深度学习算法优化系列十八 | TensorRT Mnist数字识别使用示例
1. 前言
上一节对TensorRT做了介绍,然后科普了TensorRT优化方式以及讲解在Windows下如何安装TensorRT6.0,最后还介绍了如何编译一个官方给出的手写数字识别例子获得一个正确的预测结果。这一节我将结合TensorRT官方给出的一个例程来介绍TensorRT的使用,这个例程是使用LeNet完成MNIST手写数字识别,例程所在的目录为:
2. 代码解析
按照上一节的讲解,我们知道TensorRT的例程主要是分为Build和Deployment(infer)这两个步骤,接下来我们就按照参数初始化,Build,Deployment这个顺序来看看代码。
2.1 主函数
sampleMNIST例程的主函数代码实现如下:
int main(int argc, char** argv)
{
// 参数解析
samplesCommon::Args args;
bool argsOK = samplesCommon::parseArgs(args, argc, argv);
if (!argsOK)
{
gLogError << "Invalid arguments" << std::endl;
printHelpInfo();
return EXIT_FAILURE;
}
// 打印帮助信息
if (args.help)
{
printHelpInfo();
return EXIT_SUCCESS;
}
auto sampleTest = gLogger.defineTest(gSampleName, argc, argv);
gLogger.reportTestStart(sampleTest);
// 使用命令行参数初始化params结构的成员
samplesCommon::CaffeSampleParams params = initializeSampleParams(args);
// 构造SampleMNIST对象
SampleMNIST sample(params);
gLogInfo << "Building and running a GPU inference engine for MNIST" << std::endl;
// Build 此函数通过解析caffe模型创建MNIST网络,并构建用于运行MNIST(mEngine)的引擎
if (!sample.build())
{
return gLogger.reportFail(sampleTest);
}
// 前向推理如果没成功,用gLogger报告状态
if (!sample.infer())
{
return gLogger.reportFail(sampleTest);
}
// 用于清除示例类中创建的任何状态,内存释放
if (!sample.teardown())
{
return gLogger.reportFail(sampleTest);
}
// 报告例子运行成功
return gLogger.reportPass(sampleTest);
}
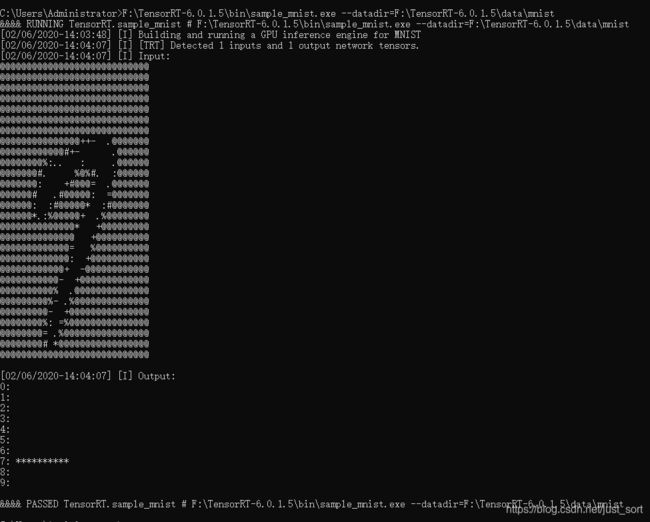
可以清晰的看到代码主要分为参数初始化,Build,Infer这三大部分,最后的输出结果是下面这样。
2.2 参数初始化
参数初始化主要由initializeSampleParams函数来完成,这个函数的详细注释如下,具体就是根据输入数据和网络文件所在的文件夹去读取LeNet的Caffe原始模型文件和均值文件,另外设置一些如输出Tensor名字,batch大小,运行时精度模式等关键参数,最后返回一个params对象。注意这里使用的LeNet模型是Caffe的原始模型,因为TensorRT是直接支持Caffe的原始模型解析的,但例如Pytorch模型之类的还要进行转换,这在以后的文章中会涉及到。
//!
