keras-Yolo-V4-mujoco仿真数据产生-训练-视频流预测 三维方块 全过程
keras-Yolo-V4-mujoco仿真数据产生-训练-视频流预测 三维方块 全过程
文章目录
- keras-Yolo-V4-mujoco仿真数据产生-训练-视频流预测 三维方块 全过程
- 前言
- 整体思路流程图:
- 数据集准备
- bounding box 标签数据的产生
- 图片的渲染:
- 坐标转xml文件脚本array2voc_class.py
- voc2yolo4.py产生train.txt,生成图片绝对路径
- voc_annotation.py生成2007_train.txt
- 准备预训练权重:
- 修改model_data/yolo_anchors.txt文件
- 修改model_data/new_classes.txt文件
- 修改utils文件夹名称为yolo_utils
- 修改train.py文件
- 拿到好的结果:
- predict文件:
- 预测效果:
- 总结:
前言
一直想试试传说中的you just look once.
由于原版的都是基于darknet的,环境配置太过陌生,就没搭建成功过…
尝试毁于环境搭建.jpg
但是最近发现了一个宝藏up,能用最简单的方式给复现,拆解各种经典算法的原理和代码细节。
因此想着再次试试,看看这玩意儿到底好不好使儿…
很明显tf2的环境我搭建失败。可能是cuda的版本不对。但实在是不想再换cuda了。
于是又发现了up竟然同时推出了keras-tf1.13版的yolo4.
简直不要太贴心。
不管在Windows10还是在ubuntu,都能非常方便的搭建这个环境。
OK,环境搭建,第一步完成~
第二步就是数据从哪儿来。
我肯定不想用labelme标个两三天。
首先这玩意儿太费眼,其次,这玩意儿也标的不准…
最重要的是,我就算标好了,那么场景变了,又得重新标。
简直要命。
因此我必须要自动标注!
如何才能自动标注呢?
靠所谓的自动标注脚本肯定是不行的,因为我没找到合适的…
刚好我对mujoco仿真环境比较熟。
试试仿真环境中能不能产生一批数据,用来训练一个模型。
直接在真实场景中测试?
毕竟我在仿真环境中是可以拿到准确,真实,多变的图片和标签。
现在的问题在于,我拿到的数据标签只是普普通通的数组,而需要的标签文件,至少是xml文件。或者json文件,这个要有一个转换脚本。
这个脚本,果然也有大佬写了(当然我还是需要根据我的需要修改。)
那就能利用yolo自带的处理脚本,进行训练了。
一切都是那么的完美,我花了两天多的时间进行仿真环境的仿真调试,两天时间进行debug数据标签的匹配,一天时间进行小数据训练验证,发现效果确实可以,证明数据标签应该没啥问题,模型也没问题。
接下来就是调仿真16万数据,训练一个模型,在真实场景的迁移效果,发现离线数据还好,但真实测试的时候,总有的位置预测失灵–找不到和找错的情况时有发生。
而我这个场景需求,假阳性和假阴性这两种致命的问题都是不可接受的。
目前还没有想明白到底是因为什么,可能存在的原因有:
- 仿真的数据集不够,得加大域随机化(domain randomalization)的力度
- 数据集结构有问题,整个classes_num就是1
- 模型没有训练好,我的锚点没选对,锚点大小,会对预测的精度有影响,如果锚点整体偏小,那么预测的框就会很小。
- 域随机化无法弥补仿真-真实的gap。
- yolo就是无法覆盖所有的情况(划掉,我也不知道)
写这篇博客,主要是感恩回馈,各位大佬的分享,以及我自己也怕我忘了某些操作细节。
类似于做一个总结;
另外,关于仿真的脚本,我就先不放了,因为那个环境模型太复杂,大家要是用ros的话,可能需要自己想办法生成。
整体思路流程图:
数据集准备
原版数据集 – VOC2007:
.
