python--基于RANSAC的图像全景拼接
在上一篇博客,介绍了图片映射的相关例子。但在操作中,由于噪声以及错误匹配的干扰,结果并不能让两张图片很好的拼接或者映射。

例如这两幅图,由于玻璃的反射角度,光等因素,造成了使用匹配子查找特征点时产生错误

如何解决这个问题呢?可以通过RANSAC方法来解决
一、RANSAC
RANSAC的全称是“RANdom SAmple Consensus(随机抽样一致)”。它可以从一组包含“局外点”的观测数据集中,通过迭代方式估计数学模型的参数。它是一种不确定的算法,也就是说它有一定的概率得出一个合理的结果,所以为了提高概率必须提高迭代次数。
(一)步骤
- 随机选择四对匹配特征
- 根据DLT计算单应矩阵 H (唯一解)
- 对所有匹配点,计算映射误差ε= ||pi’, H pi||
- 根据误差阈值,确定inliers(例如3-5像素)
- 针对最大inliers集合,重新计算单应矩阵 H
(二)示例
1.在给定若干二维空间中的点,求直线 y=ax+b ,使得该直线对空间点的拟合误差最小。

2.随机选择两个点,根据这两个点构造直线,再计算剩余点到该直线的距离
给定阈值(距离小于设置的阈值的点为inliers),计算inliers数量

3.再随机选取两个点,同样计算inliers数量

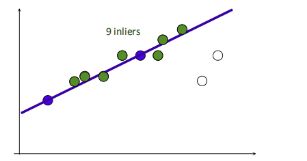
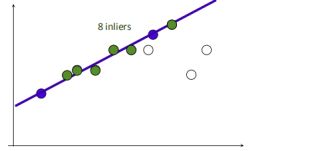
4.循环迭代,其中inliers最大的点集即为最大一致集,最后将该最大一致集里面的点利用最小二乘拟合出一条直线。
(三)参数
在上面原理介绍中,有两个重要的参数需要设置,即采样次数和阈值。
当数据过大的时候,若采集所有样本会造成算法复杂度过高,计算难度加大。Fischler和Bolles通过概率统计的方法得出了采样次数与数据中外点比例和得到一个好样本概率之间的数学关系

其中K为需要采样的次数,z为获取一个好样本的概率,一般设为99%;w为点集中inliers的比例,一般可以在初始时设置一个较小值,如0.1,然后迭代更新;n为模型参数估计需要的最小点个数,通常设置为2,直线拟合最少需要2个点。
阈值一般根据经验来设定,当观测误差符合0均值和sigma标准差的高斯分布时,则可以计算距离阈值。当inliers被接受的概率为95%时,阈值t2=3.84σ2。
(四)特点
RANSAC只能从特定的数据集中估计出一个模型,如果存在两个(或多个)模型,RANSAC则不能找到别的模型。
优点:能鲁棒的估计模型参数,能从包含大量局外点的数据集中估计出高精度的参数
缺点:它计算参数的迭代次数没有上限,如果设置迭代次数的上限,得到的结果可能不是最优的结果,甚至可能得到错误的结果
(五)使用RANSAC算法匹配


RANSAC算法只能描述同一平面的问题。当特征匹配对处于不同平面时,特征匹配则不同。
二、APAP
在图像拼接融合的过程中,受客观因素的影响,拼接融合后的图像可能会存在“鬼影现象”以及图像间过度不连续等问题。下图就是图像拼接的一种“鬼影现象”。解决鬼影现象可以采用APAP算法。

算法流程:
1.提取两张图片的sift特征点
2.对两张图片的特征点进行匹配
3.匹配后,使用RANSAC算法进行特征点对的筛选,排除错误点。筛选后的特征点基本能够一一对应。
4.使用DLT算法,将剩下的特征点对进行透视变换矩阵的估计。
5.因为得到的透视变换矩阵是基于全局特征点对进行的,即一个刚性的单应性矩阵完成配准。为提高配准的精度,Apap将图像切割成无数多个小方块,对每个小方块进行单应性矩阵变换。

三、最小割问题(最大流问题)–找拼接缝

当两张图像拼接完成后,可能会出现上图的情况:两张图像之间的过度不连续,也就是存在拼接缝隙,拼接线两侧的灰度变化较为明显。最小割问题可以解决这个问题
(一)最小割问题
割是网络中定点的一个划分,它把网络中的所有顶点划分成两个顶点集合S和T,其中源点s∈S,汇点t∈T。记为CUT(S,T),满足条件的从S到T的最小割(Min cut)。
在有向图所有的割中,边权值和最小的割为最小割。也就是说,在最小割位置,A,B两幅图在当前像素点差别最小。

