《深入理解Linux内核》-3.3. 进程切换
3.3. 进程切换
为了控制进程的执行,内核必须能够挂起正在运行的进程并恢复运行其他之前被挂起的进程。这个活动通过进程切换,任务切换或上下文切换执行这种各样的操作。接下来的章节介绍Linux系统上的进程切换。
3.3.1. 硬件上下文
虽然每个进程拥有自己的地址空间,但是它们必须共享相同的CPU寄存器。因此恢复执行一个进程之前,内核必须保证用该进程先前被挂起时的寄存器值来初始化这些寄存器。
这组在进程恢复运行之前必须被加载到CPU寄存器的数据叫做硬件上下文。硬件上下文是进程执行上下文的子集,进程执行上下文包含进程执行所需要的所有信息。在Linux上,一部分的硬件上下文存储在进程描述符中,剩下的部分保存在内核栈中。
在下文的描述中,我们假设局部变量prev表示被切换出的进程描述符,next表示切换进用于替代prev的进程描述符。因此我们可以这样定义进程切换:保存prev的硬件上下文然后用next的硬件上下文来替代。因为进程切换非常频繁,所以尽可能地减少保存和加载硬件上下文的时间显得尤为重要。
老版的Linux系统利用80x86架构提供的硬件支持,使用far jmp指令来实现进程切换。当执行这条指令时,CPU通过自动地保存旧的硬件上下文并加载一个新的来完成硬件上下文切换。但是Linux2.6使用软件方法来实现进程切换,原因如下:
- 通过一系列的mov指令按部就班地进行切换允许更好的控制对被加载数据的验证。尤其是对于ds和es段寄存器的检查,这些寄存器可能会被恶意的用户入侵。当时用far jmp指令时是做不了这些检查的。
- 新方法和旧方法在时间上的消耗几乎是一样的。而且,在当前的切换代码仍有很大优化空间的情况下,再优化硬件上下文切换的必要性不是很大。
进程切换只发生在内核态。进程在用户态使用的寄存器内容在执行进程切换前就已经被保存到内核栈里(参考第4章)。这些内容包含指示用户态栈指针地址的ss和esp寄存器。
3.3.3. 任务状态段
80x86架构包含一个特殊的段类型叫任务状态段(TSS),用来存储硬件上下文。虽然Linux硬件上下文切换中不会用到,但还是强制地为每个CPU设置了一个TSS。主要原因如下:
- 当一个80x86 CPU从用户态切换到内核态时,它从TSS获取内核栈的地址(参考第4章的“中断和异常的硬件处理”一节和第10章的“使用系统指令发起一个系统调用”一节)。
当一个用户态进程尝试通过in或者out指令访问I/O端口时,CPU需要通过TSS中的权限位图来验证该进程是否有权限访问这个端口。
更精确地说,当进程在用户态执行一个in或者out指令时,CPU控制单元会执行以下操作:
- 检查eflags寄存器(标志寄存器)中的2位的IOPL字段。如果值为3,控制单元执行这个指令,否则,执行下一个任务。
- 访问tr寄存器(任务寄存器)来决定当前的TSS,然后获取适当的I/O权限位图。
- 检查I/O访问指令中的I/O端口对应的权限位图位,如果被清除,指令可以执行,否则抛出一个“常规保护”异常。
tss_struct结构描述了TSS的格式。第2章已经提到过,init_tss数据为每个CPU存储了一个TSS。每次进程切换,内核会更新TSS中的一些字段,这样相应的CPU控制单元就可以安全的获取它需要的信息。因此,TSS反应了当前进程的权限,但是对于不在运行状态的进程没有必要维护TSS。
每个TSS有一个8字节的任务状态段描述符(TSSD)。这个描述符包含一个32位的Base字段指向TSS的起始地址,和一个20位的Limit字段。当TSSD的S标志被清除时,表示对应的TSS是一个系统段(参考第2章“段描述符”一节)。
Type字段设置为9或者11,表示这是一个TSS段。在Intel的原始设计里,每个进程都有自己的TSS,Type的第二个最低有效位叫做Busy位,为1表示进程正在运行,否则是0.在linux设计里,每个CPU只有一个TSS,因此Busy为总是1。
Linux创建的TSSDs存储在全局描述符表(GDT)里,GDT的基地址存储在每个CPU的gdtr寄存器中。每个CPU的tr寄存器包含TSS相应的TSSD选择器。这个寄存器还包含两个隐藏的不可编程的字段:TSSD的Base和Limit字段。这样,处理器可以直接定位TSS的地址,而不用先从GDT中获取TSS的地址。
