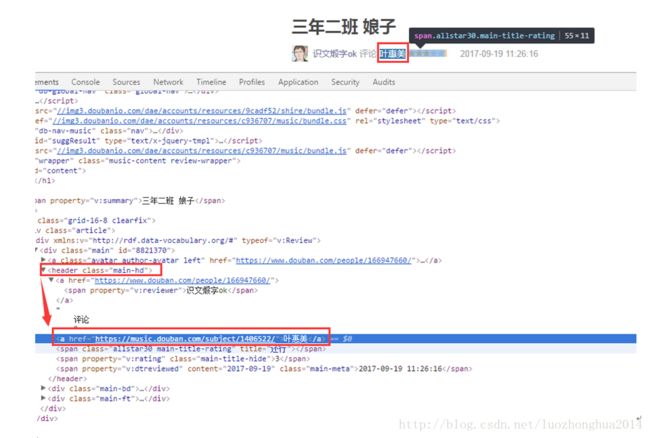
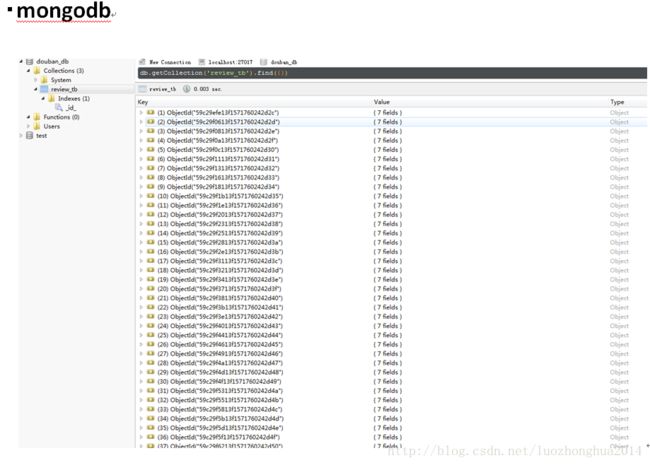
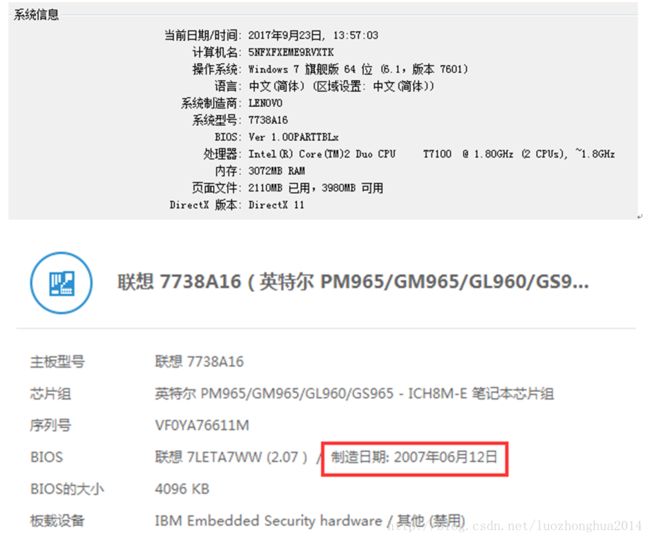
- 高防IP与高防CDN有哪些区别呢?
