对于每个即将就读社会大学的学生,总要面临就业问题。如何赢在起跑线上,在网上找到心仪的工作并做好准备?今天让我们来爬取实习僧的招聘信息,看看当今的实习岗位数据分析,助你成功!!!
运行平台: windows
Python版本: Python3.5
IDE: Pycharm
其他工具: Chrome浏览器
目录
- 结果展示
1.1 文件展示
1.2 图表展示 - 思路分析
- 网页分析
3.1 分析初始网页请求
3.2 分析有用数据 - 文件读写
- 图表制作
5.1 热词图
5.2 学历分布饼图
5.3 工资分布直方图 - 代码优化
6.1 获取最大页数
6.2 进度显示
城市编码转化 - 完整代码
- 干货奉献
1. 结果展示
1.1文件展示
范例里爬取实习僧职位共12个字段,这里选择 city 为广州,keyword 为数据分析,进行了爬取(city, keyword稍做解释)

1.2 图表展示

2. 思路分析
1、打开实习僧网站,根据需求选择地区和职位关键词,点击搜索。
2、进入初始界面分析抓取职位具体信息链接,请求此链接,抓取想要字段。
3、数据清洗完毕后存放在CSV文件
4、提取数据分别制作图表
5、多次修改,代码优化
3. 网页分析
3.1 分析初始网页请求
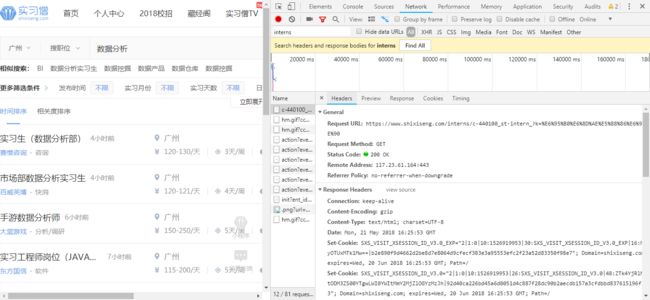
以广州数据分析职位为例,进入实习僧网站后输入点击搜索,F12打开开发者工具。点击Network栏,按F5刷新一次获取请求数据。
这里查看网页请求连接可“Ctrl+F”搜索输入“interns”(即网页链接关键词,快速锁定信息)。其中Headers栏查看具体请求信息,Preview栏查看展示界面。
通过观察,可以发现爬取信息有多个网页,需要构造不同链接
然后我们就可以着手爬取初始网页了
import requests
def get_one_page(cityid, keyword, pages):
# 传入的请求数据
paras = {
'k': keyword,
'p': pages
}
# 请求头设置
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3423.2 Safari/537.36',
'Host': 'www.shixiseng.com',
'Referer': 'https://www.shixiseng.com/gz',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9'
}
# 初始页面的url
url = 'https://www.shixiseng.com/interns/c-{}_?'.format(cityid)
# 获取网页内容,返回html数据
response = requests.get(url, headers=headers, params=paras)
# 通过状态码判断是否获取成功
if response.status_code == 200:
return response.text
return None
参数解释:
city:工作城市对应id(实习僧对每个城市进行编号,后续代码有编号转化,直接输入城市即可)
keyword:搜索的关键词
pages:想要获取的数据页数
接着我们来获取职位具体信息链接,通过元素定位找到职位具体链接的HTML代码,用正则表达式简单提取
import re
def get_detail_pageinfo(response):
hrefs = re.findall('.*?3.2 分析有用数据
选中其中一个职位信息,发现满满的数据,找到想要获取的数据,分别通过元素定位找到对应HTML代码
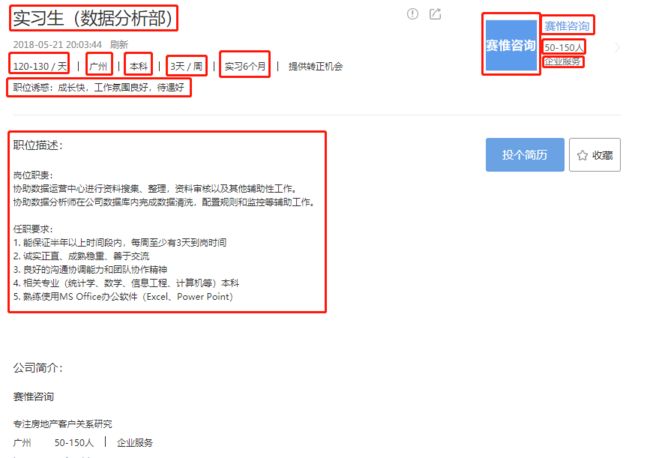
首先,利用前面爬取到的职位链接,请求职位具体数据页
def get_detail_page(href):
url = 'https://www.shixiseng.com' + href
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3423.2 Safari/537.36',
'Host': 'www.shixiseng.com',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9'
}
response = requests.get(url=url, headers=headers)
# 通过状态码判断请求是否获取成功
if response.status_code == 200:
return response.text
return None