3.3.2.1. thread字段
每次进程切换,被替换出来的硬件上下文必须被存储在某个地方。它不能存在TSS中,因为Linux的设计:多个处理器使用一个TSS,而不是每个进程一个。
因此,每个进程描述符包含一个thread_struct类型的thread字段,内核把被切换出的硬件上下文存储在其中。正如我们将要看到的,这个数据结构包含大部分的CPU寄存器字段,除了那些通用寄存器,比如eax,ebx,它们存储在内核栈中(译者注:进程切换中并不需要专门恢复这些寄存器的值)。
3.3.3 执行进程切换
进程切换可能只发生在一个明确定义的点: schedule()函数,在第7章会详细讨论它。这里我们只关注内核是怎样执行一个进程切换的。
实质上,每个进程切换分为两步:
- 切换全局页目录,并装载一个新的地址空间;我们将会在第9章详细描述这步。
- 切换内核态栈和硬件上下文,它们提供了内核执行一个新进程所需要的所有信息,包括CPU寄存器。
同样的,我们假设prev指向被替换的进程的描述符,next指向被激活的进程的描述符。我们在第7章会按到,prev和next是schedule()函数的局部变量。
3.3.3.1. switch_to宏
进程切换的第二部使用switch_to宏来执行的。它是内核最依赖硬件的例程之一,并且需要付出一些努力才能理解它的功能。
首先,这个宏有三个参数,prev、next和last。你应该很容易就能猜出prev和next的功能:它们是局部变量prev和next的占位符(placeholders),即它们作为输入参数定义了被替换进程和新进程的描述符的内存地址。
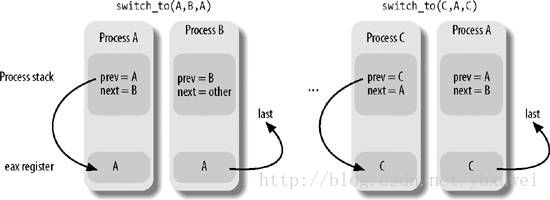
那么第三个参数last是做什么的呢?所有的进程切换都会涉及三个进程,而不是只有两个。假设内核决定关闭进程A并激活进程B。这schedule()函数中,prev指向A的描述符,next指向B的描述符。一旦宏switch_to关闭A,A的执行就被冻结了。
之后,当内核又要重新激活A时,它必须调用switch_to关闭另一个进程C(通常和B不一样),prev指向C,next指向A。当A恢复执行时,它找到旧的内核栈,此时,prev指向A的描述符,next指向B的描述符(A挂起之前的状态)。这时调度器当前执行的进程A丢失了到C的任何引用。然而这个对C的引用却对进程切换特别有用(从第7章可以查看更多细节)。
switch_to宏的最后一个参数last是个输出参数,用来存储进程C的描述符地址(当然,这时在A恢复执行后做的)。进程切换之前,这个宏把A的内核栈中prev的值存储在eax寄存器中,进程切换之后,当A已经恢复执行,把eax寄存器的内容写入last参数指向的内存。因为eax寄存器在进程切换中不会改变,因此last指定的位置存储了C的描述符地址。在当前的schedule()实现中,最后一个参数是进程A的prev地址,因此prev被C的地址覆盖。
图3-7展示了进程A、B、C的内核态栈布局和eax寄存器的值;注意,此图显示的prev在被eax寄存器的值覆盖之前的值。
图3-7. 进程切换时保留对进程C的引用
switch_to宏是用扩展内联汇编语言编写的,使得其可读性非常差:这些代码使用一些特殊的位置符号来表示寄存器,这样编译器可以自由地选择通用寄存器来使用。为了避免看这些麻烦的扩编内联汇编代码,我们使用标准汇编语言来描述switch_to宏在80x86微处理器上的处理过程。
把prev和next的值分别保存在eax和edx寄存器中:
movl prev, %eax movl next, %edx把eflags和ebp寄存器的内容保存在prev的内核栈里。它们必须被保存,因为编译器会假设它们的值直到
switch_to结束都不会变:pushfl pushl %ebp保存esp的值到prev->thread.esp中,如此这个字段指向prev内核栈的顶端。
movl %esp, 484(%eax)484(%eax)操作符表示地址为eax的值加上484的内存元素。
