《 Acquiring High-Fidelity 3D Avatar from a Single Image》笔记
摘要
本文提出一种,从单个图像生成,具有高分辨率UV纹理贴图的,高保真的,3D面部头像的方法。为了评估人脸的几何形状,我们使用深度神经网络直接根据给定的图像,预测3D人脸模型的顶点坐标。通过非刚性变形过程进一步完善了3D面部几何形状,以便在纹理投影之前更准确地捕获面部标志。文章方法的关键新颖之处在于,在使用高质量渲染引擎综合生成的面部图像上训练形状回归网络。此外,作者形状估算器,充分利用了,从数百万张面部图像中学到的,深度面部识别功能的辨别力。作者进行了广泛的实验,以证明优化2D到3D渲染方法的优越性,尤其是其在现实世界中自拍图像上的出色泛化特性。作者提出的从2D图像渲染3D化身的系统具有广泛的应用范围,从虚拟/增强现实(VR / AR)和望远镜技术到人机交互和社交网络。
--------------------------------------这是注释-------------------------------------------
关于UV纹理贴图:
1、SketchUV(UV贴图工具)是SketchUp里面一个贴图插件。
2、UVW贴图一般都是贴图坐标丢失时使用,也可以用在自己想把贴图位置详细设置的时候使用。因为贴图一般是平面的,所以贴图坐标一般只用到UV两项,W项很少用到。大家常说的要调整UV坐标,实际就是调整贴图在模型上的位置。
投影贴图,球形贴图,柱形贴图,Box贴图,四边面贴图,路径贴图;
非刚性变形(non-rigid deformation)
只有物体的位置(平移变换)和朝向(旋转变换)发生改变,而形状不变,得到的变换称为刚性变换。非刚性变换就是比这更复杂的变换,如伸缩,仿射,透射,多项式等一些比较复杂的变换。
例如:ps中自由变换命令里面的斜切、扭曲、透视这些功能就属于非刚性变换
-------------------------------------------------------------------------------------------------------------------------------------
1. Introduction
在许多视觉应用程序中,包括VR / AR,电话会议,虚拟试戴,计算机游戏,特效等,获取高质量3D化身是一项基本任务。大多数专业制作工作室采用的一种常见做法是,由熟练的艺术家根据3D扫描或照片参考手动创建化身。由于每个模型都需要数天的人工处理和润色,因此此过程通常很耗时且人工密集。期望通过利用计算机视觉/图形和图像/几何处理中的快速发展来自动化3D化身生成的过程。
开发用于从单个图像生成3D化身的全自动系统很具有挑战性,因为面部形状和纹理贴图的估计都涉及光,形状和表面材料的本质上模糊的组成。传统的智慧试图通过逆向渲染来解决这个问题,逆向渲染将图像分解位置公式化为优化问题,并估计最适合观察图像的参数。但是,这些现有方法通常会假设将照明,阴影和皮肤表面模型过度简化(over-simplifified),这些模型并没有考虑到现实世界中的复杂性(例如,表面下的散射,自闭(未理解,低头?)引起的阴影以及复杂的皮肤反射场 )。因此,恢复的3D化身通常不会如实反映图像中呈现的实际面孔。