马上,就是最让人兴奋的数据爬取环节。也是最容易让人抓狂的环节- - 。
from bs4 import BeautifulSoup
def parse_detail_info(response):
# decrypt_text() 函数,用来解密实习僧加密的数字信息
response = decrypt_text(response)
# 使用BeautifulSoup库进行解析
soup = BeautifulSoup(response, 'lxml')
# soup.find(class_='x'),find返回匹配到属性'class'为'x'的第一个元素。
info1 = soup.find(class_='job-header')
# get_text():获取文本内容
job = info1.find(class_='new_job_name').get_text()
info1_detail = info1.find(class_='job_msg')
salary = info1_detail.find(class_='job_money cutom_font').get_text()# 获取salary字段
city = info1_detail.find(class_='job_position').get_text()# 获取city字段
education = info1_detail.find(class_='job_academic').get_text()# 获取education字段
workday = info1_detail.find(class_='job_week cutom_font').get_text()# 获取workday字段
worktime = info1_detail.find(class_='job_time cutom_font').get_text()# 获取worktime字段
job_good = info1.find(class_='job_good').get_text()# 获取job_good字段
job_detail = soup.find(class_='job_detail').get_text().replace('\n','')
# 获取job_detail字段,这里选择把换行符‘\n’去掉,是为了打开csv时观感变好,否则行高过大影响观察
info2 = soup.find(class_='job-com')
company_href_pre = info2.a # info2.a:返回info2中a标签内容
company_href = 'https://www.shixiseng.com' + company_href_pre['href']# 获取company_href字段,注意这里获取的是相对链接,需要补充部分url字符
company_pic_pre = info2.find('img')#返回匹配的第一个div标签内容
company_pic = company_pic_pre['src']# 获取company_pic字段
company_info = info2.find('div')
company_name = company_info.get_text()
company_scale = info2.find(class_='com-num').get_text()
company_class = info2.find(class_='com-class').get_text()
# 最后以字典形式返回,方便后续数据提取存放
return {
'job':job,
'salary':salary,
'city':city,
'education':education,
'workday':workday,
'worktime':worktime,
'job_good':job_good,
'job_detail':job_detail,
'company_pic':company_pic,
'company_name':company_name,
'company_scale':company_scale,
'company_class':company_class
}
哎,看上去貌似很简单,爬虫不难嘛!
看到这里或许很多人会这样想。爬虫本身是一门讲究耐心和方法的技术,看似简单地代码背后,需要反复调试。同时,实习僧对信息的整理很到位,几乎不需要进行数据清洗,即爬即用。
不过先别高兴太早,在工资处元素定位看清楚再说

什么,我的工资呢!!!∑(゚Д゚ノ)ノ。咦~仔细看看,个别文字也被加密处理。
实习僧反爬力度不大,可轻松提取信息,然而也有加密处理信息。没有解密的话,所有数字和个别文字都显示为正方形。(你的工资空空如也)

咋办呢?