(二)最大流问题
给定指定的一个有向图,其中有两个特殊的点源S和汇源T,每条边有权值,为正,也叫容量,求满足条件的从S到T的最大流(MaxFlow)。如下图

可以将这个模型想象成水管模型,比如你家是汇,自来水厂是源;自来水厂和你家之间修了很多条水管通道接在一起,由于水管通道的规格不一样大,有的流经水的容量大,有的比较小;
那么自来水厂开闸放水,你家收到水的最大流量是多少?如果自来水厂停水了,你家的流量就是0,但是这不是最大的流量。那个如果自来水厂一直往通道里放水,那么你家的流量也就变多了,此时会达到最大流。
当然在这个模型中,有一个前提条件flow小于等于capacity 不然水管就爆了。
再考虑任意一个节点 流入量总是等于流出的量,否则就会蓄水,或者平白无故多出水。
因此得出有以下性质:
一个st-flow(简称flow)是为每条边附一个值,这个值需要满足两个条件
1 、0<=边的flow <<边的capacity
2、除了s和t外,每个顶点的inflow要等于outflow
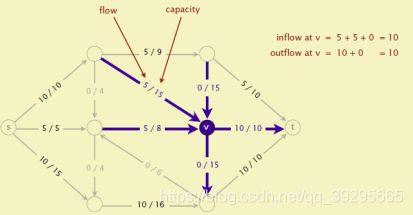
一个flow的值就是t的inflow.Maxflow我们的目标就是找到这个最大值。
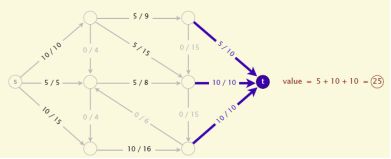
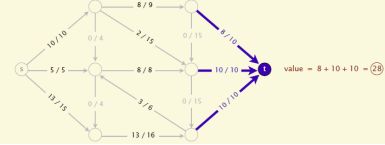
那么如何求解呢,下面介绍一种最短路径增广算法 简称EK算法
(三)EK算法
EK算法基于一个基本的方法:Ford-Fulkerson方法 即增广路方法 简称FF方法,增广路方法是很多网络流算法的基础。
思路是每次找出一条从源到汇的能够增加流的路径,调整流值和残留网络,不断调整,直到没有增广路为止。也就是说不断地找一条增广路径,然后算出这个增广路径里的最小允许通过的流,然后在s上加入这个流量。不断小心翼翼地加入流量,使之最终饱和。
FF方法的基础是增广路定理:网络达到最大流当且仅当残留网络中没有增广路。这里需要注意的是,如果无残差图就可能无法找到最优解
EK算法就是不断的找最短路 找的方法就是每次找一条边数最少的增广 也就是最短路径增广
增广路算法好比是自来水公司不断的往水管网里一条一条的通水
参考:https://blog.csdn.net/zitian246/article/details/76218020
求解过程:
(1)初始化,所有边的flow都初始化为0

(2)沿着增广路径增加flow。增广路径是一条从s到t的无向路径,可以经过没有满容量的前向路径(s到t)或者是不为空的反向路径(t->s)
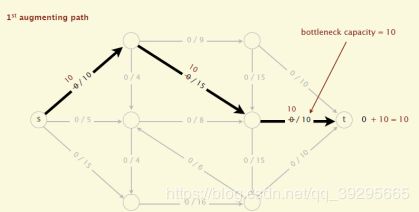
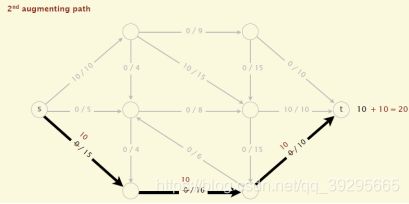

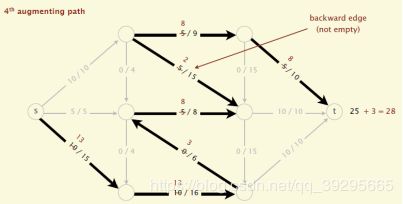

现在,我们可以引出一条定理:
增广路径定理:一个流f是最大流当且仅当没有增广路径。
这样每次增广的复杂度为O(E),EK算法的总复杂度就是O(VE^2)
四、multi-band bleing
在找完拼接缝后,由于图像噪声、光照、曝光度、模型匹配误差等因素,直接进行图像合成会在图像重叠区域的拼接处出现比较明显的边痕迹。

这些边痕迹需要使用图像融合算法来消除。这里介绍一种方法—multi-band bleing
思想:采用的方法是直接对带拼接的两个图片进行拉普拉斯金字塔分解,后一半对前一半进行融合。
步骤:
(1)首先计算当前待拼接图像和已合成图像的重叠部分。并对图像A、B 重叠部分进行高斯金字塔和拉普拉斯金字塔分解
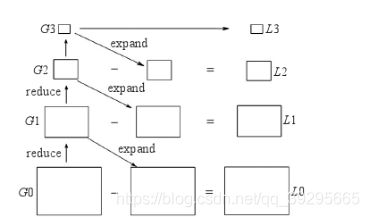
G0为原始图像,G1表示对G0做reduce操作。Reduce操作定义如下:

对G1进行扩展后与G0相减,可以得到拉普拉斯金字塔的第一层L0。同理,拉普拉斯金字塔的L2、L3等层也可以按照这种方法来计算。
两幅图像的融合过程:分别构建图像A、B的高斯金字塔和拉普拉斯金字塔,然后进行加权融合。

其中,LA0LA3为图像A的拉普拉斯金字塔,LB1LB3为图像B的拉普拉斯金字塔。
(2)对加权后的拉普拉斯金字塔进行重构

最后得到的LS0*就是重叠区域的像素值。
五、实验结果
# ch3_panorama_test.py
from pylab import *
from numpy import *
from PIL import Image
# If you have PCV installed, these imports should work
from PCV.geometry import homography, warp
from PCV.localdescriptors import sift
import os
root=os.getcwd()+"\\"
"""
This is the panorama example from section 3.3.
"""
# set paths to data folder
featname = ['../data/wanren/uu' + str(i + 1) + '.sift' for i in range(5)]
imname = ['../data/wanren/uu' + str(i + 1) + '.jpg' for i in range(5)]
# extract features and match
l = {}
d = {}
for i in range(5):
sift.process_image(root+imname[i], root+featname[i])
l[i], d[i] = sift.read_features_from_file(featname[i])
matches = {}
for i in range(4):
matches[i] = sift.match(d[i + 1], d[i])
# visualize the matches (Figure 3-11 in the book)
for i in range(4):
im1 = array(Image.open(imname[i]))
im2 = array(Image.open(imname[i + 1]))
figure()
sift.plot_matches(im2, im1, l[i + 1], l[i], matches[i], show_below=True)
# function to convert the matches to hom. points
def convert_points(j):
ndx = matches[j].nonzero()[0]
fp = homography.make_homog(l[j + 1][ndx, :2].T)
ndx2 = [int(matches[j][i]) for i in ndx]
tp = homography.make_homog(l[j][ndx2, :2].T)
# switch x and y - TODO this should move elsewhere
fp = vstack([fp[1], fp[0], fp[2]])
tp = vstack([tp[1], tp[0], tp[2]])
return fp, tp
# estimate the homographies
model = homography.RansacModel()
fp, tp = convert_points(1)
H_12 = homography.H_from_ransac(fp, tp, model)[0] # im 1 to 2
fp, tp = convert_points(0)
H_01 = homography.H_from_ransac(fp, tp, model)[0] # im 0 to 1
tp, fp = convert_points(2) # NB: reverse order
H_32 = homography.H_from_ransac(fp, tp, model)[0] # im 3 to 2
tp, fp = convert_points(3) # NB: reverse order
H_43 = homography.H_from_ransac(fp, tp, model)[0] # im 4 to 3
# warp the images
delta = 2000 # for padding and translation
im1 = array(Image.open(imname[1]), "uint8")
im2 = array(Image.open(imname[2]), "uint8")
im_12 = warp.panorama(H_12, im1, im2, delta, delta)
im1 = array(Image.open(imname[0]), "f")
im_02 = warp.panorama(dot(H_12, H_01), im1, im_12, delta, delta)
im1 = array(Image.open(imname[3]), "f")
im_32 = warp.panorama(H_32, im1, im_02, delta, delta)
im1 = array(Image.open(imname[4]), "f")
im_42 = warp.panorama(dot(H_32, H_43), im1, im_32, delta, 2 * delta)
figure()
imshow(array(im_42, "uint8"))
axis('off')
savefig("quanjing.png", dpi=300)
show()
实验数据1






实验结果:

这是第一次的运行结果,在反复调试后发现图片的顺序要从右边往左边排,因为算法的匹配是从最右边的图像计算出来的,代码中有一步骤是将对应的顺序进行颠倒,使其从左边图像开始进行扭曲。




结果分析:在这个实验结果中,光照较强,室外场景落差比较大,我们可以看出图片向内扭曲,且在5、6张图拼接的过程中有一条明显的拼接缝。图片拼接后出现扭曲是因为APAP算法是对每个小格做单应性变换,从单个小格看是没有特征的,所以拼接起来会出现扭曲的现象。
实验数据2:





实验结果:
在这里插入图片描述




结果分析:在这组数据中,室外落差比较小,运行的结果没有出现黑色区域。拼接的正确率达到80%以上,虽然大体拼接上了,在后两张的拼接上,同样发生了扭曲的现象。我认为,除了与算法本身有关的情况下,与拍摄角度也是有关系的。同时,拼接效果图上也出现了较为明显的拼接缝,由于两张图片曝光率相差过大,因此会更明显。
实验数据3:





实验结果:





结果分析:这张图中,左边出现了黑边,可能原因是后面几张图的光线较亮,前两张较暗,这样就导致存在一些光线的落差。另外,由于镜头拍照的位置不同,会导致图四和图五虽然有相同的拍摄区域,但是并不能简单的将两图的重叠区域覆盖进行拼接。