scikit-lean 随机森林代码学习--红酒
代码笔记
%matplotlib inline
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_wine
wine = load_wine()
from sklearn.model_selection import train_test_split
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data, wine.target, test_size = 0.3)
clf = DecisionTreeClassifier(random_state = 0)
rfc = RandomForestClassifier(random_state = 0)
clf = clf.fit(Xtrain, Ytrain)
rfc = rfc.fit(Xtrain, Ytrain)
score_c = clf.score(Xtest, Ytest)
score_r = rfc.score(Xtest, Ytest)
print("Single Tree:{}".format(score_c),
"Random Forest:{}".format(score_r))引入交叉验证评估效果
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
rfc = RandomForestClassifier(n_estimators=25)
rfc_s = cross_val_score(rfc, wine.data, wine.target,cv=10)
clf = DecisionTreeClassifier()
clf_s = cross_val_score(clf, wine.data, wine.target, cv=10)
plt.plot(range(1,11),rfc_s, label = "RandomForest")
plt.plot(range(1,11),clf_s, label="DecisionTree")
plt.legend()
plt.show()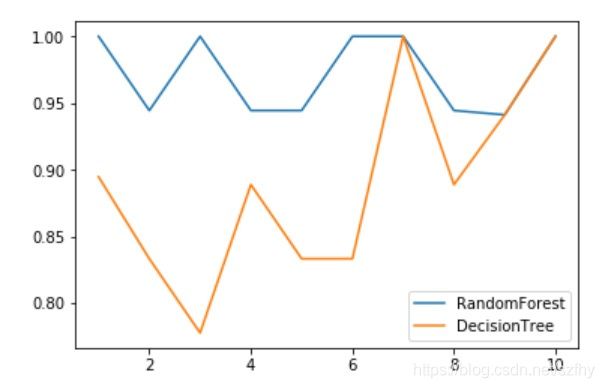
调参
#n_estimators 能建多少颗树,越多,效果越好,但是计算量也跟着变大,这个数是调参的重点
rfc_l = []
clf_l = []
for i in range(10):
rfc = RandomForestClassifier(n_estimators=25)
rfc_s = cross_val_score(rfc, wine.data, wine.target,cv=10).mean()
rfc_l.append(rfc_s)
clf = DecisionTreeClassifier()
clf_s = cross_val_score(clf, wine.data, wine.target,cv=10).mean()
clf_l.append(clf_s)
plt.plot(range(1,11), rfc_l, label="RandomForest")
plt.plot(range(1,11), clf_l, label="DecisionTree")
plt.legend()
plt.show()
superpa = []
for i in range(200):
rfc = RandomForestClassifier(n_estimators=i+1, n_jobs=-1)
rfc_s = cross_val_score(rfc, wine.data, wine.target, cv=10).mean()
superpa.append(rfc_s)
print(max(superpa), superpa.index(max(superpa)))
plt.figure(figsize=[20,5])
plt.plot(range(1,201),superpa)
plt.show()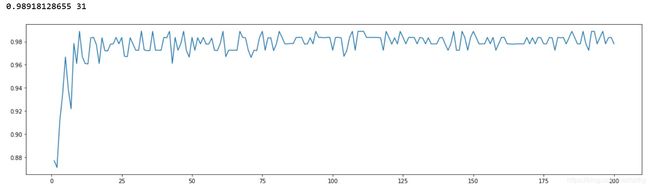
rfc = RandomForestClassifier(n_estimators=25)
rfc = rfc.fit(Xtrain, Ytrain)
rfc.estimators_
rfc.oob_score_
rfc.feature_importances_
rfc.apply(Xtest)
rfc.predict(Xtest)
rfc.predict_proba(Xtest)