把next->thread.esp的值加载到esp中。从现在开始,内核在next的内核栈上操作,因此这条语句执行了实际的prev到next的进程切换。因为进程描述符的地址和内核栈的地址紧密关联(见本章前一节中“定义进程”一段的介绍),改变内核栈以为这改变了当前进程:
movl 484(%edx), %esp把标签1表示(本节之后会提到)的地址保存到prev->thread.eip。当被替换的进程恢复执行后,它将执行标签1表示的指令:
movl $1f, 480(%eax)在next的内核栈中压入
next->thread.eip的值,这个值在多数情况下是标签1对应的地址:pushl 480(%edx)跳转到
__switch_to()函数(看下一步):jmp __switch_to到此,被B替换的进程A重新获取到了CPU:它执行一些指令来恢复eflags和ebp寄存器。最先的两个指令被标记为1:
1: popl %ebp popfl注意这些pop指令是怎么涉及到prev进程的内核栈的。它们在调度器选择prev进程来运行时被执行,即调用
switch_to并用prev作为第二个参数。因此,esp寄存器指向prev内核栈。拷贝eax寄存器(上面第一步加载的)内容到
switch_to的第三个参数last里:movl %eax, last之前已经提到。eax寄存器指向刚刚被替换的进程的描述符。
3.3.3.2. __switch_to()函数
__switch_to()函数做了由switch_to()宏开始的进程切换的大部分工作。它作用于分别表示之前进程和新进程的prev_p和next_p参数。然而,这个函数又与一般的函数不同,因为__switch_to()的参数prev_p和next_p分别取自eax和edx寄存器,而不是像一般的函数那样从栈取参数。为了强制使这个函数从寄存器取参数,内核使用_attribute__和regpram关键字,它们是gcc编译器实现的c语言非标准扩展。__switch_to()函数在include/asm-i386/system.h头文件里声明:
_ _switch_to(struct task_struct *prev_p,
struct task_struct *next_p)
_ _attribute_ _(regparm(3));
该函数的执行步骤如下:
执行
__unlazy_fpu()宏产生的代码(参考本章之后的“保存和加载FPU,MMX,和XMM寄存器”一节)来有选择的保存prev_p进程的FPU、MMX和XMM寄存器的内容。__unlazy_fpu(prev_p);执行
smp_processor_id()宏来获取本地CPU的索引,即执行该代码的CPU。这个宏从当前进程的thread_info结构的cpu字段获取这个索引并保存在局部变量cpu里。加载
next_p->thread.esp0到本地CPU的TSS的esp0字段;我们在第10章“使用sysenter指令执行系统调用”一节中会看到,任何由sysenter汇编指令引起的从用户态到内核态的未来特权级别的改变都会拷贝这个地址到esp寄存器:init_tss[cpu].esp0 = next_p->thread.esp0;加载
next_p进程使用的线程局部存储(TLS)到本地CPU的全局描述符表里;这三个段选择器保存在进程描述符的tls_array数组中(参考第二章“Linux中的段”一节)。cpu_gdt_table[cpu][6] = next_p->thread.tls_array[0]; cpu_gdt_table[cpu][7] = next_p->thread.tls_array[1]; cpu_gdt_table[cpu][8] = next_p->thread.tls_array[2];把fs和gs段寄存器的内容分别保存到
prev_p->thread.fs和prev_p->thread.gs;相应的汇编指令如下:movl %fs, 40(%esi) movl %gs, 44(%esi)esi寄存器指向
prev_p->thread结构。如果fs和gs寄存机已经被