我们可以从其本质出发,既然对数据进行过加密,必然有对应的解密映射。
# mapping 是数字的映射字典
mapping = {'': '0', '': '1', '': '2', '': '3', '': '4',
'': '5', '': '6', '': '7', '': '8', '': '9'}
def decrypt_text(text):
# 定义文本信息处理函数,通过字典mapping中的映射关系解密
for key, value in mapping.items():
text = text.replace(key, value)
return text
思路剖析:(由于文字解密过于繁琐,这里只进行了数字解密)
-
为了找到对应加密映射,我们手动查看网页源代码,找到对应的unicode编码方式,并建立映射字典mapping。
 展示页面
展示页面

- 将mapping当中的unicode编码替换为数字。上面的text是请求获取的职位具体信息页HTML代码。获取请求即进行解密过滤。
本人才疏学浅,目前只掌握最为简朴而略繁琐的字符串替换方法。
附上更为详尽的解密方式解说,此处不做过多赘述
- 爬虫实战|破解“实习僧”网站字体加密
- Python爬虫杂记 - 字体文件反爬(二)
4. 文件读写
获取的数据字段数相同,且样本量不大,这里直接存储为csv文件格式
(CSV :逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。纯文本意味着该文件是一个字符序列,不含必须像二进制数字那样被解读的数据。
)
# python内置的csv函数库
import csv
# pandas库,用于数据整理
import pandas as pd
# csv文件表头设置
headers = ['job','salary','city','education','workday','worktime','job_good','job_detail',
'company_pic','company_name','company_scale','company_class']
def write_csv_headers(file, headers):
with open(file, 'a', encoding='gb18030', newline='') as f:
f_csv = csv.DictWriter(f, headers)
f_csv.writeheader()
# 这里将写入表头和写入数据分为两个函数,因为前者只需写入一次,后者重复多次
def write_csv_rows(file, headers, rows):
with open(file, 'a', encoding='gb18030', newline='') as f:
f_csv = csv.DictWriter(f, headers)
f_csv.writerow(rows)
# 读取CSV文件数据,为后续图表制作提供数据
def read_scv(file):
data = pd.read_csv(file , engine = 'python')
return data
参数解释:
file :文件的存储路径(带有文件名)
当数据利用pandas库从csv文件中提取下来时,是一个DataFrame格式数据(二维数组),方便高效处理数据分析。不清楚pandas用法的可参考此教程:pandas用法大全
5. 图表制作
5.1 热词图
热词图,即通过统计职位描述中单词,查看哪些词汇是本职位中出现最为频繁,也是职位的第一印象和要求。
这是本次项目里最为繁琐的一个环节,我们先来整理思路。
1、读取 CSV 文件,提取‘job_detail’字段,将其拆分为多个词汇。
2、词汇依次存放 TXT 文件中。
3、下载停止词‘stopwords.txt’文件(停止词如你我他等使用频率过高而不带实际作用的词汇),过滤不必要统计的停止词汇
4、准备一张背景图(颜色区分度明显为优),以此生成词云图
统计用到多个函数库,务必提前安装好
- pip install jieba
- pip install pandas
- pip install numpy
- pip install scipy
5.1.1词汇的存储与读取
# 写入txt文本
def write_txt_file(file, txt):
# newline='':防止每次写入自动换行,影响读取
with open(file, 'a', encoding='gb18030', newline='') as f:
f.write(txt)
# 读取txt文本
def read_txt_file(file):
with open(file, 'r', encoding='gb18030', newline='') as f:
return f.read()
5.1.2停止词过滤

百度搜索stopword.txt即可下载,把文件放在py文件同级目录
# 利用jieba库分割词汇,并存储为DataFrame格式方便数据整理
segment = jieba.lcut(content)
words_df = pd.DataFrame({'segment': segment})
stopwords = pd.read_csv("stopwords.txt", index_col=False, quoting=3, sep=" ", names=['stopword'], encoding='utf-8')
words_df = words_df[~words_df.segment.isin(stopwords.stopword)]
参数解释:
content:读取 txt 文件的数据
PS:可依照个人偏向,自助在stopwords.txt添加过滤词汇
5.1.3词云制作
统计词汇虽然简单,但无法给人带来视觉冲击,便引用词云,带入可视化。
def wordcloud(words_df, keyword, cityid):
