美团Leaf源码——snowflake模式源码解析
前言
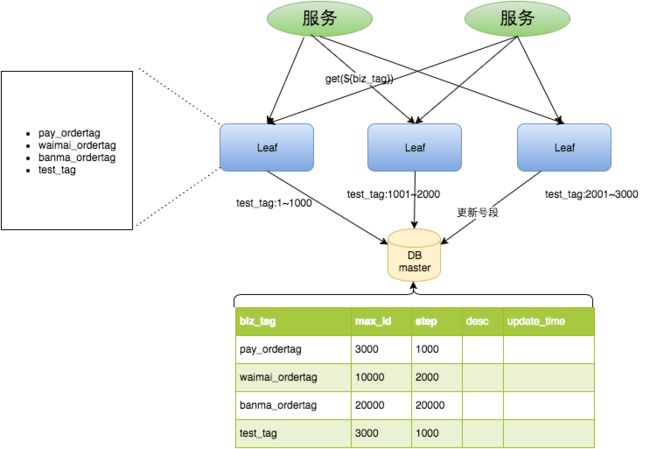
上一篇文章介绍了如何使用Leaf的号段模式生成分布式全局唯一id,参照下图我们简单总结一下。当我们部署Leaf集群时(图中是3个),每个节点起初都包含一个双 buffer,也就是双号段。当有请求过来时,每个节点都会去数据库查询按照初始的DB中的step去更新最大id,从而获取到一个号段,然后每个节点当第一个号段用到超过10%的时候再异步准备第二个号段。所以按照图中的理解可以认为左中右三个节点依次被调用请求test_tag业务对应的id,从而每个节点都获得到自己的号段,三个节点都按照step=1000去更新maxId,最后maxId表示已经分配最大的id为3000,接下来三个节点谁先用到超过10%就会再去异步准备另一个号段。等到请求量都达到10%之后,都会准备好双buffer,然后不断切换异步准备。
这次我们主要讨论snowflake模式的使用以及源码解析。本文的Leaf源码注释地址:https://github.com/MrSorrow/Leaf
I. 测试snowflake模式
「安装ZooKeeper」
这里选择Docker的方式快速搭建一个单机版的ZooKeeper,用于整合Leaf框架。
docker pull zookeeper:3.4
firewall-cmd --zone=public --add-port=2181/tcp --permanent
firewall-cmd --zone=public --add-port=2888/tcp --permanent
firewall-cmd --zone=public --add-port=3888/tcp --permanent
firewall-cmd --reload
docker run --name leaf-zookeeper --restart always -p 2181:2181 -e TZ=Asia/Shanghai -d zookeeper:3.4
可能会遇到 WARNING IPv4 forwarding is disabled. Networking will not work 错误,解决方法如下:
vi /usr/lib/sysctl.d/00-system.conf
# 添加上一行
net.ipv4.ip_forward=1
# 重启network服务
systemctl restart network
# 查看
sysctl net.ipv4.ip_forward
# 如果返回为“net.ipv4.ip_forward = 1”则表示成功了
「开启snowflake模式」
主要配置好最后的三项,开启snowflake模式,配置好zookeeper的地址和端口号。
leaf.name=com.sankuai.leaf.opensource.test
# 关闭号段模式
leaf.segment.enable=false
leaf.jdbc.url=jdbc:mysql://localhost:3306/leaf_test?useUnicode=true&characterEncoding=utf8&characterSetResults=utf8
leaf.jdbc.username=root
leaf.jdbc.password=1234
# 开启号段模式
leaf.snowflake.enable=true
leaf.snowflake.zk.address=192.168.2.113
leaf.snowflake.port=2181
「启动测试」
仍然和号段模式启动一样,点击启动 leaf-server 模块的 LeafServerApplication,将服务跑起来。

浏览器输入http://localhost:8080/api/snowflake/get/key来获取分布式递增id。或者通过命令行中 curl 方式进行测试。
wangguopingdeMacBook-Air:~ guoping$ curl http://localhost:8080/api/snowflake/get/key1
1128852519460536335
wangguopingdeMacBook-Air:~ guoping$ curl http://localhost:8080/api/snowflake/get/key1
1128852531322028054
wangguopingdeMacBook-Air:~ guoping$ curl http://localhost:8080/api/snowflake/get/key2
1128852655284682815
wangguopingdeMacBook-Air:~ guoping$ curl http://localhost:8080/api/snowflake/get/key2
1128852694715334657
