【今日CV 计算机视觉论文速览】 6 Mar 2019
今日CS.CV计算机视觉论文速览
Wed, 6 Mar 2019
Totally 34 papers

Interesting:
?TableBank,基于图像的文件表格检测,结构识别数据集,利用work和latex的弱监督数据,构建了417K高质量的标记表格图像数据,同时构建基准数据模型。(from 北航和微软亚洲研究院)
表格数据集:

表格检测表格结构识别:


dataset&code&link: https://github.com/doc-analysis/TableBank
相关数据集:
ICDAR 2013 table 比赛数据集(128电子文本)
UNLV table 数据集(427扫描文件)
Marmot数据集(2000页)
DeepFigure Dataset(arxiv & PubMed数据集) , ref paper
?H3D Dataset拥挤城市场景的三维全景多目标检测和跟踪数据集, 来自本田研究院的数据集,包含了多个交通参与者的数据标注,将有利于自动驾驶的开发和研究。包含了160个场景下1M个标注实例和27721帧。数据收集于旧金山、山景城、圣克鲁斯,圣马特奥。

包含时间序列的标记信息:

以及数据收集车:
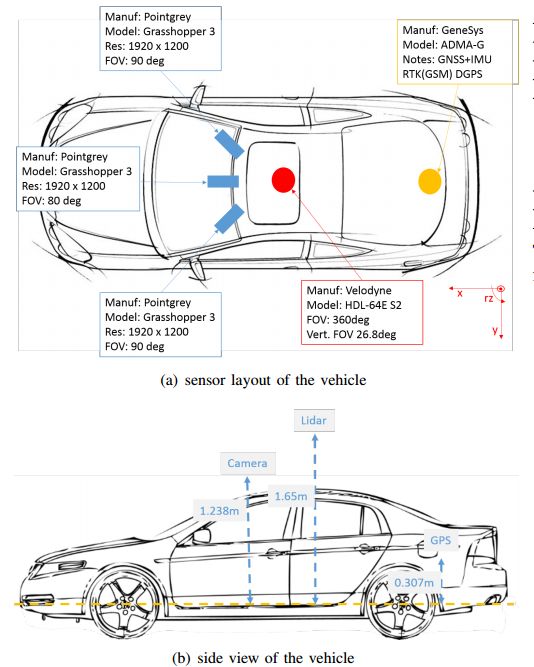
?dataset link
相关数据集:Oxford RobotCar, KITTI FlyingThikng,视差光流和场景流合成数据集
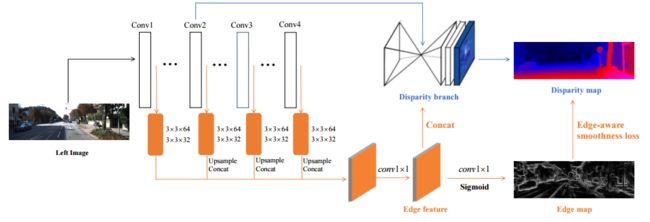
?EdgeStereo同时用于学习立体匹配和边缘数据的网络,为了克服低纹理、小细节和小物体等缺乏几何信息的小物体匹配问题,研究人员提出了多任务处理框架来学习视差图和边缘检测。提出了边缘平滑损失和特征嵌入,设计了残差金字塔模型来实现立体匹配。(from 上交)
网络模型,共享了低层级架构和边缘特征:

文章中的残差金字塔细节,在小尺度上估计视差图并在大尺度上进行修正:

边缘检测分支的结构:
一些结果:

