利用python对简书文章进行文本挖掘【词云/word2vec/LDA/t-SNE】
这是一个快速上手词云/word2vec/LDA/t-SNE的一个小例子,实践之后,可以让大家对这些方法有初步的了解。
以下代码在jupyter notebook中测试通过,代码请戳这里。
简单介绍下数据
简书有个简书交友的专题,某知名博主爬取了该专题2700余篇文章,我就偷个懒直接拿来用了~
数据呢,大概就是长这个样子了:
主要涵盖:作者,主页URL,文章标题,发布时间,阅读量,评论数,喜欢数,文章摘要,文章URL,文中图片URL列表,文章内容等等维度。
该demo实现目标
- 绘制文章词云
- 利用word2vec查找具有高相关性的词语,并绘图显示
- 利用LDA主题模型总结出每篇文章的主题词
提取出文章中的200个关键词绘制词云
光是提取关键字我知道的就有三种方法,分别是:
- 利用
counter.most_common()方法直接获取 jieba.analyse.extract_tags()jieba.analyse.textrank()
思路也是惊人的一致:
分词–》提取关键词–》利用WordCloud绘制词云
import warnings
# 忽略警告
warnings.filterwarnings('ignore')
content = df['Artical_Content'].tolist()
# 载入停用词
# quoting : int or csv.QUOTE_* instance, default 0
# 控制csv中的引号常量。可选 QUOTE_MINIMAL (0), QUOTE_ALL (1), QUOTE_NONNUMERIC (2) or QUOTE_NONE (3)
stopwords = pd.read_csv('./chinesestopword.txt',sep='\n',encoding='utf-8',names=['stopwords'],header=None,quoting=3)
# 结巴分词
import re
import jieba
from collections import Counter
pattern = re.compile('\d+')
# 存放词语和词频
wordsCounter = Counter()
for line in content:
segs = jieba.lcut(line)
for seg in segs:
if len(seg)>1 and seg != '\r\n' and re.search(pattern,seg)==None:
wordsCounter[seg] += 1
# 将Counter的键提取出来做list
segment = list(wordsCounter)
# 将分好的词列表转化为词典
words = pd.DataFrame({'segment':segment})
# 剔除停用词
words = words[~words['segment'].isin(stopwords['stopwords'])]
# 绘制词云
from pyecharts import WordCloud
def counter2list(_counter):
wordslist,nums = [],[]
for item in _counter:
wordslist.append(item[0])
nums.append(item[1])
return wordslist,nums
outputFile = './result/文章关键词词云图.html'
# 这个关键词抽取方法不唯一
wordslist,nums = counter2list(wordsCounter.most_common(1000))
cloud = WordCloud('文章关键词词云', width=1200, height=600, title_pos='center')
cloud.add(
' ',wordslist,nums,
shape='circle',
background_color='white',
max_words=1000
)
cloud.render(outputFile)

word2vec模型计算词的相似度
使用word2vec词向量,看看这些词语在向量空间中会是怎样分布的?
哪些词语会在相似的区域?
import jieba.analyse
# 基于TextRank算法进行关键词抽取
textrank2 = ' '.join(jieba.analyse.textrank(contentStr,topK=500,allowPOS=('ns','n')))
# 一定要先弄清楚模型需要的数据格式是什么,看官方文档!!!
# 利用word2vec找出关联词语,将语料整理成嵌套列表的形式
corpus = []
# 将停用词dataFrame转化为列表
stopwordsList = stopwords['stopwords'].tolist()
# print(stopwordsList[:10])
for line in content:
segs = jieba.lcut(line)
segs = filter(lambda x:len(x)>1, segs)
segs = filter(lambda x:re.search(pattern,x)==None, segs)
segs = filter(lambda x:x not in stopwordsList, segs)
corpus.append(list(segs))
# 训练模型
import multiprocessing
from gensim.models import Word2Vec
model = Word2Vec(corpus,min_count=20,sg=0,workers=multiprocessing.cpu_count())
# 查询和简书相关性比较高的词语
model.wv.most_similar(['简书'],topn=15)

t-SNE 可视化高维数据
t-SNE是目前最为流行的一种高维数据降维的算法
百度云API
点击上面的连接,然后阅读新手指南和python SDK文档就能上手了,非常简单~
但是我发现很多词并不能在这个API中找到对应词向量,所以我大胆推辞,因此会影响到效果~
t-SNE降维算法
一种有效的高维数据降维方法,如果你还不了解,请点击上面标题
# 调用百度云NLP进行词向量表示
from aip import AipNlp
APP_ID = '11617353'
API_KEY = 'eV2R48IOWKcLgBrZwtf0ZF7N'
SECRET_KEY = 'HHtuGb3BPGaXAguPld5r9gfrY4xCCdzh'
client = AipNlp(APP_ID, API_KEY, SECRET_KEY)
textrankList = textrank2.split(' ')
# 整理格式 原始格式:('简书', 0.9286492277441794) 后者是特征权重
import numpy as np
words_list = []
word_vectors = []
for word in textrankList:
try:
data = client.wordEmbedding(word)
word_vector = data['vec']
words_list.append(data['word'])
word_vectors.append(word_vector)
except:
print('No words:{}'.format(word))
word_vectors = np.array(word_vectors)
from sklearn.manifold import TSNE
import numpy as np
def plotTsne2D(word_vectors,words_list):
tsne = TSNE(n_components=2,random_state=0,n_iter=10000,perplexity=20)
# 在控制台输出过程中,默认小数会以科学计数法的形式输出,若不需要加上下面这句
np.set_printoptions(suppress=True)
T = tsne.fit_transform(word_vectors)
labels = wordslist
plt.figure(figsize=(14,10))
plt.scatter(T[:,0],T[:,1],c='blue',edgecolors='k')
for label,x,y in zip(labels,T[:,0],T[:,1]):
plt.annotate(label,xy=(x+1,y+1),xytext=(0,0),textcoords='offset points')
plotTsne2D(word_vectors,words_list)
虽然效果比较差,但是我们还是可以看出一些端倪的(红框处都是意思相近的词语),此处提取出的500个关键词,之前200个关键词效果更差。

