从零开始DRF框架源码剖析—序列化与反序列
文章目录
- 序列化组件的使用
- Serializers组件的使用
- ModelSerializers多表序列化组件的使用
- 单查与群查接口实现
- 单增与群增接口实现
- 单删与群删接口实现
- 单改与群改接口实现
现在我将带着大家一起实现一个增删改查的接口,包括单查群查,单增群增,单改群改,单删群删,Let ’ s Go
序列化组件的使用
先介绍一下序列化组件的使用,之后再详细介绍源码。序列化组件有三个
Serializer(偏底层)、ModelSerializer(重点)、ListModelSerializer(辅助群改)
Serializers组件的使用
我们先讲Serializer,首先在models.py创建类,然后进行数据迁移。
class User(models.Model):
SEX_CHOICES = [
[0,'男'],
[1,'女'],
]
name = models.CharField(max_length=64)
pwd = models.CharField(max_length=32)
phone = models.CharField(max_length=11,null=True,default=None)
sex = models.IntegerField(choices=SEX_CHOICES,default=0)
icon = models.ImageField(upload_to='icon',default='icon/default.jpg')
class Meta:
db_table='user'
verbose_name='用户'
verbose_name_plural=verbose_name
def __str__(self):
return '%s' %self.name
ModelSerializers多表序列化组件的使用
现在我将带着大家一起实现一个增删改查的接口,包括单查群查,单增群增,单改群改,单删群删
ModelSerializer与常规的Serializer相同,但提供了:
-
基于模型类自动生成一系列字段
-
包含默认的create()和update()的实现
-
基于模型类自动为Serializer生成validators,比如unique_together
-
使用Serializer不容易跨表,有外键的情况可以用ModelSerializer
-
对于逻辑不是很复杂的,ModelSerializers可以整合序列化和反序列化。
模型层
里面涉及到了DRF新手不熟悉的东西,待会讲解,先把各个数据表关系捋清。
from django.db import models
# 基类
class BaseModel(models.Model):
is_delete = models.BooleanField(default=False) # 默认不是删除,数据库中是0/1
create_time = models.DateTimeField(auto_now_add=True)
# 设置 abstract = True 来声明基表,作为基表的Model不能在数据库中形成对应的表
class Meta:
abstract = True # 声明该表只是一个抽象表不出现在数据库中
# 书籍表
class Book(BaseModel):
name = models.CharField(max_length=64)
price = models.DecimalField(max_digits=5,decimal_places=2)
img = models.ImageField(upload_to='img',default='default.jpg')
#关联出版社表
publish = models.ForeignKey(
to='Publish', # 关联publish表
db_constraint=False, # 断关联(断开Book表和Publish表的关联,方便删数据,虽然断开了关联但是还能正常使用)
related_name='books', # 反向查询字段:publish_obj.books就能查出当前出版社出版的的所有书籍
on_delete=models.DO_NOTHING, # 设置连表操作关系
)
#关联作者表
authors = models.ManyToManyField(
to='Author',
db_constraint=True, #断开关联
related_name='books' #反向查询字段
)
"""
定义连表操作,而且可以实现可插拔,@property为静态方法
然后get_Book_Publish写到serialize文件的field里面
"""
@property
def get_Book_Publish(self):
return self.publish.name
@property
def get_Book_Authors(self):
return self.authors.values('name', 'age')
class Meta:
db_table = 'book'
verbose_name = '书籍'
verbose_name_plural = verbose_name
def __str__(self):
return self.name
#出版社表
class Publish(BaseModel):
"""name、address、is_delete、create_time"""
name = models.CharField(max_length=64)
addres = models.CharField(max_length=64)
class Meta:
db_table = 'publish'
verbose_name = '出版社'
verbose_name_plural = verbose_name
def __str__(self):
return self.name
#作者表
class Author(BaseModel):
"""name、age、is_delete、create_time"""
name = models.CharField(max_length=64)
age = models.IntegerField()
class Meta:
db_table = 'author'
verbose_name = '作者'
verbose_name_plural = verbose_name
def __str__(self):
return self.name
#作者详情
class AuthorDetail(BaseModel):
"""mobile, author、is_delete、create_time"""
mobile = models.CharField(max_length=11)
author = models.OneToOneField(
to = 'Author',
db_constraint = False,
related_name = 'detail',
on_delete = models.CASCADE
)
class Meta:
db_table = 'author_detail'
verbose_name = '作者详情'
verbose_name_plural = verbose_name
def __str__(self):
return self.author.name
在app目录下创建serializes.py,创建序列化与反序列化类,其实相对于不复杂的逻辑,基本上我们以后写不是特别复杂的,就比如说除了权限不一样得到的类的字段不一样这种情况,其他都可以整合序列化类与反序列化类,这里先介绍分开来写的。
from rest_framework.serializers import ModelSerializer, SerializerMethodField
from . import models
from rest_framework.response import Response
from django.core.exceptions import ValidationError
class BookModelSerializer(ModelSerializer):
# 通过连表自定义字段信息
publish_address = SerializerMethodField()
def get_publish_address(self, obj):
# obj是Book对象
return obj.publish.addres
class Meta:
model = models.Book
# 显示所以的字段
# fields = '__all__'
# 显示指定的字段
fields = ('name', 'price', 'img', 'get_Book_Publish', 'publish_address', 'get_Book_Authors')
# 不显示指定字段
# exclude = ('image', )
class BookModelDeSerializer(ModelSerializer):
# ModelSerializer已经帮我们实现了update和create,我们不用自己写
# 要进行序列化的字段
class Meta:
# 注意是model,不是models
model = models.Book
fields = ('name', 'price', 'publish', 'authors')
extra_kwargs = {
'name':{
# 设置name字段必填
'required': True,
'max_length': 10,
'error_messages':{
'max_length': '书名太长了'
}
}
}
def validate_name(self, values):
# 验证钩子函数,这里简单验证:书名含有g就不行
if 'g' in values:
return Response({
'status': 1,
'message': '书名不能含有g'
})
return values
def validate(self, attrs):
publish = attrs.get('publish') # publish如果是外键字段,这个就是publish对象
name = attrs.get('name')
if models.Book.objects.filter(name=name, publish=publish):
raise ValidationError({'book': '该书已存在'})