//! 简介: 使用命令行参数初始化params结构的成员
//!
samplesCommon::CaffeSampleParams initializeSampleParams(const samplesCommon::Args& args)
{
samplesCommon::CaffeSampleParams params;
if (args.dataDirs.empty()) //!< 如果用户未提供目录路径,则使用默认目录
{
params.dataDirs.push_back("data/mnist/");
params.dataDirs.push_back("data/samples/mnist/");
}
else //!< 使用用户提供的目录路径
{
params.dataDirs = args.dataDirs;
}
params.prototxtFileName = locateFile("mnist.prototxt", params.dataDirs); //读取params.dataDirs文件夹下的mnist.prototxt
params.weightsFileName = locateFile("mnist.caffemodel", params.dataDirs); //读取params.dataDirs文件夹下的mnist.caffemodel
params.meanFileName = locateFile("mnist_mean.binaryproto", params.dataDirs); //读取MNIST数字识别网络的均值文件
params.inputTensorNames.push_back("data"); // 输入Tensor
params.batchSize = 1; //设置batch_size大小
params.outputTensorNames.push_back("prob"); // 输出Tensor
params.dlaCore = args.useDLACore; // 是否使用DLA核心
params.int8 = args.runInInt8; //以INT8的方式运行
params.fp16 = args.runInFp16; //以FP16的方式运行
return params; // 返回Params对象
}
2.3 Build
对于Build,具体的流程可以用下图来表示:
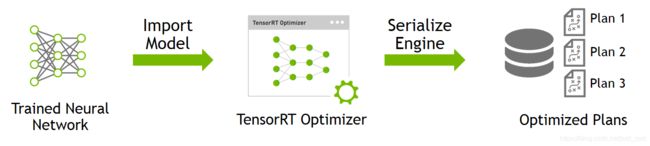
如上图所示,Build阶段主要完成模型转换(从Caffe/TensorFlow/Onnx->TensorRT),在转换阶段会完成优化过程中的计算图融合,精度校准。这一步的输出是一个针对特定GPU平台和网络模型的优化过的TensorRT模型。这个TensorRT模型可以序列化的存储到磁盘或者内存中。存储到磁盘中的文件叫plan file。在sampleMNIST例子中只需要给tensorRT提供Caffe的*.prototxt,*.caffemodel,*.mean.binaryproto文件即可完成Build过程,另外这个还需要指定batch的大小并标记输出层。下面展示了sampleMNIST例子中的Build代码解析。
//! 简介: 创建网络、配置生成器并创建网络引擎
//! 细节: 此函数通过解析caffe模型创建MNIST网络,并构建用于运行MNIST(mEngine)的引擎
//! 返回值: 如果引擎被创建成功,直接返回True
bool SampleMNIST::build()
{
// 1. Create builder
//创建一个 IBuilder,传进gLogger参数是为了方便打印信息。
//builder 这个地方感觉像是使用了建造者模式。
auto builder = SampleUniquePtr(nvinfer1::createInferBuilder(gLogger.getTRTLogger()));
if (!builder)
{
return false;
}
//创建一个 network对象,但是这个network对象只是一个空架子,里面的属性还没有具体的数值。
auto network = SampleUniquePtr(builder->createNetwork());
if (!network)
{
return false;
}
//创建一个配置文件解析对象
auto config = SampleUniquePtr(builder->createBuilderConfig());
if (!config)
{
return false;
}
//创建一个caffe模型解析对象
auto parser = SampleUniquePtr(nvcaffeparser1::createCaffeParser());
if (!parser)
{
return false;
}
// 使用caffe解析器创建MNIST网络并标记输出层
constructNetwork(parser, network);
// 设置batch大小,工作空间等等
builder->setMaxBatchSize(mParams.batchSize);
config->setMaxWorkspaceSize(16_MiB);
config->setFlag(BuilderFlag::kGPU_FALLBACK);
config->setFlag(BuilderFlag::kSTRICT_TYPES);
if (mParams.fp16)
{
config->setFlag(BuilderFlag::kFP16);
}
if (mParams.int8)
{
config->setFlag(BuilderFlag::kINT8);
}
samplesCommon::enableDLA(builder.get(), config.get(), mParams.dlaCore);
// 返回一个初始化好的cuda推理引擎
mEngine = std::shared_ptr(builder->buildEngineWithConfig(*network, *config), samplesCommon::InferDeleter());
if (!mEngine)
return false;
assert(network->getNbInputs() == 1);
mInputDims = network->getInput(0)->getDimensions();
assert(mInputDims.nbDims == 3);
return true;
}
这个代码中的关键函数是constructNetwork,这个函数的作用是使用caffe解析器创建MNIST数字识别网络(LeNet)并标记输出层,我们可以看一下它的代码解析。可以看到代码中主要就是标记了输出Tensor,并且对网络的输入数据进行预处理包括减均值和缩放之类的操作。
//!
//! 简介: 使用caffe解析器创建MNIST网络并标记输出层
//!
//! 参数: 指向将用MNIST网络填充的网络指针
//!
