干货 | 掌握 Selenium 元素定位,解决 Web 自动化测试痛点
有关 Selenium 的介绍在网上实在是太多了,总结起来就是一个目前在 Web 自动化方面运用最为广泛的一个开源、无浏览器要求、可支持多语言、设计测试用例非常灵活的自动化测试框架。
Selenium架构及核心组件

了解 Selenium 之前,我们需要了解 Selenium 的架构及核心组件。俗话说:『工欲善其事,必先利其器』。只有先了解架构及核心组件,才能了解该如何正确使用这个工具。才能让『它』成为我们工作中的一把利器,帮助我们解决难题。
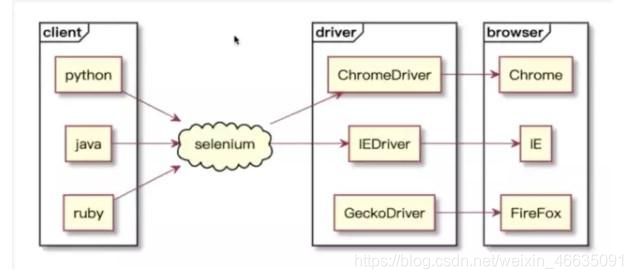
Selenium架构
client:每个语言都有自己的库,提供不同的 API 供用户去调用完成相关的自动化测试行为;这里调用有关 web 自动化的 API 到 selenium 的 server
selenium:用于将接收到的请求传给浏览器的driver,实施调用,实际上 selenium 就是浏览器driver的一个封装
driver:针对浏览器的一个驱动引擎,每个浏览器都有自己的驱动(一般由各个浏览器厂商提供),可以通过驱动浏览器的API来完成对应操作
browser:浏览器
Selenium核心组件
selenium webdriver client (目前主要使用的,依赖于drivers)
selenium drivers (浏览器驱动,被webdriver client 所依赖)
selenium1 selenium-rc (已弃用)
selenium IDE (入门录制工具-本人不常用,仅了解过)
selenium grid (可操纵浏览器集群,也可操作App)
Selenium安装
第一步:组件安装
安装浏览器 :web自动化,没浏览器好像说不过去了,先装浏览器是必须的
安装selenium driver,加入环境变量path :环境变量,老生常谈的问题了
安装selenium-client :安装到这步后就可以开始web自动化了,不同语言的根据需要进行安装,如Java的可以使用maven,目前建议使用稳定版本的3.141.59:
安装selenium-ide : 新手入门,我在这里就不去演示了,需要入门了解的小伙伴可以查阅资料哈~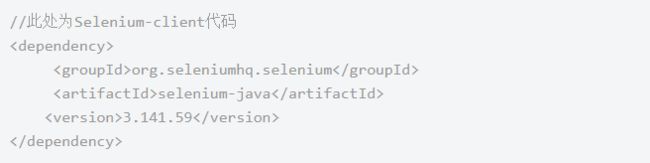
第二步:ChromeDriver下载
笔者这里主要用的是Chrome浏览器,所以就以Chrome为例 。
1)先去到selenium官网的下载中心http://www.seleniumhq.org/download/;往下翻,翻到如下图的位置: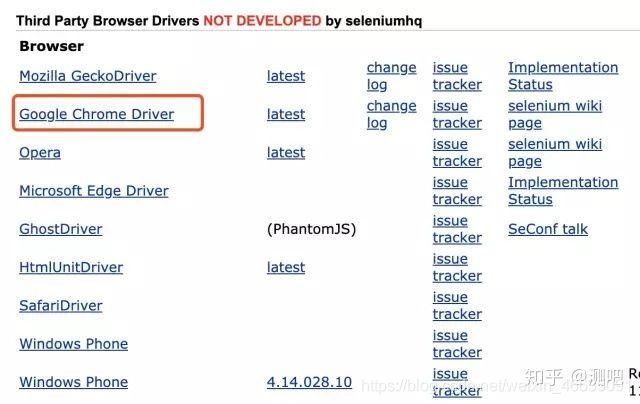
2)进去后找到与你当前Chrome浏览器版本对应的driver版本,下载对应系统的driver(需要梯子,如果没有继续往下看)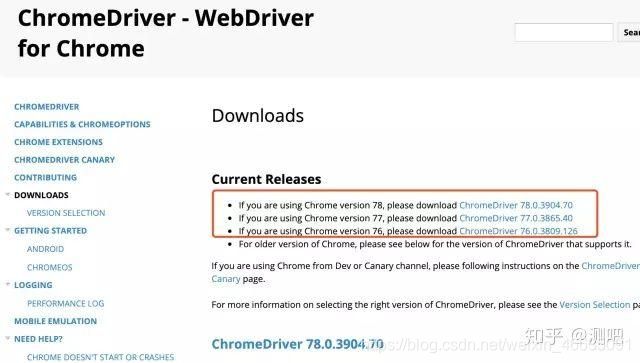
