lucene4.5源码分析系列:搜索过程
IndexSearcher是搜索的入口,主要提供的api都是关于search的。关于搜索,比较有意思的话题有这么几个:如何计算打分,这个问题已经在空间向量模型一文中讨论过?如何从一个搜索词得到一个Query对象?如何从Query对象到评分器从而计算打分的?几个重要的参数是如何在被组织起来计算的,比如n, filter, sort, collector等。另外,分页是如何进行的?
本文以展示搜索的组织和整个搜索过程为主,其他未讨论的问题将会在接下来陆续讨论。
大致上,前两个search属于简单搜索一类的,接下来两个api是带Collector的,最后三个api是带排序的
public TopDocs search(Query query, int n) throws IOException;
public TopDocs search(Query query, Filter filter, int n) throws IOException;
public void search(Query query, Filter filter, Collector results) throws IOException;
public void search(Query query, Collector results) throws IOException;
public TopFieldDocs search(Query query, Filter filter, int n,
Sort sort) throws IOException;
public TopFieldDocs search(Query query, Filter filter, int n,
Sort sort, boolean doDocScores, boolean doMaxScore) throws IOException;
public TopFieldDocs search(Query query, int n,
Sort sort) throws IOException;
public TopDocs searchAfter(ScoreDoc after, Query query, int n) throws IOException;
public TopDocs searchAfter(ScoreDoc after, Query query, Filter filter, int n) throws IOException;
public TopDocs searchAfter(ScoreDoc after, Query query, Filter filter, int n, Sort sort) throws IOException;
public TopDocs searchAfter(ScoreDoc after, Query query, int n, Sort sort) throws IOException;
public TopDocs searchAfter(ScoreDoc after, Query query, Filter filter, int n, Sort sort,
boolean doDocScores, boolean doMaxScore) throws IOException;关键字的组织
讲到搜索,首先要从理解输入的关键字讲起,也就是QueryParser如何理解输入关键字(当然,也可以自己手动的构造不同的Query),然后如何组织它们。关于关键字的组织,应该要想到如何表达与或非这样的谓词逻辑以便搜索的完整。其次,不同的关键字有不同的种类用以应对不同的场合,比如,模糊匹配,顺序匹配,正则表达式匹配,数字范围匹配等等,熟悉面向对象的同学应当想到将各个种类的匹配方式封装到类里,然后再用谓词逻辑连接起来,从而构成一个完整的查询。没错,lucene也是这样做的。由于构建谓词逻辑的类与构建其他关键字的类继承了相同的接口,操作谓词类就等于操作整个查询链,所以这里是典型的装饰器模式,它的好处是用一个类表示了一整个结构,并且遵循统一的接口形成一个规范。如图,多个关键字搜索的情况下,一个BooleanQuery便可以表示整棵树。事实上,后面的Weight和Scorer也是这样的结构。

下表简单的介绍了一些常见的Query。关于各种不同的Query如何融入进这样一个统一的框架中来,有许多值得讲的地方,这里主要介绍从Query产生后真正查询的过程,暂且略讲Query的产生部分以及各个Query的特点。

整个搜索的横向上主要是以3种类来组织的,即Query,Weight, Scorer。Query负责组织查询对象,Weight负责计算查询对象的权重,Scorer负责计算打分;纵向上依靠BooleanQuery组织成一整颗树结构,其非叶子节点就是BooleanQuery,叶子节点是其他Query,形成Query后,Weight对象的组织就依靠Query树递归一步一步构建起来的,Scorer也是类似的。

