《Python计算机视觉》学习之图像检索
利用文本挖掘技术对基于图像视觉内容进行图像搜索。
矢量空间模型,是用来表示和搜索文本文档的模型。矢量包含每个单词出现的次数,而在其他地方包含很多0元素。我们忽略单词出现的顺序及位置(研究表明,单词顺序不一定会影响到我们的阅读)。该模型也被称为BOW(Bag of words)表示模型。
一、BOW模型实验步骤
1.1 用sift方法提取特征点
1.2 学习“特征词典”
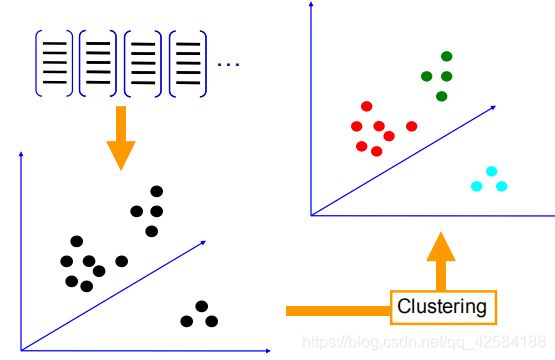
我们从一个训练集中提取特征描述子,利用K-Means聚类算法得到的视觉单词是聚类质心。
K-Means算法:首先先初始化N个聚类中心(下图是N=3)。重复下面步骤直至算法收敛:对应每个特征,最小化每个特征 xi 与其相对应的聚类中心 mk之间的欧式距离,将该特征赋予给某个类别。对每个类别的特征集重新计算其的聚类中心。
1.3 针对输入特征集,根据视觉词典进行量化
K-Means算法得到的聚类中心称为codevector。对于输入特征,量化的过程是将该特征映射到距离其最接近的 codevector ,并实现计数。
1.4 把输入图像,根据TF-IDF转化成视觉单词(visual words)的频率直方图
TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力。也就是我们TF-IDF的思想计算一个视觉单词在该图片中出现的频率,据此得到一张图片的视觉单词的频度直方图。
词w在文档d中的词频TF(Term Frequency),即词w在文档d中出现次数count(w, d)和文档d中总词数size(d)的比值:TF(w,d) = count(w, d) / size(d)。
词w在整个文档集合中的逆向文档频率IDF(Inverse Document Frequency),即文档总数n与词w所出现文件数docs(w, D)比值的对数:IDF = log(n / docs(w, D))。
TF-IDF模型根据TF和IDF为每一个文档d和由关键词w[1]…w[k]组成的查询串q计算一个权值,用于表示查询串q与文档d的匹配度:TF-IDF(q, d) = sum { i = 1…k | TF(w[i], d) * IDF(w[i]) }。

1.5 构造特征到图像的倒排表,通过倒排表快速索引相关图像
倒排索引是指由属性值来确定记录的位置。在本实验中,我们构造视觉单词(特征)到图像的倒排表,便于我们通过找到相似的特征,再找到相关图现象
1.6 根据索引结果进行直方图匹配
二、实验结果分析
首先载入图像列表,特征列表(分别包含图像文件名和SIFT特征文件)及词汇。
from PCV.geometry import homography
from PCV.tools.imtools import get_imlist
# load image list and vocabulary
#载入图像列表
imlist = get_imlist('first1000/')
nbr_images = len(imlist)
#载入特征列表
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
#载入词汇
with open('first1000/vocabulary.pkl', 'rb') as f:
voc = pickle.load(f)
然后,创建一个Searcher对象,执行定期查询,并将结果保存在res_reg列表中。
src = imagesearch.Searcher('testImaAdd.db',voc)
# index of query image and number of results to return
#查询图像索引和查询返回的图像数
q_ind = 0
nbr_results = 20
# regular query
# 常规查询(按欧式距离对结果排序)
res_reg = [w[1] for w in src.query(imlist[q_ind])[:nbr_results]]
print ('top matches (regular):', res_reg)
然后载入res_reg列表中没一幅图像的特征,并和查询图像进行匹配。单应性通过计算匹配数和计算内点数得到。
# load image features for query image
#载入查询图像特征
q_locs,q_descr = sift.read_features_from_file(featlist[q_ind])
fp = homography.make_homog(q_locs[:,:2].T)
# RANSAC model for homography fitting
#用单应性进行拟合建立RANSAC模型
model = homography.RansacModel()
rank = {}
# load image features for result
#载入候选图像的特征
for ndx in res_reg[1:]:
locs,descr = sift.read_features_from_file(featlist[ndx]) # because 'ndx' is a rowid of the DB that starts at 1
# get matches
matches = sift.match(q_descr,descr)
ind = matches.nonzero()[0]
ind2 = matches[ind]
tp = homography.make_homog(locs[:,:2].T)
# compute homography, count inliers. if not enough matches return empty list
#计算转置矩阵,统计内点数,如果不满足初始的最低值就返回空矩阵。
try:
H,inliers = homography.H_from_ransac(fp[:,ind],tp[:,ind2],model,match_theshold=4)
except:
inliers = []
# store inlier count
rank[ndx] = len(inliers)
最终我们通过减少内点数目对包含图像索引和内点数进行排序。
# sort dictionary to get the most inliers first
sorted_rank = sorted(rank.items(), key=lambda t: t[1], reverse=True)
res_geom = [res_reg[0]]+[s[0] for s in sorted_rank]
print ('top matches (homography):', res_geom)
# 显示查询结果
imagesearch.plot_results(src,res_reg[:8]) #常规查询
imagesearch.plot_results(src,res_geom[:8]) #重排后的结果
实验结果
![]()

上一行是没有常规查询的结果,下一行是重排后的结果。

要查询的图片:

错误结果:




前四张图可以看出其背景图片均是相同的地毯,前景不同但有相似的颜色。我们找到的词汇单词是一张图片的特征,也就是它每次是在一张图片找出几百个特征点,可能第一张图片的频度直方图比较高频的点与另一张错配图片的直方图的高频点匹配上了。

这张错配的图片与前几张错配图片不一样,其背景与要查询的图不一致,但颜色相近。之所以会被查询出来,我认为是因为在某些视觉词汇上的频度比较大,而该图片能匹配上的视觉词汇的数量也满足了我们的要求,就被搜了出来。但也就意味着可能剩余的视觉词汇匹配结果不理想。