Docker入门(这篇真的够详细)
Docker入门
文章目录
- Docker入门
- docker的感性认识
- docker的优势
- 感受一下docker的便利性
- 一、docker的核心技术
- Namespaces
- 1、UTS Namespace
- 2、IPC Namespace
- 3、PID Namespace
- 4、Network Namespace
- 5、Mount Namespace
- 6、User Namespace
- Cgroups
- 1、什么是 Cgroups
- 2、Cgroups的使用
- UnionFS
- 1、什么是UnionFS
- 2、UnionFS在Images中的使用
- 二、docker网络
- 1、网络原理
- 2、模拟实现Docker网络
- 3、端口映射原理
- 三、docker使用
- docker命令列表
- docker search查找镜像
- docker images查看本机已经存在的镜像
- docker pull拉取镜像
- docker push推送镜像
- docker load从文件中导入镜像
- docker save将镜像保存为归档文件
- docker run 运行镜像,创建容器
- docker start/stop/restart 启动、关闭、重启容器
- docker ps 查看正在运行的容器
- docker exec在容器内执行命令
- docker rm删除容器
- docker rmi删除镜像
- docker commit从容器创建一个新的镜像
- docker inspect查看镜像和容器的详细信息
- docker cp宿主机、容器文件互拷
- ☆☆☆、容器使用建议:
- 四、Dockefile指令
- Dockerfile说明
- FROM
- MAINTANIER(已废弃)
- LABEL
- RUN
- centos安装软件的最佳实践:
- alpine安装软件的最佳实践:
- CMD
- ENTRYPOINT
- EXPOSE
- ENV
- ARG
- ADD
- COPY
- VOLUME
- USER
- WORKDIR
- HEALTHCHECK
- SHELL
- STOPSIGNAL
- ONBUILD
docker的感性认识
镜像与容器的关系?
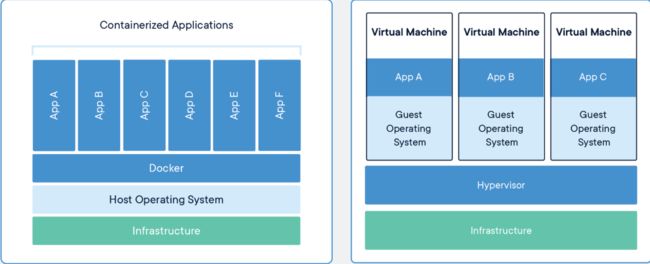
docker容器就是一个虚拟机。(不准确!!!)
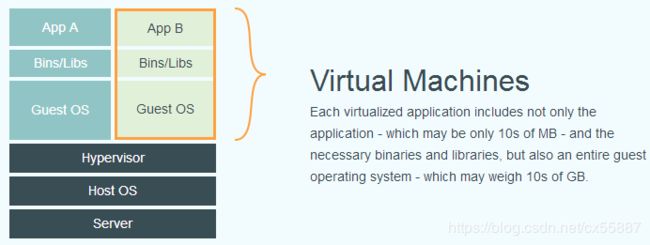
每个虚拟化应用程序不仅包括应用程序(可能只有数十MB)以及必要的二进制文件和库,还包括整个客户机操作系统(可能重数十GB)。

Docker容器仅包含应用程序及其依赖项。它在主机操作系统上的用户空间中作为隔离进程运行,与其他容器共享内核。因此,它具有虚拟机的资源隔离和分配优势,而且具有更高的可移植性和效率。
docker的优势
作为一种新兴的虚拟化方式,Docker 跟传统的虚拟化方式相比具有众多的优势。
1.更高效的利用系统资源
docker对系统资源的利用率更高,无论是应用执行速度,内存损耗或者文件存储速度,都要比传统虚拟机技术更高效。因此,相比虚拟机技术,一个相同配置的主机往往可以运行更多数量的应用。
2.更快速的启动时间
传统的虚拟机技术启动应用服务往往需要数分钟,而docker容器应用,由于直接运行于宿主内核,无需启动完整的操作系统,因此可以做到秒级,甚至毫秒级的启动时间,大大的节约了开发测试,部署的时间。
3.一致的运行环境
开发过程中常见的一个问题是环境一致问题,由于开发环境,测试环境,生产环境不一致,导致有些bug并未在开发过程中发现。而docker的镜像提供了除内核外完整的运行时环境(库、依赖),确保环境一致性,从而不会在出现“这段代码在我机器上没问题”这类问题。
4.持续支付和部署
docker不像传统的软件交付方式那样,只把代码以及说明文档之类的给你就完了,而是直接给你一个docker镜像作为标准的交付件,这个标准件不仅包括了应用代码本身,还包括了代码运行需要的OS等整体依赖环境。
对开发和运维人员来说,最希望就是一次创建和部署,可以在任意的地方运行。
使用 Docker 可以通过定制应用镜像来实现持续集成、持续交付。开发人员可以通过 Dockerfile 来进行镜像构建,并结合持续集成(Continuous Integration) 系统进行集成测试,而运维人员则可以直接在生产环境中快速部署该镜像,甚至结合持续部署(Continuous Delivery/Deployment) 系统进行自动部署。
而且使用 Dockerfile 使镜像构建透明化,不仅仅开发团队可以理解应用运行环境,也方便运维团队理解应用运行所需条件,帮助更好的生产环境中部署该镜像。
5.更轻松的迁移
由于docker确保了执行环境的一致性,使得应用的迁移更加的容易。docker可以在很多平台上运行,无论是物理机、虚拟机、公有云、私有云、甚至是笔记本、其运行结果是一致的。因此用户可以很轻易的将在一个平台上运行的应用,迁移到另一个平台上,而不用担心运行环境的变化导致应用无法正常运行的情况。
6.更轻松的维护和拓展
docker使用的分层存储以及镜像的技术,使得应用重复部分的复用更为容易,也使得应用的维护更新更加简单,基于基础镜像进一步扩展镜像也变得十分简单。此外,docker团队同各个开源项目团队一起维护了一大批高质量的官网镜像,既可以直接在生产环境使用,又可以作为基础进一步定制,大大的降低了应用服务的镜像制作成本。
对比传统虚拟机总结
| 特性 | 容器 | 虚拟机 |
|---|---|---|
| 启动 | 秒级 | 分钟级 |
| 硬盘使用 | 一般为 MB | 一般为 GB |
| 性能 | 接近原生 | 弱于 |
| 系统支持量 | 单机支持上千个容器 | 一般几十个 |
感受一下docker的便利性
Docker安装文档
k8s文档中关于docker安装
案例1:为了保证宿主机的纯净,启动一个linux环境:
docker run -it -d centos
案例2:部署nginx
docker run -d -p 80:80 nginx:1.14-alpine
案例3: 部署MySQL5.7
docker run -d -p 3306:3306 -e MYSQL_ROOT_PASSWORD='111111' mysql:5.7.20
部署DOClever:64.115.4.15
一、docker的核心技术
Docker主要是使用了一些已有的技术实现的,主要的核心技术是Namespaces、Cgroup和UnionFS。
Namespaces
命名空间(Namespaces) 是Linux系统提供的一种内核级别的环境隔离方法,Docker 就是利用的这种技术来实现容器环境隔离的。Linux Namnespace提供了对UTS、IPC、mount、PID、network、User 等隔离机制。
1、UTS Namespace
UTS为Unix Timesharing System的简称。
UTS namespace主要是用来隔离hostname和domainname两个系统标识的。
2、IPC Namespace
IPC Namespace主要提供了进程间通信的隔离能力。使消息队列处于不同的名称空间中。
3、PID Namespace
PID Namespace用来隔离进程。让每个容器的进程PID使用独立的名称空间。
4、Network Namespace
