2018最新安卓面试大全(含BAT,网易,滴滴)----你面不上BAT的原因:面经宝典,都在这里啦
废话不多说,直接进入正题。
童鞋们可以扫码右侧二维码,加入微信群,分享你的面试经历哦~
Java篇
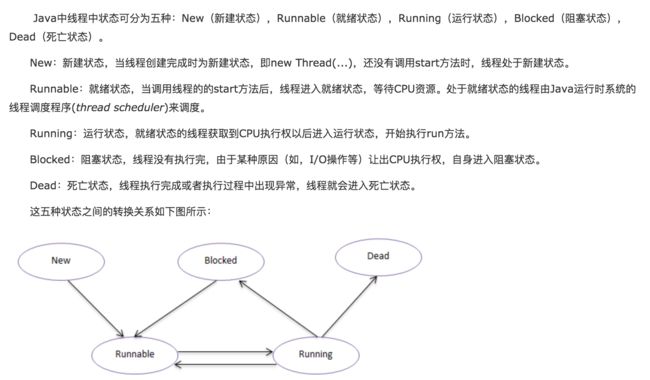
1.Java中sleep、wait、yield、join的区别?
参考文章:
java sleep和wait的区别的疑惑?
多线程中的wait与sleep到底谁释放了锁
sleep() wait() yield() join()用法与区别
Java多线程-(5)线程的优先级、sleep()、yield()、join()
| 比较项| 归属| 是否释放锁|使用范围|是否需要捕获异常|是否能自我唤醒|进入状态|
|: ---- | :----- | :— |:— |:— |:— |:— |:— |
| sleep |Thread类 | 没有释放|任何地方|是|是|Blocked|
| wait | Object类 | 释放 |同步控制方法或者同步控制块中|否|否|Blocked|
|yield|Thread类 |没有释放|任何地方|是|有可能|runnable|
|join|Thread类 |没有释放|任何地方|是|能|runnable|
总结:
sleep是Thread类中的静态方法。无论是在a线程中调用b的sleep方法,还是b线程中调用a的sleep方法,谁调用,谁睡觉。
2.throw和throws有什么区别?
参考文章:
Java中throw和throws的区别
1、throws出现在方法函数头;而throw出现在函数体。
2、throws表示出现异常的一种可能性,并不一定会发生这些异常;throw则是抛出了异常,执行throw则一定抛出了某种异常。
3、两者都是消极处理异常的方式(这里的消极并不是说这种方式不好),只是抛出或者可能抛出异常,但是不会由函数去处理异常,真正的处理异常由函数的上层调用处理。
void doA(int a) throws Exception1,Exception3{
try{
......
}catch(Exception1 e){
throw e;
}catch(Exception2 e){
System.out.println("出错了!");
}
if(a!=b)
throw new Exception3("自定义异常");
}
3.接口和抽象类的区别是什么?
1、Java提供和支持创建抽象类和接口。它们的实现有共同点,不同点在于:
2、接口中所有的方法隐含的都是抽象的。而抽象类则可以同时包含抽象和非抽象的方法。
3、类可以实现很多个接口,但是只能继承一个抽象类
4、类可以不实现抽象类和接口声明的所有方法,当然,在这种情况下,类也必须得声明成是抽象的。
5、抽象类可以在不提供接口方法实现的情况下实现接口。
6、Java接口中声明的变量默认都是final的。抽象类可以包含非final的变量。
7、Java接口中的成员函数默认是public的。抽象类的成员函数可以是private,protected或者是public。
8、接口是绝对抽象的,不可以被实例化。抽象类也不可以被实例化,但是,如果它包含main方法的话是可以被调用的。
4.为什么接口中只能定义常量?
从上一道问题的6,7中我们其实已经可以得到答案了。
接口中只能定义常量,即使你的代码是这样写的:public int a,底层语言也会默认加上public static final int a转为常量,那么这是为什么呢?
我们都知道,接口中不能定义方法的实现,但是抽象类中是可以定义变量、常量以及方法的实现的,所以我们可以将接口看为比抽象类更高层次的抽象,是特殊的抽象类。加入接口可以定义变量,因为接口中的方法都是抽象的,我们无法通过行为,例如set()方法来修改这一属性值。
5.Java支持多继承么?
Java中类不支持多继承,只支持单继承(即一个类只有一个父类)。 但是java中的接口支持多继承,,即一个子接口可以有多个父接口。(接口的作用是用来扩展对象的功能,一个子接口继承多个父接口,说明子接口扩展了多个功能,当类实现接口时,类就扩展了相应的功能)。
6.什么是Java虚拟机?为什么Java被称作是“平台无关的编程语言”?