肖家山子龙
为了避免因为攻击导致的服务器瘫痪,运营商们通常会选择具备高防御的服务器来进行运营。如果是在运营过程中遭遇了攻击,不想去更换服务器的话。这个时候,就可以采用添加高防IP或者高防CDN的形式去防御了。那么在使用上,高防IP与高防CDN有哪些区别呢?区别一:应用场景的不同高防IP与高防CDN都是具备防御攻击特性的两种产品。但是在应用上,两者应用的范围是有区别的,高防IP主要是应用在游戏上居多。而高防CD
- 一路有你的美好Day158
果果儿guoguo132328
我的赞美日记:1.赞美自己手下留情留下了一个未退出的宝藏群,获取了资源,节约了时间成本。2.赞美自己顺风车送了4位同事,接了公公下班。3.赞美自己面对突如其来的撂挑子,迎难而上,调动一切资源自己干。4.赞美自己陪久哥在户外玩了一个小时,看着他撒欢儿的与同学玩,终于认证转学是值得的。5.赞美自己听了宝琪老师的创业力课程,听了阿离的分享,践行莺歌老师的9点站。6.赞美自己给妹妹打气,分享能落地的干货,
- 员村美食(二)
fun麦兜
梁记猪红汤,在员村菜市场往上走,昌乐园小区入口处。一看菜单就可以看出,价格非常亲民,基本都是10元以下。图一是牛筋丸米粉,四颗牛肉丸,劲道有嚼劲,与潮汕牛肉丸无异。这个份量去到其他地方,至少10以上了。猪红汤也很好吃,4块钱就有一碗了。这家店开在小区内,平常顾客很多,大都是附近居民。图片发自App图片发自App图片发自App图片发自App
- AI时代的弯道超车之第十七章:黄仁勋:坚持一件事,哪怕坐足冷板凳
Hebron_Deb
AI时代-弯道超车-逆袭人生人工智能
在这个AI重塑世界的时代,你还在原地观望吗?是时候弯道超车,抢占先机了!李尚龙倾力打造——《AI时代的弯道超车:用人工智能逆袭人生》专栏,带你系统掌握AI知识,从入门到实战,全方位提升认知与竞争力!内容亮点:AI基础+核心技术讲解职场赋能+创业路径揭秘打破信息差+预测行业未来第十七章:黄仁勋:坚持一件事,哪怕坐足冷板凳我们终于来到了第十七章,也是这本人物传记中该领域的最后一章。前面我们讲到了李飞飞
- Leetcode 523. Continuous Subarray Sum
SnailTyan
文章作者:Tyan博客:noahsnail.com|CSDN|1.DescriptionContinuousSubarraySum2.Solution解析:Version1,使用前缀和来解决,遍历数组,求前缀和,求前缀和与k的余数,余数在字典中存在时,则意味着当前前缀和减去之前的前缀和等于k的倍数,此时计算两个前缀和的长度差,如果大于等于2,则返回True,如果余数不存在,则将余数保存在字典中并记
- 化妆品牌排行榜前十名有哪些?这10款化妆品牌,好用口碑又好值得下手
高省APP珊珊
现如今,使用化妆品已不仅仅是对美的一种追求,更是对向往美好生活的一种态度。在正式场合精致的仪容仪表也是对他人的一种尊重,在平日里保养好漂亮的脸蛋也是取悦自己的一种方式。俗话说,化妆可以改变一个人,是一张名片,一个人的气质如何不仅跟体态有关,与精致的脸蛋也有很大关系。若是简单的使用化妆品就能让你保持良好的精气神,那我们是否就可以多了解下化妆品呢。今天,小编将跟大家分享小编心中化妆品排行榜的前十名。高
- AI+Python赋能!长时序植被遥感动态分析全攻略:从物候提取到生态评估
梦想的初衷~
土壤植被遥感人工智能遥感植被土壤
在遥感技术与人工智能深度融合的2025年,AI大模型正重塑长时序植被遥感数据分析范式。从Landsat/Sentinel卫星数据的智能化去云处理,到MODIS植被产品的AI辅助质量控制,以ChatGPT、DeepSeeK为代表的大模型技术已成为提升遥感数据处理效率与精度的核心工具——尤其在长时序植被动态监测、物候期精准提取、时空变异归因分析及生态环境质量评估等领域,展现出传统方法难以企及的技术优势
- 爸爸妈妈不怕,有我们呢,抱抱吧
亚堂家的央初
不知何时,我们的很多传统节日突然回归大众眼前,正如这重阳节,很小就背诵过《九月九日忆山东兄弟》的八零后,那时就已知重阳节了吧,可从未想过把这个节日与自己的父母挂钩,三十年后,慢慢意识到曾经身强体壮、堪称家里顶梁柱的父母已然老去。原来以为时间没那么匆忙,然不知岁月向来如此嚣张,哗哗几笔就让身边的亲人戴上了布满皱纹和老年斑的面具,身形也日渐趋向于佝偻。年近四十,我们就开始害怕老去,害怕面对很多老了可能
- OpenHarmony解读之设备认证:解密流程全揭秘
陈乔布斯
HarmonyOS鸿蒙开发OpenHarmonyharmonyosopenHarmony嵌入式硬件鸿蒙开发respons
