图的表示
邻接矩阵
int G [maxv][maxv]或
数组元素存储连接与否或连接权重的信息
如果有多个边的相关属性,例如多个权重,则可以声明边的结构体 struct edge替换上面的int
如果有多个节点的相关属性,例如节点的颜色、访问时间、估计最短距离等,只需再单独声明|V|大小的一维数组即可邻接表
vectorG[maxv]
for(int i = 0; i < E; i++) {
cin >> s >> t;
G[s].push_back[t];
// G[t].push_back[s];
}
每个节点的邻接表中存储连接信息,也可以表示为
struct edge { int to; int cost; }
vector
1. 搜索
对于连通图,一次搜索可访问全部节点
BFS
- 利用BFS可求:
- 无权图从给定源点出发到所以可以到达结点间的最短路径
- 树的直径(树的所有最短路径距离的最大值):两次BFS即可实现,第二次BFS选择第一次遍历得到的最长路径的末节点作为源节点
DFS
深度优先森林的前驱子图的深度优先森林中包含:
树边(遍历路径)、后向边(已访问过的某级父节点)、前向边(已访问过的某子节点)、横边(其他所有的边,包括不同树间的边)
第一次访问边(u,v)时,如果v为白色即树边,如果v为灰色即后向边,如果v为黑色即横向边或前向边(无向图中是不会出现前向边和横向边的)
- 利用DFS可求:
- 有向图或无向图是无环图<=>DFS不产生后向边
对于无向图这一判定算法的时间复杂度O(V)与E无关,因为对于无环的森林|E| < |V|-1,因此如果存在后向边,遍历V个结点后后向边一定已经出现 - 拓扑排序
DFS结束时间的反序
- 连通分量
无向图的连通分量个数即DFS森林树的颗数
有向图的强连通分量即对G和G的转置分别DFS得到的结果
有向图的单连通分量判定:
从每个点作一次DFS,得到一棵DFS树,如果没有出现DFS树内cross edge和forward edge,则此图必为单连通图
有向图的半连通分量判定:
计算强连通分量,对得到的分量图SCC进行拓扑排序,如果拓扑排序的结果
时间复杂度O(V+E) - 衔接点、桥、双连通分量
朴素方法
对于每个点,删除该点判断图的连通性O(V(V+E))
利用深度优先森林
前驱子图的根节点是图的衔接点<=>它在前驱子图中至少有两个子节点 - 欧拉回路
如果图的每个节点的出度等于入度则存在欧拉回路
如果一个无向图连通图最多只有两个奇点(就是度数为奇数的点),则一定存在欧拉回路 - 二分图判定
二分图:若能将无向图G=(V,E)的顶点V划分为两个交集为空的顶点集,并且任意边的两个端点都分属于两个集合,则称图G为一个为二分图
二分图判定:染色法
LCA 多个点的最近公共祖先
RMQ区间最值查询
2. 连通无向图的最小生成树
最小生成树:
贪心算法 核心是找到一个安全边(u,v)加入到集合A使得 A U {(u,v)} 依然是最小生成树的一个子集
横跨切割的权重最小的边即轻量级边
- Kruskal算法:集合A是森林,按权重从低到高考察每条边,如果它将两棵不同的树连接起来就加入到森林A里并完成两棵树的合并
实现:不相交数据结构
MST-Kruskal(G, w)
A = 空集
for each vertex v in G.V
make-set(v)
sort edges E in G.E in nodecreasing order
for each edge (u,v) in sorted G.E
if find-set(u) != find-set(v) //否则会形成环
A.push((u,v))
union(u,v)
return A
时间复杂度O(ElgV)
- Prim算法:集合A是一棵树,每次加入连接集合A和A之外结点的所有边中权重最小的边
实现:优先队列
增加最小生成树的根节点r作为输入
v.key存在v和树中节点的所有边中的最小权重
MST-Prim(G, w, r)
for each vertex v in G.V
v.key = 无穷
v.pi = null
r.key = 0
Q = G.V
while Q 不为空
u = extract-min(Q)
for each v in G.adj[u]
if v in Q and w(u,v) < v.key
v.pi = u
v.key = w(u,v)
第一次循环队列中为MST根节点r
建堆总时间O(V)
extract-min时间共V次
使用二叉堆
使用斐波那契堆 时间复杂度与迪杰斯特拉算法相同
差别主要在于for循环(E次)中v.key隐含的decrease-key操作在斐波那契堆上的执行成本可以从lgV降为1
3. 最短路径
3.1 问题分析
- 最短路径具有最优子结构:最短路径的子路径也是最短路
- 无权重图的最短路径可以直接使用BFS求解,因此本节讨论的图均有权重
- 最短路径问题可以包含负权重边(例如Bellman-Ford),但不支持负权重环(不过Bellman-Ford算法可以检测是否存在负权重环)
- 最短路径必定不包括环路,路径长度至多为|V| - 1
- 最短路径的表示是以源点s为根节点的一颗最短路径树,由于s到每个可以从s到达的节点的最短路径不唯一,最短路径树不唯一
- 三角不等式 表示两点间最短路径
松弛操作