Java虚拟机是一个可以执行Java字节码的虚拟机进程。Java源文件被编译成能被Java虚拟机执行的字节码文件。
Java是平台无关的语言是指用Java写的应用程序不用修改就可在不同的软硬件平台上运行。平台无关有两种:源代码级和目标代码级。C和C++具有一定程度的源代码级平台无关,表明用C或C++写的应用程序不用修改只需重新编译就可以在不同平台上运行。
Java主要靠Java虚拟机(JVM)在目标码级实现平台无关性。JVM是一种抽象机器,它附着在具体操作系统之上,本身具有一套虚机器指令,并有自己的栈、寄存器组等。但JVM通常是在软件上而不是在硬件上实现。(目前,SUN系统公司已经设计实现了Java芯片,主要使用在网络计算机NC上。另外,Java芯片的出现也会使Java更容易嵌入到家用电器中。)JVM是Java平台无关的基础,在JVM上,有一个Java解释器用来解释Java编译器编译后的程序。Java编程人员在编写完软件后,通过Java编译器将Java源程序编译为JVM的字节代码。任何一台机器只要配备了Java解释器,就可以运行这个程序,而不管这种字节码是在何种平台上生成的。另外,Java采用的是基于IEEE标准的数据类型。通过JVM保证数据类型的一致性,也确保了Java的平台无关性。
从上面可以看出java属于半编译,半解释型语言:
java的编译器先将其编译为class文件,也就是字节码;然后将字节码交由jvm(java虚拟机)解释执行;
7.JAVA中常用的数据结构
参考文章:
JAVA常用数据结构及原理分析
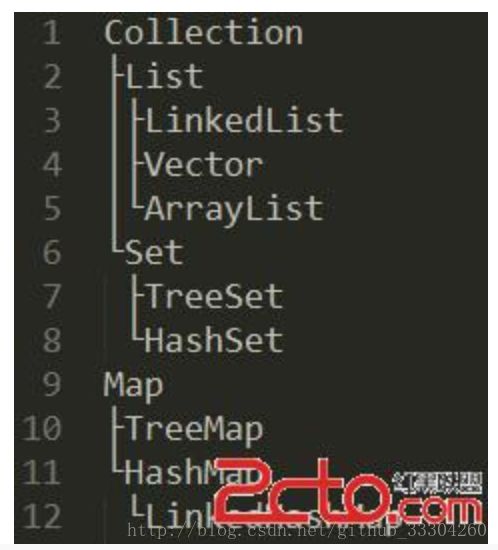
相关问题:
7.1HashMap和Hashtable的区别?
参考文章:
HashMap和Hashtable的区别
HashMap底层实现原理
1.两者最主要的区别在于Hashtable是线程安全,而HashMap则非线程安全
2.HashMap可以使用null作为key,而Hashtable则不允许null作为key
3.两者计算hash的方法不同
- Hashtable计算hash是直接使用key的hashcode对table数组的长度直接进行取模
- HashMap计算hash对key的hashcode进行了二次hash,以获得更好的散列值,然后对table数组长度取摸
4.HashMap和Hashtable的底层实现都是数组+链表结构实现
7.2HashSet和HashMap的区别?

7.3我们能否让HashMap同步?
HashMap可以通过下面的语句进行同步:
Map m = Collections.synchronizeMap(hashMap);
8.synchronized 和volatile 关键字的作用/区别?
作用:
1)保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
2)禁止进行指令重排序。
区别:
volatile 本质是在告诉jvm 当前变量在寄存器(工作内存)中的值是不确定的,需要从主存中读取;synchronized 则是锁定当前变量,只有当前线程可以访问该变量,其他线程被阻塞住。
1.volatile 仅能使用在变量级别;synchronized 则可以使用在变量、方法、和类级别的
2.volatile 仅能实现变量的修改可见性,并不能保证原子性;synchronized 则可以保证变量的修改可见性和原子性
3.volatile 不会造成线程的阻塞;synchronized 可能会造成线程的阻塞。
4.volatile 标记的变量不会被编译器优化;synchronized 标记的变量可以被编译器优化
9.JAVA静态方法是否可以被继承?
参考文章:
JAVA静态方法是否可以被继承?
java中静态属性和静态方法可以被继承,但是没有被重写(overwrite)而是被隐藏.
10.简述class加载各阶段,Class Loader有哪些模型。
在java应用程序开发中,只有被jvm装载的class类型才能在程序中使用。只要生成的字节码符合jvm指令集和文件格式,就可以在jvm上运行,这为java的跨平台性提供条件。
字节码的装载过程分为3个阶段:加载,连接,初始化。其中连接包括3个步骤(验证,准备,解析)。
1)加载:处于class装载的第一个阶段,这时jvm必须完成通过类的全面获取类的二进制数据流,解析类的二进制数据流为方法区内的数据结构,创建java.lang.Class的实例。
2)连接:
- 验证:验证字节码文件,保证加载的字节码是符合规范的。
- 准备:正式为类变量(static修饰的变量)分配内存,并设置内变量的初始值,这些内存都将在方法区进行分配(不包括实例变量)。
- 解析:将类,接口,方法和字段的应用转为直接引用。
3)初始化:如果前面的步骤都没有出现问题,那么表示类可以顺利的装载到系统中。这个时候才会执行java字节码。初始化阶段的主要工作是执行类的初始化方法。
Class Loader是一个对象,主要是对类的请求提供服务,当jvm需要某个类是它根据名称向ClassLoader请求这个类,然后ClassLoader返回这个类的class对象。
1)引导类加载器(Bootstrap Class Loader):它用来加载java的核心库,使用源生代码来实现的。
2)扩展类加载器(Extensions Class Loader):用来加载java的扩展库。jvm的实现会提供一个扩展库目录,该类加载器在目录中寻找并加载java类。
3)系统类加载器(System Class Loader):一般来讲,java应用的类都是由它加载完成的,是根据java的应用类路径来加载java类。
11.多线程死锁的产生以及如何避免死锁?