往期推文全新看点(文中附带最新·鸿蒙全栈学习笔记)①鸿蒙应用开发与鸿蒙系统开发哪个更有前景?②嵌入式开发适不适合做鸿蒙南向开发?看完这篇你就了解了~③对于大前端开发来说,转鸿蒙开发究竟是福还是祸?④鸿蒙岗位需求突增!移动端、PC端、IoT到底该怎么选?⑤记录一场鸿蒙开发岗位面试经历~⑥持续更新中……一、概述本文重点介绍客户端收到end响应消息之后的处理过程。二、源码分析这一模块的源码位于:/bas
- 踏着荆棘向前
刀尖上舞蹈
踏着荆棘向前脚下布满了荆棘回转么只能是没有意义的再次折魔与伤害停顿么更是一种浪费光阴的消耗将命运交给别人来振救是一种愚蠢唯有前进是的,前进哪怕脚下已满是鲜血也要用带着血的步伐坚持向前向前唯有向前才能看到希望才能实现自己的梦想和向往
- 飞算JavaAI
一、产品简介飞算JavaAI是专为Java开发者打造的智能开发助手,深度适配Java技术栈。通过大语言模型(LLM)实现自然语言到代码的转换,覆盖需求分析、接口设计、表结构设计、业务逻辑生成、代码生成与合并等全流程开发环节。其核心优势在于:全流程自动化:从需求输入到完整工程代码生成,单日可完成传统数周的开发任务。代码质量保障:生成的代码符合阿里巴巴Java开发规范,支持静态代码分析工具自动检测安全
- QT窗口(5)-对话框
Mr_Xuhhh
qtjava数据库系统架构c++开发语言redis
QT窗口(5)-对话框基本概念用户与用户间实现短平快的操作Qt中使用QDialog类表示对话框和QWidget区别不大实际开发中,更多在代码中创建额外的类,让额外的类继承来自QDialog主窗口一般不会作为对话框,主窗口可以生成其他对话框代码如下:voidDialog::on_pushButton_clicked(){QDialog*dialog=newQDialog(this);dialog->
- 为什么会有淘宝内部优惠券,淘宝内部优惠是怎么来的?
氧惠导师
随着淘宝购物变得越来越普遍,身边也不知道从什么时候开始出现了各种优惠券群和优惠券网站,这些优惠券还都有个共同的名字淘宝内部优惠券。➤推荐网购薅羊毛app“氧惠”,一个领隐藏优惠券+现金返利的平台。氧惠只提供领券返利链接,下单全程都在淘宝、京东、拼多多等原平台,更支持抖音、快手电商、外卖红包返利等。(应用市场搜“氧惠”下载,邀请码:521521,全网优惠上氧惠!)➤由于信息差的关系,很多剁手党都不曾
- Vue4进阶指南:从零到项目实战(上)
本书全卷Vue4进阶指南:从零到项目实战(上)Vue4进阶指南:从零到项目实战(中)Vue4进阶指南:从零到项目实战(下)目录前言:开启Vue的优雅之旅致读者:Vue的魅力与本书愿景Vue演进哲学:从Vue2到Vue4的蜕变之路环境准备:现代化开发栈配置第一部分:筑基篇-初识Vue的优雅世界第1章:Hello,Vue!1.1Vue核心思想:渐进式框架、声明式渲染、组件化1.2快速上手:CDN引入与
- 由谷爱凌谈起做更好的自己(班会课)
君子寡言
冬奥会在昨天已经落下了帷幕,开幕式里的“一个都不能少”和闭幕式里的“折柳惜情”,来时迎客松,走时惜别柳,这是中国式浪漫,其实是中华文化的自信和认同,让中国可以平视世界,也是每一个国人的骄傲和自豪,何其有幸,生与华夏。这17天,176名中国冬奥健儿,用热爱、坚持和努力,诠释“更快、更高、更强、更团结”的奥林匹克精神。本届冬奥会中国体育代表团共收获9金、4银、2铜,位列奖牌榜第三,金牌数和奖牌数均创历
- Python你不知道的二三事(Python基础知识)
日暮凡尘
python开发语言
在上一篇中,我们介绍了Python解释器与编辑器的安装与使用,本次我们这是在进行Python程序的编译。我会根据我个人的学习进度进行更新,如有遗漏或错误,欢迎指正。变量与常量变量创建一个新的py文件,我们就可以开始编程了。关于变量,就是一些我们自定义的值,如a=10num=100其中a,num就是我所定义的变量,变量的命名较为自由,但也有一些规则需要遵守:1.变量由数字、字母、下划线(_)组成。n
- SQLite可视化管理工具汇总
班力勤
程序员sqlitejvm数据库
截至2012/9/14最新版本SQLiteSpy1.9.1–28Jul2011单文件,界面设计紧凑,较稳定,功能较少,创建表与添加数据均需sql语句,快捷键教方便,作为数据浏览和修改工具极佳,视图编码为utf-8,对gbk2312显示乱码。能满足一般的应用,但没有导出数据表功能,同时只能打开一个数据库文件不支持二进制字段编辑2、SQLiteStudio(推荐)开源免费单文件http://sqlit
- 三步解锁.NET Conf Student Zone:免费资源+实战项目全攻略!学生党必看!
