实习面试题总结(后端)
面试题目录
- AtomicInteger和AtomicLong怎么理解,区别?LongAdder有了解吗?
- 为什么用线程池?好处?ThreadPoolExecutor了解吗?
- TCP怎么解决粘包拆包问题

AtomicInteger和AtomicLong怎么理解,区别?LongAdder有了解吗?
释:AtomicInteger和AtomicLong是并发包下面的类(java.until.concurrent.atomic),所以AtomicInteger和AtomicLong肯定是在并发环境下使用的。
先看一道面试题:x作为全局变量,使用x++线程安全吗?
public class Test {
private static int x = 0;
private static final Integer THREAD_NUM = 100000;
//设置栅栏是为了防止循环还没结束就执行main线程输出自增的变量,导致误以为线程不安全
private static CountDownLatch countDownLatch = new CountDownLatch(THREAD_NUM);
public static void main(String[] args) throws InterruptedException {
for (int j = 0; j < THREAD_NUM; j++) {
new Thread(() -> {
add();
}).start();
}
countDownLatch.await();
System.out.println("X的值:" + x);
}
public static void add(){
x++;
countDownLatch.countDown();
}
}
输出结果:
X的值:99993
输出的结果有随机性,有可能是10000也有可能小于10000。由此可以看出使用Integer的x。对于线程是不安全的。在多线程环境下会出现错误!
以上的x是全局变量。因为全局变量相当于共享变量。在多线程环境下多个线程访问同一个变量会出现线程的不安全。x++,虽然在高级语言中是一行代码,但是对于计算机而言,所有的操作都是指令。
将x++这一操作转换为指令可以理解为由3个步骤
1. 获取变量的当前值
2. 变量的当前值加1
3. 将新的值赋给变量
假设现在有两个线程A和B同时访问一个变量
当A取到x的值,并加1.还没来得及将加1的值赋给x。B也取到了x的还没加1的值。这时候在A和B对x进行赋值的时候就会出现错误。加了两次结果x的值为1
当然以上的问题可以使用sychronized或者使用Lock显式加锁解决。
当然也可以使用AtomicInteger类更加优雅的解决。因为java.util.concurrent.atomic包下面的类都能够保证原子性。而且最大的好处就是性能。(无锁)
先了解一下AtomicInteger原子类有哪些方法
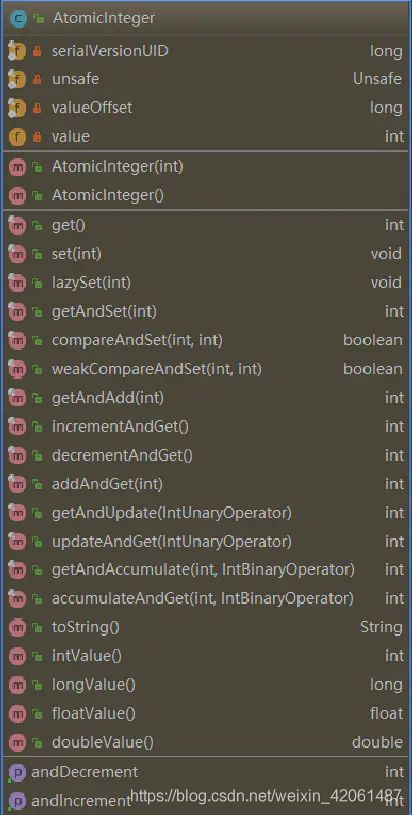
最重要的方法为getAccumulate,accumlateAndGet,lazySet,compareAndSet和CompareAndSet方法
public final int getAndAccumulate(int x, IntBinaryOperator accumulatorFunction) {
int prev, next;
do {
prev = get();
next = accumulatorFunction.applyAsInt(prev, x);
} while (!compareAndSet(prev, next));
return prev;
}
public final int accumulateAndGet(int x,IntBinaryOperator accumulatorFunction) {
int prev, next;
do {
prev = get();
next = accumulatorFunction.applyAsInt(prev, x);
} while (!compareAndSet(prev, next));
return next;
}
public final void lazySet(int newValue) {
unsafe.putOrderedInt(this, valueOffset, newValue);
}
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
public final boolean weakCompareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
getAndAccumulate() 和accumulateAndGet() 第二个参数是通过传入function函数计算,我们可以自定义计算的过程。
public class MethodDemo {
private static AtomicInteger atomic = new AtomicInteger(2);
public static void main(String[] args) {
atomic.getAndAccumulate(10, (s1, s2) -> (s1 + s2) * s2);
System.out.println(atomic.get());//计算结果:120
}
}
lazySet()、compareAndSet()、weakCompareAndSet() 方法都是调用Unsafe对象的方法。
查看Atomic包下所有类的源码,很多的方法都有用到Unsafe对象,而这个对象内部大部分方法都是使用native关键字。Unsafe这个类可以简单的理解为是与操作系统交互的对象。原子类之所以能够保证原子性,无锁情况下保证线程安全就是得益于使用Unsafe对象与操作系统硬件交互,通过计算机硬件保证系统安全。
lazySet()和set()有什么区别呢?