v.d -- 最短路径估计
Relax(u, v, w)
if v.d > u.d + w(u, v)
v.d = u.d + w(u, v)
v.pi = u
松弛满足
上界性质
收敛性质 一旦v.d收敛不会再发生变化
非路径性质 对于不可达点
3.2 单源最短路径
Bellman-Ford
每条边松弛|V| -1次(最坏情况下每次循环只松弛了一条边)之后如果存在不满足三角不等式的结点v.d > u.d + w(u,v)说明存在负权重环
时间复杂度O(VE)
Bellman-Ford的改进
改进关键是对松弛顶点的顺序重排序
Yen的改进Ex 21-1
分解图 对节点拓扑排序后两图交替松弛
DAG-Shortest-Path
DSP只适用于有向无环图
拓扑排序后按照节点依赖顺序依次对发节点发出的所有边进行松弛
时间复杂度O(V + E)
- 利用DSP可以求解PERT图的关键路径:
- 关键路径:
将图中所有权重变为负数,运行DSP 或 将松弛操作改为反向操作,初始化对应变为负无穷
Dijkstra
Dijkstra可用于有环图,但不允许存在负权重的边
贪心策略:维护一个已求出最短路径节点的集合S,以v.d为key构造最小堆,每次选择V-S中的最小堆顶,将其加入S并松弛所有与其相邻的边。注意第一次执行循环extract-min得到的是源点s。
Dijkstra(G, w, s)
for each vertex v in G.V
v.d = 无穷大
v.pi = null
s.d = 0
Q = G.V
while Q 不为空
u = extract-min(Q)
S.push(u)
for each v in G.adj[u]
if v.d > u.d + w(u, v)
v.d = u.d + w(u, v)
v.pi = u
![[算法] 图论_第1张图片](http://img.e-com-net.com/image/info10/e0f98ec1d6c948c79cfb73271ac51b04.jpg)
应用
差分约束
将m*n的线性规划矩阵看作是n个节点和m条边构成的图的邻接矩阵的转置
约束图增加节点与其他所有节点以权重为0的边连接
约束条件转换为
约束图的最短路径的解即差分约束系统的解
3.3 多源最短路径
重复平方法
类比矩阵乘法
Floyd
适用负权重边,不允许存在负权重环 O(V^3)
动态规划
递归定义最优解:
中间节点恰好经过k节点 VS 中间节点不包括k节点
![[算法] 图论_第2张图片](http://img.e-com-net.com/image/info10/03f142e0d1004473babef6388e626a21.jpg)
- 利用Floyd求图的传递闭包
有向图的传递闭包:如果存在从i到j的路径则闭包中(i,j)有边相连
每条边权重赋值1,运行Floyd算法,根据中间求解结果是否包含无穷的边来判断 O(n^3)
稀疏图的Johnson算法-Reweight
适用负权重边,调用Bellman-ford可检测负权重环
要满足重新赋值权重后最短路径不变,新增节点s与所有节点相连且w(s,v) = 0,使用Bellman-ford计算,令,则新权重且负权重边均变为正,运行V次Dijkstra算法,最后将最短路径还原即可。
4. 最大流
定义
流网络(连通图、单向边)
多源多汇:增加超级源点和超级汇点
存在双向边:增加一个额外节点
流
满足容量限制和流量守恒
流f的值为从源节点流出的总流量减流入源节点的总流量
残余网络
残余容量的反向容量最多将其正向容量抵消
![[算法] 图论_第3张图片](http://img.e-com-net.com/image/info10/717b54869fef423c90a599316408ae5d.jpg)
残存网络每条边必须允许大于0的流量通过
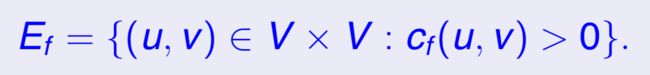
增广路径
残余网络中从s到t的简单路径

割
![[算法] 图论_第4张图片](http://img.e-com-net.com/image/info10/55d69ae4015044f1921576bb2df4ff8a.jpg)
![[算法] 图论_第5张图片](http://img.e-com-net.com/image/info10/db6f6aeaed79492bbd9dcdb420b54460.jpg)
注意割的容量不包括反向边,而横跨任何割的净流量都相同
Ford-Fulkerson方法
初始化流为0,沿着残余网络的增广路径增加流,直至残余网络不包括任何增广路径
最大流最小割定理
三条件等价:
1.残余网络不包括任何增广路径
2.f是最大流
3.流网络的某个切割c=|f|
基本Ford-Fulkerson算法
O(E|f*|)
Edmonds-Karp算法
O(VE^2)
二分图匹配
匹配
满足每个节点最多只有一条边相连的边的子集
增加源点汇点,赋值单位权重构造G',则流网络的最大流即二分图的最大匹配
O(VE)
图论500题
https://blog.csdn.net/luchy0120/article/details/39696417
https://blog.csdn.net/luomingjun12315/article/details/47438607