# 停止词过滤
stopwords = pd.read_csv("stopwords.txt", index_col=False, quoting=3, sep=" ", names=['stopword'], encoding='utf-8')
words_df = words_df[~words_df.segment.isin(stopwords.stopword)]
# 词汇统计
words_stat = words_df.groupby(by=['segment'])['segment'].agg({"计数": np.size})
words_stat = words_stat.reset_index().sort_values(by=["计数"], ascending=False)
# 设置词云属性
color_mask = imread('backgroud.png')
wordcloud = WordCloud(font_path="simhei.ttf", # 设置字体可以显示中文
background_color="white", # 背景颜色
max_words=100, # 词云显示的最大词数
mask=color_mask, # 设置背景图片
max_font_size=100, # 字体最大值
random_state=42,
width=1000, height=860, margin=2,# 设置图片默认的大小,但是如果使用背景图片的话, # 那么保存的图片大小将会按照其大小保存,margin为词语边缘距离
)
# 生成词云, 可以用generate输入全部文本,也可以我们计算好词频后使用generate_from_frequencies函数
word_frequence = {x[0]:x[1]for x in words_stat.head(100).values}
word_frequence_dict = {}
for key in word_frequence:
word_frequence_dict[key] = word_frequence[key]
wordcloud.generate_from_frequencies(word_frequence_dict)
# 从背景图片生成颜色值
image_colors = ImageColorGenerator(color_mask)
# 重新上色
wordcloud.recolor(color_func=image_colors)
# 保存图片
picname = cityid + "_" + keyword + '_' + '热词图.png'
wordcloud.to_file(picname)
plt.imshow(wordcloud)
plt.axis("off")
图片对比


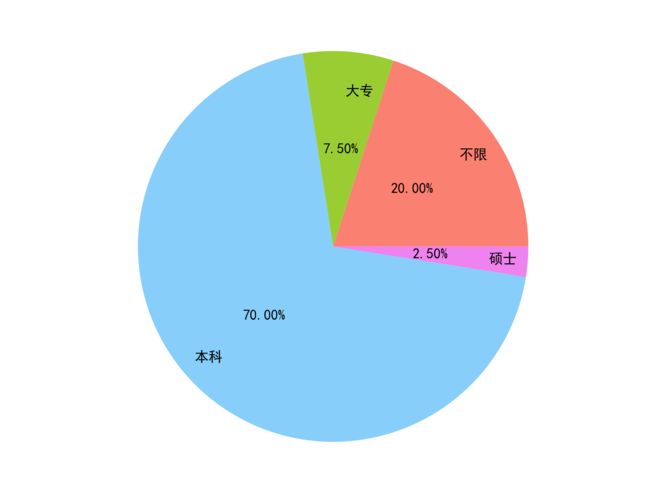
5.2 学历分布饼图
代码如下:
import matplotlib.pyplot as plt
import pandas as pd
def education_pie(data, city, keyword):
s = data.groupby('education').count()# 对'education'字段分组,并将组内数据进行计数,得到不同学历要求的数目
n = len(s.index)#学历要求种类数目
# 设置颜色列表,默认至少3种
lst = ['salmon','yellowgreen','lightskyblue']
if n >= 4:
lst.append('violet')
plt.axis('equal') # 保证长宽相等
plt.pie(s['job'],#选择其他任意字段列,获得count()计数数目
labels=s.index,#学历种类做标签
colors=lst,
autopct='%.2f%%',#比例保留两位小数
pctdistance=0.5,#比例数字据中心距离
labeldistance=0.8,#标签名据中心距离
startangle=0,#开始角度
radius=1.3)#半径大小
name = city + "_" + keyword + '_' + '学历分布饼图.png'
plt.savefig(name, dpi=300)#保存图片,'dpi'为画质参数,越高画质越好
结果展示:

更多matplotlib使用方法,可参考官方手册matplotlib
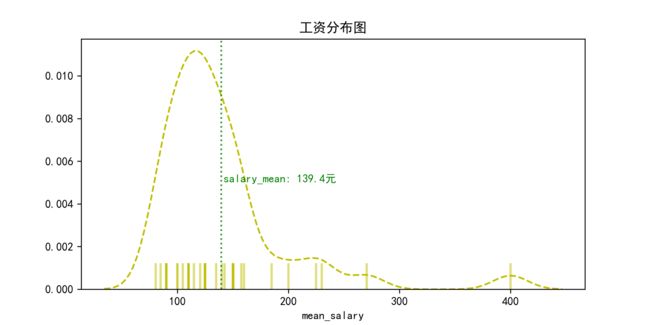
5.3 工资分布直方图
代码如下:
import matplotlib.pyplot as plt
import seaborn as sns
def salary_hist(data, city, keyword):
# 数据清洗,化为整数形式
data['low_salary'] = data['salary'].str.strip('/天').str.split('-').str[0]#.str,对元素化为字符串格式再拆分
data['high_salary'] = data['salary'].str.strip('/天').str.split('-').str[1]
data['mean_salary'] = ( data['low_salary'].astype(np.int) + data['high_salary'].astype(np.int) ) / 2#.astype():元素格式转化
s = data['mean_salary']#建立新字段方便取用
mean = s.mean()#求取所有工资的平均值
plt.figure(figsize=(8, 4)) # 设置作图大小
plt.title('工资分布图') # 图名
plt.xlabel('salary') # x轴标签