他们都是改变引用类型为AtomicInteger变量的值。但合理使用lazySet()方法可以性能优化!
private volatile int value
引用类型为AtomcInteger变量的值是用volatile关键字修饰,volatile的作用大致可以总结为:
- 提供内存屏障
- 防止重排序
- volatile关键字修饰的变量在写入的时候会强制将cpu写缓冲区刷新到内存;在读取的时候会强制从内存中读取最新的值。
使用set()方法的时候一定会将最新的值设置到value,但使用lazySet()方法改变共享变量的值不一定会被其他线程看到,但是合理的使用lazySet()可以优化程序
举个例子:
public void Demo() {
AtomicInteger atomicInteger = new AtomicInteger(10);
Lock lock = new ReentrantLock();
lock.lock();
try {
// atomicInteger.set(2333);//变量由volatile关键字修饰,会使用到内存屏障,在锁内其实是不必要的
atomicInteger.lazySet(2333);
} finally {
lock.unlock();
}
}
在加锁的环境下一定是线程安全的 lock.lock()方法。里面没必要再使用volatile再次修饰。lazySet()可以避免内存屏障,提高程序的执行效率
AtomicLong 原子类的使用
跟以上的AtomicInter基本操作是差不多的。但是再java中,使用long型和double型以外的基本类型和引用类型的写操作都是原子性操作。
因为在long和double类型都是64为的存储空间。在32位的虚拟机下的写操作可能被分为两个步骤。
先写入低32位,再写入高32位。在多线程环境下可能出现、
A线程执行低32位,B线程执行高32位的操作
因为long和double类型都是64位(8字节)的存储空间。在32位的Java虚拟机下的写操作可能被分为两个步骤操作,先写入低32位,再写入高32位,这样在多线程环境下共享long或者double类型变量,可能出现A线程对变量执行低32位操作,B线程执行高32位操作,导致变量值出错。
转载地址
为什么用线程池?好处?ThreadPoolExecutor了解吗?
使用线程池的好处:
- 线程池的重用
线程的创建和销毁的开销的巨大的。通过线程池能很好的减少这些不必要的开销。使线程的执行速度更快了! - 控制线程的并发数
控制线程池的并发可以有效的避免大量的线程争夺CPU资源而造成堵塞 - 线程池可以对线程进行管理
线程池可以提供定时,定期,单线程,并发数控制等功能。比如通过ScheduledThreadPool线程池来执行S秒后,每隔N秒执行一次的任务。
线程池的解析
1.ThreadPoolExecutor
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
平常最多用到的是corePoolSize、maximumPoolSize、keepAliveTime、unit、workQueue
夏天了,很热,所以很多烧烤店都会在外面也布置座位,分为室内、室外两个地方可以吃烧烤。(室内有空调电视,而且室内比室外烧烤更加优惠,而且外面下着瓢泼大雨所以顾客会首先选择室内)
corePoolSize(烧烤店室内座位),cuurentPoolSize(目前到烧烤店的顾客数量),maximumPoolSize(烧烤店室内+室外+侯厅室所有座位),workQueue(烧烤店为顾客专门设置的侯厅室)
第(1)种,烧烤店人数不多的时候,室内位置很多,大家都其乐融融,开心的坐在室内吃着烧烤,看着世界杯。
第(2)种,生意不错,室内烧烤店坐无空席,大家都不愿意去外面吃,于是在侯厅室里呆着,侯厅室位置没坐满。