一些相关方法:
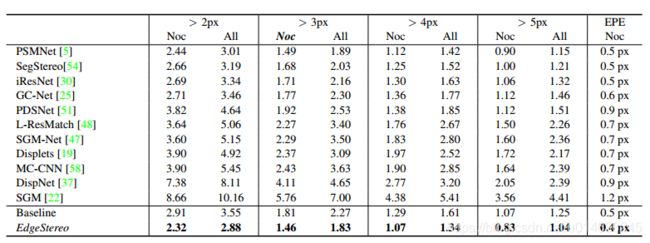
相关数据集:KITTI 2012,2015,FlyingtThings3D
?实时多人点云手部检测方法,与先前使用二维关键点检测并投影到三维的方法不同,这一方法直接对动态三维点云进行处理。为了加速三维处理,首先检测出人群中每个人的bbox,然后对手部进行定位,此外还开发了基于2D的特征的候选及轨迹优化方法(基于最大重叠),并减少了三维体积中人的关键映射为高效的二维问题。(from 美国微软)
限定为人再定位手:
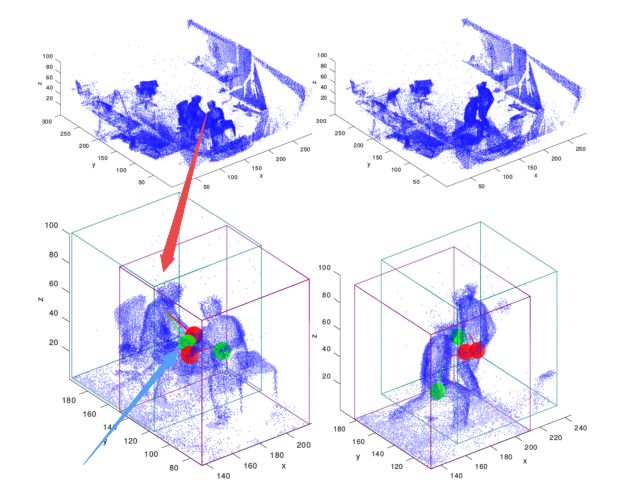
不同的视角检测和置信度累计:
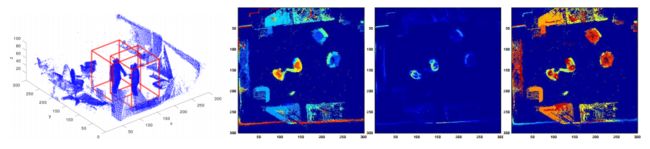
一些相关方法比较:

数据集来自于Kinect-v2收集的 300 m 2 300m^2 300m2 20个物体,一作主页
?基于五型人格模型检测人群中人的文化性格倾向,(from pucrs.br)

?无人机对室内墙布局的学习,并基于这些布局来进行室内定位(from 德国弗莱堡大学)
效果:

模式输入RGB和消失线,输入房间布局边缘:

实验数据集:Fr078-1 (113 mlong), Fr078-2 (179 m long) and Fr080 (108 m long).
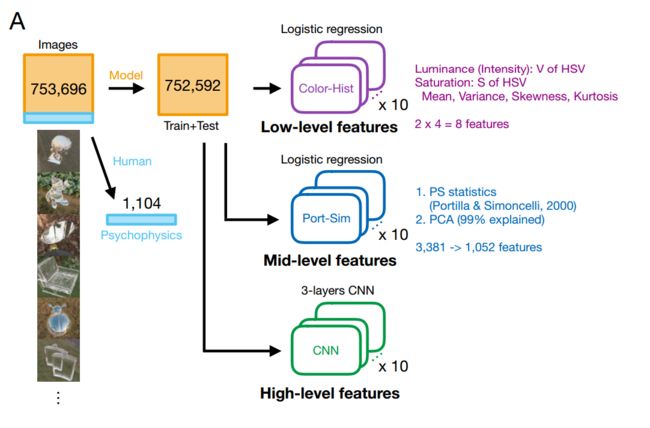
?识别玻璃和镜面,根据图像中的反射行为来测定材质(Toyohashi University of Technology)
?M-VAD Names,为视频数据集进行命名的数据集,Caption。(University of Modena and Reggio Emilia)