关注墨瑾轩,带你探索编程的奥秘!超萌技术攻略,轻松晋级编程高手技术宝库已备好,就等你来挖掘订阅墨瑾轩,智趣学习不孤单即刻启航,编程之旅更有趣.NETConfStudentZone三步称王第一步:注册与资源获取——“领取你的魔法钥匙”目标:用StudentZone的免费资源,告别“资源散落”困境。步骤1:注册账号(1分钟搞定!)//模拟注册流程(伪代码,实际需访问官网)stringemail="yo
- 全栈Todo应用实战:从零到一的本地部署与深度解析
全栈Todo应用实战:从零到一的本地部署与深度解析前言在现代Web开发中,全栈应用已成为主流。本文将以一个经典的Todo(待办事项)应用为例,详细记录从项目下载、环境配置、后端启动、数据库交互到前端运行的完整流程。我们将深入探讨在此过程中遇到的一个典型问题——CORS与API请求失败,并提供从“快速修复”到“最佳实践”的解决方案。这不仅是一份操作指南,更是一次宝贵的实战经验总结。你将从本博客中学到
- 第三章 拉文尼病毒
十點差三分Pixar
“震惊!两男子山中烤蝙蝠吃,事后口吐白沫昏迷不醒!”“惊呆!仅在蝙蝠身上存在的拉文尼病毒竟在人体中发现!”“可怕!因贪恋野味品尝蝙蝠,两男子感染拉文尼病毒!”“深度揭秘!拉文尼病毒与蝙蝠几千年以来的共生关系!”“你知道吗?拉文尼病毒已出现人传人现象!”“又出现了!全国各地部分人群感染拉文尼病毒!”最近这些日子,全国各大媒体一直在互联网上大肆播报关于拉文尼病毒的新闻和文章,掀起了一阵又一阵社会热潮。
- 飞算JavaAI:Java开发者的智能革命,从代码生成到架构重塑
目录一、Java开发困局:效率与质量的双重挑战二、技术架构解析:三层智能引擎驱动开发革命1.智能语义理解层2.代码智能生成层3.运行时智能优化层三、核心功能矩阵:从需求到部署的全流程覆盖1.智能需求分析2.自动化软件设计3.工程化代码输出4.智能重构引擎四、实战场景解析:从初创项目到老系统改造场景1:初创项目快速验证场景2:老系统迭代升级场景3:高并发系统优化五、开发者价值重构:从代码工人到系统设
- 飞算 JavaAI 深度体验:开启 Java 开发智能化新纪元
♡喜欢做梦
飞算JavaAI炫技赛Java开发
个人主页:♡喜欢做梦欢迎点赞➕关注❤️收藏评论目录一、引言二、飞算JavaAI初印象与功能概览(一)初识(二)核心功能模块概览三、智能代码生成功能深度体验(一)基础场景测试(二)复杂业务逻辑场景(三)代码生成功能总结四、代码优化建议功能测评(一)测试用例准备(二)优化建议(三)进一步复杂代码测试(四)代码优化功能总结五、故障诊断与修复功能实践(一)模拟常见Java故障场景一、引言在当今软件开发领域
- pytest-bdd 行为驱动自动化测试
东汉末年出bug
pytestpythonpytest-bdd
引言pytest-bdd是一个专为Python设计的行为驱动开发(BDD)测试框架,它允许开发人员使用自然语言(如Gherkin)来编写测试用例,从而使测试用例更易于理解和维护。安装通过pip安装pipinstallpytest-bdd介绍特性文件(FeatureFile):定义了要测试的系统功能。通常以.feature为扩展名,并使用Gherkin语言编写。特性文件包含特性名称、描述以及一个或多
- UI 组件 | Button
测试开发小白变怪兽
最近在与其他自学CocosCreator的小伙伴们交流过程中,发现许多小伙伴对基础组件的应用并不是特别了解,自己在编写游戏的过程中也经常对某个属性或者方法的用法所困扰,而网上也没有比较清晰的用法讲解,所以准备对常用的UI组件常用用法进行一个总结,方便自己和其他小伙伴们查看,下面正文开始(注:属性介绍部分大部分内容我会取自官方文档)。Button(按钮)组件Button组件可以响应用户的点击操作,当