sns.distplot(s, hist=False, kde=True, rug=True,
rug_kws={'color': 'y', 'lw': 2, 'alpha': 0.5, 'height': 0.1}, # 设置数据频率分布颜色
kde_kws={"color": "y", "lw": 1.5, 'linestyle': '--'}) # 设置密度曲线颜色,线宽,标注、线形
# 其中'hist'直方图不显示。'rug'边际毛毯,颜色深浅代表数据多少。'kde'密度直线
plt.axvline(mean, color='g', linestyle=":", alpha=0.8)
plt.text(mean + 2, 0.005, 'salary_mean: %.1f元' %mean, color='g')
# 绘制平均工资辅助线
name = city + "_" + keyword + '_' + '工资分布直方图.png'
plt.savefig(name, dpi=300)
结果展示:
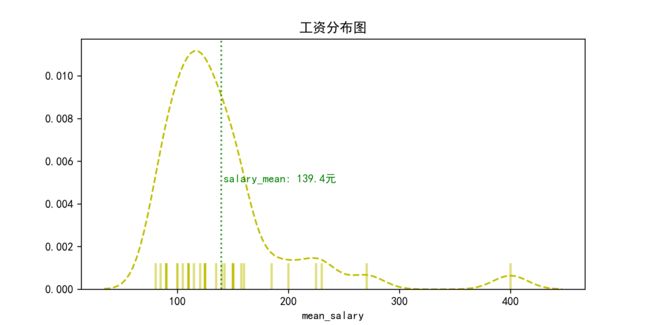
更多seaborn使用方法,可参考官方手册 serborn
6.代码优化
6.1 获取最大页数
因为提供了页数自定义,若输入数字远大于实际页数,产生不必要的数据请求和抓取,影响效率。

轻松发现,尾页的HTML格式固定,使用正则表达式即可
def get_mpage(response): #response为请求的初始页面
mpage = re.findall('.*?p=(\d+)">尾页.*?',response)[0]
return int(mpage)
# 对pages进行判断,取两者较小值
mpage = get_mpage(response)
if pages >= mpage:
pages = mpage
6.2 进度显示
在爬取数据量较大时,代码运行时间较长,心里没有底这时急需一个进度条一般的交互方式来提示运行进度。
这里我们选取了tqdm库,下面为tqdm库的简单用法
from tqdm import tqdm
for i in range(100000):
print()
实际应用如下:
from tqdm import tqdm
for i in tqdm(range(pages)):
# 获取该页中的所有职位信息,写入csv文件
i = i + 1
response = get_one_page(cityid, keyword, i)
hrefs = get_detail_pageinfo(response)
for href in hrefs:
n += 1
response_detail = get_detail_page(href)
items = parse_detail_info(response_detail)
pattern = re.compile(r'[一-龥]+') # 清除除文字外的所有字符
data = re.findall(pattern, items['job_detail']) # 清洗符号,方便热词统计
write_txt_file(txt_filename, ''.join(data)) # 不能直接写data,此时的data是列表格式
write_csv_rows(csv_filename, headers, items)
print('已录入 %d 条数据' % n)

其中print()代码可以省略,这里是由于样本量较小故多加一步显示,实质上输出语句运行很慢,影响效率,依个人喜好是否删减。
6.3 城市编码转化
由于实习僧对地区城市分别进行了编码,不清楚编码的小伙伴在使用时很麻烦。所以我又写了一个小爬虫,把城市编码抓取下来并形成一个json文件方便提取。
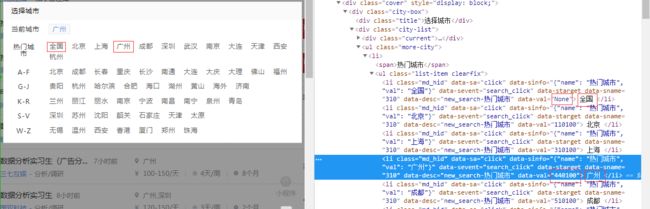
注意注意:这里的“全国”地区编码是字符串格式的“None”,并不是真正的“None”不存在。
小爬虫完整代码如下:
import requests
import json
from bs4 import BeautifulSoup
def main():
url = 'https://www.shixiseng.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3423.2 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9'
}
response = requests.get(url = url, headers = headers).text
soup = BeautifulSoup(response , 'lxml')
info = soup.find_all(class_='list-item clearfix')
# 城市编码以热门城市,和城市拼音两种方法,逐个抓取即可。
cityid_list = {}
hot_city = info[0].find_all(class_='md_hid')
for i in hot_city:
city = i.get_text().strip()# 注意城市名旁边的空格字符,容易被坑
cityid = i['data-val']
cityid_list[city] = cityid
a_f = info[1].find_all(class_='md_hid')
for a in a_f:
city = a.get_text().strip()
cityid = a['data-val']
cityid_list[city] = cityid
g_j = info[2].find_all(class_='md_hid')
for g in g_j:
city = g.get_text().strip()
cityid = g['data-val']
cityid_list[city] = cityid
k_r = info[3].find_all(class_='md_hid')