我们将返回的id转换为十六进制数,可以确定 workerId 是 0,时间戳也确实在递增,自增序列却不是递增的,这在后面我们研究源码可以知道当时间戳一致才会自增,时间戳增大后,自增序列要“清零”重新开始自增。
1128852519460536335=0-00011111010101001111101011000101011001001-0000000000-000000001111
1128852531322028054=0-00011111010101001111101011001010111010101-0000000000-000000010110
1128852655284682815=0-00011111010101001111101100000100101001000-0000000000-000000111111
1128852694715334657=0-00011111010101001111101100010111000000001-0000000000-000000000001
按照snowflake算法的比特分配,我们将上述的id值转换成对应的形式。图中有些错误,最后自增序列是12位。

III. snowflake模式源码分析
有了号段模式源码的分析基础,我们对于整个项目的结构有了更加清晰的认识。调用snowflake模式下的Leaf服务,依然调用的是 LeafController 下的接口,然后Service层的实现则换成了 SnowflakeService,Service层依赖的ID生成器 IDGen 的实现类则是 SnowflakeIDGenImpl。
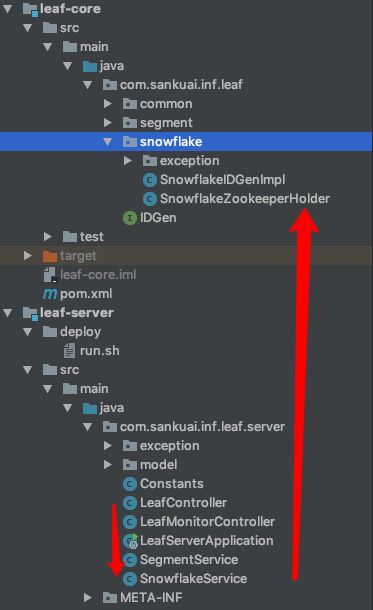
下面我们就来从LeafController 下的接口出发。
@Autowired
SnowflakeService snowflakeService;
/**
* snowflake模式获取id
* @param key 随便定义
* @return
*/
@RequestMapping(value = "/api/snowflake/get/{key}")
public String getSnowflakeID(@PathVariable("key") String key) {
return get(key, snowflakeService.getId(key));
}
可以看出核心方法调用的是 SnowflakeService 的 getId(key) 方法。
SnowflakeService
/**
* snowflake模式的service层
*/
@Service("SnowflakeService")
public class SnowflakeService {
private Logger logger = LoggerFactory.getLogger(SnowflakeService.class);
/**
* ID生成器
*/
IDGen idGen;
/**
* 构造函数,注入单例SnowflakeService时,完成以下几件事:
* 1. 加载leaf.properties配置文件解析配置
* 2. 创建snowflake模式ID生成器
* 3. 初始化ID生成器
* @throws InitException
*/
public SnowflakeService() throws InitException {
// 1. 加载leaf.properties配置文件解析配置
Properties properties = PropertyFactory.getProperties();
// 是否开启snowflake模式
boolean flag = Boolean.parseBoolean(properties.getProperty(Constants.LEAF_SNOWFLAKE_ENABLE, "true"));
if (flag) {
// 2. 创建snowflake模式ID生成器
String zkAddress = properties.getProperty(Constants.LEAF_SNOWFLAKE_ZK_ADDRESS);
int port = Integer.parseInt(properties.getProperty(Constants.LEAF_SNOWFLAKE_PORT));
idGen = new SnowflakeIDGenImpl(zkAddress, port);
// 3. 初始化ID生成器
if(idGen.init()) {
logger.info("Snowflake Service Init Successfully");
} else {
throw new InitException("Snowflake Service Init Fail");
}
} else {
// ZeroIDGen一直返回id=0
idGen = new ZeroIDGen();