prev_p或者next_p使用(比如,它们有个非0值),则把next_p的thread_struct结构中的值存储到这些寄存器中。这步逻辑上补充了前一步的操作。主要的汇编指令如下:movl 40(%ebx),%fs movl 44(%ebx),%gsebx寄存器指向
next_p->thread结构。这个代码实际上非常复杂,因为当CPU检测到一个非法的段寄存器值时可能会产生一个异常。它采用一个“fix-up”方法来处理这种情况(参考第10章“动态地址检测:Fix-up代码”一节)。加载dr0,…,dr7中的6个寄存器的值为
next_p->thread.debugreg数组的内容。这个操作仅在next_p被挂起时正在使用调试寄存器时才会发生(即next_p->thread.debugreg[7]不为0)。这些寄存器不需要被保存,因为prev_p->thread.debugreg数组只在调试器想要监控prev的时候才会被修改:if (next_p->thread.debugreg[7]){ loaddebug(&next_p->thread, 0); loaddebug(&next_p->thread, 1); loaddebug(&next_p->thread, 2); loaddebug(&next_p->thread, 3); /* no 4 and 5 */ loaddebug(&next_p->thread, 6); loaddebug(&next_p->thread, 7); }根据需要更新TSS的I/O位图。当
next_p或prev_p拥有自定义的I/O位图时,必须要走这一步:if (prev_p->thread.io_bitmap_ptr || next_p->thread.io_bitmap_ptr) handle_io_bitmap(&next_p->thread, &init_tss[cpu]);因为进程很少修改I/O权限位图,所以对它的处理是以一种“懒惰”的模式:只有当进程在当前时间片实际的访问I/O端口时,才会把相应的位图拷贝到本地CPU的TSS中。进程自定义的I/O权限位图存储在由
thread_info的io_bitmap_ptr字段指向的缓冲区中。handle_io_bitmap()函数设置next_p进程的CPU的TSS的io_bitmap字段的如下:- 如果
next_p进程没有自定义的I/O权限位图,TSS的io_bitmap字段被设置为0x8000 。 - 如果
next_p进程有自定义的I/O权限位图,TSS的io_bitmap字段被设置为0x9000 。
TSS的
io_bitmap字段应该包含实际位图存储在TSS中的偏移。0x8000和0x9000超出了TSS限制,因而当用户态进程尝试访问一个I/O端口时会引起一个“常规保护”异常(参考第4章“异常”一节)。do_general_protection()异常处理函数会检查io_bitmap的值:如果为0x8000,则发送一个SIGSEGV信号到用户态进程;否则如果是0x9000,拷贝进程位图(由thread_info结构的io_bitmap_ptr字段指定)到本地CPU的TSS中,设置io_bitmap字段为实际位图的偏移(104),然后重新执行这个错误汇编指令。- 如果
终止。
__switch_to()函数通过以下语句结束执行:return prev_p;编译器会产生如下汇编指令:
movl %edi,%eax retprev_p参数(当前在edi中)被拷贝进eax,因为所有C函数默认通过eax寄存机来传递返回值。如此eax的值通过__switch_to()的调用被保存下来;这个至关重要,因为switch_to的调用假定eax总是存储被替换进程的描述符地址。ret指令从栈顶加载返回地址到eip程序计数器。但是
__switch_to()函数通过跳转被调用。因此ret指令从栈顶找到的是被标记为1的指令地址,它是通过switch_to宏压入栈中。如果next_p是首次执行而从未被挂起过,则找到的是ret_from_fork()函数的地址(查看本章之后的“clone(),fork(),vfork()系统调用”一节)。
3.3.4 保存和加载FPU、MMX、XMM寄存器