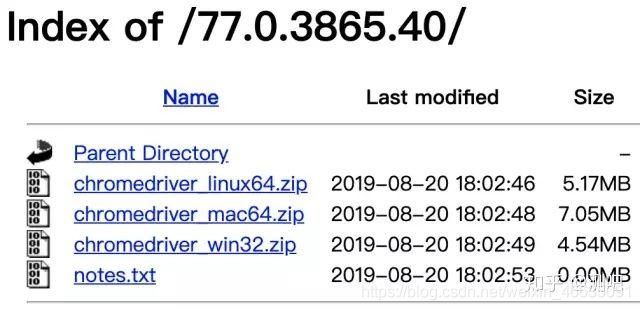
如果你没有梯子,无法去官网下载driver的话,这里提供一个淘宝的镜像,在国内的网络就可以直接下载 https://npm.taobao.org/mirrors/chromedriver
3)下载完成后解压到自己指定的路径即可,别忘了将路径添加到环境变量中(这里以Mac为例)
元素定位
元素定位是做UI自动化最基础也是最重要的部分之一了,搞定了元素定位,算是推开了web自动化的大门,即可走进web自动化的世界。
现在我们用一个『侦探』的眼光,把元素定位当成一个『刑侦手段』,来看看如何利用元素定位这个刑侦手段,侦破一个『犯罪现场』。
首先,我们需要认识元素。元素是可识别区分的属性。Selenium的WebDriver一共提供了九种定位方法,其中最常用的是前八种,先来看看在Java中的对应关系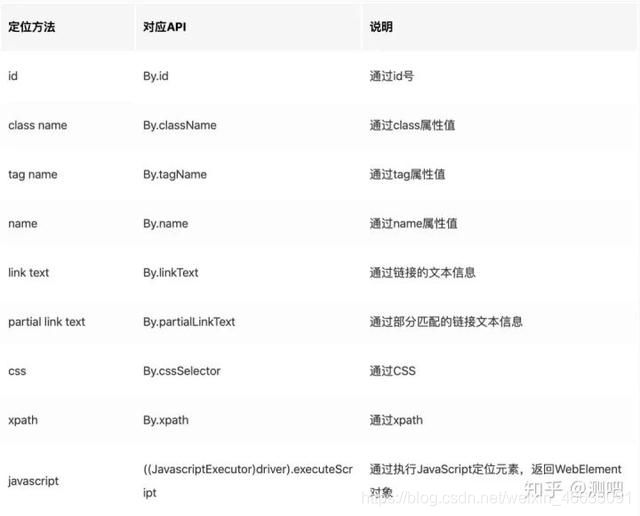
如上表所示,web自动化就是靠着HTML的各种标签、属性等来定位元素来进行操作,那么这些定位方式怎么理解?我们可以参考一个犯罪案例:
警察正在抓捕一名人犯罪嫌疑人,要确认犯罪嫌疑人的身份就可以根据嫌疑人的姓名、别名、指纹、身份证号、手机号等可识别区分的属性;同样的,元素自身也有id、classname、tagname、name等属性可用于区分定位;
此嫌疑人的反侦察能力比较强,隐藏了自己的身份特征,无法根据其自身的属性进行定位,那么就可以根据其经常出没的场所来进行定位抓捕,例如去某省某市的某个酒吧里,去某县某村某号的一个住所去;同样的,元素自身也可以通过Xpath和CSS这种标签的层级位置来定位元素。
到目前为止,嫌犯依然在逃,为了躲避侦查,曾经的常去场所都不再接触,高手!这是高手!苦苦的等待,最终办案民警们终于有了线索(接下来该办案民警出场讲述转机了~):由于犯罪嫌疑人是个大孝子且十分疼爱自己的妻儿,于是在某个地方偷偷的给父母通了电话,去学校见了妻儿;最终根据其家人提供的信息暴露自己,被定位抓获!同样的,元素也可以通过与其相关的元素来进行定位,我们就可以用CSS或Xpath来进行父子,兄弟等节点位置的方式来进行定位了。
案件告破,案件总结-定位元素的方法
Warning! 下面在介绍各种定位方式的时候还会顺便补充CSS的定位方式作为对比,首次接触的话可能会因为看不懂而引起不适,不用担心,可以先忽略,后面会专门介绍CSS的,待了解了CSS定位方式后再回来学习
1.By ID - 身份证
现在我们要定位testerhome首页右上角的欢迎,如下图:
打开Chrome开发者工具,选中元素进行查看,元素是有id的,可以根据id来定位: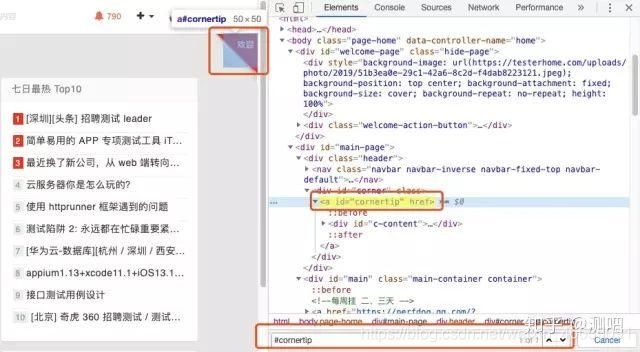

