一个移位操作引发的程序Bug
最近在开发一个有关IPV6的项目,碰到一个非常奇怪的问题,在计算IPV6的子网掩码的时候,网络前缀为8,16,48,80,112能计算正确,当网络前缀为32,64,96计算错误。这个问题花了近一天的时间定位和修改。计算IPV6子网掩码的函数如下:
#include
#include
#define MAX_IP_SEG 4
class CIPV6Address
{
public:
CIPV6Address()
{
memset(m_uiIPSeg, 0, sizeof(m_uiIPSeg));
};
void Output(unsigned int uiPrefixLen)
{
printf("PrefixLen_%u=%08x:%08x:%08x:%08x\n", uiPrefixLen,m_uiIPSeg[0],m_uiIPSeg[1],m_uiIPSeg[2], m_uiIPSeg[3]);
}
void fillNetMask(unsigned int uiPrefixLen)
{
unsigned int uiLoc=uiPrefixLen/32;
unsigned int uiBits=uiPrefixLen%32;
for(unsigned int i = 0;i < uiLoc; ++i)
{
m_uiIPSeg[i] = 0xFFFFFFFF;
}
if (uiPrefixLen < 128)
{
m_uiIPSeg[uiLoc] = (0xFFFFFFFF<<(32-uiBits));
}
Output( uiPrefixLen);
};
private :
unsigned int m_uiIPSeg[MAX_IP_SEG];
};
int main()
{
CIPV6Address addr;
addr.fillNetMask(16);
addr.fillNetMask(32);
addr.fillNetMask(48);
addr.fillNetMask(64);
addr.fillNetMask(80);
addr.fillNetMask(96);
return 0;
}
上面程序的输出如下:
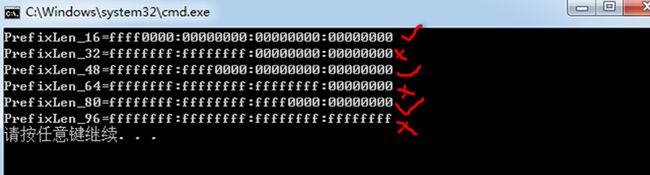
可以看到网络前缀为32,64,96的子网掩码计算错误。到底是什么原因导致了这个结果呢?开始怀疑是算法出现了问题,通过检查发现算法没有问题,于是心中充满了各种疑惑,然后写了一个小程序来进行测试。如下:

大家可以不看下面,猜猜上面程序的输出是什么?
通过运行发现,两句打印的结果不同,第一个uiResult是一个非常大的值,而uiRes是0。这里唯一的差别是前面使用变量uiBits,而uiBits的值为0,下面是直接使用0,然后进行移位。如下:
输出如下:uiResult=4294967295
uiRes=0
而后者是我们预期的结果, 这也就是函数fillNetMask计算结果错误的直接原因,但是为什么会出现这种情况呢?
接下来看看两种情况的汇编指令:
第一情况:
unsigned int uiBits=0;
011E344E mov dword ptr [uiBits],0
unsigned int uiResult = (0xFFFFFFFF<<(32-uiBits));
mov ecx,20h
011E345A sub ecx,dword ptr [uiBits]
011E345D or eax,0FFFFFFFFh
011E3460 shl eax,cl
011E3462 mov dword ptr [uiResult],eax
printf("%u\n",uiResult);
011E3465 mov esi,esp
011E3467 mov eax,dword ptr [uiResult]
011E346A push eax
011E346B push offset string "%u\n" (11E5C18h)
011E3470 call dword ptr [__imp__printf (11E82B8h)]
011E3476 add esp,8
011E3479 cmp esi,esp
011E347B call @ILT+460(__RTC_CheckEsp) (11E11D1h)
从上面011E3460 shl eax,cl 可以看出,移位指令向左移动了cl位,这个cl是移位操作数的低4位寄存器。32的低四位为0,其实没有向左移。
第二种情况:
unsigned int uiResult =(0xFFFFFFFF<<(32-0));
00BE344E mov dword ptr [uiResult],0
printf("%u\n",uiResult);
00BE3455 mov esi,esp
00BE3457 mov eax,dword ptr [uiResult]
00BE345A push eax
00BE345B push offset string "%u\n" (0BE5C18h)
00BE3460 call dword ptr [__imp__printf(0BE82B8h)]
00BE3466 add esp,8
00BE3469 cmp esi,esp
00BE346B call @ILT+460(__RTC_CheckEsp) (0BE11D1h)
通过观察,发现上面的汇编指令中没有shl移位操作指令,编译器在编译阶段发现unsigned int 向左移动32位,可能会溢出,优化了该操作,直接将结果赋值为0.,如下这条赋值语句。
00BE344E mov dword ptr [uiResult],0
这就导致了上面两者的结果不同。同时第二种情况编译的时候也会出现编译告警,提示移位操作大于数据类型的最大长度。

由此可以看出,为了保证移位操作的正确性,应该保证移位个数不能大于等于数据类型的最大位数,如果出现这种情况,可能会得到意向不到的结果。
修改方式
由于是溢出导致的结果错误,立马想到的是采用如下下的方式修改

上面的结果会是我们的预期吗?按照我们上面的理论,应该是正确的,我们来看看运行的结果是多少。
编译运行:

发现上面的结果也不是我们预期的,真的好纠结,难道和编译器的行为有关?或者和操作系统有关?或者上面总结的理论错误?各种猜测。 起初自己各种尝试,都得不到正确的结果,后来一个同事跟我说,你编译的是32位程序还是64位,因为32位的程序unsigned long和unsigned int都是四个字节。而g++默认的编译方式是32位的,为了验证这个想法,我以64位的方式进行编译。
g++ -m64 shift.c –o shift
./shift
uiResult=0
发现运行结果正确。
主要原因是在32位程序sizeof(unsigned int)=sizeof(unsignedlong)=4,向左移位32,都可能会溢出。
而64位平台,sizeof(unsigned long)>sizeof(unsignedint)。
为了保证在不同平台上能运行正确,我没有选择上面的修改方式,而是选用了下面的修改方式。
voidfillNetMask(unsigned intuiPrefixLen)
{
unsigned intuiLoc=uiPrefixLen/32;
unsigned intuiBits=uiPrefixLen%32;
for(unsigned int i = 0;i < uiLoc; ++i)
{
m_uiIPSeg[i] = 0xFFFFFFFF;
}
if (uiPrefixLen < 128)
{
if(0 == uiBits)
{ m_uiIPSeg[uiLoc] = 0;}
else
{ m_uiIPSeg[uiLoc] =(0xFFFFFFFF<<(32-uiBits));
}
Output(uiPrefixLen);
};本文总结一句话:在进行移位操作时,移位的位数不能超过数据类型的最大位数,同时也不能对负数进行移位。同时需要注意32位和64位平台数据类型的差异。