logger.info("Zero ID Gen Service Init Successfully");
}
}
/**
* 通过ID生成器获得key对应的id
* @param key
* @return
*/
public Result getId(String key) {
return idGen.get(key);
}
}
SnowflakeService 的内容非常简单,其方法只有一个就是 getId(String key)。成员变量包含一个ID生成器,构造函数主要的目的就是创建并初始化这个ID生成器。
构造函数中,注入单例SnowflakeService时主要完成三件事:
- 加载
leaf.properties配置文件解析配置 - 创建snowflake模式ID生成器
- 初始化ID生成器
① 创建ID生成器
第一步加载 leaf.properties 配置文件解析zookeeper连接ip与port的相关配置信息就不用多描述了,和号段模式解析数据库连接配置如出一辙。
然后校验配置文件中是否打开了snowflake模式,如果打开了则创建 SnowflakeIDGenImpl 类型的ID生成器。我们查看 SnowflakeIDGenImpl 的构造函数。
/**
* snowflake模式ID生成器
*/
public class SnowflakeIDGenImpl implements IDGen {
·········
/**
* 保存该节点的workId
*/
private long workerId;
/**
* 是否初始化完成,也就标记着是否get到workID
*/
public boolean initFlag = false;
/**
* zk的端口号
*/
private int port;
public SnowflakeIDGenImpl(String zkAddress, int port) {
this.port = port;
// 创建SnowflakeZookeeperHolder对象
SnowflakeZookeeperHolder holder = new SnowflakeZookeeperHolder(Utils.getIp(), String.valueOf(port), zkAddress);
// 初始化SnowflakeZookeeperHolder对象
initFlag = holder.init();
if (initFlag) {
// 初始化完成后最重要的就是确定了本机器的workerId
workerId = holder.getWorkerID();
LOGGER.info("start success use zk workerId-{}", workerId);
} else {
// 校验initFlag是否为true,不为true报出Snowflake Id Gen is not init ok错误
Preconditions.checkArgument(initFlag, "Snowflake Id Gen is not init ok");
}
// 校验生成的workID必须在0~1023之间
Preconditions.checkArgument(workerId >= 0 && workerId <= maxWorkerId, "workerID must gte 0 and lte 1023");
}
········
}
可以看到 SnowflakeIDGenImpl 的构造函数的最主要目的就是创建 SnowflakeZookeeperHolder 对象,并调用其 init() 初始化方法,初始化完成后最重要的就是确定了本机器的 workerId。这样 SnowflakeIDGenImpl 的 workerId 得到了初始化,获得了本Leaf节点在集群中的工作机器id号。这样snowflake算法的三分之一内容就已经搞定了。
为了显示 workerId 的获取的重要性,这里准备单独再开一节内容单独讨论。
② 初始化ID生成器
我们查看 SnowflakeIDGenImpl ID生成器的初始化方法:
/**
* 初始化直接返回为true
* @return
*/
@Override
public boolean init() {
return true;
}
可以看到初始化方法默认返回 true,直接认为初始化成功,所以创建 SnowflakeService 的整个流程最重要的目的其实就是获取本机器在集群中分配得到的 workerId,那么下面来具体研究 SnowflakeZookeeperHolder 具体是怎么获取到 workerId 的。
分配workerId
官方博客说明,分配机器的 workerId 策略:
对于workerID的分配,当服务集群数量较小的情况下,完全可以手动配置。Leaf服务规模较大,动手配置成本太高。所以使用Zookeeper持久顺序节点的特性自动对snowflake节点配置wokerID。