为了面临这些困难,作者提出了一种新颖的半监督方法。在使用医疗级3D面部扫描仪收集和处理482次中性面部扫描后,作者使用形状增强并利用了高保真渲染引擎,从而创建大量逼真的面部图像。据作者所知,这项工作是首次利用照片级逼真的面部图像合成进行准确的面部形状的尝试。对于面部几何形状估计,作者建议首先提取在数百万个图像上训练的深层面部身份特征,该特征将每个面部编码为唯一的潜在表示,并对一般三维头部模型的顶点坐标进行回归。为了更好地捕获纹理投影的面部特征,通过联合优化相机固有的、头部姿态、面部表情和每个顶点的校正场,以非刚性的方式进一步重新细化顶点坐标。作者最终生成的模型包括一个具有低多边形数的形状模型,但具有清晰细节的高分辨率纹理贴图,即使在移动设备上也可以有效地渲染(如图1所示)。
接下来对比了一些其他方法的3D AVATARS,优缺点。
文章的主要贡献可以总结如下:
- •一种用于从单个图像生成高保真UV纹理3D化身的系统,即使在移动设备上,也可以实时有效地对其进行渲染。
- •通过使用预先训练的深度面部识别功能,在合成照片逼真的图像上训练形状估计器。 训练完成的网络在真实世界的图像上展现出出色的图像生成特性。
- •相对于其他最新的面部造型技术,对所提方法进行了广泛的定性和定量评估,证明了其优越性(即更高的形状相似性和纹理分辨率)。
2. Related Works
3D Face Representation.3D人脸表示
Fitting via Inverse Rendering.通过逆向渲染进行拟合
Supervised Shape Regression.监督形状回归
值得一提的是,许多基于CNN的方法在训练过程中都使用通过反向渲染估算的面部形状作为基本事实。
Unsupervised Learning.无监督学习。
Deep Facial Identity Feature.。深度面部识别功能
3. Proposed Method
3.1. Overview
为了人脸图像的合成(3.2节),为了训练形状回归神经网络(3.3节),我们收集并处理了一个优先级的3D人脸数据集,我们可以从该数据集中提取带有UV纹理的增强3D人脸形状样本,以呈现大量逼真的人脸图像。在测试过程中,首先使用输入图像直接回归具有给定拓扑的3D面部模型的3D顶点坐标,然后进一步对其进行精炼以使其适合每个顶点非刚性变形方法的输入图像(3.4)。精确拟合后,自拍纹理将投射到UV空间以推断出完整的纹理图(第3.5节)。
3.2. Photo-Realistic Facial Synthesis( 逼真的面部合成)
3D Scan Database
使用最广泛的 Basel Face Model 巴塞尔面部模型(BFM)有两个主要缺点。首先,它由200名受试者组成,但主要是白人,这可能导致面部形状估计有偏差。其次,每个面都由具有高多边形数,每个顶点纹理外观和仅正面的密集模型表示,这限制了其在生产级实时渲染中的使用。
使用包含2925个顶点的头部模型和大小为2048×2048的漫反射贴图的面部表示。我们采用非刚性对齐方法[8]来变形通用头部模型以匹配捕获的面部扫描。 然后,将纹理转移到通用模型的UV空间中。通过进一步的手动艺术修饰,我们获得了最终的高保真扩散贴图。
Shape Augmentation(形状增强)
482位受试者远远不足以涵盖所有可能的面部形状变化。 虽然收集数千个高质量的面部扫描非常昂贵,但我们采用了另一种形状增强方法来提高训练后的神经网络的泛化能力。首先,我们采用最近的一个变形方法表示(DR)[46,13]对3D面部网格P建模。DR功能将第i个顶点Pi = [Pix,Piy,Piz]编码为R9向量。因此,整个网格的DR特征表示为向量D∈R | P |×9。
请参阅有关如何从P计算DR特征D的补充材料,反之亦然。(应该是在附录里)