搜索流程
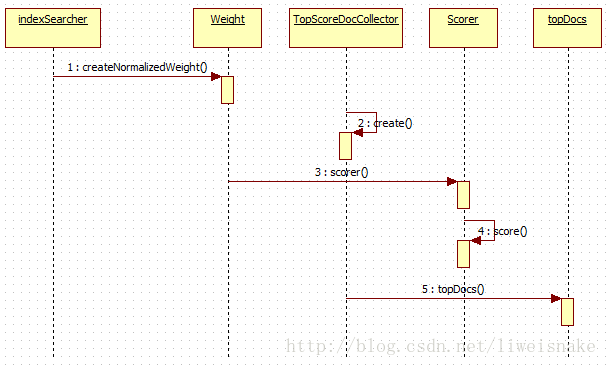
明白了上面这个纲之后再来看search这个过程,就比较容易理解了,大致步骤如下:
1. 通过createNormalizedWeight从Query创建Weight,Weight是一个非常重要的对象,通过它来计算查询评分的因子---权重。
2. 通过TopFieldCollector.create生成Collector,Collector的主要作用是用来搜集原始的评分结果,在结果的基础上可以进行排序,过滤等操作。
3. 从weight中生成Scorer,Scorer的目的是用于计算评分并生成结果
4. 调用Scorer的score方法计算评分结果并用collector搜集文档结果集
5. 从collector的结果中得到topDocs
以下是这个过程一个大致的顺序图。
接下来我们一步一步来看每个步骤。
在实际创建Weight之前,可以指定Filter来过滤不想搜索的内容,我们可以了解下lucene是如何实现这个filter的。
lucene中通过一个FilteredQuery包装原来的Query来完成这件事情,这里的Filte好像一道门禁,使得搜索能够从索引中获得能够通过门禁的文档ID,下面的MultiTermScorer重写ConstantScorerQuery时也是使用了Filter, Filter中有个重要的方法getDocIdSet,这个方法过滤对应的文档,然后将结果集返回。在这里可以根据需要选择不同的filter,或者自己定义filter来满足各种过滤或者安全需求。
public abstract DocIdSet getDocIdSet(AtomicReaderContext context, Bits acceptDocs) throws IOException; 在所有步骤中,首先是创建Weight并计算部分评分,源码如下:
public Weight createNormalizedWeight(Query query) throws IOException {
query = rewrite(query);
Weight weight = query.createWeight(this);
float v = weight.getValueForNormalization();
float norm = getSimilarity().queryNorm(v);
if (Float.isInfinite(norm) || Float.isNaN(norm)) {
norm = 1.0f;
}
weight.normalize(norm, 1.0f);
return weight;
}创建weight的过程分为这样几步
1. 重写Query树。重写的主要目的是将整棵树上一些需要改变搜索关键词的地方重新改变。比如,整个索引建立时有这样几个term,"算法","算术",在搜索"算*"时QueryParser将其解释为PrefixQuery,在重写这步便会搜索所有前缀为"算"的term,并用ConstantScoreQuery替换掉原来的PrefixQuery,在ConstantScorer中会将"算*"替换为"算法", "算术"两个实际的term,进而转化成求解一般term评分,这是典型的将复杂问题转换成已知问题求解的思想。
2. 根据Query树创建Weight树,这个创建过程是一个递归的过程。调用顶层query.createWeight,就会将整棵Weight树构建起来。
3. 计算ValueForNormalization
4. 根据ValueForNormalization计算queryNorm
5. 计算公共部分打分公式(3,4,5参见打分公式一文),之所以这里会计算一部分打分公式,因为这部分是每个文档计算时共用的。
其次通过TopScoreDocCollector.create创建Collector,查询文档数n会被传入到collector,并且在每次新加入一个文档时验证是否已经达到上限n。
接下来从Weight中生成Scorer,这部分其实类似从Query创建Weight。值得一提的地方有3个,BooleanScorer2, MultiTermScorer, TermScorer。
TermWeight中是如何得到TermScorer的呢?getTermsEnum会得到TermsEnum,再由termsEnum得到DocsEnum,这两个都是比较重要的对象,DocsEnum中的nextDoc可以遍历命中的文档
public Scorer scorer(AtomicReaderContext context, boolean scoreDocsInOrder,
boolean topScorer, Bits acceptDocs) throws IOException {
assert termStates.topReaderContext == ReaderUtil.getTopLevelContext(context) : "The top-reader used to create Weight (" + termStates.topReaderContext + ") is not the same as the current reader's top-reader (" + ReaderUtil.getTopLevelContext(context);
final TermsEnum termsEnum = getTermsEnum(context);
if (termsEnum == null) {
return null;
}
DocsEnum docs = termsEnum.docs(acceptDocs, null);
assert docs != null;
return new TermScorer(this, docs, similarity.simScorer(stats, context));
}在BooleanScorer2中,将Scorer的组织分成了3类,即requiredScorers,optionalScorers, prohibitedScorers,其实就分别代表了与或非。
在MultiTermScorer及其子类中,之前的rewrite方法会将query重新封装,可以看到,比较重要的是,用了一个ConstantScoreQuery,对应的Weight是ConstantWeight,对应的Scorer是ConstantScorer
Query result = new ConstantScoreQuery(new MultiTermQueryWrapperFilter(query)); 随后调用scorer中的score方法, 该方法遍历所有结果文档,并将目标文档保存在一个优先队列中,该优先队列负责排序。这个过程见下面的代码
public void score(Collector collector) throws IOException {
assert docID() == -1; // not started
collector.setScorer(this);
int doc;
while ((doc = nextDoc()) != NO_MORE_DOCS) {
collector.collect(doc);
}
}该优先队列是一个比较重要的结构,之所以说它重要,因为一方面,查询文档数会作为优先队列的大小;另一方面,排序的也是通过优先队列完成的。
关于比较的流程,可以看到,调用collect方法之后,紧接着就是调用优先队列的updateTop及downHeap,downHeap就是真正调整队列位置的地方,但是,它的判断依据是lessThan来的,而lessThan正是利用类似Comparator的比较器来灵活的实现优先度的排序。
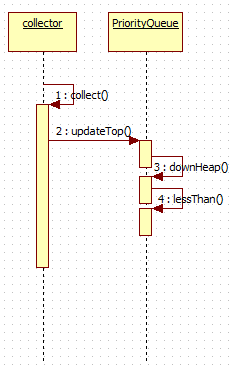
我们来看一个MultiComparatorsFieldValueHitQueue中的lessThan方法,如果有多个field需要比较,它会按照field的顺序循环,分别比较这堆field,一旦判断两者分数不一样就返回比较结果,否则,就要按照顺序找下一个field比较。
protected boolean lessThan(final Entry hitA, final Entry hitB) {
assert hitA != hitB;
assert hitA.slot != hitB.slot;
int numComparators = comparators.length;
for (int i = 0; i < numComparators; ++i) {
final int c = reverseMul[i] * comparators[i].compare(hitA.slot, hitB.slot);
if (c != 0) {
// Short circuit
return c > 0;
}
}
// avoid random sort order that could lead to duplicates (bug #31241):
return hitA.doc > hitB.doc;
}优先队列实现并不难,但是它灵活的实现了许多不同field的比较,因而很值得我们借鉴。
比较特殊的地方是searchAfter,他用到了PagingFieldCollector,因此它在插入优先队列之前还会先过滤掉afterDoc文档之前的所有文档,从而达到分页的效果。
scorer最后会调用到similarity中的设置来进行实际的打分,similarity实现了一个简单的策略模式,通过不同的策略选取,可以实现不同的评分算法。
最后从collector中得到TopDocs,这一步仅仅是将之前的搜索结果整理成TopDocs的形式。
评分,排序,分页,过滤的顺序