Network Namespace是用来隔离网络。Network Namespace可以让每个容器拥有自己的网络设备、端口、IP 地址等。因为其网络是完全隔离的,所以每个Namespace下的端口不会产生任何冲突。
既然完全隔离了,容器与外部之间需要通信该怎么办?在Docker中可以通过虚拟网桥来实现。
5、Mount Namespace
MountNamespace用来隔离各个进程看到的挂载点视图。在不同Namespace中的进程看到的文件系统层次是不一样的,不同的Namespace 进行mount和umount 操作只会对自己的Namespace内的文件系统产生影响,对其他的Namespace没有影响。
6、User Namespace
User Namespace可以用来隔离用户的用户组ID。在不同的User Namespace下进程的UserID和Group ID是不同的。
Cgroups
1、什么是 Cgroups
Cgroups是Linux系统中提供的对一组进程及其子进程进行资源(CPU、 内存、存储和网络等)限制、控制和统计的能力。
Cgroup可以直接通过操作Cgroup文件系统的方式完成使用。例如,使用mount -t cgroup cgroup /cgroup命令进行操作,此时就会在/cgroup下生成很多默认的文件,这就创建一个Cgroup,在这个目录下每创建一个目录就表示创建了一个子Cgroup。进入子目录会发现里面会生成一些文件与上层Cgroup即/cgroup目录内容大致相同。这就是Cgroup文件系统的树形层次结构。
创建完Cgroup之后,可以为其分配可用的资源并将不同的进程放进去。当创建完第一-个Cgroup时,系统会把所有的进程都放到主Cgroup中,可以查看Cgroup中的tasks文件来查看此Cgroup中的进程PID;同样可以通过在tasks 中添加对应的进程PID,会把该进程放入该Cgroup中。但需要注意,如果在子Cgroup中添加-一个进程,则子Cgroup的上层Cgroup中的tasks文件中也会有这个PID,因为子Cgroup属于上层Cgroup,所以子Cgroup中的进程也同时会属于上层Cgroup,但是同一层级的Cgroup却不能同时拥有同一个进程。比如A和B这2个Cgroup是同属于C的子Cgroup,那么A和B就不能同时拥有同一个进程。至于每个Cgroup中的资源配置量都是通过设置当前Cgroup的子系统来配置的。
Cgroups为不同的资源定义了各自的Cgroup子系统,来实现对资源的具体管理。Cgroup实现的子系统及其实现的功能如下。
- devices:设备权限控制。
- cpuset:分配指定的CPU和内存节点。
- cpu: 控制CPU占用率。
- cpuacct:统计CPU的使用情况。
- memory: 限制内存的使用.上限。
- freezer:暂停Cgroup中的进程。
- net_cls: 配合traffic controller限制网络带宽。
- net_prio: 可以动态控制每个网卡流量的优先级。
- blkio: 限制进程的块设备I/O。
- ns: 使不同Cgroups中的进程使用不同的Namespace。
2、Cgroups的使用
可以使用mount -t cgroup cgroup /cgroup命令创建cgroups,其中可以通过-o参数添加子系统,如命令mount -t cgroup -o cpu、cpuset、 memory cgroup /cgroup。这个命令表示创建了一个名为cgroup的层级,并附加了cpu、cpuset、 memory 三个子系统,并把层级挂载到/cgroup目录上。但实际执行命令时会报出already mounted错误,且执行不成功。这是因为该命令一般在Linux发行版启动时就已经执行了,对应的子系统的Cgroup已经被创建并挂载了。并且虽然cgroupfs可以挂载在任意目录中,但是标准挂载点是/sys/fs/cgroup目录并且在启动时已经挂载上了,所以一般并不需要执行该命令。由于系统的/sys/fs/cgroup目录已经挂载了各种cgroupfs,可以直接在该Cgroup上进行操作。
首先查看/sys/fs/cgroup,如下所示。
[root@localhost ~]$ ll /sys/fs/cgroup/
'总用量 0
drwxr-xr-x 4 root root 0 3月 14 2019 blkio
lrwxrwxrwx 1 root root 11 3月 14 2019 cpu -> cpu,cpuacct
lrwxrwxrwx 1 root root 11 3月 14 2019 cpuacct -> cpu,cpuacct
drwxr-xr-x 4 root root 0 3月 14 2019 cpu,cpuacct
drwxr-xr-x 3 root root 0 3月 14 2019 cpuset
drwxr-xr-x 4 root root 0 3月 14 2019 devices
drwxr-xr-x 3 root root 0 3月 14 2019 freezer
drwxr-xr-x 3 root root 0 3月 14 2019 hugetlb
drwxr-xr-x 4 root root 0 3月 14 2019 memory
lrwxrwxrwx 1 root root 16 3月 14 2019 net_cls -> net_cls,net_prio
drwxr-xr-x 3 root root 0 3月 14 2019 net_cls,net_prio
lrwxrwxrwx 1 root root 16 3月 14 2019 net_prio -> net_cls,net_prio
drwxr-xr-x 3 root root 0 3月 14 2019 perf_event
drwxr-xr-x 3 root root 0 4月 22 09:21 pids
drwxr-xr-x 4 root root 0 3月 14 2019 systemd
可以看到/sy/fs/cgroup目录下有很多子目录,分别对应拥有对应子系统的Cgroup, 以cpuset为例,查看cpuset目录,如下所示。
[root@localhost ~]$ ls -l /sys/fs/cgroup/cpuset/
总用量 0
-rw-r--r-- 1 root root 0 3月 14 2019 cgroup.clone_children
--w--w--w- 1 root root 0 3月 14 2019 cgroup.event_control
-rw-r--r-- 1 root root 0 3月 14 2019 cgroup.procs
-r--r--r-- 1 root root 0 3月 14 2019 cgroup.sane_behavior
-rw-r--r-- 1 root root 0 3月 14 2019 cpuset.cpu_exclusive
-rw-r--r-- 1 root root 0 3月 14 2019 cpuset.cpus
-rw-r--r-- 1 root root 0 3月 14 2019 cpuset.mem_exclusive
-rw-r--r-- 1 root root 0 3月 14 2019 cpuset.mem_hardwall
-rw-r--r-- 1 root root 0 3月 14 2019 cpuset.memory_migrate