数据集:https://github.com/aimagelab/mvad-names-dataset
?无人红外数据集视觉导航,(内华达州立)
[视频](https://www.youtube.com/watch?v=aqZugneeCxc&feature=youtu.be
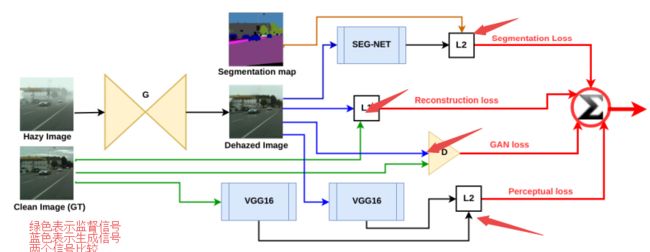
?用于增强图像分割的去雾算法,(from , Universite Laval)这篇文章的逻辑框图十分清晰,值得学习,分割网络损失、中间去雾损失和下面分类损失,再加上中间的判别器GAN损失,一气呵成:
Daily Computer Vision Papers
[1] Title: TableBank: Table Benchmark for Image-based Table Detection and Recognition
Authors:Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou, Zhoujun Li
[2] Title: MS-TCN: Multi-Stage Temporal Convolutional Network for Action Segmentation
Authors:Yazan Abu Farha, Juergen Gall
[3] *Title: O-GAN: Extremely Concise Approach for Auto-Encoding Generative Adversarial Networks
Authors:Jianlin Su
[4] Title: FastReg: Fast Non-Rigid Registration via Accelerated Optimisation on the Manifold of Diffeomorphisms
Authors:Daniel Grzech, Loïc le Folgoc, Mattias P. Heinrich, Bishesh Khanal, Jakub Moll, Julia A. Schnabel, Ben Glocker, Bernhard Kainz
[5] Title: Learning a smooth kernel regularizer for convolutional neural networks
Authors:Reuben Feinman, Brenden M. Lake
[6] *Title: Frustum ConvNet: Sliding Frustums to Aggregate Local Point-Wise Features for Amodal 3D Object Detection
Authors:Zhixin Wang, Kui Jia
[7] Title: Virtual Ground Truth, and Pre-selection of 3D Interest Points for Improved Repeatability Evaluation of 2D Detectors
Authors:Simon R Lang, Martin H Luerssen, David M Powers
[8] Title: HexagDLy - Processing hexagonally sampled data with CNNs in PyTorch
Authors:Constantin Steppa, Tim Lukas Holch
[9] **Title: Leveraging Shape Completion for 3D Siamese Tracking
Authors:Silvio Giancola, Jesus Zarzar, Bernard Ghanem
[10] Title: Hue Modification Localization By Pair Matching
Authors:Quoc-Tin Phan, Michele Vascotto, Giulia Boato
[11] Title: Improve Object Detection by Data Enhancement based on Generative Adversarial Nets
Authors:Wei Jiang, Na Ying
[12] *Title: Deep Learning Based Motion Planning For Autonomous Vehicle Using Spatiotemporal LSTM Network
Authors:Zhengwei Bai, Baigen Cai, Wei Shangguan, Linguo Chai
[13] **Title: EdgeStereo: An Effective Multi-Task Learning Network for Stereo Matching and Edge Detection
Authors:Xiao Song, Xu Zhao, Liangji Fang, Hanwen Hu
[14] Title: Real-time Multiple People Hand Localization in 4D Point Clouds
Authors:Hao Jiang, Quanzeng You
[15] ***Title: Using Big Five Personality Model to Detect Cultural Aspects in Crowds
Authors:Rodolfo Migon Favaretto, Leandro Dihl, Soraia Raupp Musse, Felipe Vilanova, Angelo Brandelli Costa
[16] **Title: Distinguishing mirror from glass: A ‘big data’ approach to material perception
Authors:Hideki Tamura, Konrad E. Prokott, Roland W. Fleming
[17] Title: A DenseNet Based Approach for Multi-Frame In-Loop Filter in HEVC
