文章原创,最近更新:2018-08-8
本章节的主要内容是:
重点介绍项目案例1: 优化约会网站的配对效果中的 准备数据:使用 Python 解析文本文件。
1.KNN项目案例介绍:
项目案例1:
优化约会网站的配对效果
项目概述:
1)海伦使用约会网站寻找约会对象。经过一段时间之后,她发现曾交往过三种类型的人: 不喜欢的人、魅力一般的人、 极具魅力的人。
2)她希望: 1. 工作日与魅力一般的人约会 2. 周末与极具魅力的人约会 3. 不喜欢的人则直接排除掉。现在她收集到了一些约会网站未曾记录的数据信息,这更有助于匹配对象的归类。
开发流程:
- 收集数据:提供文本文件
- 准备数据:使用 Python 解析文本文件
- 分析数据:使用 Matplotlib 画二维散点图
- 训练算法:此步骤不适用于 k-近邻算法
- 测试算法:使用海伦提供的部分数据作为测试样本。
测试样本和非测试样本的区别在于:测试样本是已经完成分类的数据,如果预测分类与实际类别不同,则标记为一个错误。 - 使用算法:产生简单的命令行程序,然后海伦可以输入一些特征数据以判断对方是否为自己喜欢的类型。
数据集介绍
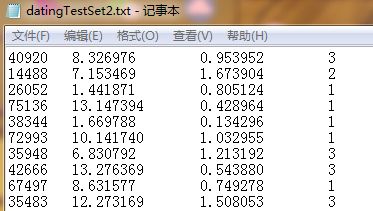
海伦把这些约会对象的数据存放在文本文件 datingTestSet2.txt (数据来源于《机器学习实战》第二章 k邻近算法)中,总共有 1000 行。
本文使用的数据主要包含以下三种特征:每年获得的飞行常客里程数,玩视频游戏所耗时间百分比,每周消费的冰淇淋公升数。其中分类结果作为文件的第四列,并且只有3、2、1三种分类值。datingTestSet2.csv文件格式如下所示:
| 飞行里程数 | 游戏耗时百分比 | 冰淇淋公升数 | 分类结果 |
|---|---|---|---|
| 40920 | 8.326976 | 0.953952 | 3 |
| 14488 | 7.153469 | 1.673904 | 2 |
| 26052 | 1.441871 | 0.805124 | 1 |
数据在datingTestSet2.txt文件中的格式如下所示:
2.准备数据:使用 Python 解析文本文件代码
这段代码主要是准备数据,并将数据转化为numpy解析程序
def file2matrix(filename):
"""
导入训练数据
filename: 数据文件路径
return: 数据矩阵returnMat和对应的类别classLabelVector
"""
# 打开文件
fr=open(filename)
# 读取每一行的信息
array0Lines=fr.readlines()
# 获得文件中的数据行的行数
numberofLines=len(array0Lines)
# 生成numberofLines行3列的零矩阵,这3列都是用来存放特征信息
returnMat=np.zeros((numberofLines,3))
# 存放类别是列表
classLabelVector=[]
index=0
for line in array0Lines:
# 去掉回车制表符,生成新的字符串
line=line.strip()
# 通过split以\t切割字符串,返回元素列表
listFromLine=line.split('\t')
# 选取前三个数据的特征值放进矩阵
returnMat[index,:]=listFromLine[0:3]
# 将listFromLine列表中的最后一列元素存储到classLabelVector
# 这列的数据是类别数据
classLabelVector.append(int(listFromLine[-1]))
# 更新index
index +=1
#返回特征矩阵returnMat和类别矩阵classLabelVector
return returnMat,classLabelVector
测试代码及其结果如下:
import kNN
kNN.file2matrix('datingTestSet2.txt')
datingDataMat
Out[46]:
array([[ 4.09200000e+04, 8.32697600e+00, 9.53952000e-01],
[ 1.44880000e+04, 7.15346900e+00, 1.67390400e+00],
[ 2.60520000e+04, 1.44187100e+00, 8.05124000e-01],
...,
[ 2.65750000e+04, 1.06501020e+01, 8.66627000e-01],
[ 4.81110000e+04, 9.13452800e+00, 7.28045000e-01],
[ 4.37570000e+04, 7.88260100e+00, 1.33244600e+00]])
3.相关知识点
知识点1:文件的打开、路径、打开模式、关闭
文件的打开,如下:

文件路径,如下:

打开模式,如下:


文件关闭,如下:

综合案例,如下:

知识点2:文件内容的读取


知识点3:python中numpy.zeros(np.zeros)的使用方法
zeros(shape, dtype=float, order='C')
- 返回:返回来一个给定形状和类型的用0填充的数组;
- 参数:shape:形状
- dtype:数据类型,可选参数,默认numpy.float64
np.zeros(5)
Out[35]: array([ 0., 0., 0., 0., 0.])
np.zeros((5,),dtype=int)
Out[37]: array([0, 0, 0, 0, 0])
np.zeros((2,1))
Out[38]:
array([[ 0.],
[ 0.]])
s=(2,2)
np.zeros(s)
Out[40]:
array([[ 0., 0.],
[ 0., 0.]])
知识点4:Python3 字符串的strip()方法
Python strip() 方法用于移除字符串头尾指定的字符(默认为空格)或字符序列。
注意:
- 该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
- strip() 处理的时候,如果不带参数,默认是清除两边的空白符,例如:/n, /r, /t, ' ')。
strip()方法语法:
str.strip([chars]);
- 参数:chars -- 移除字符串头尾指定的字符序列。
- 返回值:返回移除字符串头尾指定的字符序列生成的新字符串。
而这里的代码有导入数据的时候,每行末尾都有\n
故使用如下代码:
line=line.strip()
小案例如下:
addr = '[email protected]'
addr1 = addr.strip('12')#案例1
addr1
Out[43]: '[email protected]'
addr2 = addr.strip('23')#案例2
addr2
Out[45]: '[email protected]'
解析:
strip() 带有参数的时候,这个参数可以理解一个要删除的字符的列表,是否会删除的前提是从字符串最开头和最结尾是不是包含要删除的字符,如果有就会继续处理,没有的话是不会删除中间的字符的。
- 案例1:1 在字符串的左边第一个,所以删除了继续判断,2 也存在,所以也删除。
- 案例2:要删除的字符列表不包含第一个字符,时 2 不是第一个字符,所以无法继续。
知识点5:Python3 字符串的split()方法
split()通过指定分隔符对字符串进行切片,如果参数num 有指定值,则仅分隔 num 个子字符串。
split()方法语法:
str.split(str="", num=string.count(str))
- 参数:
- str -- 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。
- num -- 分割次数。
- 返回值:返回分割后的字符串列表。
小案例如下:
str = "this is string example....wow!!!"
print (str.split( ))
print (str.split('i',1))
print (str.split('w'))
输出结果如下:
['this', 'is', 'string', 'example....wow!!!']
['th', 's is string example....wow!!!']
['this is string example....', 'o', '!!!']
而这里的代码有导入数据的时候,每行都有\t
故使用如下代码:
listFromLine=line.split('\t')
知识点6:Python3 List append()方法
append() 方法用于在列表末尾添加新的对象。
append()方法语法:
list.append(obj)
- 参数:obj -- 添加到列表末尾的对象。
- 返回值:该方法无返回值,但是会修改原来的列表。
小案例如下:
list1 = ['Google', 'Runoob', 'Taobao']
list1.append('Baidu')
print ("更新后的列表 : ", list1)
输出结果如下:
更新后的列表 : ['Google', 'Runoob', 'Taobao', 'Baidu']