-r--r--r-- 1 root root 0 3月 14 2019 cpuset.memory_pressure
-rw-r--r-- 1 root root 0 3月 14 2019 cpuset.memory_pressure_enabled
-rw-r--r-- 1 root root 0 3月 14 2019 cpuset.memory_spread_page
-rw-r--r-- 1 root root 0 3月 14 2019 cpuset.memory_spread_slab
-rw-r--r-- 1 root root 0 3月 14 2019 cpuset.mems
-rw-r--r-- 1 root root 0 3月 14 2019 cpuset.sched_load_balance
-rw-r--r-- 1 root root 0 3月 14 2019 cpuset.sched_relax_domain_level
-rw-r--r-- 1 root root 0 3月 14 2019 notify_on_release
-rw-r--r-- 1 root root 0 3月 14 2019 release_agent
drwxr-xr-x 4 root root 0 4月 29 14:55 system.slice
-rw-r--r-- 1 root root 0 3月 14 2019 tasks
可以看到里面有很多的控制文件,其中以cpuset开头的是cpuset子系统产生的,剩下的是由Cgroup产生的。前文已经提到过,默认所有进程的PID都是在Cgroup的根目录的tasks文件中,通过mkdir创建一个childA目录,就创建了一个子Cgroup,如下所示。
[root@localhost cpuset]$ mkdir childA
接着进入childA目录对该子Cgroup进行配置,可以通过修改文件的方式进行配置,如下所示。
[root@localhost cpuset]# echo 0 > childA/cpuset.cpus
[root@localhost cpuset]# echo 0 > childA/cpuset.mems
两个命令分别表示限制Cgroup里的进程只能在0号CPU上运行,并只会从0号内存节点分配内存。接下来是给Cgroup分配进程,上文也已经提到通过修改tasks的方式把进程添加到当前Cgroup中,如下所示。
[root@localhost cpuset]# echo $$ >childA/tasks
上面的命令表示把当前进程添加到Cgroup中,其中$$变量表示当前进程的PID。这时进程的所有子进程也会被自动地添加到Cgroup中,并受到该Cgoup资源的限制。
UnionFS
1、什么是UnionFS
UnionFS(联合文件系统)是把不同物理位置的目录合并到同一个目录中的文件系统服务。其早期是应用在LiveCD领域的,通过联合文件系统可以非常快速地引导系统初始化或检测磁盘等硬件资源。这是因为只需要把CD只读挂载到特定目录,然后在其上附加一层可读写的文件层,对文件的任何变动修改都会被添加到新的文件层内,这种技术被称为写时复制。
写时复制是一种可以有效节约资源的技术,它被很好地应用在Docker镜像上。其思想是如果有一个资源需要被重复利用,在没有任何修改的情况下,新旧实例会共享资源,并不需要进行复制,如果有实例需要对资源进行任何的修改,并不会直接修改资源,而是会创建一个新的资源并在其上进行修改,这样原来的资源并不会进行任何修改,而是与新创建的资源结合在外,表现为修改后的资源状态。这样做可以显著地减轻对未修改资源的复制而带来的资源消耗问题。
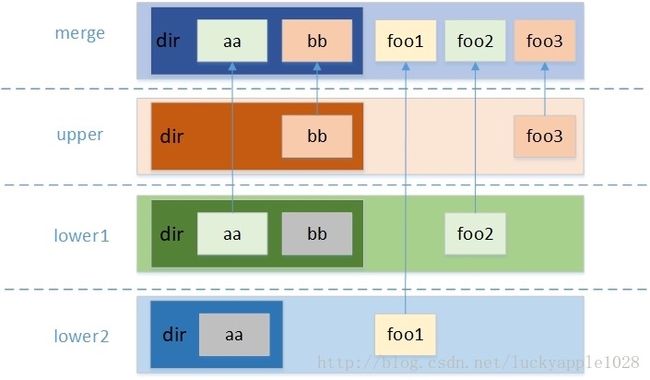
下面通过讲解在Docker中如何使用UnionFS更深入地理解写时复制。
2、UnionFS在Images中的使用
一个最常见的 rootfs,或者说容器镜像,会包括如下所示的一些目录和文件,比如 /bin,/etc,/proc 等等。Docker在镜像的设计中,引入了层(layer)的概念。也就是说,用户制作镜像的每一步操作,都会生成一个层,也就是一个增量 rootfs。
在 docker 架构中,当 docker daemon 为docker容器挂载 rootfs 时,沿用了 Linux 内核启动时的做法,即将 rootfs 设为只读模式。在挂载完毕之后,利用联合挂载(union mount)技术在已有的只读 rootfs 上再挂载一个读写层。这样,可读写的层处于 docker 容器文件系统的最顶层,其下可能联合挂载了多个只读的层,只有在 docker 容器运行过程中文件系统发生变化时,才会把变化的文件内容写到可读写层,并隐藏只读层中的旧版本文件。
目前docker在使用的文件系统包括但不限于以下这几种:aufs, device mapper, btrfs, overlayfs, vfs, zfs。aufs是ubuntu 常用的,device mapper 是 centos,btrfs 是 SUSE,overlayfs ubuntu 和 centos 都会使用,vfs 和 zfs 常用在 solaris 系统。现在最新的docker版本中默认两个系统都是使用的overlay2。之前centos有一段时间使用了device mapper,但其性能不佳,所以很多文章不要在centos上面使用docker,现在看来,还是可以使用的。
注意:容器使用的这种文件系统不能持久化数据,当容器关闭后,所有的更改都会丢失,所以当数据需要持久化时用这个命令。
参考文章:https://www.wumingx.com/k8s/docker-rootfs.html
二、docker网络
1、网络原理
这部分主要介绍Docker的网络原理,通过Linux系统模拟实现一个Docker默认网络的方法。
首先对Docker网络的实现原理进行整体简略的介绍,当Docker服务安装并启动后,在主机上输入ifconfig 命令,可以发现主机上多了一个docker0的虚拟网桥,这个网桥为Docker的网络通信提供支持。如图所示,在默认网络情况下,当启动一个Docker容器时,Docker会为容器分配一个IP地址,并通过一对vethpair将容器的eth0绑定到主机的docker0网桥中。
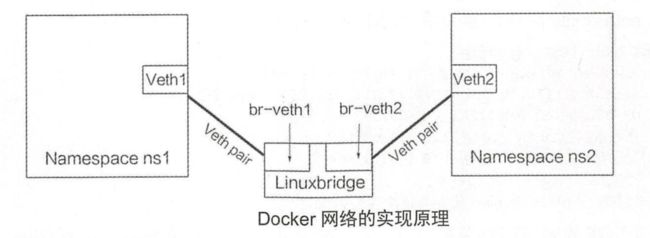
2、模拟实现Docker网络
下面通过Linux系统模拟Docker网络模型,实现上面介绍的网络结构。
- 创建Network Namespace
[root@centos-7 ~]# ip netns add test
[root@centos-7 ~]# ip netns list
test
此时Namespace test 创建成功了,在/var/un/netns 目录中可以看到一个test文件。这个namespace可以理解为是一个docker容器。
当启动一个容器时,Docker 会为容器创建一个Network Namespace,可以看到在/var/run/docker/netns目录下生成一个对应的文件。
- 添加网口到Namespace
先创建veth:
[root@centos-7 ~]# ip link add veth0 type veth peer name veth1
在当前Namespace中可以看到veth0和veth1:
[root@centos-7 ~]# ip link list