//! 参数: 指向引擎生成器的生成器指针
//!
void SampleMNIST::constructNetwork(SampleUniquePtr& parser, SampleUniquePtr& network)
{
const nvcaffeparser1::IBlobNameToTensor* blobNameToTensor = parser->parse(
mParams.prototxtFileName.c_str(),
mParams.weightsFileName.c_str(),
*network,
nvinfer1::DataType::kFLOAT);
//输出Tensor标记
for (auto& s : mParams.outputTensorNames)
{
network->markOutput(*blobNameToTensor->find(s.c_str()));
}
// 在网络开头添加减均值操作
nvinfer1::Dims inputDims = network->getInput(0)->getDimensions();
// 读取均值文件的数据
mMeanBlob = SampleUniquePtr(parser->parseBinaryProto(mParams.meanFileName.c_str()));
nvinfer1::Weights meanWeights{nvinfer1::DataType::kFLOAT, mMeanBlob->getData(), inputDims.d[1] * inputDims.d[2]};
// 数据的原始分布是[0,256]
// 减去均值之后是[-127,127]
// The preferred method is use scales computed based on a representative data set
// and apply each one individually based on the tensor. The range here is large enough for the
// network, but is chosen for example purposes only.
float maxMean = samplesCommon::getMaxValue(static_cast(meanWeights.values), samplesCommon::volume(inputDims));
auto mean = network->addConstant(nvinfer1::Dims3(1, inputDims.d[1], inputDims.d[2]), meanWeights);
mean->getOutput(0)->setDynamicRange(-maxMean, maxMean);
network->getInput(0)->setDynamicRange(-maxMean, maxMean);
// 执行减均值操作
auto meanSub = network->addElementWise(*network->getInput(0), *mean->getOutput(0), ElementWiseOperation::kSUB);
meanSub->getOutput(0)->setDynamicRange(-maxMean, maxMean);
network->getLayer(0)->setInput(0, *meanSub->getOutput(0));
// 执行缩放操作
samplesCommon::setAllTensorScales(network.get(), 127.0f, 127.0f);
// 最后的网络的输出就是[-1, 1]
}
3.4 Infer

如上图所示,Infer阶段就是完成前向推理过程了,这里将Build过程中获得的plan文件首先反序列化,并创建一个 runtime engine,然后就可以输入数据,然后输出分类向量结果或检测结果。Deploy阶段的实现在infer函数中,它负责分配缓冲区,设置输入,执行推理引擎并验证输出。代码解析如下:
//!
//! 简介: 对这个例子执行TensorRT的前向推理
//!
//! 细节: 此函数是示例的主要执行功能。 它分配缓冲区,设置输入,执行推理引擎并验证输出。
//!
bool SampleMNIST::infer()
{
// 创建 RAII 缓冲区管理对象
samplesCommon::BufferManager buffers(mEngine, mParams.batchSize);
// 创建推理引擎
auto context = SampleUniquePtr(mEngine->createExecutionContext());
if (!context)
{
return false;
}
// 挑选一个要推理的随机数
srand(time(NULL));
const int digit = rand() % 10;
// 读取输入数据到缓冲区管理对象中
// 这里是由一个输入Tensor
assert(mParams.inputTensorNames.size() == 1);
if (!processInput(buffers, mParams.inputTensorNames[0], digit))
{
return false;
}
// 创建CUDA流以执行此推断
cudaStream_t stream;
CHECK(cudaStreamCreate(&stream));
// 将数据从主机输入缓冲区异步复制到设备输入缓冲区
buffers.copyInputToDeviceAsync(stream);
// 异步排队推理工作
if (!context->enqueue(mParams.batchSize, buffers.getDeviceBindings().data(), stream, nullptr))
{
return false;
}
// 将数据从设备输出缓冲区异步复制到主机输出缓冲区
buffers.copyOutputToHostAsync(stream);
// 等待流中的工作完成
cudaStreamSynchronize(stream);
// 释放流
cudaStreamDestroy(stream);
// 检查并打印推断的输出
// 这里只有一个输出张量
assert(mParams.outputTensorNames.size() == 1);
bool outputCorrect = verifyOutput(buffers, mParams.outputTensorNames[0], digit);
return outputCorrect;
}
2.5 辅助函数
在初始化函数initializeSampleParams中有一个函数叫locateFile,以及在processInput函数中有一个readPGMFile函数。这两个函数不是在sampleMNIST.cpp中实现的。而是在F:\TensorRT-6.0.1.5\samples\common文件夹下的common.h中实现的,是这个例程的辅助函数。这两个函数的实现如下:
// 定位文件
inline std::string locateFile(const std::string& filepathSuffix, const std::vector& directories)
{
const int MAX_DEPTH{10};
bool found{false};
std::string filepath;
for (auto& dir : directories)
{
if (!dir.empty() && dir.back() != '/')
{
#ifdef _MSC_VER
filepath = dir + "\\" + filepathSuffix;
#else
filepath = dir + "/" + filepathSuffix;
#endif
}
else