小技巧:我们可以在Chrome的开发者工具中Control+F搜索框中对我们要定位的元素进行搜索来确认定位是否正确,支持CSS和xpath,如上图所示
2.By Class Name - 别名
要定位testerhome首页的搜索框,就可以根据ClassName,如下图: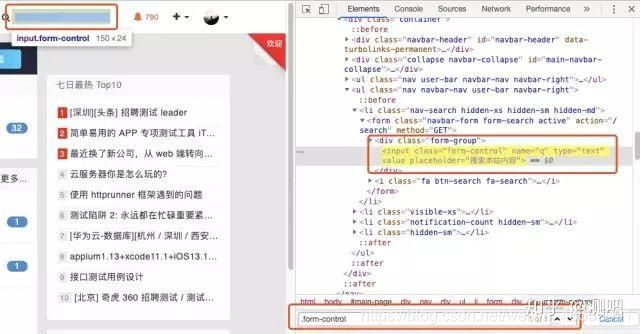

3.By Name - 姓名
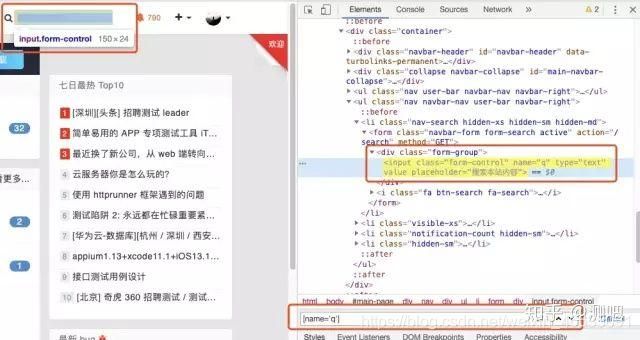
依然定位首页的搜索框,可通过name和CSS定位:

4.By Tag Name
依然是定位testerhome首页的搜索框,通过tagname :input来定位
5.By Link Text
定位testerhome首页一周最热的帖子,通过linktest和CSS: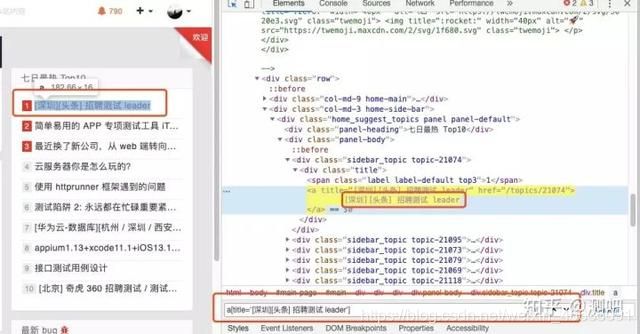

6. By Partial Link Text
定位testerhome首页一周最热的帖子,通过partialLinkText和CSS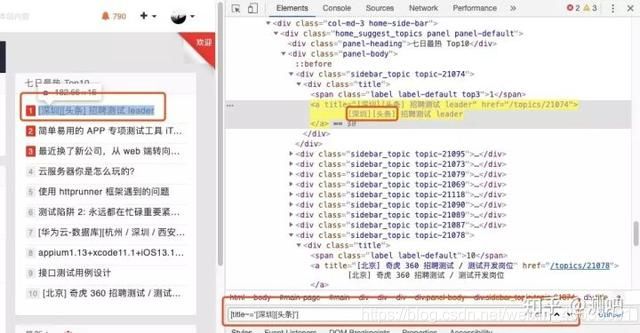

7.Using JavaScript
有时候我们的页面元素被遮挡导致无法定位,需要滚动屏幕进行可视化,便可以用JS来操作:![]()
8.By Xpath
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历,而HTML又正好可以看做是XML的一种实现,因此我们便可以用xpath来定位元素啦
问题:一般刚开始学定位的时候很多人都会想,都有了上面那么多种定位方式了,还要xpath干吗?感觉还挺复杂的样子(和其他的定位方式相比却是要复杂那么一丢丢)~
答:那是因为并不是所有的元素都“如您所愿”,就如上面警察抓捕罪犯的例子,有时候元素并不能直接提供给我们想要的定位
常用路径表达式:
举几个简单的栗子
1)绝对路径定位:
做测试开发或者有编程经验的小伙伴一定对绝对路径不陌生,通过绝对路径就是使用元素在页面上的完整路径。
还是以定位一周内的最热门帖子为例,在Chrome浏览器的开发者工具栏中,找到要定位元素的HTML位置,右击会出现Copy full Xpath,点击它
然后我们把复制到的内容黏贴后如下:![]()
写到代码里就是这样:
可以用又臭又长来形容了,那么细心的小伙伴会发现还有一个Copy xpath,复制黏贴后内容如下:![]()
看起来好像简化了点,还用上了xpath的语法,但是实际上也没优化多少,依然是通过标签的层级关系,从最外层一级一级的往下找,也不是很可取;
其实不可取的最主要原因还是这种绝对路径的方式在实际自动化过程中很不稳定,界面的位置发生任何一丢丢的变化,那元素的绝对路径就很可能变了,也就无法准确定位了。
因此我们就要用元素的属性或者属性和层级关系相结合的方式来定位,这样就算页面变化,只要变化不是非常大,依然可以通过元素的属性和相对的位置来进行定位,受页面位置变化的影响就要小的多了
2)元素属性定位:
定位testerhome首页的欢迎,利用xpath语法通过id来定位: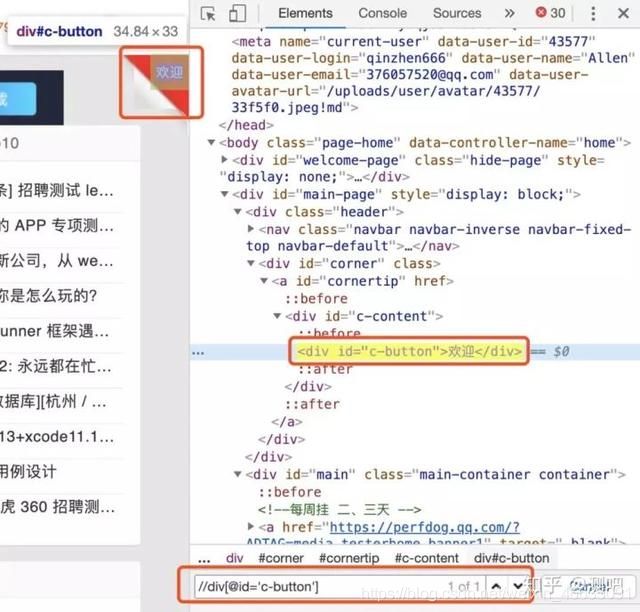