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 00:1c:42:60:50:ff brd ff:ff:ff:ff:ff:ff
3: virbr0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default qlen 1000
link/ether 52:54:00:b9:2f:bb brd ff:ff:ff:ff:ff:ff
4: virbr0-nic: <BROADCAST,MULTICAST> mtu 1500 qdisc pfifo_fast master virbr0 state DOWN mode DEFAULT group default qlen 1000
link/ether 52:54:00:b9:2f:bb brd ff:ff:ff:ff:ff:ff
5: veth1@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 7a:51:22:e3:a6:15 brd ff:ff:ff:ff:ff:ff
6: veth0@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether a6:78:43:74:23:33 brd ff:ff:ff:ff:ff:ff
将veth1加到namespace “ test”:
[root@centos-7 ~]# ip link set veth1 netns test
通过ip link list命令发现,当前Namespapce只能看到veth0,而veth1已经找不到了。
[root@centos-7 ~]# ip link list
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 00:1c:42:60:50:ff brd ff:ff:ff:ff:ff:ff
3: virbr0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default qlen 1000
link/ether 52:54:00:b9:2f:bb brd ff:ff:ff:ff:ff:ff
4: virbr0-nic: <BROADCAST,MULTICAST> mtu 1500 qdisc pfifo_fast master virbr0 state DOWN mode DEFAULT group default qlen 1000
link/ether 52:54:00:b9:2f:bb brd ff:ff:ff:ff:ff:ff
6: veth0@if5: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether a6:78:43:74:23:33 brd ff:ff:ff:ff:ff:ff link-netnsid 0
通过如下命令可以查看test namespace的网口,发现刚刚不见了的veth1。说明veth1已经加入test namespace中。
[root@centos-7 ~]# ip netns exec test ip link list
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
5: veth1@if6: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 7a:51:22:e3:a6:15 brd ff:ff:ff:ff:ff:ff link-netnsid 0
配置test Namespace的网口。可以通过ip netns exec进行配置。
[root@centos-7 ~]# ip netns exec test ifconfig veth1 172.16.0.2/16 up
[root@centos-7 ~]# ip netns exec test ifconfig
veth1: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.16.0.2 netmask 255.255.0.0 broadcast 172.16.255.255
ether 7a:51:22:e3:a6:15 txqueuelen 1000 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
这样一个隔离的容器网络就完成了,又该如何实现容器网络与外部的通信呢?这就需要用到Bridge了。
- 创建网桥
在默认的Network Namespace"下创建test0网桥:
[root@centos-7 ~]# brctl addbr test0
[root@centos-7 ~]# brctl show
bridge name bridge id STP enabled interfaces
test0 8000.000000000000 no
virbr0 8000.525400b92fbb yes virbr0-nic
test0网桥创建成功,其中docker0是Docker服务器自己的网桥。下一步是给test0分配IP地址并生效,充当Gateway:
[root@centos-7 ~]# ip addr add 172.16.0.1/16 dev test0
[root@centos-7 ~]# ip link set dev test0 up
[root@centos-7 ~]# ifconfig test0
test0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.16.0.1 netmask 255.255.0.0 broadcast 0.0.0.0
inet6 fe80::50aa:30ff:fea2:ed27 prefixlen 64 scopeid 0x20<link>
ether 52:aa:30:a2:ed:27 txqueuelen 1000 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 25 bytes 3785 (3.6 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
将veth0"插到"test0 这个Bridge上:
[root@centos-7 ~]# brctl addif test0 veth0
[root@centos-7 ~]# ip link set veth0 up
[root@centos-7 ~]# brctl show test0
bridge name bridge id STP enabled interfaces
test0 8000.a67843742333 no veth0
查看test网络生成了一条直连路由表,现在test网络可以ping通test0了。
[root@centos-7 ~]# ip netns exec test ip route show
172.16.0.0/16 dev veth1 proto kernel scope link src 172.16.0.2
[root@centos-7 ~]# ip netns exec test ping -c 3 172.16.0.1
PING 172.16.0.1 (172.16.0.1) 56(84) bytes of data.