for k in k_r:
city = k.get_text().strip()
cityid = k['data-val']
cityid_list[city] = cityid
s_v = info[3].find_all(class_='md_hid')
for s in s_v:
city = s.get_text().strip()
cityid = s['data-val']
cityid_list[city] = cityid
w_z = info[3].find_all(class_='md_hid')
for w in w_z:
city = w.get_text().strip()
cityid = w['data-val']
cityid_list[city] = cityid
data = json.dumps(cityid_list) # 转成json格式
f = open('cityid_list.json', 'w', encoding='utf8')
f.write(data)
f.close()
if __name__ == '__main__':
main()
为了使代码文件更具独立性,这里没有直接把代码融入项目的主代码。依个人喜好,可以直接生成城市编号列表后,import这个.py文件,达到引用效果。又或者写在主代码的一个函数内,直接引用。
7. 完整代码
import re
import csv
import requests
import jieba
import json
import numpy as np
import pandas as pd
from tqdm import tqdm
from scipy.misc import imread
from bs4 import BeautifulSoup
from wordcloud import WordCloud, ImageColorGenerator
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
# 不发出警告
def get_one_page(cityid, keyword, pages):
# 获取网页html内容并返回
paras = {
'k': keyword,
'p': pages
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3423.2 Safari/537.36',
'Host': 'www.shixiseng.com',
'Referer': 'https://www.shixiseng.com/gz',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9'
}
url = 'https://www.shixiseng.com/interns/c-{}_?'.format(cityid)
# 获取网页内容,返回html数据
response = requests.get(url, headers=headers, params=paras)
# 通过状态码判断是否获取成功
if response.status_code == 200:
return response.text
return None
def get_mpage(response):
mpage = re.findall('.*?p=(\d+)">尾页.*?',response)[0]
return int(mpage)
def get_detail_pageinfo(response):
hrefs = re.findall('.*?= 4:
lst.append('violet')
plt.axis('equal') # 保证长宽相等
plt.pie(s['job'],
labels=s.index,
colors=lst,
autopct='%.2f%%',
pctdistance=0.5,
labeldistance=0.8,
startangle=0,
radius=1.3)
name = city + "_" + keyword + '_' + '学历分布饼图.png'
plt.savefig(name, dpi=300)
def salary_hist(data, city, keyword):
data['low_salary'] = data['salary'].str.strip('/天').str.split('-').str[0]
data['high_salary'] = data['salary'].str.strip('/天').str.split('-').str[1]
data['mean_salary'] = ( data['low_salary'].astype(np.int) + data['high_salary'].astype(np.int) ) / 2
s = data['mean_salary']
mean = s.mean()
plt.figure(figsize=(8, 4)) # 设置作图大小
plt.title('工资分布图') # 图名
plt.xlabel('salary') # x轴标签
sns.distplot(s, hist=False, kde=True, rug=True,
rug_kws={'color': 'y', 'lw': 2, 'alpha': 0.5, 'height': 0.1}, # 设置数据频率分布颜色
kde_kws={"color": "y", "lw": 1.5, 'linestyle': '--'}) # 设置密度曲线颜色,线宽,标注、线形
plt.axvline(mean, color='g', linestyle=":", alpha=0.8)
plt.text(mean + 2, 0.005, 'salary_mean: %.1f元' %mean, color='g')