- LLM - 通过案例轻松理解MCP、Tool Calling、Agent
小小工匠
【LLM大模型】MCPFunctionCallAgentToolCalling
文章目录一、MCP是什么?二、MCP解决了哪些痛点?三、什么是ToolCalling?四、对比案例一:ToolCallingvsMCP五、对比案例二:AgentvsAgent+MCP六:使用场景理解Agent→ToolCalling→MCP场景一:智能助手帮你整理工作安排(重构版)Agent的理解与规划ToolCalling的执行流程MCP的幕后支撑场景二:智能电商客服处理订单异常Agent的理解
- 拼多多纸巾群赚钱秘诀:简单步骤,丰厚收益等你来
氧惠好项目
拼多多是一个非常受欢迎的电商平台,它提供了各种类型的商品。最近,拼多多上的纸巾群非常火热,吸引了很多人的关注。本文将介绍在拼多多从事纸巾群的步骤和教程,帮助您轻松获得几百元收益。来,我们先上干货,看完可以少走很多弯路大家好,我是破局。经过对数十个拼多多纸巾群进行研究,我发现了一些拼多多纸巾群的奥秘,今天就和大家一起分享下。很多人都希望通过撸纸项目赚到自己的第一桶金,我今天可以很直接告诉你,只要你坚
- Linux系统磁盘挂载操作及原理详解
前言:在Linux系统的日常运维与管理中,磁盘存储的配置是一项基础且关键的工作。无论是新增一块物理硬盘、扩展云服务器的云盘,还是处理分区扩容,最终都绕不开“挂载”这一核心操作——只有将磁盘分区正确挂载到系统目录树中,其存储空间才能被有效利用。然而,挂载并非简单的“连接”操作,它涉及分区识别、文件系统格式化、挂载点设置、开机自动挂载配置等多个环节,每个步骤都有其特定的逻辑和注意事项。例如,不同文件系
- 读书丨《我们仨》观后感
一棵两棵三棵树_8622
那些相濡以沫的爱情“从今往后,咱们只有死别,再无生离。”——钱钟书“人间不会有单纯的快乐,快乐总夹杂着烦恼和忧虑,人间也没有永远。”“我们这个家,很朴素;我们三个人,很单纯。我们与世无求,与人无争,只求相聚在一起,相守在一起,各自做力所能及的事。碰到困难,我们一同承担,困难就不复困难;我们相伴相助,不论什么苦涩艰辛的事,都能变得甜润。我们稍有一点快乐,也会变得非常快乐。”这是本书的经典句子。相比平
- 2024 前端技术指南:从趋势到实战,构建你的知识地图
王旭晨
前端
一、2024前端领域的“破局者”与“新势力”2024年的前端圈依然热闹非凡,技术迭代与行业焦虑并存。React19带来的useActionState与服务端渲染升级,Vite6的多线程编译挑战Webpack的地位,Bun和Deno对Node.js发起的性能冲击,都在重塑开发者的选择。而尤雨溪创立VoidZero融资460万美金,更是为开源商业化注入了一剂强心针。尽管“前端已死”的论调此起彼伏,但技
- 使用Spire.Doc.Free在Python中为Word文档添加批注
Ven%
pythonpythonword批注
文章目录技术背景环境准备完整实现代码功能说明:注意事项:总结在文档协作和审阅过程中,批注是极其重要的功能。本文将详细介绍如何使用Python的Spire.Doc.Free库为Word文档添加批注,并提供一个完整的解决方案。技术背景Spire.Doc.Free是一个功能强大且免费的Python库,用于处理Word文档。虽然免费版本有一些限制(如文档处理页数限制等),但它提供了丰富的API用于文档操作
- Java开发中,spring mvc 的线程怎么调用?