64 bytes from 172.16.0.1: icmp_seq=1 ttl=64 time=0.091 ms
64 bytes from 172.16.0.1: icmp_seq=2 ttl=64 time=0.109 ms
64 bytes from 172.16.0.1: icmp_seq=3 ttl=64 time=0.150 ms
--- 172.16.0.1 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2001ms
rtt min/avg/max/mdev = 0.091/0.116/0.150/0.027 ms
[root@centos-7 ~]# ip netns exec test ping -c 3 172.17.0.1
connect: 网络不可达
但由于没有默认路由,Docker还不能与其他网络相通,通过ping docker0测试发现确实如此。为test网络添加一条默认路由表,测试ping docker0发现成功。
[root@centos-7 ~]# ip netns exec test ip route add default via 172.16.0.1
[root@centos-7 ~]# ip netns exec test ping -c 3 172.17.0.1
PING 172.17.0.1 (172.17.0.1) 56(84) bytes of data.
64 bytes from 172.17.0.1: icmp_seq=1 ttl=64 time=0.091 ms
64 bytes from 172.17.0.1: icmp_seq=2 ttl=64 time=0.109 ms
64 bytes from 172.17.0.1: icmp_seq=3 ttl=64 time=0.150 ms
--- 172.17.0.1 ping statistics ---
现在的test网络可以与主机相通了,但还不能访问外部网络,因为icmp包回来时找不到目的地,也就找不到172.17.0.2了,可以通过iptables来解决。
[root@centos-7 ~]# ip netns exec test ping -c 3 114.114.114.114
hang住...
[root@centos-7 ~]# iptables -t nat -A POSTROUTING -s 172.16.0.0/16 ! -o test0 -j MASQUERADE
[root@centos-7 ~]# ip netns exec test ping -c 3 114.114.114.114
PING 114.114.114.114 (114.114.114.114) 56(84) bytes of data.
64 bytes from 114.114.114.114: icmp_seq=1 ttl=127 time=10.9 ms
64 bytes from 114.114.114.114: icmp_seq=2 ttl=127 time=15.4 ms
64 bytes from 114.114.114.114: icmp_seq=3 ttl=127 time=14.6 ms
--- 114.114.114.114 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2005ms
rtt min/avg/max/mdev = 10.923/13.666/15.444/1.972 ms
可以看出添加完iptables规则后已经可以正常访问外网了。这样一个类Docker的网络就完成了,其实Docker的网络相对会比这复杂很多,但基本实现原理方法是一样的。
3、端口映射原理
Iptables的DNAT规则。
三、docker使用
docker命令列表

查看命令帮助:docker COMMAND --help
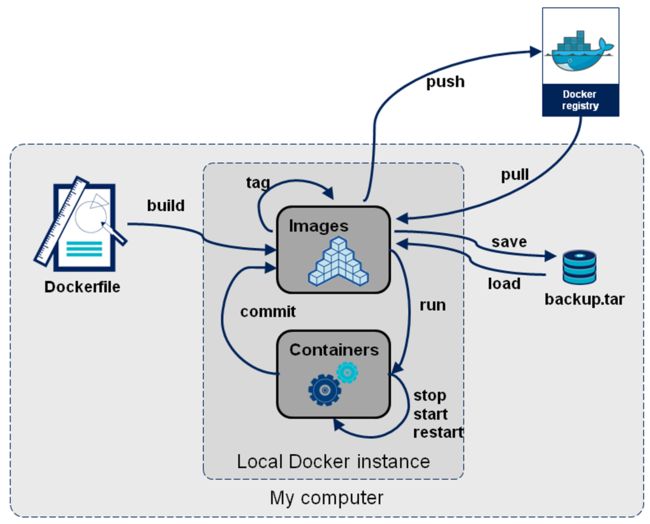
docker search查找镜像
[root@localhost ~]# docker search centos #搜索远程仓库的镜像
INDEX NAME DESCRIPTION STARS OFFICIAL AUTOMATED
docker.io docker.io/centos The official build of CentOS. 3939 [OK]
docker.io docker.io/ansible/centos7-ansible Ansible on Centos7 103 [OK]
docker.io docker.io/jdeathe/centos-ssh CentOS-6 6.9 x86_64 / CentOS-7 7.4.1708 x8... 91 [OK]
......
docker search可能搜索到的比较少,例如centos的official分支只有latest版本,如果需要其他版本,可以使用https://hub.docker.com/进行搜索。
Docker镜像命名的规则:镜像仓库地址/用户名(或项目名)/镜像名称:tag标签;如果镜像仓库地址缺省,则为dockerhub,即docker.io;如果是私有仓库,一般有用户名或项目名,如果缺省,则为library;如果tag缺省,则为latest。
docker images查看本机已经存在的镜像
新版本中,使用docker image ls .
docker pull拉取镜像
Docker registry是存储容器镜像的仓库,用户可以通过Docker client与Docker registry进行通信,以此来完成镜像的搜索、下载和 上传等相关操作。Docker Hub是由Docker公司在互联网上提供的一个镜像仓库,提供镜像的公有与私有存储服务,它是用户最主要的镜像来源。除了Docker Hub外,用户还可以自行搭建私有服务器来实现镜像仓库的功能。
格式:docker pull [OPTIONS] NAME[:TAG]
[root@localhost ~]# docker pull docker.io/centos
docker push推送镜像
格式:docker push[OPTIONS] NAME[:TAG]
无论是pull还是push,如果镜像仓库是私有仓库,则需要登录后才能进行相关的操作。
docker login|logout URL
[root@k8s-node01 ~]# docker login registry.cn-qingdao.aliyuncs.com
Username: admin
Password:
docker load从文件中导入镜像
docker load -i /path/to/image #-i指定导入的镜像的归档文件
docker save将镜像保存为归档文件
docker save -o /path/to/image image_id
docker run 运行镜像,创建容器
格式:docker run -it REPOSITORY:TAG [COMMAND:-/bin/bash] [ARG]
-
-i: interactive 交互模式,通常与-t同时使用
-
-t:terminate 为容器分配一个伪终端
-
-d:daemon 以后台进程运行
-
–rm:参数使容器退出之后自动删除,ps -a的时候是不显示的
-
–name:指定docker run命令运行的容器的名称,如果缺省,Docker将为容器随机分配一个名字
-
-p:端口映射, 宿主机端口:容器的端口
-
-v:用于挂载一个volume,将宿主机目录/文件挂载到容器内的某个目录。格式:
[host-dir]:[container-dir][:rw|ro] -
–volumes-from :卷可以容器间共享和重用
docker run -it -d --rm -p 80:80 --name c1 -v /data/html:/var/share/nginx/html nginx docker run -it -d --rm -p 80:80 --name c2 --volumes-from c1 nginx -
-e:指定环境变量
-
–link:使用
:alias docker run -d --name mysql mysql:5.7.20 docker run -d --name web --link mysql:mysql app:lastest -
–network 指定网络
- –network bridge 缺省默认网络,会自动创建docker0桥,所有容器都会连接到docker0上,并将网关设置为docker0。
- –network none 没有网络,只有lo网卡;这种网络一般会在自定义网络的情况下使用。
- –network container:CANTAINERNAME 与其他已存在的容器共用一个网络,新创建的容器可以与之前的容器使用localhost进行访问。
- –network host 与宿主机共用网络。容器就相当于宿主机上的一个普通进程。
-
–privileged 为容器提供扩展权限
-
-m, --memory bytes:内存限制
-
–cpus decimal:cpu限制
docker start/stop/restart 启动、关闭、重启容器
docker start/stop/restart :用于一个已经存在的容器的启动、关闭、重启,可以指定容器id或容器name。
docker ps 查看正在运行的容器
docker ps :默认显示当前正在运行的容器
docker ps -a :显示所有运行过的容器(已分配container id),当前状态可能是运行,也可能是未运行
docker ps -q :–quite,只显示容器ID
新版本中,使用
docker container ls.