参考文章:
多线程死锁的产生以及如何避免死锁
死锁:多线程以及多进程改善了系统资源的利用率并提高了系统 的处理能力。然而,并发执行也带来了新的问题——死锁。所谓死锁是指多个线程因竞争资源而造成的一种僵局(互相等待),若无外力作用,这些进程都将无法向前推进。
满足以下四个条件,只要其中任一条件不成立,死锁就不会发生。
- 互斥条件:进程要求对所分配的资源(如打印机)进行排他性控制,即在一段时间内某 资源仅为一个进程所占有。此时若有其他进程请求该资源,则请求进程只能等待。
- 不剥夺条件:进程所获得的资源在未使用完毕之前,不能被其他进程强行夺走,即只能 由获得该资源的进程自己来释放(只能是主动释放)。
- 请求和保持条件:进程已经保持了至少一个资源,但又提出了新的资源请求,而该资源 已被其他进程占有,此时请求进程被阻塞,但对自己已获得的资源保持不放。
- 循环等待条件:存在一种进程资源的循环等待链,链中每一个进程已获得的资源同时被 链中下一个进程所请求。即存在一个处于等待状态的进程集合{Pl, P2, …, pn},其中Pi等 待的资源被P(i+1)占有(i=0, 1, …, n-1),Pn等待的资源被P0占有,如图2-15所示。
12.Java Synchronize 和 Lock 的区别与用法
深入研究 Java Synchronize 和 Lock 的区别与用法
synchronized:在需要同步的对象中加入此控制,synchronized可以加在方法上,也可以加在特定代码块中,括号中表示需要锁的对象。
lock:需要显示指定起始位置和终止位置。一般使用ReentrantLock类做为锁,多个线程中必须要使用一个ReentrantLock类做为对象才能保证锁的生效。且在加锁和解锁处需要通过lock()和unlock()显示指出。所以一般会在finally块中写unlock()以防死锁。
Android篇
1.Activity的生命周期?
一张图带你读懂Activity的生命周期,详细参考:
深入理解Activity的生命周期
Activity状态图、生命周期图
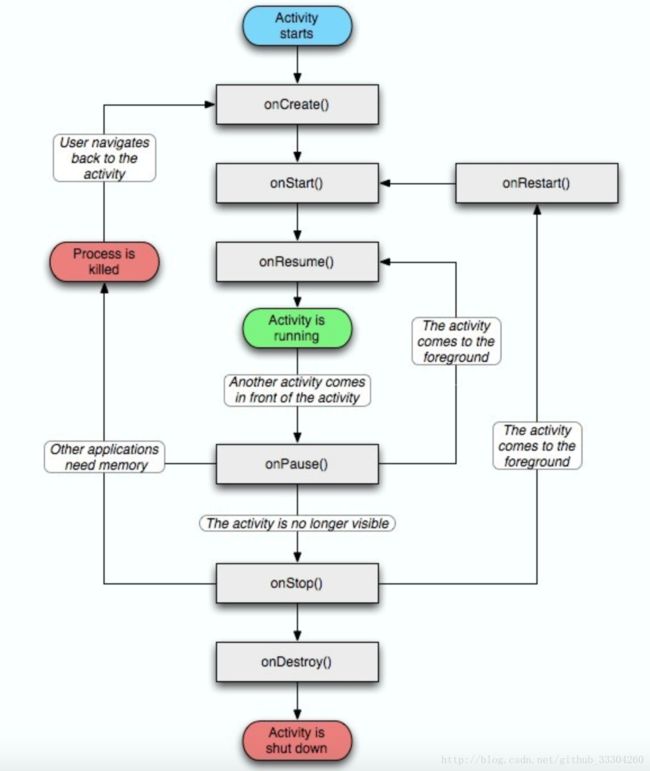
2.什么情况下Activity就不会得到完整的生命周期回调?
- 在onCreate()中调用Activity的finish()方法,这时候会直接进入onDestory(),而不会产生其他中间过程的回调,即onCreate()->onDestory()。这个我们可以应用到类似跳转功能的Activity中,在onCreate()进行逻辑处理后,打开目标Activity,然后finish()。这种情况下,用户不会看到这个Activity,这个Activity充当一个分发者的角色。
- 某个生命周期发生了crash,如在onCreate()中就发生了crash,就不会有下面生命周期的回调了。

3.Service的生命周期
详细参考:Service生命周期
一张图带你看懂Service的生命周期。
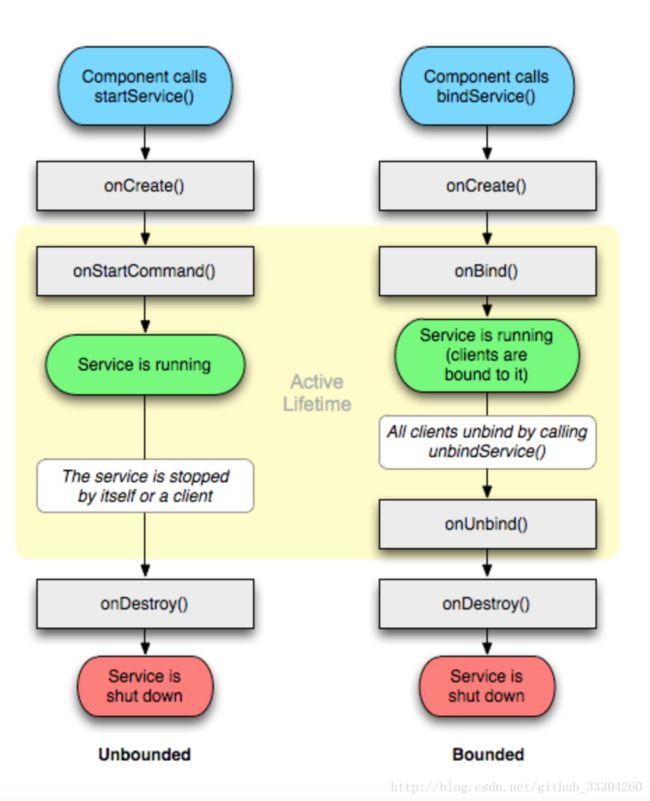
这里需要注意通过 如果一个Service被startService 方法多次启动,那么onCreate方法只会调用一次,onStart将会被调用多次(对应调用startService的次数),并且系统只会创建Service的一个实例。
4.Service是否在main thread中执行, service里面是否能执行耗时的操作?