小麦麦子
springmvc
今天逛知乎,看到最近很多人都在问spring mvc 的线程http://www.maiziedu.com/course/java/ 的启动问题,觉得挺有意思的,那哥们儿问的也听仔细,下面的回答也很详尽,分享出来,希望遇对遇到类似问题的Java开发程序猿有所帮助。
问题:
在用spring mvc架构的网站上,设一线程在虚拟机启动时运行,线程里有一全局
- maven依赖范围
bitcarter
maven
1.test 测试的时候才会依赖,编译和打包不依赖,如junit不被打包
2.compile 只有编译和打包时才会依赖
3.provided 编译和测试的时候依赖,打包不依赖,如:tomcat的一些公用jar包
4.runtime 运行时依赖,编译不依赖
5.默认compile
依赖范围compile是支持传递的,test不支持传递
1.传递的意思是项目A,引用
- Jaxb org.xml.sax.saxparseexception : premature end of file
darrenzhu
xmlprematureJAXB
如果在使用JAXB把xml文件unmarshal成vo(XSD自动生成的vo)时碰到如下错误:
org.xml.sax.saxparseexception : premature end of file
很有可能时你直接读取文件为inputstream,然后将inputstream作为构建unmarshal需要的source参数。InputSource inputSource = new In
- CSS Specificity
周凡杨
html权重Specificitycss
有时候对于页面元素设置了样式,可为什么页面的显示没有匹配上呢? because specificity
CSS 的选择符是有权重的,当不同的选择符的样式设置有冲突时,浏览器会采用权重高的选择符设置的样式。
规则:
HTML标签的权重是1
Class 的权重是10
Id 的权重是100
- java与servlet
g21121
servlet
servlet 搞java web开发的人一定不会陌生,而且大家还会时常用到它。
下面是java官方网站上对servlet的介绍: java官网对于servlet的解释 写道
Java Servlet Technology Overview Servlets are the Java platform technology of choice for extending and enha
- eclipse中安装maven插件
510888780
eclipsemaven
1.首先去官网下载 Maven:
http://www.apache.org/dyn/closer.cgi/maven/binaries/apache-maven-3.2.3-bin.tar.gz
下载完成之后将其解压,
我将解压后的文件夹:apache-maven-3.2.3,
并将它放在 D:\tools目录下,
即 maven 最终的路径是:D:\tools\apache-mave
- jpa@OneToOne关联关系
布衣凌宇
jpa
Nruser里的pruserid关联到Pruser的主键id,实现对一个表的增删改,另一个表的数据随之增删改。
Nruser实体类
//*****************************************************************
@Entity
@Table(name="nruser")
@DynamicInsert @Dynam
- 我的spring学习笔记11-Spring中关于声明式事务的配置
aijuans
spring事务配置
这两天学到事务管理这一块,结合到之前的terasoluna框架,觉得书本上讲的还是简单阿。我就把我从书本上学到的再结合实际的项目以及网上看到的一些内容,对声明式事务管理做个整理吧。我看得Spring in Action第二版中只提到了用TransactionProxyFactoryBean和<tx:advice/>,定义注释驱动这三种,我承认后两种的内容很好,很强大。但是实际的项目当中
- java 动态代理简单实现
antlove
javahandlerproxydynamicservice
dynamicproxy.service.HelloService