docker exec在容器内执行命令
命令格式: docker exec -it
[root@localhost ~]# docker exec -it 1592daced897 /bin/bash
docker rm删除容器
删除容器:docker rm CONTAINERID [CONTAINERID…]
删除所有的容器:docker rm $(docker ps -a -q)
docker rmi删除镜像
删除镜像:docker rmi IMAGE [IMAGE…]
docker commit从容器创建一个新的镜像
docker commit命令可以将一个容器固化为一个新的镜像。当需要制作特定的镜像时,会进行修改容器的配置,如在容器中安装特定工具等,通过commit命令可以将这些修改保存起来,使其不会因为容器的停止而丢失。
使用方法如下:
docker commit [OPTIONS] CONTAINER [REPOSITORY[ :TAG]]
提交保存时,只能选用正在运行的容器(即可以通过docker ps查看到的容器)来制作新的镜像。在制作特定镜像时,直接使用commit命令只是一个临时性的辅助命令,不推荐使用。官方建议通过docker build命令结合Dockerfile创建和管理镜像。
docker inspect查看镜像和容器的详细信息
docker inspect命令可以查看镜像和容器的详细信息,默认会列出全部信息,可以通过–format参数来指定输出的模板格式,以便输出特定信息。
使用方法如下:
docker inspect [OPTIONS] CONTAINER| IMAGE [CONTAINER | IMAGE...]
#查看容器的内部IP
docker inspect --format='{{.NetworkSettings.IPAddress}}' ee36
172.17.0.8
#查看容器卷
docker inspect --format "{{.Volumes}}" bc8e
docker cp宿主机、容器文件互拷
使用方法:
docker cp [OPTIONS] CONTAINER:SRC_PATH DEST_PATH
docker cp [OPTIONS] SRC_PATH CONTAINER:DEST_PATH
☆☆☆、容器使用建议:
1、docker容器的日志全部输出到控制台。
2、应用做健康监测的接口。
3、如果使用服务器文件系统目录,要使用相对目录。尤其不要出现windows目录,例如e:\myapp\upload
4、接上例。如果应用运行过程中,会在服务器上产生数据文件(并非临时文件)。例如用户上传的附件等。这些操作一定要通知运维。因为默认数据全部放在数据中心里(mysql、oss等),如果存放在服务器上,需要对这些文件进行备份处理,以免丢失数据。尤其是docker运行的情况下。
四、Dockefile指令
Dockerfile说明
- 井号开头的行为注释行。
- 非井号开头的行为指令行,指令是不区分大小写的,但是建议指令使用大写。
- Dockerfile文件中的第一个非指令行必须为FROM指令,用于指定构建镜像使用的基础镜像。
FROM openjdk:8u201-jdk-alpine3.9
#*****Alpine系统设置*****
RUN echo http://mirrors.aliyun.com/alpine/v3.9/main > /etc/apk/repositories && \
echo http://mirrors.aliyun.com/alpine/v3.9/community >> /etc/apk/repositories && \
#*****时区设置*****
apk -U --no-cache add tzdata && \
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && \
#*****添加系统字体(ttf-dejavu)、字体管理软件(fontconfig)*****
apk -U --no-cache add ttf-dejavu fontconfig && \
#*****其他常用软件*****
apk -U --no-cache add ca-certificates curl bash
#*****添加中文字体,前提:已经安装字体管理软件(fontconfig)*****
COPY chinese /usr/share/fonts/chinese
#*****设置环境变量*****
ENV PS1="[\u@\h \W]\$"
#*****entrypoint脚本*****
COPY docker-entrypoint.sh /usr/local/bin/
RUN chmod +x /usr/local/bin/docker-entrypoint.sh
#-------------------------------------------------------
#*****Tomcat相关设置*****
#-------------------------------------------------------
#*****设置Tomcat环境变量*****
ARG TOMCAT_VERSION="8.5.56"
ENV TOMCAT_VERSION=${TOMCAT_VERSION} \
CATALINA_HOME="/usr/local/tomcat" \
CLASSPATH=".:$JAVA_HOME/lib:$JAVA_HOME/jre/lib"
ENV PATH="${CATALINA_HOME}/bin:$PATH"
#*****安装tomcat*****
ADD https://mirrors.aliyun.com/apache/tomcat/tomcat-8/v${TOMCAT_VERSION}/bin/apache-tomcat-${TOMCAT_VERSION}.tar.gz /usr/local
RUN set -ex; \
tar xf /usr/local/apache-tomcat-${TOMCAT_VERSION}.tar.gz -C /usr/local/ && \
mv /usr/local/apache-tomcat-${TOMCAT_VERSION} ${CATALINA_HOME} && \
rm -rf ${CATALINA_HOME}/webapps/* /usr/local/apache-tomcat-${TOMCAT_VERSION}.tar.gz
#*****启动入口*****
ENTRYPOINT ["docker-entrypoint.sh"]
EXPOSE 8080
WORKDIR $CATALINA_HOME
CMD ["catalina.sh", "run"]
#-------------------------------------------------------
#*****运行应用相关Dockerfile*****
#-------------------------------------------------------
# FROM registry.cn-qingdao.aliyuncs.com/rcyj/tomcat:8.5.54-openjdk8u201-alpine3.9
# LABEL maintainer lijuzhangFROM
FROM指令是最重的一个且必须为Dockerfile文件开篇的第一个非注释行,用于为image构建过程指定基准镜像,后续的指令运行于此基准镜像所提供的运行环境
实践中,基准镜像可以是任何可用镜像文件,默认情况下,docker build会在docker主机上查找指定的镜像文件,在其不存在时,则会从Docker Hub Registry上拉取所需的镜像文件。如果找不到指定的镜像文件,dockerbuild会返回一个错误信息
语法:
FROM <repository>[:<tag>]
或
FROM <resository>@<digest>]
说明:
<reposotiry>: 指定作为base image的名称;
<tag>: base image的标签,为可选项,省略时默认为latest;
最佳实践:
1、尽可能使用当前官方仓库作为你构建镜像的基础。推荐使用 Alpine 镜像,因为它被严格控制并保持最小尺寸(5MB左右),但它仍然是一个完整的发行版。
2、可以使用多阶段构建
FROM centos:7.5.1804 as base
...