在获得一组(D1,...,DN)的DR特征后,其中N是对象的总数,我们遵循[21]来采样新的DR特征。更具体地说,我们在极坐标中采样一个向量(r,θ1,...,θm1),其中r观察到均匀分布U [0.6,1.3],θi遵循均匀分布U [0,π/ 2]。我们计算其对应的笛卡尔坐标(a1,a2,...,am),并将所采样的DR特征插值为公式,从中进一步计算对应的面部网格。
在我们的实验中,我们使用m = 5,并且仅从相同性别和种族中选择样本。 我们生成了10,000个新的3D面孔,其中亚洲/白种人/黑人的比例为0.65 / 0.30 / 0.05,男性/女性的比例为0.5 / 0.5。 对于每个新采样的面孔,我们通过选择现有482个对象中,相同种族和性别的,最接近的3D面孔,来分配其UV纹理。
Synthetic Rendering.(合成渲染)
我们使用现成的高质量渲染引擎V-ray 2。在artistic的帮助下,我们建立了一个着色图来渲染照片真实的面部图像,给出了一个自定义漫反射贴图和一个通用的高光贴图。我们手动设置30种不同的光照条件,并进一步随机调整头的旋转度[[15°,+ 15°]的横摇,偏航和俯仰。渲染图像的背景是随机的,有大量的室内和室外图像。我们选择不渲染眼睛模型,并掩盖了眼睛区域,当测试时使用检测到的本地眼睛特征。
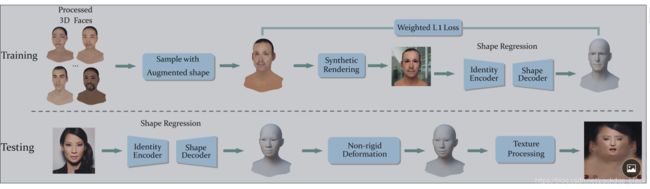
fig2:在训练期间,我们会在逼真的合成人脸图像上学习形状回归神经网络。 在测试过程中,我们使用从投影纹理生成的UV扩散贴图来推断低多边形数形状模型。
3.3. Regressing Vertex Coordinates(回归顶点坐标)
我们的形状回归网络由特征编码器和形状解码器组成。深层面部识别功能以其在各种条件下(例如光照,头部姿势和面部表情)的鲁棒性而闻名,为编码后的功能自然提供了理想的选择。尽管任何现成的面部识别网络都足以满足我们的任务,但我们建议采用Light CNN-29V2 [47],因为它在网络大小和编码效率之间具有良好的平衡性。预训练的Light CNN-29V2模型用于将输入图像编码为256维(?)特征向量。我们使用了加权的每个顶点L1损失(L1 loss):面部区域的顶点权重为5(距鼻尖半径为95mm以内),其他顶点的权重为1。
对于形状解码器,我们使用了三个全连接的(FC)层,其输出大小分别为128、200和8,775。最后一个FC层直接预测由2,925个点组成的通用头部模型的级联顶点坐标,并使用200个预先计算的PCA组件进行初始化,解释了在10,000个增强3D面部形状中观察到的超过99%的方差。与无监督学习相比[16],我们对高质量优先3D面部扫描数据集的可访问性,使通过监督获得更高的准确性成为可能。
3.4. Non-rigid Deformation( 非刚性变形)
由形状回归神经网络生成的3D顶点坐标不适用于纹理投影,因为面部图像通常包含未知因素,例如相机固有,头部姿势和面部表情。同时,由于形状回归预测了整体面部形状,因此无法准确地重建眼睛,鼻子和嘴巴等局部部位; 但是当与原始人脸图像进行比较时,它们对于质量感知还是很重要。我们建议利用以从粗糙到精细的方式,来检测到的人脸标志,并将非刚性变形公式化为一个优化问题,来一起优化摄像机固有的,外部的,面部表情和每个顶点的校正场。
Problem Formulation.(问题表述)
为了处理面部表情,我们将在FaceWarehouse [8]中将表情blendshape模型转移到相同的头部拓扑中,并请艺术家协助{B1,B2,...,BM}。(没看懂这部分)
这一部分内容写在了论文的纸质材料上,最后的总结是,将上述的这些放在一起,我们可以通过p来表示总体参数化向量。
Landmark Term.