从Intel 80486DX开始,浮点运算单元被集成到CPU中。名词“数学协处理器”曾经一直被使用,那时的浮点运算是通过一个昂贵的专用芯片执行的。然而,为了和旧模式兼容,浮点运算通过“ESCAPE”指令实现,这些指令的字节前缀从0xd8到0xdf。它们作用于CPU的一套浮点寄存器。显然,如果一个进程使用ESCAPE指令,属于硬件上下文的浮点寄存器的内容必须被保存。
在后来的奔腾模型里,因特尔引入了一套新的汇编指令到微处理器中。它们叫做MMX指令,用来加速多媒体应用程序的执行。MMX指令作用于FPU的浮点寄存器。选择这种架构的一个明显的缺点是程序员不能混淆浮点指令和MMX指令。优点是,操作系统设计人员可以忽略这套新的指令集,因为相同的用来保存浮点运算单元状态的任务切换代码也可以用来保存MMX的状态。
MMX指令加速了多媒体应用程序,因为它们在处理器内部引进一个单指令多数据(SIMD)管道。奔腾3模型扩展了SIMD性能:它引入了SSE扩展(流式SIMD扩展),它增加了一个能够处理8个128位寄存器(XMM寄存器)中的浮点数的设施。这些寄存器与FPU和MMX寄存器不重叠,因此SSE和FPU/MMX指令可以自由组合。奔腾4模型还引进另一个特性:SSE2扩展,它是一个能够支持更高精度浮点值的SSE扩展。SSE2使用和SSE相同的一套XMM寄存器。
80x86微处理器不会自动保存TSS中的FPU,MMX和XMM寄存器。但是,它们包含一些硬件来使得内核能够在需要的时候保存这些寄存器。这些硬件支持包含cr0寄存器中的TS(Task-Switching)标志,它遵循以下规则:
每次硬件上下文切换,TS标志都被设置。
当TS标志被设置时,每次ESCAPE、MMX、SSE、SSE2指令的执行都会产生一个“设备不可用”异常(参考第4章)。
TS标志只允许内核在正真需要的是才保存和恢复FPU、MMX、XMM寄存器。为了解释他是怎样工作的,假设进程A正在使用数学协处理器。当从A到B发生上下文切换时,内核设置TS标志,并保存浮点寄存器到进程A的TSS中。如果新的进程B不使用数学协处理器,内核不需要恢复浮点寄存器的内容。但是一旦B尝试执行一个ESCAPE或者MMX指令,CPU产生一个“设备不可用”异常,然后相应的处理函数会把进程B的TSS中保存的值加载到浮点寄存器。
我们现在描述下引进用于处理选择性加载FPU、MMX和XMM寄存器的结构。它们保存在进程描述符的thread.i387子字段中,格式定义为i387_union:
union i387_union {
struct i387_fsave_struct fsave;
struct i387_fxsave_struct fxsave;
struct i387_soft_struct soft;
};
我们可以看到,这个字段只会存储三个不同类型数据中的一个。i387_soft_struct类型用于没有数学协处理器的CPU模型;Linux内核通过软件模拟协处理器来支持这些旧的芯片。但是,我们不打算深入讨论这些过时的案例。i387_fsave_struct类型用于有数学协处理器或者一个MMX单元的CPU模型。最后,i387_fxsave_struct类型用于有SSE或者SSE2扩展特性的CPU模型。
进程描述符包含两个额外的标志:
TS_USEDFPU标志,它包含在thread_info的status字段中。它标记了该进程是否在运行中使用了FPU,MMX或者XMM寄存器。PF_USED_MATH标志,包含在task_struct的flags字段中。它标记了thread.i387子字段的内容是否有意义。这个标志在以下两种情况下被清除:
- 当该进程通过调用
execve()启动了一个新的程序。因为控制永远不会返回之前的程序,thread.i387当前存储的数据永远不会被使用。 - 当运行在用户态的进程开始执行一个信号处理过程(参考第11章)。因为信号处理过程相对于进程执行流是异步的,浮点寄存器对信号处理过程来说是无意义的。然而,内核会在开始信号处理之前将浮点寄存器保存在thread.i387,并在信号处理结束后恢复它们的值。由此,信号处理过程可以使用数学协处理器。
- 当该进程通过调用