...
#多阶段构建
from centos:7.5.1804
COPY --from=base /usr/local/jdk* $JAVA_HOME/
MAINTANIER(已废弃)
MAINTANIER (depreacted),使用LABEL代替。
用于让Dockerfile制作者提供本人的详细信息
Dockerfile并不限制MAINTAINER指令可在出现的位置,但推荐将其放置于FROM指令之后
语法:
MAINTAINER
MAINTAINER "
LABEL
LABEL指令将元数据添加到图像。你可以给镜像添加标签来帮助组织镜像、记录许可信息、辅助自动化构建等。
语法:
LABEL
一个LABEL是一个key-value对,如果你的字符串中包含空格,必须将字符串放入引号中或者对空格使用反斜线转义。如果字符串内容本身就包含引号,必须对引号使用转义。
一个image可以有多个LABEL,也可以在一行中指定多个LABEL.
# Set one or more individual labels
LABEL com.example.version="0.0.1-beta"
LABEL vendor="ACME Incorporated"
LABEL com.example.release-date="2015-02-12"
LABEL com.example.version.is-production=""
一个镜像可以包含多个标签,但建议将多个标签放入到一个 LABEL 指令中。
# Set multiple labels at once, using line-continuation characters to break long lines
LABEL vendor=ACME\ Incorporated \
com.example.is-beta= \
com.example.is-production="" \
com.example.version="0.0.1-beta" \
com.example.release-date="2015-02-12"
RUN
用于指定docker build过程中运行的程序,其可以是任何命令
语法:
RUN 或
RUN ["
- 第一种格式中,
"/bin/sh -c"来运行它,这意味着此进程在容器中的PID不为1,不能接收Unix信号,因此,当使用docker stop命令停止容器时,此进程接收不到SIGTERM信号; - 第二种语法格式中的参数是一个JSON格式的数组,其中
"/bin/sh -c"来发起,因此*常见的shell操作如变量替换以及通配符(?,等)替换将不会进行;不过,如果要运行的命令依赖于此shell特性的话,可以将其替换为类似下面的格式。RUN ["/bin/bash", "-c", "。注意: json数组中, 要使用双引号", " "] - 为了保持
Dockerfile文件的可读性,可理解性,以及可维护性,建议将长的或复杂的RUN指令用反斜杠\分割成多行。
FROM alpine:3.9
RUN echo http://mirrors.aliyun.com/alpine/v3.9/main > /etc/apk/repositories && \
echo http://mirrors.aliyun.com/alpine/v3.9/community >> /etc/apk/repositories && \
#*****时区设置*****
apk -U --no-cache add tzdata && \
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && \
#*****添加系统字体(ttf-dejavu)、字体管理软件(fontconfig)*****
apk -U --no-cache add ttf-dejavu fontconfig && \
#*****其他常用软件*****
apk -U --no-cache add ca-certificates curl bash
centos安装软件的最佳实践:
RUN yum update -y && yum install -y wget && yum clean all && rm -rf /var/cache/yum/*
alpine安装软件的最佳实践:
示例1:
RUN apk -U --no-cache add curl bash
示例2:
$ apk -U --no-cache add --virtual .name git openssh-client
使用git openssh-client做相关的操作后,如果后续不再使用,可以使用如下命令对其进行删除。
$ apk del .name
CMD
类似于RUN指令,CMD指令也可用于运行任何命令或应用程序,不过,二者的运行时间点不同
- RUN指令运行于映像文件构建过程中,而CMD指令运行于基于Dockerfile构建出的新映像文件启动一个容器时
- CMD指令的首要目的在于为启动的容器指定默认执行命令,且其运行结束后,容器也将终止;不过,CMD指定的命令其可以被
docker run的命令行选项所覆盖。 - 在Dockerfile中可以存在多个CMD指令,但仅最后一个会生效。
语法:
CMD 或
CMD ["或
CMD [" 该方式与ENTRYPOINT命令一起使用,为其提供默认参数
语法格式的意义同RUN
ENTRYPOINT
类似CMD指令的功能,用于为容器指定默认运行程序。
与CMD不同的是,由ENTRYPOINT启动的程序不会被dockerrun命令行指定的参数所覆盖,而且,这些命令行参数会被当作参数传递给ENTRYPOINT指定指定的程序。不过,docker run命令的--entrypoint选项的参数可覆盖ENTRYPOINT指令指定的程序
语法:
ENTRYPOINT
ENTRYPOINT ["
-
docker run命令传入的命令参数会覆盖CMD指令的内容并且附加到ENTRYPOINT命令最后做为其参数使用。
ENTRYPOINT的最佳用处是设置镜像的主命令,允许将镜像当成命令本身来运行(用CMD提供默认选项)。ENTRYPOINT指令常常结合一个辅助脚本使用。当ENTRYPOINT、CMD同时存在dockerfile中,容器启动后,会运行
ENTRYPOINT+CMD,即CMD作为ENTRYPOINT的参数;如果docker run给出参数,docker run参数会覆盖CMD,即运行ENTRYPOINT+docker run参数。 -
Dockerfile文件中也可以存在多个ENTRYPOINT指令,但仅有最后一个会生效
EXPOSE
用于为容器打开指定要监听的端口,以实现与外部通信。因此,你应该为你的应用程序使用常见的端口。例如,提供 Apache web 服务的镜像应该使用 EXPOSE 80,而提供 MongoDB 服务的镜像使用 EXPOSE 27017。
对于外部访问,用户可以在执行 docker run 时使用一个标志来指示如何将指定的端口映射到所选择的端口。
语法:
EXPOSE
- EXPOSE指令可一次指定多个端口,例如