Service不是独立的进程,也不是独立的线程,它是依赖于应用程序的主线程的,也就是说,在更多时候不建议在Service中编写耗时的逻辑和操作(比如:网络请求,拷贝数据库,大文件),否则会引起ANR。
如果想在服务中执行耗时的任务。有以下解决方案:
- 在service中开启一个子线程
2)可以使用IntentService异步管理服务
3给server开个独立进程
附:在Service中执行的耗时操作最多20秒,BroadcastReceiver是10秒,Activity是5秒。
5.context.startService 和context.bindService应用场景?
跨进程使用
context.bindServer(不过也要看具体业务,如果和activity生命周期关联紧密使用context.bindServer也是可以的)
同一个进程建议使用context.startServer
6.Activity的几种启动模式?
standard 模式
默认模式: 每次激活Activity时都会创建Activity实例,并放入任务栈中。
使用场景:大多数Activity。
singleTop 模式
如果在任务的栈顶正好存在该Activity的实例,就重用该实例( 会调用实例的 onNewIntent() ),否则就会创建新的实例并放入栈顶,即使栈中已经存在该Activity的实例,只要不在栈顶,都会创建新的实例。
使用场景: 如新闻类或者阅读类App的内容页面。
singleTask 模式
如果在栈中已经有该Activity的实例,就重用该实例(会调用实例的 onNewIntent() )。重用时,会让该实例回到栈顶,因此在它上面的实例将会被移出栈。如果栈中不存在该实例,将会创建新的实例放入栈中。
使用场景: 如浏览器的主界面。不管从多少个应用启动浏览器,只会启动主界面一次,其余情况都会走onNewIntent,并且会清空主界面上面的其他页面。
附:每个应用都有一个task(可以理解为进程),singleTask在启动的时候,会先在系统中查找属性值affinity等于它的属性值taskAffinity的任务存在
singleInstance 模式
在一个新栈中创建该Activity的实例,并让多个应用共享该栈中的该Activity实例。一旦该模式的Activity实例已经存在于某个栈中,任何应用再激活该Activity时都会重用该栈中的实例( 会调用实例的 onNewIntent() )。其效果相当于多个应用共享一个应用,不管谁激活该 Activity 都会进入同一个应用中。
使用场景: 如闹铃提醒,将闹铃提醒与闹铃设置分离;电话。singleInstance不要用于中间页面,如果用于中间页面,跳转会有问题,比如:A -> B (singleInstance) -> C,完全退出后,在此启动,首先打开的是B。
附:singleTask 和 singleInstance还有性能上的区别,singleInstance尽量少用,与其说singleInstance独占一个task,还不如说占用一个进程。
7.应用setContentView与LayoutInflater加载解析机制?
参考文章:
Android应用setContentView与LayoutInflater加载解析机制源码分析
看完上面的文章,你需要明白下面几个问题,自行在文章中寻找答案吧!!
1)xml怎么显示的?
2)在java文件设置Activity的属性时为什么必须在setContentView方法之前调用requestFeature()?
3)Activity调运setContentView方法自身会显示布局吗?
总结:
1)创建一个DecorView的对象mDecor,该mDecor对象将作为整个应用窗口的根视图。
2)依据Feature等style theme创建不同的窗口修饰布局文件,并且通过findViewById获取Activity布局文件该存放的地方(窗口修饰布局文件中id为content的FrameLayout)。
3)将Activity的布局文件添加至id为content的FrameLayout内。
4)当setContentView设置显示OK以后会回调Activity的onContentChanged方法。Activity的各种View的findViewById()方法等都可以放到该方法中,系统会帮忙回调。
5)当启动Activity调运完ActivityThread的main方法之后,接着调用ActivityThread类performLaunchActivity来创建要启动的Activity组件,在创建Activity组件的过程中,还会为该Activity组件创建窗口对象和视图对象;接着Activity组件创建完成之后,通过调用ActivityThread类的handleResumeActivity中r.activity.makeVisible()将它激活。调用Activity的makeVisible方法显示我们上面通过setContentView创建的mDecor视图族。
图中id为content的内容就是整个View树的结构,所以对每个具体View对象的操作,其实就是个递归的实现。
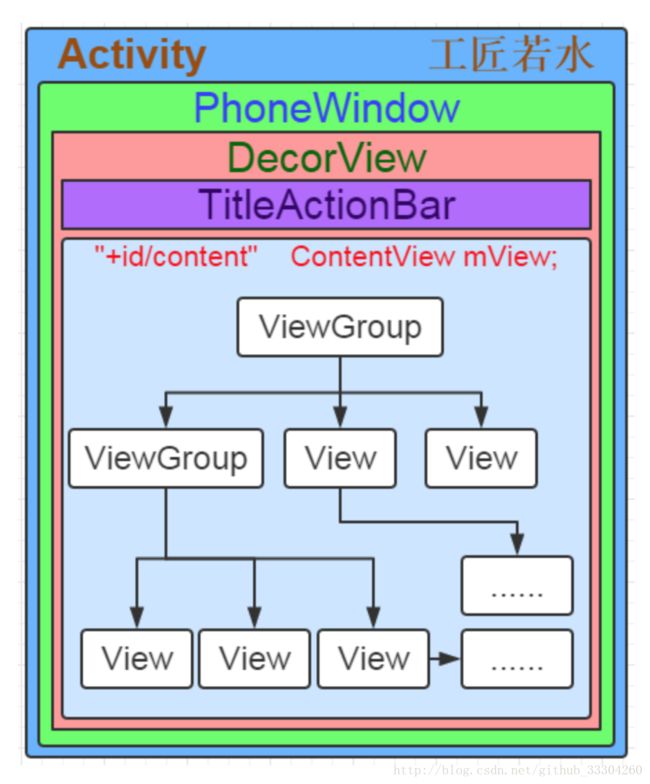
8.Android应用层View绘制流程
相关问题:
对MeasureSpec 的理解?