Authors:Tianyi Li, Mai Xu, Ren Yang, Xiaoming Tao
[18] Title: Defense Against Adversarial Images using Web-Scale Nearest-Neighbor Search
Authors:Abhimanyu Dubey, Laurens van der Maaten, Zeki Yalniz, Yixuan Li, Dhruv Mahajan
[19] Title: Unsupervised Domain-Specific Deblurring via Disentangled Representations
Authors:Boyu Lu, Jun-Cheng Chen, Rama Chellappa
[20] **Title: On measuring the iconicity of a face
Authors:Prithviraj Dhar, Carlos D. Castillo, Rama Chellappa
[21] **Title: The H3D Dataset for Full-Surround 3D Multi-Object Detection and Tracking in Crowded Urban Scenes
Authors:Abhishek Patil, Srikanth Malla, Haiming Gang, Yi-Ting Chen
[22] Title: Unsupervised Rank-Preserving Hashing for Large-Scale Image Retrieval
Authors:Svebor Karaman, Xudong Lin, Xuefeng Hu, Shih-Fu Chang
[23] Title: Selective Sensor Fusion for Neural Visual-Inertial Odometry
Authors:Changhao Chen, Stefano Rosa, Yishu Miao, Chris Xiaoxuan Lu, Wei Wu, Andrew Markham, Niki Trigoni
[24] Title: Learning of Image Dehazing Models for Segmentation Tasks
Authors:Sébastien de Blois, Ihsen Hedhli, Christian Gagné
[25] Title: TKD: Temporal Knowledge Distillation for Active Perception
Authors:Mohammad Farhadi, Yezhou Yang
[26] Title: Fine-grained lesion annotation in CT images with knowledge mined from radiology reports
Authors:Ke Yan, Yifan Peng, Zhiyong Lu, Ronald M. Summers
[27] *Title: M-VAD Names: a Dataset for Video Captioning with Naming
Authors:Stefano Pini, Marcella Cornia, Federico Bolelli, Lorenzo Baraldi, Rita Cucchiara
[28] Title: Statistical Guarantees for the Robustness of Bayesian Neural Networks
Authors:Luca Cardelli, Marta Kwiatkowska, Luca Laurenti, Nicola Paoletti, Andrea Patane, Matthew Wicker
[29] Title: Towards Design Space Exploration and Optimization of Fast Algorithms for Convolutional Neural Networks (CNNs) on FPGAs
Authors:Afzal Ahmad, Muhammad Adeel Pasha
[30] **Title: Robot Localization in Floor Plans Using a Room Layout Edge Extraction Network
Authors:Federico Boniardi, Abhinav Valada, Rohit Mohan, Tim Caselitz, Wolfram Burgard
[31] Title: Vision-Depth Landmarks and Inertial Fusion for Navigation in Degraded Visual Environments
Authors:Shehryar Khattak, Christos Papachristos, Kostas Alexis
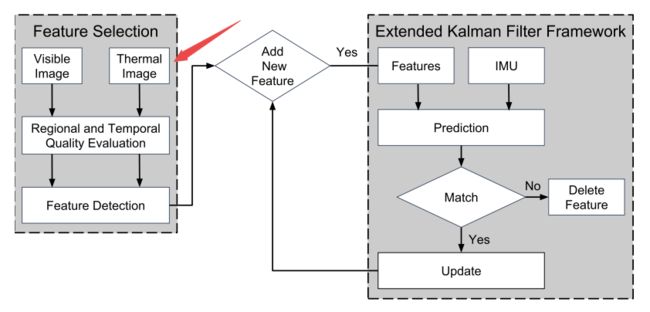
[32] Title: Visual-Thermal Landmarks and Inertial Fusion for Navigation in Degraded Visual Environments
Authors:Shehryar Khattak, Christos Papachristos, Kostas Alexis
[33] Title: The Lottery Ticket Hypothesis at Scale
Authors:Jonathan Frankle, Gintare Karolina Dziugaite, Daniel M. Roy, Michael Carbin
[34] Title: The Regretful Agent: Heuristic-Aided Navigation through Progress Estimation
Authors:Chih-Yao Ma, Zuxuan Wu, Ghassan AlRegib, Caiming Xiong, Zsolt Kira
Papers from arxiv.org
更多精彩请移步主页

pic from pixels.com