我们采用全局到局部方法进行面部特征定位。为了进行全局推断,我们首先检测到标准的68个面部标志,然后使用该初始估计来裁剪包括眼睛,鼻子和嘴巴在内的局部区域,即总共裁剪了4张图像。然后,我们对裁剪后的图像进行精细的局部推断(有关更多详细信息,请参见补充材料)。我们建议最小化3D模型上的预测地标与检测到的地标之间的距离。(中间隔了一段公式说明)我们在M上预选m并遵循滑动方案[7]在每次迭代时更新17个面部轮廓界标的重心坐标。
Corrective Field Regularization.(校正场正则化)
为了实现一个平滑且较小的每顶点校正域,我们结合了以下两个损失(loss),
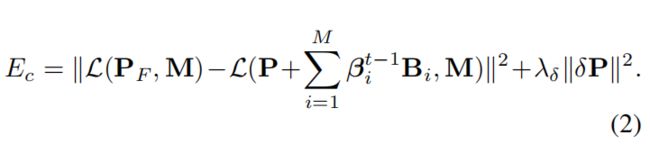
通过将拉普拉斯算子L保持在变形的网格上,第一个loss用于调整平滑变形(更多细节请参考[36])。 下面的那个是一个固定值,他来自上次的迭代结果,他表示估计的面部表情blendshape权重。
![]()
第二个loss用于强制执行较小的校正场,而λδ则用于平衡这两项。
Other Regularization Terms.
我们进一步规范了面部表情,焦距比例因子和相机外部的旋转分量,如下所示:
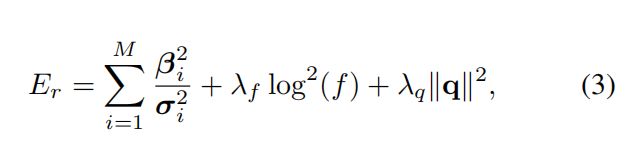
Summary.
所以总的损失函数就是:
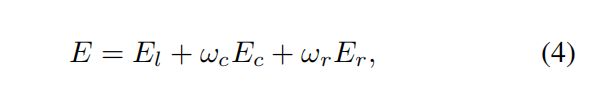
然后讲了各个数值初始化值和其有估计的方法。
3.5. Texture Processing(纹理处理)
在非刚性变形时,我们使用估计的摄像头固有时间,头部姿势,面部表情和每个顶点校正将自拍纹理 投影到通用模型的UV空间。通常,通常只有自拍上的前部区域可见,但我们使用482个subject中最接近查询subject之一的UV纹理来恢复其他区域(例如,头和颈的后部)的纹理。我们将贴近度定义为LightCNN-29V2嵌入之间距离的L1损失,即通过使用人脸识别。最后,给定前景投影的纹理和背景默认纹理,我们使用泊松图像编辑[30]混合它们。
4. Experimental Results
4.1. Implementation Details
对于形状回归,我们使用Adam优化器,其学习率为0.0001,并且500个时元的动量β1= 0.5,β2= 0.999。 我们训练了总共10,000个合成渲染的面部图像,批次大小为64。对于非刚性变形,我们总共使用N = 5次迭代。 当最小化公式(4)时,我们使用ωc= 25并且ωr= 10.在公式(2)中,我们设置λδ= 4,在公式(3)中,我们设置λf= 5和λq= 5。
4.2. Database and Evaluation Setup
Stirling/ ESRC 3D Faces Database(人脸数据库)
ESRC [12]是Di3D相机系统捕获的最新公共3D人脸数据库。该数据库还提供了在不同光照条件下从不同角度捕获的几幅图像。我们选择同时具有3D扫描和额中性面孔的受试者进行评估。 共有129名受试者(男性62位,女性67位)进行测试。 请注意,在此数据集中,大约95%的人是白种人。
JNU-Validation Database
JNU验证数据库是江南大学[25]收集的JNU 3D人脸数据库的一部分。它具有10个亚洲人的161张2D图像,以及3dMD捕获的3D面部扫描。由于在训练期间未使用验证数据库,因此我们将其视为亚洲人的测试数据库。 每个对象的2D图像在[3,26]范围内。 为了最大程度地减少不平衡数据的影响,我们选择每个主题的三个正面图像进行定量比较。
Our Test Data
由于没有可用于测试所有性别和种族的公共数据库,因此我们从表1的六个组中随机选择五个主题,并形成总共30个主题作为评估数据库。其他482次扫描用于几何和纹理的数据增强和训练/验证阶段。每个对象都有两张测试图像:由三星Galaxy S7拍摄的自拍图像和由摄影师从Sony a7R DSLR相机拍摄的图像。
Evaluation Setup
本文将他们的方法与包括3DMM-CNN [42],Extreme 3D Face(E3D)[43],PRNet [11],RingNet [32]和GanFit [14]在内的几种最新方法进行了比较。 每种方法的重构模型详细信息如表2所示。请注意,对于本文的方法和RingNet,在进行比较之前,都将眼睛,牙齿和舌头及其模型保持器移除。由于评估指标使用的是点到面误差,因此不相关的数据将增加总体误差。尽管删除这些部分也会稍微增加误差(例如,眼睛区域中没有可比较的数据),但引入的误差远小于直接使用原始模型的误差。
4.3. Quantitative Comparison
Evaluation Metric:(评估指标)
ground truth(?)