语法解释://div表示从当前页面的div标签开始匹配,@id表示用id属性值,=后面跟着具体的id值
3)属性和层级关系定位:
上面的通过属性定位完全可以用WebDriver的API或者CSS搞定,xpath最大的价值就是上面说的当元素没有直接可定位的属性时,它的价值才得以完美体现:
现在我们要定位”七日最热 Top10“这个标题,它只有class属性,我们按照className来进行定位会发现如下情况: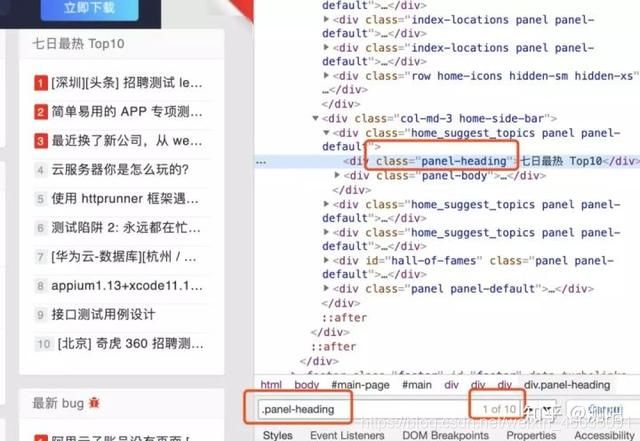
没错,出现了10个可被定位到的元素,因为有很多的标题都有相同的classname,并且没有其他如id,name等属性了;没办法了,我们就要往上找,我们发现往上2个div标签节点,classname为”col-md-3 home-side-bar“的标签节点是唯一的:
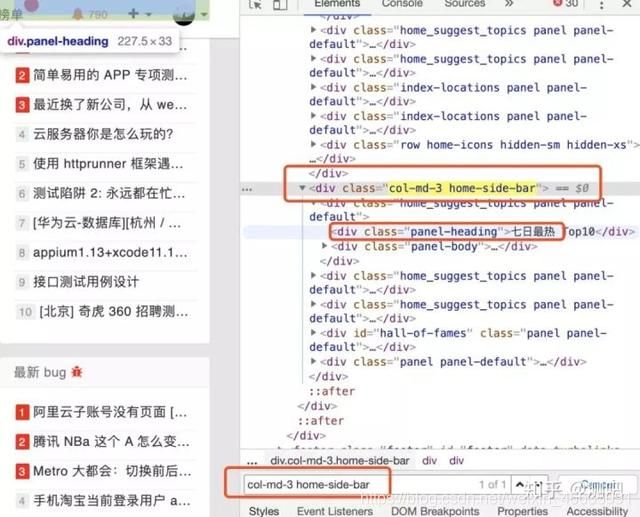
现在我们就利用Xpath先定位到唯一的那个class,然后往下找两层div,再取两层后div中的第一个就可以了