package dynamicproxy.service;
public interface HelloService {
public void sayHello();
}
dynamicproxy.service.impl.HelloServiceImpl
package dynamicp
- JDBC连接数据库
百合不是茶
JDBC编程JAVA操作oracle数据库
如果我们要想连接oracle公司的数据库,就要首先下载oralce公司的驱动程序,将这个驱动程序的jar包导入到我们工程中;
JDBC链接数据库的代码和固定写法;
1,加载oracle数据库的驱动;
&nb
- 单例模式中的多线程分析
bijian1013
javathread多线程java多线程
谈到单例模式,我们立马会想到饿汉式和懒汉式加载,所谓饿汉式就是在创建类时就创建好了实例,懒汉式在获取实例时才去创建实例,即延迟加载。
饿汉式:
package com.bijian.study;
public class Singleton {
private Singleton() {
}
// 注意这是private 只供内部调用
private static
- javascript读取和修改原型特别需要注意原型的读写不具有对等性
bijian1013
JavaScriptprototype
对于从原型对象继承而来的成员,其读和写具有内在的不对等性。比如有一个对象A,假设它的原型对象是B,B的原型对象是null。如果我们需要读取A对象的name属性值,那么JS会优先在A中查找,如果找到了name属性那么就返回;如果A中没有name属性,那么就到原型B中查找name,如果找到了就返回;如果原型B中也没有
- 【持久化框架MyBatis3六】MyBatis3集成第三方DataSource
bit1129
dataSource
MyBatis内置了数据源的支持,如:
<environments default="development">
<environment id="development">
<transactionManager type="JDBC" />
<data
- 我程序中用到的urldecode和base64decode,MD5
bitcarter
cMD5base64decodeurldecode
这里是base64decode和urldecode,Md5在附件中。因为我是在后台所以需要解码:
string Base64Decode(const char* Data,int DataByte,int& OutByte)
{
//解码表
const char DecodeTable[] =
{
0, 0, 0, 0, 0, 0
- 腾讯资深运维专家周小军:QQ与微信架构的惊天秘密
ronin47
社交领域一直是互联网创业的大热门,从PC到移动端,从OICQ、MSN到QQ。到了移动互联网时代,社交领域应用开始彻底爆发,直奔黄金期。腾讯在过去几年里,社交平台更是火到爆,QQ和微信坐拥几亿的粉丝,QQ空间和朋友圈各种刷屏,写心得,晒照片,秀视频,那么谁来为企鹅保驾护航呢?支撑QQ和微信海量数据背后的架构又有哪些惊天内幕呢?本期大讲堂的内容来自今年2月份ChinaUnix对腾讯社交网络运营服务中心
- java-69-旋转数组的最小元素。把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。输入一个排好序的数组的一个旋转,输出旋转数组的最小元素
bylijinnan
java
public class MinOfShiftedArray {
/**
* Q69 旋转数组的最小元素
* 把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。输入一个排好序的数组的一个旋转,输出旋转数组的最小元素。
* 例如数组{3, 4, 5, 1, 2}为{1, 2, 3, 4, 5}的一个旋转,该数组的最小值为1。
*/
publ
- 看博客,应该是有方向的
Cb123456
反省看博客
看博客,应该是有方向的:
我现在就复习以前的,在补补以前不会的,现在还不会的,同时完善完善项目,也看看别人的博客.
我刚突然想到的:
1.应该看计算机组成原理,数据结构,一些算法,还有关于android,java的。
2.对于我,也快大四了,看一些职业规划的,以及一些学习的经验,看看别人的工作总结的.