filepath = dir + filepathSuffix;
for (int i = 0; i < MAX_DEPTH && !found; i++)
{
std::ifstream checkFile(filepath);
found = checkFile.is_open();
if (found)
break;
filepath = "../" + filepath; // Try again in parent dir
}
if (found)
{
break;
}
filepath.clear();
}
if (filepath.empty())
{
std::string directoryList = `在这里插入代码片`std::accumulate(directories.begin() + 1, directories.end(), directories.front(),
[](const std::string& a, const std::string& b) { return a + "\n\t" + b; });
std::cout << "Could not find " << filepathSuffix << " in data directories:\n\t" << directoryList << std::endl;
std::cout << "&&&& FAILED" << std::endl;
exit(EXIT_FAILURE);
}
return filepath;
}
// 读图
inline void readPGMFile(const std::string& fileName, uint8_t* buffer, int inH, int inW)
{
std::ifstream infile(fileName, std::ifstream::binary);
assert(infile.is_open() && "Attempting to read from a file that is not open.");
std::string magic, h, w, max;
infile >> magic >> h >> w >> max;
infile.seekg(1, infile.cur);
infile.read(reinterpret_cast(buffer), inH * inW);
}
2.6 日志类
在上面的代码中我们可以看到还有大量的和日志相关的信息,这些都来源于在F:\TensorRT-6.0.1.5\samples\common\logging.h中实现的日志类class Logger : public nvinfer1::ILogger,这个日志类继承于nvinfer1::ILogger,代码简要摘抄一点:
// Logger for TensorRT info/warning/errors
class Logger : public nvinfer1::ILogger
{
public:
Logger(): Logger(Severity::kWARNING) {}
Logger(Severity severity): reportableSeverity(severity) {}
void log(Severity severity, const char* msg) override
{
// suppress messages with severity enum value greater than the reportable
if (severity > reportableSeverity) return;
switch (severity)
{
case Severity::kINTERNAL_ERROR: std::cerr << "INTERNAL_ERROR: "; break;
case Severity::kERROR: std::cerr << "ERROR: "; break;
case Severity::kWARNING: std::cerr << "WARNING: "; break;
case Severity::kINFO: std::cerr << "INFO: "; break;
default: std::cerr << "UNKNOWN: "; break;
}
std::cerr << msg << std::endl;
}
Severity reportableSeverity{Severity::kWARNING};
};
然后nvinfer1::ILogger这个类在TensorRT的头文件NvInferRuntimeCommon.h中,目录如下图所示。
nvinfer1::ILogger类的代码如下。这个类是builder,engine和runtime类的日志接口,这个类应该以单例模式使用,即当存在多个IRuntime 和/或 IBuilder对象时仍然只能使用一个ILogger接口。这个接口中有一个枚举变量enum class Severity用来定义日志报告级别,分别为 kINTERNAL_ERROR,kERROR,kWARNING和kINFO;然后还有一个纯虚函数 log() ,用户可以自定义这个函数,以实现不同效果的打印。例如在2.6节的日志类就是根据不同的报告等级向准错误输出流输出带有不同前缀的信息。当然,我们也可以自己定义这个函数的,比如将日志信息存到一个log.txt里。
class ILogger
{
public:
//!
//! \enum Severity
//!
//! The severity corresponding to a log message.
//!
enum class Severity : int
{
kINTERNAL_ERROR = 0, //!< An internal error has occurred. Execution is unrecoverable.
kERROR = 1, //!< An application error has occurred.
kWARNING = 2, //!< An application error has been discovered, but TensorRT has recovered or fallen back to a default.
kINFO = 3, //!< Informational messages with instructional information.
kVERBOSE = 4, //!< Verbose messages with debugging information.
};
//!
//! A callback implemented by the application to handle logging messages;
//!
//! \param severity The severity of the message.
//! \param msg The log message, null terminated.
//!
virtual void log(Severity severity, const char* msg) TRTNOEXCEPT = 0;
virtual ~ILogger() {}
};
3. 后记
这篇推文从源码角度来分析了一下TensorRT使用LeNet对MNIST数据进行推理的例程,旨在对TensorRT的推理过程有一个初步的印象,因为LeNet模型本身就很小所以加速效果也体现不太出来,这里就不贴了。
参考
- //docs.nvidia.com/deeplearning/sdk/tensorrt-api/#graphsurgeon
- https://docs.nvidia.com/deeplearning/sdk/tensorrt-api/
- https://arleyzhang.github.io/articles/c17471cb/
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:
