我能力能做的…
(求求大佬们别学了,跟不上了…)