# 绘制平均工资辅助线
name = city + "_" + keyword + '_' + '工资分布直方图.png'
plt.savefig(name, dpi=300)
def main(city, keyword, pages):
f_cityid = open('cityid_list.json','r', encoding ='utf8')
data_id = f_cityid.read()
data_id = json.loads(data_id)
cityid = data_id[city]
csv_filename = 'sxs' + city +'_' +keyword +'.csv'
txt_filename = 'sxs' + city + '_' + keyword + '.txt'
headers = ['job','salary','city','education','workday','worktime','job_good','job_detail',
'company_pic','company_name','company_scale','company_class']
write_csv_headers(csv_filename, headers)
n = 0
response = get_one_page(cityid, keyword, 1)
mpage = get_mpage(response)
if pages >= mpage:
pages = mpage
for i in tqdm(range(pages)):
# 获取该页中的所有职位信息,写入csv文件
i = i + 1
response = get_one_page(cityid, keyword, i)
hrefs = get_detail_pageinfo(response)
for href in hrefs:
n += 1
response_detail = get_detail_page(href)
items = parse_detail_info(response_detail)
pattern = re.compile(r'[一-龥]+') # 清除除文字外的所有字符
data = re.findall(pattern, items['job_detail'])
write_txt_file(txt_filename, ''.join(data)) # 不能直接写data,此时的data是列表格式
write_csv_rows(csv_filename, headers, items)
print('已录入 %d 条数据' % n)
content = read_txt_file(txt_filename)
segment = jieba.lcut(content)
words_df = pd.DataFrame({'segment': segment})
wordcloud(words_df, keyword, city)
data_csv = read_scv(csv_filename)
education_pie(data_csv, city, keyword)
salary_hist(data_csv, city, keyword)
if __name__ == '__main__':
# 手动输入解密映射,需要时自助更新
mapping = {'': '0', '': '1', '': '2', '': '3', '': '4',
'': '5', '': '6', '': '7', '': '8', '': '9'}
main('广州', '数据分析', 6)
'''
注意:
1、main()参数输入
第一个参数 :工作城市(小城市搜索不到会报错,可查看 cityid_list 文档里可搜索的城市)
第二个参数 :岗位关键词
第三个参数 :爬取的岗位网页页数,一页有10个岗位信息
2、云图热词背景图
可更换图片,注意图片名字不变
3、停止词
云图生成的热词经过‘stopwords’过滤掉不必要的词语,可按需要自助添加删减
'''
最后结果运行即为文章开头所示,在当前.py文件的目录下生成文件。
8. 干货奉献
1、项目文件:全都放在本人的github里,欢迎多多指点讨论
2、anaconda:是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项。更集成了jupyter nootbook,spyder等实用IDE。若先前没有下载Python,可选择附带下载。觉得官网安装过于缓慢的,可以在清华大学开源软件镜像站进行下载。
下载自带conda,效果同pip,在第三方库安装失败是可查看此攻略:
Anaconda找包,安装包时,遇到PackageNotFoundError: ''Package missing in current channels"
3、Pycharm:PyCharm是一种Python IDE,带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制。(这里安利一波,良心公众号“软件安装管家”,多种无毒破解软件,更有超小白安装教程。多次被拯救的我不得不服d(´ω`*))
4、第三方库安装:
https://www.lfd.uci.edu/~gohlke/pythonlibs/
https://pypi.tuna.tsinghua.edu.cn/simple/
通过pip,conda无法直接下载的,可以通过以上两个网站,Ctrl+F,找到所需库文件,安装下载
文章总结:
文章用Python抓取了实习僧网站上的职位数据,并作出简单图表分析当前就职环境。其中,实习僧的加密困扰了我很久,最后以一种比较简朴的方法解决,部分文字仍未处理。
文章对数据挖掘利用较浅,代码运行速度也是一大问题,可考虑多线程多进程优化处理。学术尚浅,希望仍可帮到一丝看到本文的你。