由于每种方法的拓扑都是固定的,因此首先使用七个预先选择的顶点索引来粗略地将重建的模型与ground truth情况对齐,然后通过迭代最近点(ICP)进一步完善模型[3]。鼻尖vt的顶点位置被选为ground truth和重建模型的中心。
ESRC and JNU-validation Dataset:
请注意,ESRC数据库提供的注释仅具有用于对齐的七个landmark,因此,我们不使用鼻尖,而是使用7个界标的平均值作为面部中心。在ESRC中,当d> 95时,我们的结果要优于其他方法,并且随着d的增加,我们的性能会更具弹性。 这表明我们的方法比其他方法可以更好地复制整个头部的形状。在JNU验证数据库中,由于其他方法是从白种人主导的3DMM模型中训练出来的,而在我们的增强阶段也考虑了其他种族,因此我们可以在每个d值处获得更小的重构误差。
Our Test Dataset:
4.4. Ablation Study
为了证明所提出方法中各个模块的有效性,我们一次修改一个变量,并与以下替代方法进行比较:
• No Augmentation (No-Aug):
在不进行任何增强的情况下,我们仅从482个对象中重复采样了10,000张脸。
• Categorized-PCA Sampling (C-PCA):
代替基于DR特征的采样,我们提出了一种基于PCA的采样方法。 我们训练了来自482位受试者的对象PCA模型,对于表1中的每个组,使用高斯随机向量x〜N(µi,Σ2i)来创建主要形状分量的权重,其中µi和Σ2i是均值向量, 组中这些系数的协方差矩阵。 我们使用这种增强方法对10,000张脸进行了采样
Game engine Rendering-Unity:
我们没有使用高质量的逼真的渲染器,而是使用标准游戏渲染引擎Unity来合成面部图像(关于游戏引擎应该是这篇文章里知道的最多的一部分了)。渲染图像的质量相对低于V射线。 我们保留了基于DR特征的增强方法,并完全渲染了3.2节中提到的10000个合成面。
在图6中,我们提出的方法胜过所有其他选择。 可以预期,如果不进行数据扩充(即No-Aug),则在所有方法中,重建的误差都是最严重的。C-PCA与我们的方法之间的差异证明,DR采样增强可创建更多自然的人工合成面部进行训练。 Unity与我们的方法之间的结果表明,renred图像的质量在弥合真实图像与合成图像之间的差距方面起着重要作用。
table2和fig4分别用不同方法比较了,文章内方法和其他方法之间的优劣性
4.4.1 Qualitative Comparison
图7与MoFA测试数据库中的最新技术并排显示了正面图像的形状估计方法。我们选择了GanFit [14]中显示的相同图像。 我们的方法可以创建准确的人脸几何形状,同时还可以捕获区分特征,从而使每个人脸的身份易于与其他人区分开。同时,如表2所示,我们的结果保持了较低的几何复杂度。 这使我们的化身即使在要求苛刻的情况下(例如在移动平台上)也可以投入生产。 在图8中,我们选择了一些名人来比较我们的方法的几何精度。在图9中,我们在第3.5节中用混合的漫反射图展示了最终结果。
5. Conclusions and Future Works
在本文中,我们演示了一种有监督的学习方法,用于通过逼真的高分辨率漫射贴图来估计高质量3D脸部形状。为了促进面部图像合成,我们已经收集并处理了3D面部数据库,从中我们可以使用UV纹理对增强的3D面部形状进行采样以渲染出大量逼真的面部图像。 与以前的方法不同,我们的方法利用了在数百万个合成的逼真的面部图像上训练的现成的面部识别神经网络的判别能力。