└── VOC2007
├── Annotations
│ ├── image0_0.csv
│ ├── image0_0.xml
│ ├── image0_1.csv
│ ├── image0_1.xml
├── ImageSets
│ └── Main
│ ├── image0_0.jpg
│ ├── image0_1.jpg
└── JPEGImages
图片直接渲染就成了,但是这个xml文件,我们必须要详细的生成~
bounding box 标签数据的产生
由于我们识别的是正方体物块,因此我们需要拿到正方体在图像平面的投影,形成的六边形的像素坐标,然后在这六个中,拿到最大最小坐标值,即bounding box的两个坐标。
这里很多细节,尤其是3D到2D的转换,需要用到相机模型和参数,以及计算最大最小值的时候,xy轴别反了
我到时候看看能不能把脚本放到github上~
图片的渲染:
这个就是涉及到域随机化和仿真的一些细节了,域随机化大家可以看看这篇文章,当然看了没也啥用,这篇文章没给实现例程。
作者给我了一份mujoco_py的例程,大家可以试试,如果用ros的pybullet,可能有大佬实现过域随机化的功能:
https://github.com/openai/mujoco-py/blob/master/examples/disco_fetch.py
这玩意儿的话大家看看我的例程脚本,也许能套用得上?
坐标转xml文件脚本array2voc_class.py
参考脚本:
https://github.com/spytensor/prepare_detection_dataset
csv to coco
csv to voc
labelme to coco
labelme to voc
csv to json
但是他这个需要用csv做一个中介,而我需要的是边产生数组,边保存xml文件。
因此直接上代码吧:
https://github.com/kaixindelele/train-keras-yolo-v4-with-simulation-images/blob/master/robosuite_save_data/array2voc_class.py
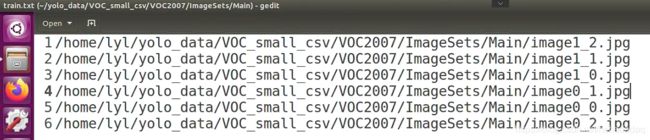
voc2yolo4.py产生train.txt,生成图片绝对路径
代码:
https://github.com/kaixindelele/train-keras-yolo-v4-with-simulation-images/blob/master/voc2yolo4.py
效果如下:
voc_annotation.py生成2007_train.txt
https://github.com/kaixindelele/train-keras-yolo-v4-with-simulation-images/blob/master/voc_annotation.py
主要动的位置:
修改class
classes = [“cube”]
确定image_id
str_image_index = image_id.find(‘image’)
xml_id = image_id[str_image_index:-4]
所有路径都要动
in_file = open(’/home/lyl/yolo_data/VOC_small_csv/VOC%s/Annotations/%s.xml’ % (year, xml_id))
…

其实比上面那个就多了一个label数据。
但是!!!
一定不能图省事儿,用上一节的那个train.txt来训练,那个没有标签数据,啥玩意儿都训练不出来,别问我怎么知道的…
现在有一个简单的文档,将图片和标签联系起来了,直接读取这个TXT文档,就可以训练了。
准备预训练权重:
链接: https://pan.baidu.com/s/1FF79PmRc8BzZk8M_ARdMmw 提取码: dc2j
放到model_data文件夹内
修改model_data/yolo_anchors.txt文件
多少个数不要变,数值可以修改一下。
修改model_data/new_classes.txt文件
修改成你需要的classes。
cube
…
修改utils文件夹名称为yolo_utils
因为很多库都有utils文件夹,如果直接from utils import * 会导入其他的文件,最好修改一下。
修改train.py文件
路径修改好就行了;
其次epoch的设定,慢慢调试吧
拿到好的结果:
predict文件:
修改一下detect部分的函数,也可以将导入模型路径的功能加上。
def __init__(self,
return_class_flag=None,
return_score_flag=None,
font_size=10,
print_flag=True,
get_max_flag=True,
**kwargs):
if kwargs is None:
pass
else:
for key, value in kwargs.items():
self._defaults[key] = value
调用的时候直接这样就行了:
model_path = '/home/lyl/Documents/yolov4-keras-master/nb_logs/ep006-loss12.358-val_loss6.002.h5'
yolo = YOLO(model_path=model_path)
预测效果:
https://www.bilibili.com/video/bv1f54y1m7tv
keras-YoloV4-sim2real测试效果
总结:
由于我的mask-rcnn训练一直失败。所以这个yolo就算效果不错,也没啥用…
性能:20fps
显卡1080
而且在特定场景它也有不好使儿的地方。
深度学习做检测,完全用仿真数据,这玩意儿有点迷惑~
有时间再看看物体种类多点,会不会好些~
或者试试改一下yolo,让它能多回归几个点。
另外用yolo-tiny的话,速度会大大提高,简直恐怖。