第(3)种,生意兴隆,室内、侯厅室都坐无空席,但是顾客太饿了,剩下的人没办法只好淋着雨吃烧烤,哈哈,好可怜。
第(4)种,生意爆棚,室内、室外、侯厅室都坐无空席,在有顾客过来直接赶走。
2. 其他线程池的解析
- FixedThreadPool
Fixed中文解释为固定。结合在一起解释固定的线程池,说的更全面点就是,有固定数量线程的线程池。其corePoolSize=maximumPoolSize,且keepAliveTime为0,适合线程稳定的场所。 - SingleThreadPool
Single中文解释为单一。结合在一起解释单一的线程池,说的更全面点就是,有固定数量线程的线程池,且数量为一,从数学的角度来看SingleThreadPool应该属于FixedThreadPool的子集。其corePoolSize=maximumPoolSize=1,且keepAliveTime为0,适合线程同步操作的场所。 - CachedThreadPool
Cached中文解释为储存。结合在一起解释储存的线程池,说的更通俗易懂,既然要储存,其容量肯定是很大,所以他的corePoolSize=0,maximumPoolSize=Integer.MAX_VALUE(2^32-1一个很大的数字) - ScheduledThreadPool
Scheduled中文解释为计划。结合在一起解释计划的线程池,顾名思义既然涉及到计划,必然会涉及到时间。所以ScheduledThreadPool是一个具有定时定期执行任务功能的线程池。
TCP怎么解决粘包拆包问题
如果客户端连续不断的向服务器发送数据包时,服务器端接受的数据会出现两个数据包粘在一起的情况。这就是TCP协议中集成会遇到的粘包问题。
UDP是不会出现粘包或拆包。
UDP是基于报文发送的。从UDP的帧结果可以看出,UDP首部采用了16bit来指示UDP数据报文的长度。因此在应用层能很好的将不同的数据报文区分开从而避免粘包和拆包问题。
TCP把这些数据块看成是一连串无结构的字节流。没有边界;另外从TCP的帧结构也可以看出,TCP的首部没有表示数据长度的字段。基于以上两点,在使用TCP传输数据时,菜有粘包或者拆包现象发生的可能
粘包,拆包的表现形式
现在假设客户端向服务端连续发送了两个数据包,用packet1和packet2来表示,那么服务端收到的数据可以分为三种,现列举如下:
第一种情况,接收端正常收到两个数据包,即没有发生拆包和粘包的现象,此种情况不在本文的讨论范围内。

第二种情况,接收端只收到一个数据包,由于TCP是不会出现丢包的,所以这一个数据包中包含了发送端发送的两个数据包的信息,这种现象即为粘包。这种情况由于接收端不知道这两个数据包的界限,所以对于接收端来说很难处理。

第三种情况,这种情况有两种表现形式,如下图。接收端收到了两个数据包,但是这两个数据包要么是不完整的,要么就是多出来一块,这种情况即发生了拆包和粘包。这两种情况如果不加特殊处理,对于接收端同样是不好处理的。

粘包、拆包发生原因
发生TCP粘包或拆包有很多原因,现列出常见的几点,可能不全面,欢迎补充,
1、要发送的数据大于TCP发送缓冲区剩余空间大小,将会发生拆包。
2、待发送数据大于MSS(最大报文长度),TCP在传输前将进行拆包。
3、要发送的数据小于TCP发送缓冲区的大小,TCP将多次写入缓冲区的数据一次发送出去,将会发生粘包。
4、接收数据端的应用层没有及时读取接收缓冲区中的数据,将发生粘包。
粘包、拆包解决办法
- 发送端给每个数据包添加包首部,首部中应该至少包含数据包的长度。这样接收端在接受到数据后,通过包首部的长度字段,便知道每一个数据包的实际长度了
- 发送端将每个数据包封装为固定长度。这样接受端每次从接受缓冲区中读取固定长度的数据就自然而然的把每个数据包拆分开来
- 可以在数据包之间设置边界。如添加特色符号,接收端通过这个边界就可以将不同的数据包拆分开