参考文章:
Android应用层View绘制流程与源码分析
Android View的绘制流程
先上图:
整个View树的绘图流程是在ViewRootImpl类的performTraversals()方法,该函数做的执行过程主要是根据之前设置的状态,判断是否重新计算视图大小(measure)、是否重新放置视图的位置(layout)、以及是否重绘 (draw).
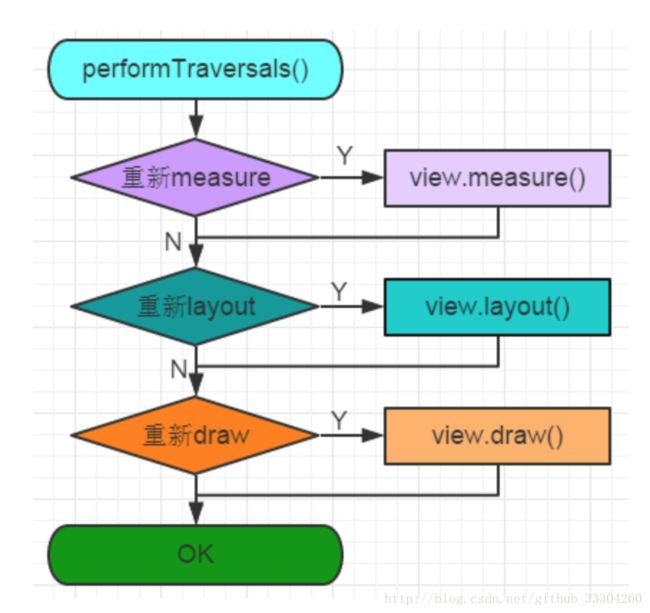
从图中可以看出,分为三步:
1)measure过程
2)layout过程
3)draw过程
第一步:measure过程
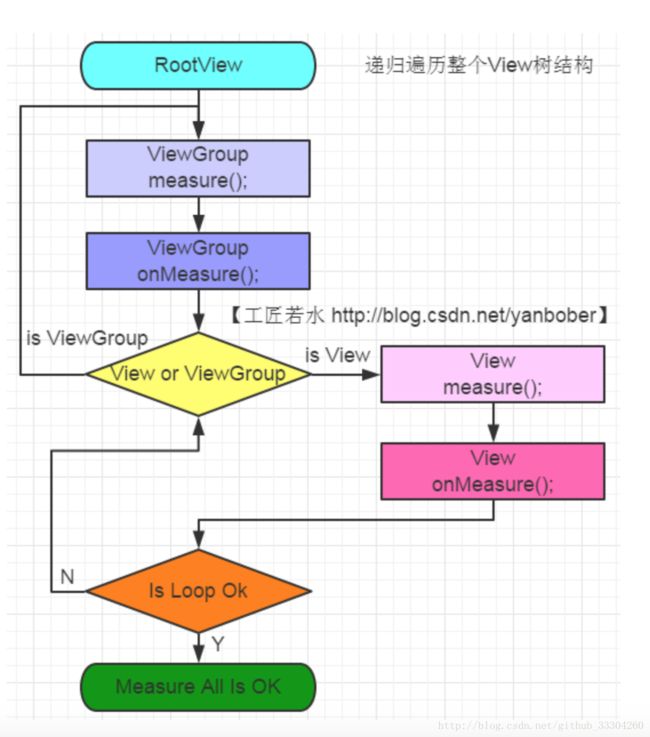
- measure过程主要就是从顶层父View向子View递归调用view.measure方法(measure中又回调onMeasure方法)的过程.
- View的measure方法是final的,不允许重写,View子类只能重写onMeasure来完成自己的测量逻辑。
- View的布局大小由父View和子View共同决定。
- 使用View的getMeasuredWidth()和getMeasuredHeight()方法来获取View测量的宽高,必须保证这两个方法在onMeasure流程之后被调用才能返回有效值。
第二步:layout过程
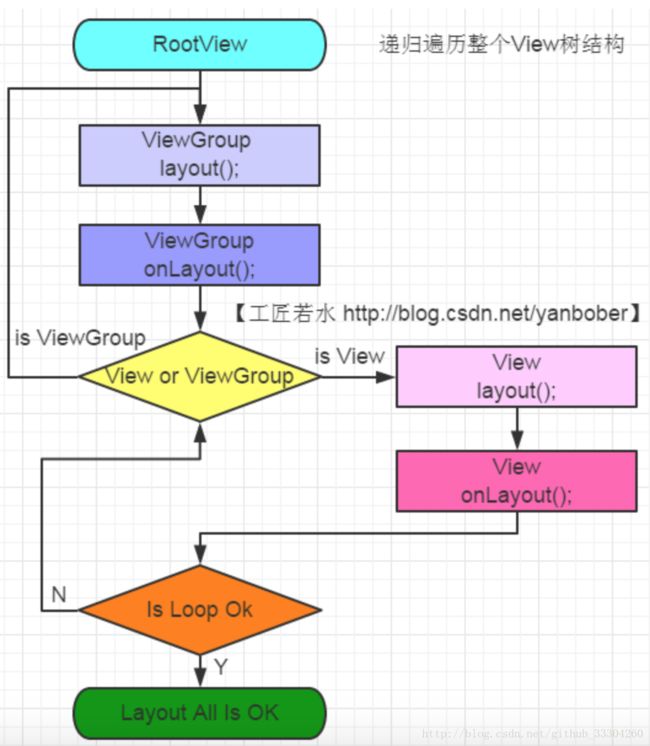
- View.layout方法可被重写,ViewGroup.layout为final的不可重写,ViewGroup.onLayout为abstract的,子类必须重写实现自己的位置逻辑。
- measure操作完成后得到的是对每个View经测量过的measuredWidth和measuredHeight,layout操作完成之后得到的是对每个View进行位置分配后的mLeft、mTop、mRight、mBottom,这些值都是相对于父View来说的。
- 凡是layout_XXX的布局属性基本都针对的是包含子View的ViewGroup的,当对一个没有父容器的View设置相关layout_XXX属性是没有任何意义的
- 使用View的getWidth()和getHeight()方法来获取View测量的宽高,必须保证这两个方法在onLayout流程之后被调用才能返回有效值。
第三步:draw过程
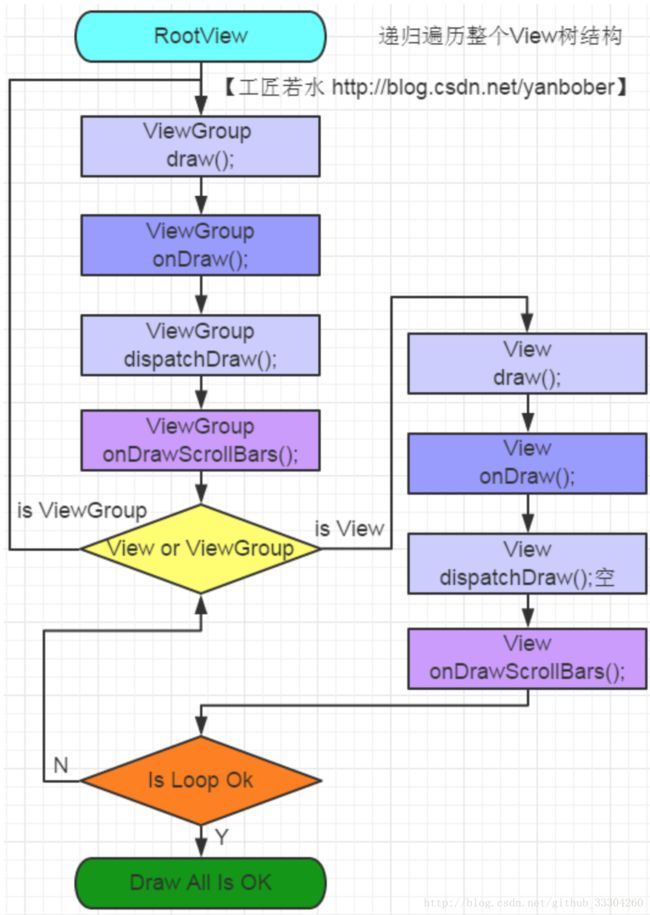
- 第一步:对View的背景进行绘制。
- 第二步,对View的内容进行绘制。
- 第三步,对当前View的所有子View进行绘制,如果当前的View没有子View就不需要进行绘制。
- 第四步,对View的滚动条进行绘制。
9.Android事件分发
参考文章:
认识一下Android 事件分发机制
需要明白以下几个问题:
1)为什么会出现事件分发机制?
2)当手指点击屏幕开始,这些动作在各层之间如何传递?
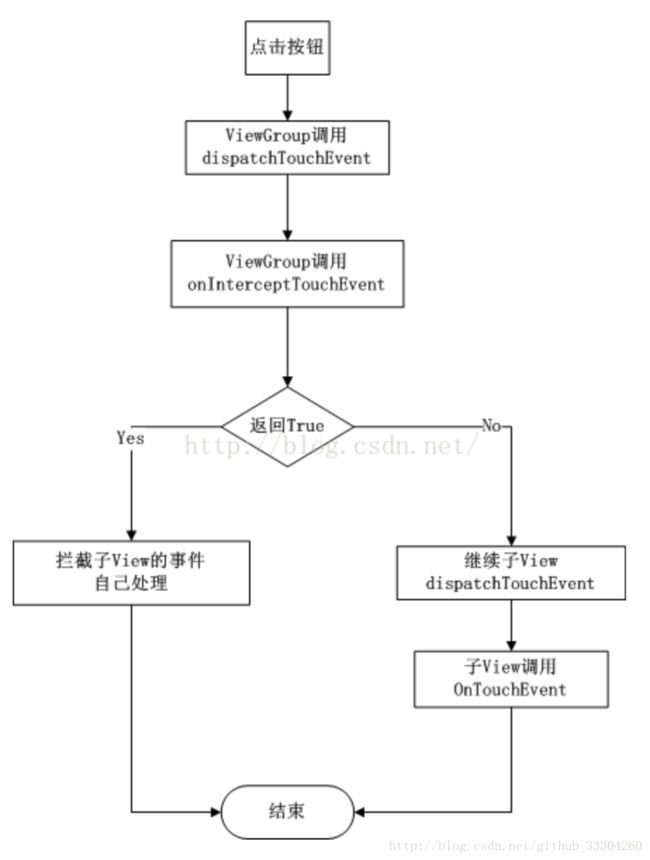
【1】事件分发dispatchTouchEvent(MotionEvent ev)
【2】事件拦截 onInterceptTouchEvent(MotionEvent ev)
【3】事件响应 onTouchEvent(MotionEvent ev)
其中ViewGroup以及继承ViewGroup的容器控件如布局文件RelativeLayout等,需回调这三个方法;通常View则只回调【1】【3】,对应一些显示控件如button等。
11.点九图的使用
参考文章:
Android点9图的运用

14. Looper、Handler、Message三者关系?
参考文章:
Android 异步消息处理机制 让你深入理解 Looper、Handler、Message三者关系
Looper主要作用:
1、 与当前线程绑定,保证一个线程只会有一个Looper实例,同时一个Looper实例也只有一个MessageQueue。
2、 loop()方法,不断从MessageQueue中去取消息,交给消息的target属性的dispatchMessage去处理。
好了,我们的异步消息处理线程已经有了消息队列(MessageQueue),也有了在无限循环体中取出消息的哥们,现在缺的就是发送消息的对象了,于是乎:Handler登场了。
13.深入解析Looper.prepare()和Looper.loop()?
参考文章:
Looper.prepare()和Looper.loop() —深入版
Looper类用来为一个线程开启一个消息循环。 默认情况下android中新诞生的线程是没有开启消息循环的。(主线程除外,主线程系统会自动为其创建Looper对象,开启消息循环。) Looper对象通过MessageQueue来存放消息和事件。一个线程只能有一个Looper,对应一个MessageQueue。
15.Android进程如何保活?
⚠️:进程的优先级?
参考文章:
Android进程保活招式大全
Android 进程拉活包括两个层面:
A. 提供进程优先级,降低进程被杀死的概率
B. 在进程被杀死后,进行拉活
进程的优先级
1.前台进程
2.可见进程
3.服务进程
4.后台进程
5.空进程
16.Android 中的几种动画?
参考文章:
Android 动画总结
总的来说,Android动画可以分为两类,最初的传统动画和Android3.0 之后出现的属性动画;
传统动画又包括 帧动画(Frame Animation)和补间动画(Tweened Animation)。
17.如何加载大图?如何加载多图?
参考文章:
Android高效加载大图、多图解决方案,有效避免程序OOM
1)BitmapFactory.Options参数的inJustDecodeBounds属性设置为true,可以让解析方法禁止为bitmap分配内存
2)最核心的类是LruCache (此类在android-support-v4的包中提供) 。这个类非常适合用来缓存图片,它的主要算法原理是把最近使用的对象用强引用存储在 LinkedHashMap 中,并且把最近最少使用的对象在缓存值达到预设定值之前从内存中移除
18.安卓有序广播、无序广播、静态广播、动态广播?
参考文章:
Android 两种注册、发送广播的区别
Android中的有序和无序广播浅析
动态/静态
代码中动态注册:不是常驻型广播,也就是说广播跟随程序的生命周期。
在Manifest.xml中静态注册:是常驻型,也就是说当应用程序关闭后,如果有信息广播来,程序也会被系统调用自动运行。
无序/有序
无序广播:所有的接收者都会接收事件,不可以被拦截,不可以被修改。
有序广播:按照优先级,一级一级的向下传递,接收者可以修改广播数据,也可以终止广播事件。
19.讲解一下context?
参考文章:
Android Context 上下文 你必须知道的一切
Android Context完全解析,你所不知道的Context的各种细节
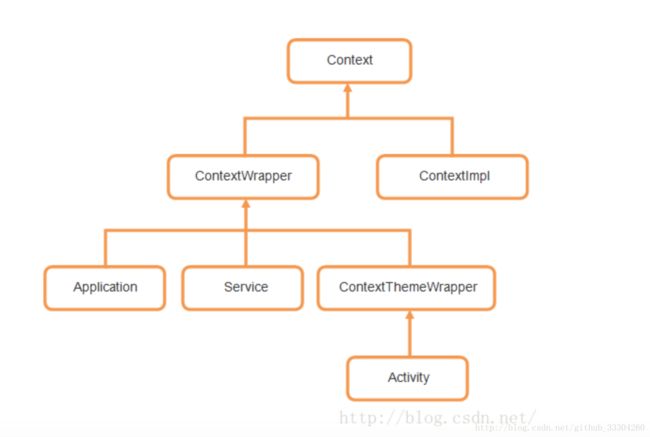
⚠️:注意事项:
- 单例中错误使用activity的context
- 在Application的构造起里调用context方法会crash

20.Android从哪些方面可以优化布局?
参考文章:
布局优化技巧
1)include
2)merge
3)viewStub(不可以与merge同时使用,会增加绘制层数,如何取舍看具体业务)
21.Serializable和Parcelable的区别?
参考文章:
序列化Serializable和Parcelable的理解和区别
1.Parcelable的速度比高十倍以上
2.Serializable的迷人之处在于你只需要对某个类以及它的属性实现Serializable 接口即可。Serializable 接口是一种标识接口(marker interface),这意味着无需实现方法,Java便会对这个对象进行高效的序列化操作。
3.Parcelable方式的实现原理是将一个完整的对象进行分解,而分解后的每一部分都是Intent所支持的数据类型,这样也就实现传递对象的功能了
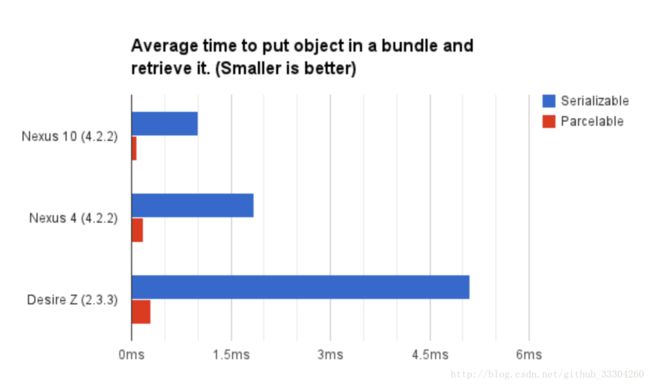
22.Android跨进程通信的几种方式
参考文章:
Android跨进程通信的四种方式
方式一:访问其他应用程序的Activity【intent、AMS两种方式】
方式二:Content Provider
方式三:广播(Broadcast)
方式四:AIDL服务【包括:Message(内部封装的还是AIDL)】
相关知识点:
Messenger与AIDL的异同
Android 基于Message的进程间通信 Messenger完全解析
23.Android 中的Binder跨进程通信机制与AIDL?