那么 SnowflakeZookeeperHolder 就是采用ZooKeeper来进行分配机器id的。对于ZooKeeper不太熟悉的朋友可以参考这篇文章。从上面 SnowflakeIDGenImpl 的构造函数流程中可以得知, workerId 的获取经过两个步骤即可完成:
- 创建
SnowflakeZookeeperHolder实例; - 调用
SnowflakeZookeeperHolder的初始化方法。
两步完成之后, SnowflakeZookeeperHolder 实例中就包含了 workerId 。
① 创建SnowflakeZookeeperHolder实例
SnowflakeZookeeperHolder 的构造函数主要是保存了几个关键的连接ZooKeeper的信息,还有用于标识自身Leaf节点机器的信息等。
/**
* 本机ip,用于区分不同的节点
*/
private String ip;
/**
* zk的端口
*/
private String port;
/**
*本机ip:port,用于区分zk根节点下不同的节点
*/
private String listenAddress = null;
/**
* zk的ip地址
*/
private String connectionString;
/**
* @param ip 本机器的ip地址
* @param port 连接zk的端口号
* @param connectionString zk的ip地址
*/
public SnowflakeZookeeperHolder(String ip, String port, String connectionString) {
this.ip = ip;
this.port = port;
this.listenAddress = ip + ":" + port;
this.connectionString = connectionString;
}
② 初始化SnowflakeZookeeperHolder
/**
* 初始化方法,包括:
* 1. 创建zk客户端连接会话并启动客户端
* 2. 检查/snowflake/${leaf.name}/forever根节点是否存在
* 3. 不存在则创建根节点,获取zk分配的workerId,并写入本地文件
* 4. 存在则查询到持久节点下属于自己的节点,得到zk分配的workerId,更新本地文件,校验是否时钟回拨
* 5. 如果启动失败,就从本地文件中读取,弱依赖zk
* @return
*/
public boolean init() {
try {
// 1. 创建zk客户端连接会话并启动客户端
CuratorFramework curator = createWithOptions(connectionString, new RetryUntilElapsed(1000, 4), 10000, 6000);
// 启动客户端
curator.start();
// 2. 检查/snowflake/${leaf.name}/forever根节点是否存在
Stat stat = curator.checkExists().forPath(PATH_FOREVER);
// 注意!!!!!这一段逻辑Leaf集群中只会有一个节点执行一次,所以下面workerId不需要从zk_AddressNode中解析赋值!!!!!
if (stat == null) {
// 3. 不存在根节点说明机器是第一次启动,则创建/snowflake/${leaf.name}/forever/ip:port-000000000,并写入自身节点标识和时间数据
zk_AddressNode = createNode(curator);
LOGGER.info("[New NODE] first register in zk and create node on forever node that endpoint ip-{} port-{} workid-{},create own node on forever node and start SUCCESS ", ip, port, workerID);
// 在本地缓存workerId,默认是0(因为此时还没有从zk获取到分配的workID,0是成员变量的默认值,这里可以不从zk_AddressNode解析workerID,直接默认0)
updateLocalWorkerID(workerID);
// 定时上报本机时间戳给/snowflake/${leaf.name}/forever根节点
ScheduledUploadData(curator, zk_AddressNode);
return true;
}
// 4. 存在的话,说明不是第一次启动leaf应用,zk存在以前的【自身节点标识和时间数据】
else {
// 自身节点ip:port->0000001