4)使用Xpath运算符定位:
Xpath还支持运算符,如果元素的一个属性无法定位,需要使用多个属性时可以使用Xpath运算符将多个属性连接起来一起定位
Xpath常用运算符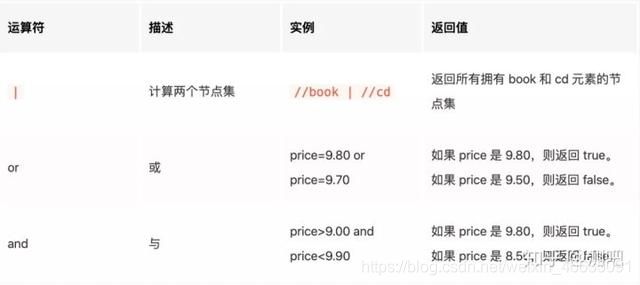
现在需要定位testhome社区首页一篇最新帖子的作者,作者名为“乌云乌云快走开” 如果我们只依靠className的话会发现有28个相同属性的元素,如下图:
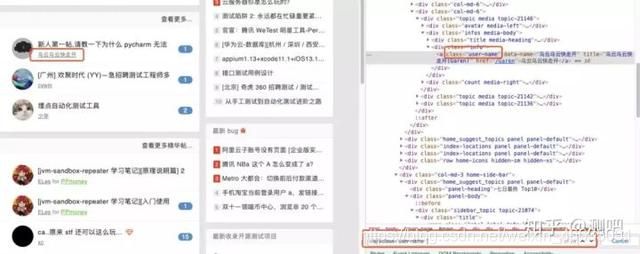
继续观察会发现还有一个叫做data-name的属性,属性值就是作者的姓名,我们通过and符将两个属性连接后便发现可以精准定位到指定元素了: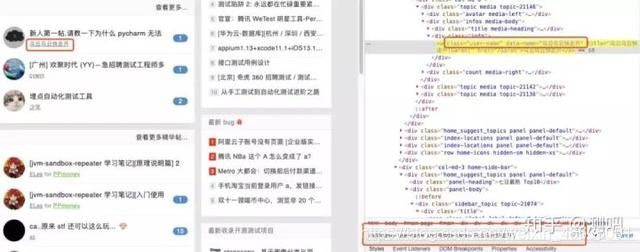

5)使用Xpath函数定位:
Xpath还提供了很多函数来供我们更灵活的定位,这里以我常用的一个contains函数为例
我们依旧来定位testerhome首页七日最热贴的首贴“[深圳][头条] 招聘测试 leader”,通过对DOM的分析可以看到title属性的内容就是帖子的标题,我们用此属性值的一部分来作为定位条件: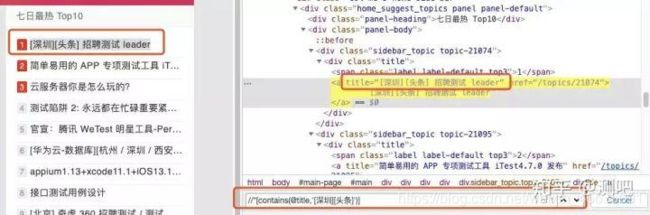

关于Xpath的语法使用还有很多,包括还有很多函数,具体的可参考W3C进行学习:https://www.w3school.com.cn/xpath/xpath_syntax.asp
9.By CSSWeb页面的样式通常保存在外部的 .css 文件中。通过仅仅编辑一个简单的 CSS 文档,外部样式表使你有能力同时改变站点中所有页面的布局和外观。因此我们可以利用CSS的选择器来定位页面绑定了属性的元素,从而为我们的selenium所用
从上面的文章一路看下来的小伙伴应该发现了,在介绍xpath之前的定位方式时,都另外还写了一个CSS的定位方式,没错,就是它,没注意的小伙伴可以返回去看一看;
推荐使用CSS: CSS也是我们在Web自动化中最推荐使用的一种方式,原因又如下几种:
例如id这种元素在一个页面中可能并不唯一,并且很有可能是前端的框架自动生成的,研发人员并未对其进行维护,随时可能变;而CSS是前端开发最常用的一种维护方式,对于我们开发和维护自动化用例也更为清晰和方便
大部分定位都可以用CSS来解决
CSS的写法相较于Xpath要更为简洁
常用的CSS选择器语法:

先将前面已经演示过的CSS语法在这来个小的汇总:

另外CSS也可以将属性和层级关系组合在一起进行使用,现在我们以这种组合方式来定位testerhome社区置顶帖的第一篇帖子: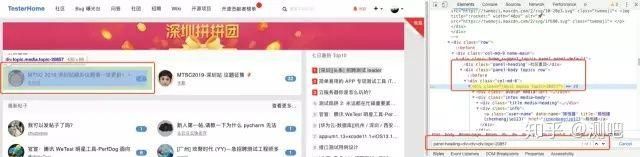

简要说明: .panel-heading:class值为panel-heading +div : 后面紧接着的div >div:后面所有子的div div.topic-20857:class名为topic-20857的div标签
(文章来源于霍格沃兹测试学院)