LDA进行主题词提取
from gensim import corpora, models
from gensim.models.ldamodel import LdaModel
# for article in corpus:
dictionary = corpora.Dictionary(corpus)
# 将 dictionary 转化为一个词袋
common_corpus = [dictionary.doc2bow(text) for text in corpus]
tfidf = models.TfidfModel(common_corpus)
corpusTfidf = tfidf[common_corpus]
lda = LdaModel(corpusTfidf, num_topics=10, id2word = dictionary, passes=20)
results = lda.print_topics(num_topics=10, num_words=3)
for res in results:
print(res[1])

# 将LDA模型保存起来方便日后对新文章进行主题预测
lda.save('lda.model')
test = "生活是一座围城,但校园不是。校园是时光精心雕刻的礼物,里面到处有十几岁长发飘飘的女孩子,朝气执着的男孩子,有单纯追求的理想和生活,还有那些用心守候的友情爱情。秋天的梧桐树铺满教学楼的道路,在密密麻麻的习题中痴迷地偷看窗外的世界,静谧、自由;冬天的大雪来势汹汹,裹着厚棉袄走在冰封的湖边独自去上课,长大的世界只有自己可以取暖;春天,随着冰雪一起褪去的还有沉重的身心,但新的一年生活好像也没什么变化;夏天有吃不完的西瓜和冰棍,如果你可以和我一起逃课,我会告诉你后山夜晚的星星很美。提起校园,或许它并不精彩,重复到近乎单调,但我们都会无比怀念年轻的自己和那些有梦做的年纪。春天濛濛的细雨还没有离开大地,夏日离别的笙歌已在悄悄响起。又快到一年毕业季,「简书交友」专题携手「简书校园」、「简书会员」、「摄影」一起推出「恰同学少年」校园创作交友大赛。请将文章以以下形式投稿至「」专题、摄影作品可投稿至「」专题。本次活动设置了丰富的奖项和奖品,参赛内容可为小学到大学,培训学校等等你经历过的任何一个校园,校园必须为的大学,虚拟意义上的校园无法参赛,,所有简友仅需写出你曾经经历过的校园生活即可参赛。感谢对本次校园创作交友大赛的,除了提供奖金支持以外,还带来了八折的购买折扣。已是简书会员的简友参与本次比赛即可线上时长;所有参与本次比赛的简友均可获得购买简书会员的资格。详细会员权益请见:参加摄影奖的文章不参考文章质量,仅参考摄影作品,但建议对摄影作品加上一定的文字描述。片子必须原创,拒绝糊片,张数不限,可用snapseed、PS等软件修图,一旦发现盗图,永久取消参与简书活动的资格;一等奖一名:500元二等奖三名:200元三等奖五名:50元创作奖视文字部分内容而定,摄影仅做锦上添花的辅助说明。一等奖二名:1000元二等奖三名:500元三等奖五名:200元凡在本次比赛参与作品中找到同校同学,你们可以将自己的互相发布到彼此的文章,只要有五名以上的同校同学,你可以获得19元打赏。每人仅能获得一次且必须在自己的文章评论区集齐五名校友评论。收集齐后点击链接附上你的文章链接和校友评论楼层,通过验证即可获奖。登记地址:交友专题会对你提供的文章进行质量审核,单纯为了凑齐人数而没达到参赛标准的文章将被视为不符合规则。本次比赛人气最高的五篇文章和点赞人气前三的评论作者都可以获得人气奖,人气奖可与以上奖项重复获得。文章评分:0.4阅读量+0.3 评论数+0.3 点赞数,得分取前5名。人气奖奖品为:100元2018年3月27日-2018年4月20日,预计2018年5月上旬公布结果,获奖结果首发(微信号:jianshuio)。1.文章建议采用记叙性、回忆性散文、诗歌,校园生活和校园情,请勿全文叙述你的爱情(同理友情、师生情等等),不接受小说等虚构类作品;2.快速找到校友:点击列表找到自己的学校,或者点击联系负责人加入学校社群。结交校友可以100%获得。3.活动不局限于在校生参与,任何简友都可以写出你憧憬/经历过的校园生活;4.简书对所有参赛文章具有使用权,简书交友专题对活动具有最终解释权;「恰同学少年」校园创作交友大赛同步合作伙伴、引力说(微信号:GravityYLS)、清华帮(微信号:THU_bang)、小也电台(微信号:xiaoyeradio),获奖作品将同步发表在以上平台。加入简书第一步,添加简书交友官方微信群(已在前面九群的请不要重复添加)。"
test = jieba.lcut(test)
# 文档转换成bow
doc_bow = dictionary.doc2bow(test)
# 得到新文档的主题分布
doc_lda = lda[doc_bow]
type = doc_lda[1][0]
print(results[type][1])
测试语料属于这个主题
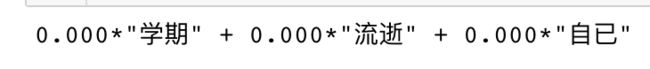
总结
收获
知识层面
===================================
- 了解了百度开源的NLP API
- 实践了word2vec计算词的相似度
- 了解t-SNE这个高维数据降维方法
- 之前实践失败的LDA主题模型,这次好像有点收获
工程层面
===================================
- jupyter notebook是个好东西
- 学会看官方文档,这是最好的学习渠道
- 出错,查错,别心急