我们已经证明了该方法的可移植性,从准确的面部识别为目标,可以基于单个自拍照完全重建面部几何形状。在对合成生成的人脸图像进行训练时,我们在真实世界的图像上进行测试时观察到了强大的泛化能力。 这在许多有趣的应用程序中打开了机会,包括VR / AR,电话会议,虚拟试戴,计算机游戏,特效等等。
Supplemental Material
Section 3.2. Scan Pre-processing(扫描预处理)
如图10所示,我们处理原始的带纹理的3D面部扫描数据以生成我们的3D面部表示,该3D面部表示由具有低多边形数的形状模型和用于保留细节的高分辨率漫射贴图组成。

fig10:第一行:左侧是具有密集拓扑结构的原始面部扫描,右侧是具有UV纹理的模型; 下排:左侧是具有稀疏拓扑的处理过的面部模型,右侧是具有UV纹理的模型。
Section 3.2. Deformation Representation(变形表示)
在这里,我们给出变形表示(DR)功能的详细表述。 DR特征D将相对于参考网格PR的每个顶点周围的局部变形编码为R9向量。 我们将所有482个经过处理的面部模型的平均面部作为参考网格。
Encode D from P.
Recover P from D.
给定DR特征D和参考网格PR,我们首先恢复每个顶点的仿射变换Ti。 然后,我们尝试恢复最小化的最佳P:
Section 3.4. Landmark Localization
为了实现更高的地标定位精度,我们开发了一种从粗到精的方法。
首先,我们从检测到的面部边界框中预测所有面部标志。
然后,在获得初始地标的情况下,我们将眼睛,鼻子和嘴巴区域裁剪为第二阶段的小规模地标定位。 图11显示了我们的地标标记以及用于小规模地标定位阶段的边界框。
我们已经使用了基于回归森林的方法[24]作为基本的地标预测指标,并且总共训练了4个地标预测指标,即针对整体的面部,眼睛,鼻子和嘴巴。

图11:我们的地标性标记包括104个点,即面部轮廓(1-17),眉毛(18-27),左眼(28-47),右眼(48-67),鼻子(68) -84)和嘴巴(85-104)。
(a)粗略检测所有地标和相应的边界框,以进行精细尺度检测。
(b)单独的局部细尺度检测结果。
Section 4.4. Different Rendering Quality(不同的渲染质量)
在本节中,我们首先说明用于高质量Vray渲染的30种手动创建的照明条件,如图12所示。然后,我们提供从Vray和Unity渲染的几个合成人脸图像,如图13所示。 请注意,对于这两种渲染方法,我们随机化了头部姿势,环境图,照明条件和视场(FOV),以模拟现实世界中的自拍照。 我们不渲染眼睛模型,因此,如第3.2节所述,我们在测试期间用检测到的面部标志物遮盖了眼睛区域。
Section 4.5. More Qualitative Results
这里展示一些结果比较的图片
Application - Audio-driven Avatar Animation(应用程序-音频驱动的头像动画)
我们自动生成的头部模型已准备好用于不同的应用。 在这里,我们演示了一种由原始波形音频输入驱动的自动唇形同步的情况,如图21所示。对于数据收集和深度神经网络结构,我们采用与[23]相似的管道来驱动 重建模型。 所有动画混合形状都将转移到我们的通用拓扑中。 请参阅我们的视频以获取更多详细信息。