python3 解析xml文件
使用python3 xml.etree.ElementTree库解析xml文件
使用的xml文件内容如下:该数据来自百度天气api返回的xml格式的结果
http://api.map.baidu.com/images/weather/day/yin.png
http://api.map.baidu.com/images/weather/night/yin.png
http://api.map.baidu.com/images/weather/day/duoyun.png
http://api.map.baidu.com/images/weather/night/duoyun.png
http://api.map.baidu.com/images/weather/day/duoyun.png
http://api.map.baidu.com/images/weather/night/duoyun.png
http://api.map.baidu.com/images/weather/day/zhenyu.png
http://api.map.baidu.com/images/weather/night/zhenyu.png
http://api.map.baidu.com/images/weather/day/zhenyu.png
http://api.map.baidu.com/images/weather/night/zhenyu.png
http://api.map.baidu.com/images/weather/day/duoyun.png
http://api.map.baidu.com/images/weather/night/duoyun.png
http://api.map.baidu.com/images/weather/day/duoyun.png
http://api.map.baidu.com/images/weather/night/duoyun.png
http://api.map.baidu.com/images/weather/day/duoyun.png
http://api.map.baidu.com/images/weather/night/duoyun.png
===========================>
def domParseXML(text=""):
if "" == text:
raise RuntimeError("解析的内容不能为空")
results = xml.etree.ElementTree.fromstring(text)
print("查询结果:",results.find("status").text,"查询日期:",results.find("date").text)
datas = results.find("results")
if datas is not None:
for data in datas:
if data.__len__() > 0:
for _,weather in enumerate(list(data)):
if weather.__len__() == 0:
text = weather.text.strip()
if text.startswith("http://"):
if text.find("day") > -1:
print("白天天气图标URL:",text)
else:
print("夜晚天气图片URL:",text)
else :
print(text)
else:
print("当前城市:",data.text)
运行结果如下: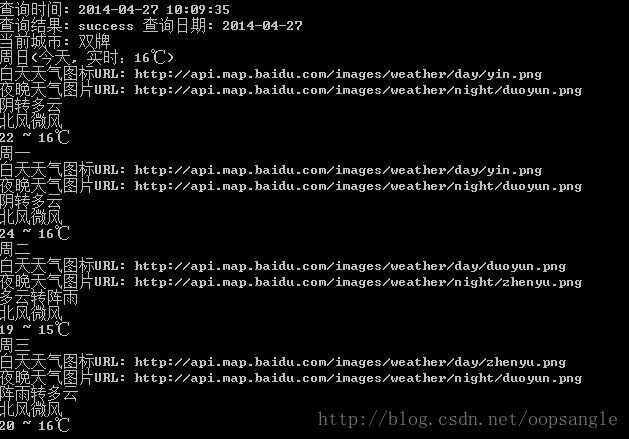
root = tree.getroot()
root.tag,root.text,root.attrid获得节点的标签,文本内容,属性
#获得子节点 --->直系子节点
for child in root:
print(child.tag,child.text)
也可以通过find方式查找节点
root.find("results")------->返回类型是Element
root.findall("results")----->返回类型是list列表
如果未查找到则返回None类型据此可做判断