Map<String, Integer> nodeMap = Maps.newHashMap();
// 自身节点ip:port->ip:port-000001
Map<String, String> realNode = Maps.newHashMap();
// 存在根节点,先获取根节点下所有的子节点,检查是否有属于自己的节点
List<String> keys = curator.getChildren().forPath(PATH_FOREVER);
for (String key : keys) {
String[] nodeKey = key.split("-");
realNode.put(nodeKey[0], key);
nodeMap.put(nodeKey[0], Integer.parseInt(nodeKey[1]));
}
// 获取zk上曾经记录的workerId,这里可以看出workerId的分配是依靠zk的自增序列号
Integer workerid = nodeMap.get(listenAddress);
if (workerid != null) {
// 有自己的节点,zk_AddressNode = /snowflake/${leaf.name}/forever+ip:port-0000001
zk_AddressNode = PATH_FOREVER + "/" + realNode.get(listenAddress);
// 启动worker时使用会使用
workerID = workerid;
// 检查该节点当前的系统时间是否在最后一次上报时间之后
if (!checkInitTimeStamp(curator, zk_AddressNode)) {
// 如果不滞后,则启动失败
throw new CheckLastTimeException("init timestamp check error,forever node timestamp gt this node time");
}
// 准备创建临时节点
doService(curator);
// 更新本地缓存的workerID
updateLocalWorkerID(workerID);
LOGGER.info("[Old NODE] find forever node have this endpoint ip-{} port-{} workid-{} childnode and start SUCCESS", ip, port, workerID);
} else {
// 不存在自己的节点则表示是一个新启动的节点,则创建持久节点,不需要check时间
String newNode = createNode(curator);
zk_AddressNode = newNode;
String[] nodeKey = newNode.split("-");
// 获取到zk分配的id
workerID = Integer.parseInt(nodeKey[1]);
doService(curator);
updateLocalWorkerID(workerID);
LOGGER.info("[New NODE] can not find node on forever node that endpoint ip-{} port-{} workid-{},create own node on forever node and start SUCCESS ", ip, port, workerID);
}
}
} catch (Exception e) {
// 5. 如果启动出错,则读取本地缓存的workerID.properties文件中的workId
LOGGER.error("Start node ERROR {}", e);
try {
Properties properties = new Properties();
properties.load(new FileInputStream(new File(PROP_PATH.replace("{port}", port + ""))));
workerID = Integer.valueOf(properties.getProperty("workerID"));
LOGGER.warn("START FAILED ,use local node file properties workerID-{}", workerID);
} catch (Exception e1) {
LOGGER.error("Read file error ", e1);
return false;
}
}
return true;
}
这一段逻辑可以说是非常的核心,其中的注释基本也达到每行都进行了极为详尽的注释。初始化方法逻辑主要包括:
- 创建zk客户端连接会话并启动客户端
- 检查/snowflake/${leaf.name}/forever根节点是否存在
- 不存在则创建根节点,获取zk分配的workerId (其实分配的肯定是0),并写入本地文件
- 存在则查询到持久节点下属于自己的节点,得到zk分配的workerId,更新本地文件,校验是否时钟回拨
- 如果启动失败,就从本地文件中读取,弱依赖zk。
为了方便理解,我们简单的绘制出ZooKeeper的节点目录。假设我们一共部署了三台Leaf服务用于生成snowflake模式的分布式id,那么zookeeper的节点目录如下。其中 ${leaf.name} 是我们在配置文件中配置的字符串。图中的都是持久节点,橙色的是持久自动编号节点。节点名称的定义规则就是Leaf应用的 本机ip地址 + ‘:’ + 端口号 + ‘-’ + 自动编号 构成。那么其实每有一个Leaf服务器上线注册到ZooKeeper,自动编号便会加1,这样自动编号就可以作为这台Leaf的 workerId。基于ZooKeeper的分配 workerId 原理就是这样。
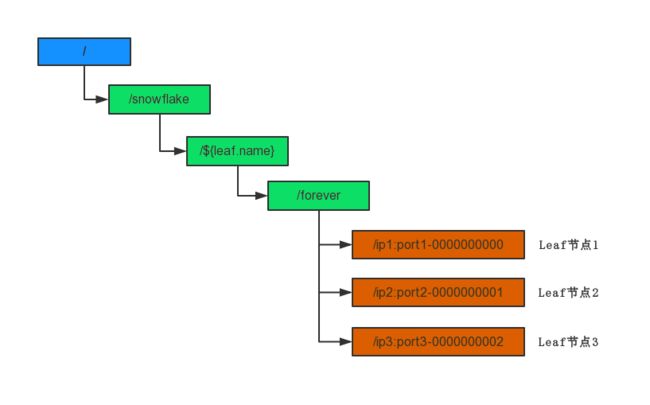
如下是真实测试过程中查询的zk节点:
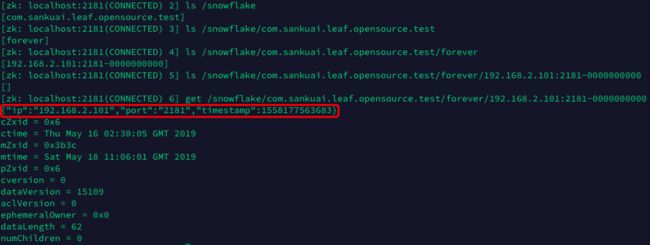
对应于官方博客中提及的根节点 leaf-forever 应该就是指代实际的 /snowflake/${leaf.name}/forever 节点。
整个 init() 方法的逻辑可以用如下的流程图表示:
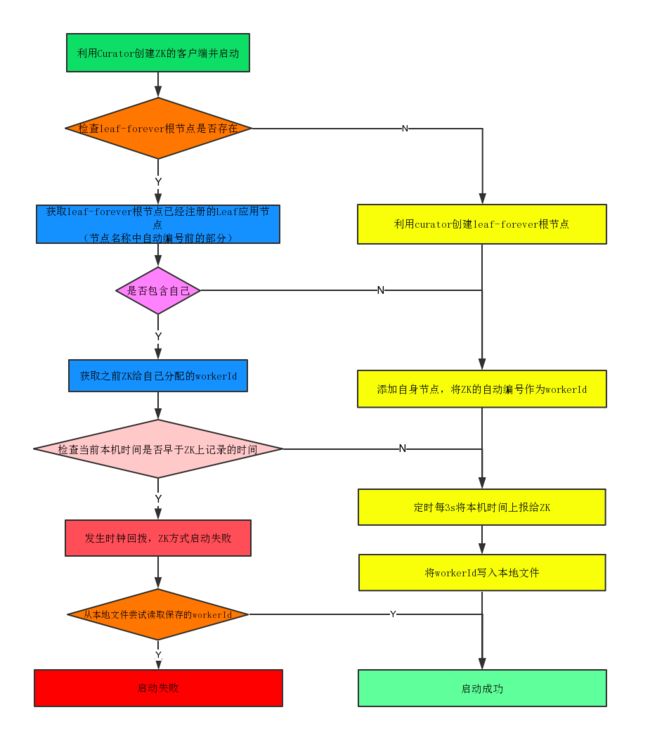
具体的流程可参考代码详细阅读,并不是很难。这里需要提及的是,官方博客介绍时还涉及到临时节点 leaf-temporary 相关逻辑,但是源码中好像并未涉及,具体问题已经在官方仓库提交问题,参考:https://github.com/Meituan-Dianping/Leaf/issues/40
获取分布式id
经过 SnowflakeService 的构造函数,我们已经从ZooKeeper或者本地文件成功获取到本机的 workerId,接下来就可以利用获取到的 workerId 按照snowflake算法拼装出64位的id。
我们从 SnowflakeService 的 get() 方法入手。首先,我们注意到该方法是一个 synchronized 修饰的同步方法,确保线程安全。
/**
* 根据key获取id
* 这是一个synchronized同步方法,确保原子性,所以sequence就是普通类型的变量值
* @param key 业务key
* @return
*/
@Override
public synchronized Result get(String key) {
/**
* 生成id号需要的时间戳和序列号
* 1. 时间戳要求大于等于上一次用的时间戳 (这里主要解决机器工作时NTP时间回退问题)
* 2. 序列号在时间戳相等的情况下要递增,大于的情况下回到起点
*/
// 获取当前时间戳,timestamp用于记录生成id的时间戳
long timestamp = timeGen();
// 如果比上一次记录的时间戳早,也就是NTP造成时间回退了
if (timestamp < lastTimestamp) {
long offset = lastTimestamp - timestamp;
// 如果相差小于5
if (offset <= 5) {
try {
// 等待 2*offset ms就可以唤醒重新尝试获取锁继续执行
wait(offset << 1);
// 重新获取当前时间戳,理论上这次应该比上一次记录的时间戳迟了
timestamp = timeGen();
// 如果还是早,这绝对有问题的
if (timestamp < lastTimestamp) {
return new Result(-1, Status.EXCEPTION);
}
} catch (InterruptedException e) {
LOGGER.error("wait interrupted");
return new Result(-2, Status.EXCEPTION);
}
}
// 如果差的比较大,直接返回异常
else {
return new Result(-3, Status.EXCEPTION);
}
}
// 如果从上一个逻辑分支产生的timestamp仍然和lastTimestamp相等
if (lastTimestamp == timestamp) {
// 自增序列+1然后取后12位的值
sequence = (sequence + 1) & sequenceMask;
// seq 为0的时候表示当前毫秒12位自增序列用完了,应该用下一毫秒时间来区别,否则就重复了
if (sequence == 0) {
// 对seq做随机作为起始
sequence = RANDOM.nextInt(100);
// 生成比lastTimestamp滞后的时间戳,这里不进行wait,因为很快就能获得滞后的毫秒数