3.3.4.1 保存FPU寄存器
之前已经提到过,switch_to()函数执行__unlazy_fpu宏,并以被替换的prev进程的描述符作为参数。这个宏会检查prev的TS_USEDFPU标志。被设置说明prev使用了FPU,MMX,SSE或者SSE2指令;因此,内核必须保存相关的硬件上下文:
if (prev->thread_info->status & TS_USEDFPU)
save_init_fpu(prev);
save_init_fpu()函数依次执行以下操作:
转存prev进程描述符的FPU寄存器内容并重新初始化它。若CPU使用了SSE/SSE2扩展,它还会转存XMM寄存器的内容并重新初始化SSE/SSE2单元。一些功能强大的扩展内联汇编语言指令可以处理所有事情:
asm volatile( "fxsave %0 ; fnclex" : "=m" (prev->thread.i387.fxsave) );若CPU使用了SSE/SSE2扩展,则:
asm volatile( "fnsave %0 ; fwait" : "=m" (prev->thread.i387.fsave) );重置prev的
TS_USEDFPU标志:prev->thread_info->status &= ~TS_USEDFPU;使用
stts()宏来设置cr0的CW标志,实际会产生以下汇编指令:movl %cr0, %eax orl $8,%eax movl %eax, %cr0
3.3.4.2. 加载FPU寄存器
浮点寄存器的内容的恢复并不是紧跟在next进程恢复执行后。但是cr0的TS标志已经被__unlazy_fpu()设置。因此,当next进程第一次尝试执行一个ESCAPE,MMX或SSE/SSE2指令时,控制单元产生一个“设备不可用”异常,然后(更准确的说,异常处理函数是被该异常唤起的)内核运行math_state_restore()函数。next进程被标识为current。
void math_state_restore( )
{
asm volatile ("clts"); /* clear the TS flag of cr0 */
if (!(current->flags & PF_USED_MATH))
init_fpu(current);
restore_fpu(current);
current->thread.status |= TS_USEDFPU;
}
该函数清除cr0的CW标志,因此之后执行的FPU,MMX或SSE/SSE2指令不会触发“设备不可用”异常。如果thread.i387子字段没有意义,比如PF_USED_MATH标志位0,则调用init_fpu()来重置thread.i387自字段并设置current的PF_USED_MATH标志为1。然后调用restore_fpu()函数从thread.i387自字段中加载合适的值到FPU中。这一步会根据CPU是否支持SSE/SSE2扩展来选择使用fxrstor或者frstor汇编指令。最后,math_state_restore()设置TS_USEDFPU标志。
3.3.4.3. 在内核态使用FPU,MMX,和SSE/SSE2单元
即使内核也可以使用FPU,MMX,或SSE/SSE2单元。这样做当然应该避免干扰当前用户模式进程的计算。因此:
- 在使用协处理器之前,内核必须调用
kernel_fpu_begin(),它实际上是在用户进程使用FPU(TS_USEDFPU标志)的情况下调用save_init_fpu()来保存寄存器的内容 ,然后重置cr0的TS标志。 - 结束使用协处理器后,内核必须调用
kernel_fpu_end()来设置cr0的TS标志。
之后,当用户态进程执行一个协处理器指令时,math_state_restore()函数会恢复这些寄存器的内容,就像进程切换那样。
但是,我们应该注意,当当前进程正在使用协处理器时,kernel_fpu_begin()的执行是非常耗时的,以至于能抵消FPU,MMX或SSE/SSE2单元带来的性能提升。实际上,内核只在极少的地方使用它们,通常是在移动或清除较大的内存区域或计算校验和函数时。