EXPOSE 11211/udp 11211/tcp - EXPOSE指定端口一般为应用监听端口,实际上它只是起到一个注释说明作用。此外如果使用-P,会自动分配一个随机宿主机的端口映射到EXPOSE端口上。
ENV
用于为镜像定义所需的环境变量,并可被Dockerfile文件中位于其后的其它指令(如ENV、ADD、COPY等)所调用,调用格式为$VARYABLE_NAME或${VARYABLE_NAME},而且支持${VARYABLE_NAME:-word}、${VARYABLE_NAME:+word}。
语法:
ENV 或
ENV
- 第一种格式中,
- 第二种格式可用一次设置多个变量,每个变量为一个
= \)进行转义,也可通过对
ARG
ARG指令定义了一个变量,用户可以在构建时将其传递给docker builder。一般用于定义构建时变量的默认值,该默认值可以在构建命令 docker build 中用--build-arg <参数名>=<值> 来覆盖。
ARG TOMCAT_VERSION="8.5.56"
RUN set -ex; \
tar xf /usr/local/apache-tomcat-${TOMCAT_VERSION}.tar.gz -C /usr/local/ && \
mv /usr/local/apache-tomcat-${TOMCAT_VERSION} ${CATALINA_HOME} && \
rm -rf ${CATALINA_HOME}/webapps/* /usr/local/apache-tomcat-${TOMCAT_VERSION}.tar.gz
ADD
用于从Docker主机复制文件至创建的映像文件。
语法:
COPY 或
COPY ["
- 注意:在路径中有空白字符时,通常使用第二种格式
- 文件复制准则:
- 如果
- 如果指定了多个
- 如果
- 拷贝目录时,可以同时修改目录属主:
COPY --chown=nginx:nginx ${PROJECT_DIR} /usr/share/nginx/html/release
COPY
ADD指令类似于COPY指令,ADD支持使用TAR文件和URL路径。
语法:
ADD 或
ADD ["
- 文件复制准则:
- 同COPY指令
- 如果
/ - 如果
- 如果
ADD最佳实践:将本地tar文件自动解压到镜像中,对于其他不需要
ADD的自动解压功能的文件或目录,你应该使用COPY。虽然
ADD和COPY功能类似,但一般优先使用COPY。因为它比ADD更透明。COPY只支持简单将本地文件拷贝到容器中,而ADD有一些并不明显的功能(比如本地 tar 提取和远程 URL 支持)。因此,ADD的最佳用例是将本地tar文件自动提取到镜像中,例如ADD rootfs.tar.xz。如果你的
Dockerfile有多个步骤需要使用上下文中不同的文件。单独COPY每个文件,而不是一次性的COPY所有文件,这将保证每个步骤的构建缓存只在特定的文件变化时失效。例如:COPY requirements.txt /tmp/ RUN pip install --requirement /tmp/requirements.txt COPY . /tmp/如果将
COPY . /tmp/放置在RUN指令之前,只要.目录中任何一个文件变化,都会导致后续指令的缓存失效。为了让镜像尽量小,最好不要使用
ADD指令从远程 URL 获取包,而是使用curl和wget。这样你可以在文件提取完之后删掉不再需要的文件来避免在镜像中额外添加一层。比如尽量避免下面的用法:ADD http://example.com/big.tar.xz /usr/src/things/ RUN tar -xJf /usr/src/things/big.tar.xz -C /usr/src/things RUN make -C /usr/src/things all而是应该使用下面这种方法:
RUN mkdir -p /usr/src/things \ && curl -SL http://example.com/big.tar.xz \ | tar -xJC /usr/src/things \ && make -C /usr/src/things all上面使用的管道操作,所以没有中间文件需要删除。
VOLUME
用于在image中创建一个挂载点目录,以挂载Docker host上的卷或其它容器上的卷。
语法:
VOLUME 或
VOLUME ["
USER
用于指定运行image时的或运行Dockerfile中任何RUN、CMD或ENTRYPOINT指令指定的程序时的用户名或UID
。默认情况下,container的运行身份为root用户。
语法:
USER
- 需要注意的是,
- 镜像构建完成后,通过docker run运行容器时,可以通过-u参数来覆盖所指定的用户。
WORKDIR
用于为Dockerfile中所有的RUN、CMD、ENTRYPOINT、COPY和ADD指定设定工作目录。
语法:
WORKDIR
- 在Dockerfile文件中,WORKDIR指令可出现多次,其路径也可以为相对路径,不过,其是相对此前一个WORKDIR指令指定的路径
- 另外,WORKIDIR也可调用由ENV指定定义的变量。例如:
WORKDIR /var/log
WORKDIR ${WPATH}
- 为了清晰性和可靠性,你应该总是在
WORKDIR中使用绝对路径。另外,你应该使用WORKDIR来替代类似于RUN cd ... && do-something的指令,后者难以阅读、排错和维护。 - 在使用docker run运行容器时,可以通过-w参数覆盖构建时所设置的工作目录。
HEALTHCHECK
不常用,不做解释
SHELL
设置默认的shell解释器。linux上默认的shell为["/bin/sh","-c"]。
语法:
SHELL [“executable”, “parameters”]
-
SHELL指令必须以JSON格式写入Dockerfile
-
SHELL指令可以多次出现。每条SHELL指令都会覆盖所有先前的SHELL指令,并影响所有后续指令
STOPSIGNAL
定义docker stop使用的信号,让PID为1的进程(主进程)来接受此信号。
此信号可以是内核的系统调用表中的无符号数,例如9,或SIGNAME格式的信号名,例如SIGKILL
语法:
STOPSIGNAL signal
ONBUILD
用于在Dockerfile中定义一个触发器。
Dockerfile用于build映像文件,此映像文件亦可作为base image被另一个Dockerfile用作FROM指令的参数,并以之构建新的映像文件。在后面的这个Dockerfile中的FROM指令在build过程中被执行时,将会“触发"创建其base image的Dockerfile文件中的ONBUILD指令定义的触发器。
语法:
ONBUILD
- 尽管任何指令都可注册成为触发器指令,但ONBUILD不能自我嵌套,且不会触发FROM和MAINTAINER指令
- 使用包含ONBUILD指令的Dockerfile构建的镜像应该使用特殊的标签,例如
ruby:2.0-onbuild - 在ONBUILD指令中使用ADD或COPY指令应该格外小心,因为新构建过程的上下文在缺少指定的源文件时会失败。