timestamp = tilNextMillis(lastTimestamp);
}
} else {
// 如果是新的ms开始,序列号要重新回到大致的起点
sequence = RANDOM.nextInt(100);
}
// 记录这次请求id的时间戳,用于下一个请求进行比较
lastTimestamp = timestamp;
/**
* 利用生成的时间戳、序列号和workID组合成id
*/
long id = ((timestamp - twepoch) << timestampLeftShift) | (workerId << workerIdShift) | sequence;
return new Result(id, Status.SUCCESS);
}
方法逻辑主要包含两部分:
- 先确定当前的时间戳和自增序列号;
- 利用第一步确定好的时间戳、自增序列以及workerId最终拼装出id。
① 生成时间戳和序列号
时间戳的生成很简单,就是调用 timeGen() 函数返回系统当前时间戳。
/**
* 生成时间戳
* @return
*/
protected long timeGen() {
return System.currentTimeMillis();
}
并发访问情况下,很可能同一时间戳下需要下发很多id,此时需要通过自增序列号来进行区分不同的id。如果当前时间戳的所有id全部下发完毕不够用时,需要调用 tilNextMillis(lastTimestamp) 得到下一个时间戳,重新下发新的id。
/**
* 自旋生成直到比lastTimestamp之后的当前时间戳
* @param lastTimestamp
* @return
*/
protected long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
注意,使用新的时间戳时,需要将自增的序列号“清零”。但实际并没有直接赋值为0,而是取的是0到100的随机数 sequence = RANDOM.nextInt(100)。官方Issue的解释如下:
主要是出于BD分表均匀考虑
至于什么是BD分表,还是写错了其实是DB分表,可能最后的自增序列影响到了分表策略吧 ?
理论上这是一个同步方法,也就是多线程并发获取id变为了顺序获取的方式,是不会出现当前时间 timestamp 小于 lastTimestamp 的。官方博客给出的解释是,机器在运行时也可能会进行NTP时间同步,NTP时间同步是指利用网络时间同步协议(NTP)来同步网络中各个计算机的时间。所以对于本机器节点而言,可能因此发生时间回退,造成 timestamp 小于 lastTimestamp 的小的情况。对于这种情况的出现,如果回退的时间比较大,那么直接报错;如果回退时间叫小,则线程等待一会等到时间追上再继续服务。
② 拼装id
/**
*利用生成的时间戳、序列号和workID组合成id
*/
long id = ((timestamp - twepoch) << timestampLeftShift) | (workerId << workerIdShift) | sequence;
return new Result(id, Status.SUCCESS);
查看用到的几个变量值分别是什么:
/**
* 起始时间戳,用于用当前时间戳减去这个时间戳,算出偏移量
*/
private final long twepoch = 1288834974657L;
/**
* workID占用的比特数
*/
private final long workerIdBits = 10L;
/**
* 最大能够分配的workerid =1023
*/
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
/**
* 自增序列号
*/
private final long sequenceBits = 12L;
/**
* workID左移位数为自增序列号的位数
*/
private final long workerIdShift = sequenceBits;
/**
* 时间戳的左移位数为 自增序列号的位数+workID的位数
*/
private final long timestampLeftShift = sequenceBits + workerIdBits;
/**
* 后12位都为1
*/
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
主要是利用位数,进行位运算得到结果。
总结
美团Leaf的号段模式与snowflake模式都可以用于生成分布式唯一id,其优缺点官方博客也都进行了详细的介绍。有关两种模式详细的源码分析可以参考博客,推荐有兴趣的朋友直接看我详尽注释版的源码,仓库地址在文章开始之处。如果发现错误,可以博客评论或者Github提交问题,一起讨论。