return attrs
单查与群查接口实现
规定指定pk是单查,不指定pk是群查
from django.shortcuts import render
from rest_framework.views import APIView
from rest_framework.response import Response
from . import models, serializers
# Create your views here.
class Book(APIView):
def get(self, request, *args, **kwargs):
pk = kwargs.get('pk')
if pk:
try:
book_obj = models.Book.objects.get(is_delete=False, pk=pk)
return Response(1)
except:
return Response({
'status':1,
'message':'没有查到信息'
})
# 如果没有写pk,就进行群查
else:
book_obj_all = models.Book.objects.filter(is_delete=False).all()
# 因为查询到的数据是queryset对象列表,所以记得加many=True
book_obj_all_ser = serializers.BookModelSerializer(book_obj_all, many=True).data
return Response({
'status':0,
'message':'success',
'result':book_obj_all_ser
})
群查测试(返回所有的数据)

单增与群增接口实现
接口:规定前端传一个字典列表过来是群增,传一个字典过来是新增(这些规则是我们自己定的,企业里面可能有对应的接口文档)
def post(self, request, *args, **kwargs):
"""
post应该实现可以群增和单增,
前端传一个字典列表过来是群增,
传一个字典过来是新增
:param request:
:param args:
:param kwargs:
:return:
"""
request_data = request.data
# 进行反序列化
if isinstance(request_data, dict) and request_data != {}:
# 单增
many = False
elif isinstance(request_data, list) and request_data != []:
# 群增,其实这里逻辑还不完善,我这里只是演示一下,就简单写了
many = True
else:
return Response({
'status': 1,
'message': '数据类型异常'
})
book_ser = serializers.BookModelDeSerializer(data=request_data, many=many)
# raise_exception=True:当校验失败,马上终止当前视图方法,抛异常返回给前台
book_ser.is_valid(raise_exception=True) # 检验是否合格 raise_exception=True必填的
book_obj = book_ser.save() # 保存得到一个对象
return Response({
'status': 0,
'msg': 'ok',
'results': serializers.BookModelDeSerializer(book_obj, many=many).data
})
测试:
群增发送数据

群查看看这些新增的数据是否入库成功
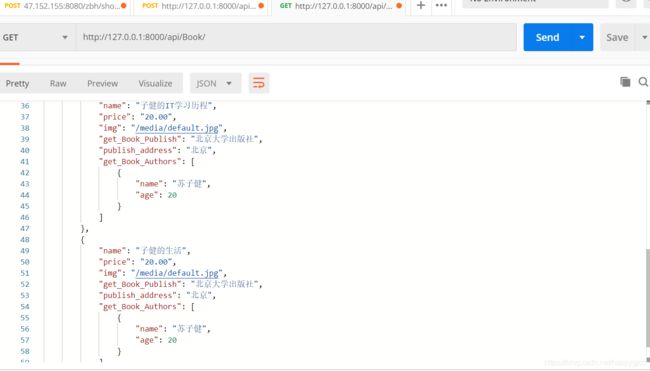
可见,入库成功 !
单删与群删接口实现
def delete(self, request, *args, **kwargs):
"""
单删:有pk,在postman中通过路径传参
群删:{pks:[1,2,3]} 通过json传参
逻辑思路是将单删也化为群删
:param request:
:param args:
:param kwargs:
:return:
"""
pk = request.GET.get('pk', None)
if pk:
# book_obj = models.Book.objects.filter(pk=pk).first().delete()
pks = [pk]
else:
pks = request.data.get('pks')
if not pks:
return Response({
'status':1,
'message': '请传入要改的参数'
})
"""
这里的逻辑是过滤出pk在pks里面的书籍,也就是要删的书籍
以及is_delete=False(没有被删除过的),避免重复删除
然后把is_delete=True,表示已将它删除
"""
if models.Book.objects.filter(pk__in=pks, is_delete=False).update(is_delete=True):
return Response({
'status': 0,
'message':'删除成功'
})
return Response({
'status': 1,
'msg': '删除失败'
})
测试
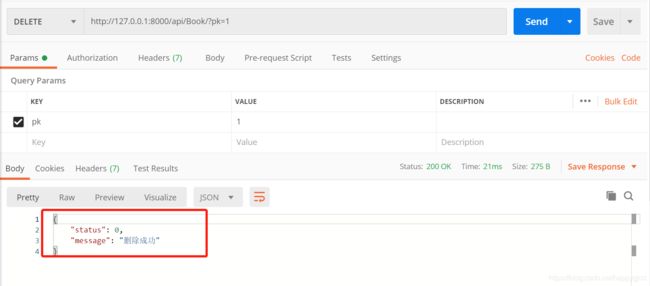
单改与群改接口实现
这里分为单局部改,单整体改和单局部改,