为什么要写
- [开源与商业]做开源项目的人生活上一定要朴素,尽量减少对官方和商业体系的依赖
comsci
开源项目
为什么这样说呢? 因为科学和技术的发展有时候需要一个平缓和长期的积累过程,但是行政和商业体系本身充满各种不稳定性和不确定性,如果你希望长期从事某个科研项目,但是却又必须依赖于某种行政和商业体系,那其中的过程必定充满各种风险。。。
所以,为避免这种不确定性风险,我
- 一个 sql优化 ([精华] 一个查询优化的分析调整全过程!很值得一看 )
cwqcwqmax9
sql
见 http://www.itpub.net/forum.php?mod=viewthread&tid=239011
Web翻页优化实例
提交时间: 2004-6-18 15:37:49 回复 发消息
环境:
Linux ve
- Hibernat and Ibatis
dashuaifu
Hibernateibatis
Hibernate VS iBATIS 简介 Hibernate 是当前最流行的O/R mapping框架,当前版本是3.05。它出身于sf.net,现在已经成为Jboss的一部分了 iBATIS 是另外一种优秀的O/R mapping框架,当前版本是2.0。目前属于apache的一个子项目了。 相对Hibernate“O/R”而言,iBATIS 是一种“Sql Mappi
- 备份MYSQL脚本
dcj3sjt126com
mysql
#!/bin/sh
# this shell to backup mysql
#
[email protected] (QQ:1413161683 DuChengJiu)
_dbDir=/var/lib/mysql/
_today=`date +%w`
_bakDir=/usr/backup/$_today
[ ! -d $_bakDir ] && mkdir -p
- iOS第三方开源库的吐槽和备忘
dcj3sjt126com
ios
转自
ibireme的博客 做iOS开发总会接触到一些第三方库,这里整理一下,做一些吐槽。 目前比较活跃的社区仍旧是Github,除此以外也有一些不错的库散落在Google Code、SourceForge等地方。由于Github社区太过主流,这里主要介绍一下Github里面流行的iOS库。 首先整理了一份
Github上排名靠
- html wlwmanifest.xml
eoems
htmlxml
所谓优化wp_head()就是把从wp_head中移除不需要元素,同时也可以加快速度。
步骤:
加入到function.php
remove_action('wp_head', 'wp_generator');
//wp-generator移除wordpress的版本号,本身blog的版本号没什么意义,但是如果让恶意玩家看到,可能会用官网公布的漏洞攻击blog
remov
- 浅谈Java定时器发展
hacksin
java并发timer定时器
java在jdk1.3中推出了定时器类Timer,而后在jdk1.5后由Dou Lea从新开发出了支持多线程的ScheduleThreadPoolExecutor,从后者的表现来看,可以考虑完全替代Timer了。
Timer与ScheduleThreadPoolExecutor对比:
1.
Timer始于jdk1.3,其原理是利用一个TimerTask数组当作队列
- 移动端页面侧边导航滑入效果
ini
jqueryWebhtml5cssjavascirpt
效果体验:http://hovertree.com/texiao/mobile/2.htm可以使用移动设备浏览器查看效果。效果使用到jquery-2.1.4.min.js,该版本的jQuery库是用于支持HTML5的浏览器上,不再兼容IE8以前的浏览器,现在移动端浏览器一般都支持HTML5,所以使用该jQuery没问题。HTML文件代码:
<!DOCTYPE html>
<h
- AspectJ+Javasist记录日志
kane_xie
aspectjjavasist
在项目中碰到这样一个需求,对一个服务类的每一个方法,在方法开始和结束的时候分别记录一条日志,内容包括方法名,参数名+参数值以及方法执行的时间。
@Override
public String get(String key) {
// long start = System.currentTimeMillis();
// System.out.println("Be
- redis学习笔记
MJC410621
redisNoSQL
1)nosql数据库主要由以下特点:非关系型的、分布式的、开源的、水平可扩展的。
1,处理超大量的数据
2,运行在便宜的PC服务器集群上,
3,击碎了性能瓶颈。
1)对数据高并发读写。
2)对海量数据的高效率存储和访问。
3)对数据的高扩展性和高可用性。
redis支持的类型:
Sring 类型
set name lijie
get name lijie
set na
- 使用redis实现分布式锁
qifeifei
在多节点的系统中,如何实现分布式锁机制,其中用redis来实现是很好的方法之一,我们先来看一下jedis包中,有个类名BinaryJedis,它有个方法如下:
public Long setnx(final byte[] key, final byte[] value) {
checkIsInMulti();
client.setnx(key, value);
ret
- BI并非万能,中层业务管理报表要另辟蹊径
张老师的菜
大数据BI商业智能信息化
BI是商业智能的缩写,是可以帮助企业做出明智的业务经营决策的工具,其数据来源于各个业务系统,如ERP、CRM、SCM、进销存、HER、OA等。
BI系统不同于传统的管理信息系统,他号称是一个整体应用的解决方案,是融入管理思想的强大系统:有着系统整体的设计思想,支持对所有
- 安装rvm后出现rvm not a function 或者ruby -v后提示没安装ruby的问题
wudixiaotie
function
1.在~/.bashrc最后加入
[[ -s "$HOME/.rvm/scripts/rvm" ]] && source "$HOME/.rvm/scripts/rvm"
2.重新启动terminal输入:
rvm use ruby-2.2.1 --default
把当前安装的ruby版本设为默