参考文章:
IPC进程间通信/跨进程通信
Android 中的Binder跨进程通信机制与AIDL
Android 跨进程双向通信(Messenger与AIDL)详解
进程:一个JVM就是一个进程
线程:最小的调度单元
一个进程可以包含多个线程,在安卓中有一个主线程也就是UI线程,UI线程才可以操作界面,如果在一个线程里面进行大量耗时操作在安卓中就会出现ANR(Application Not Responding)
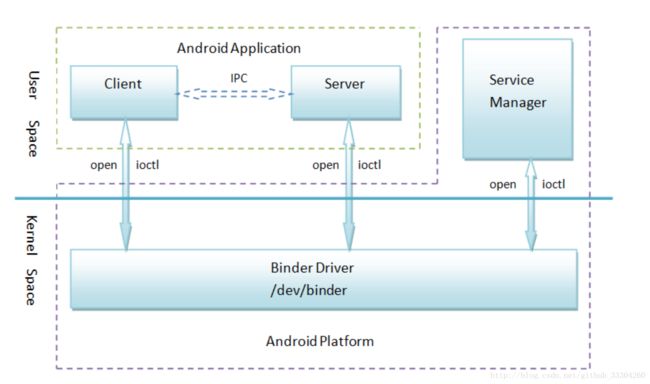
- Client、Server和Service Manager实现在用户空间中,Binder驱动程序实现在内核空间中
- Binder驱动程序和Service Manager在Android平台中已经实现,开发者只需要在用户空间实现自己的Client和Server
- Binder驱动程序提供设备文件/dev/binder与用户空间交互,Client、Server和Service Manager通过open和ioctl文件操作函数与Binder驱动程序进行通信
- Client和Server之间的进程间通信通过Binder驱动程序间接实现
- Service Manager是一个守护进程,用来管理Server,并向Client提供查询Server接口的能力
明确以下几个问题==
1.为什么需要跨进程通信?
2.为什么在Android中使用Binder进行跨进程通信?
3.Binder是什么?
4.如何使用Binder进行跨进程通信呢?
24.Dalvik和ART的区别?
Android 中的Dalvik和ART是什么,有啥区别?
Android中的ART和Dalvik对比
Dalvik与JVM的区别
(1)Dalvik指令集是基于寄存器的架构,dex字节码更适合于内存和处理器速度有限的系统。
(2)而JVM是基于栈的。相对而言,基于寄存器的Dalvik实现虽然牺牲了一些平台无关性,但是它在代码的执行效率上要更胜一筹。
(3)Dalvik 是Android4.4及以下平台的虚拟机。Art 是在Android4.4以上平台使用的虚拟机。
ART的优点:
ART 性能高于采用JIT的Dalvik
应用启动更快、运行更快、体验更流畅、触感反馈更及时
更长的电池续航能力
支持更低的硬件
ART的缺点:
字节码变为机器码之后,占用的存储空间更大
应用的安装时间会变长。
###25.如何检测内存泄漏以及内存优化
参考文章:
使用新版Android Studio检测内存泄露和性能
AndroidStudio3.0 Android Profiler分析器
Android内存泄漏分析心得
=明确如下几个问题====
1.如何检测内存泄露?
2.如何追踪内存分配
3.如何查询方法执行的时间?
Java 中的内存分配
1.静态储存区:编译时就分配好,在程序整个运行期间都存在。它主要存放静态数据和常量;
2.栈区:当方法执行时,会在栈区内存中创建方法体内部的局部变量,方法结束后自动释放内存;
3.堆区:通常存放 new 出来的对象。由 Java 垃圾回收器回收。
常见的内存泄漏案例
case 1. 单例造成的内存泄露
case 2. InnerClass匿名内部类
case 3. Activity Context 的不正确使用
case 4. Handler引起的内存泄漏
case 5. 注册监听器的泄漏
case 6. Cursor,Stream没有close,View没有recyle
case 7. 集合中对象没清理造成的内存泄漏
case 8. WebView造成的泄露
case 9. 构造Adapter时,没有使用缓存的ConvertView
26.Android O 新特性
参考文章:
Android 8.0 行为变更
Android 8.0 功能和 API
Android 8.0 新特性及开发指南
Android Oreo 的新特性介绍 视频教学
一些新特性:
通知渠道 — Notification Channels
画中画模式 — PIP
自适应图标 — Adaptive Icons
固定快捷方式和小部件 — Pinning shortcuts
…
…
27.Android组件化和插件化区别
参考文章:
Android组件化和插件化开发
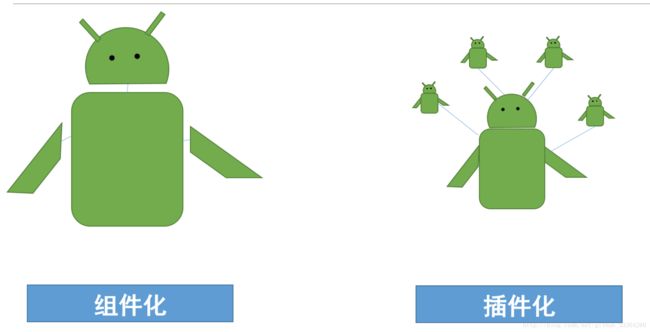
组件化开发就是将一个app分成多个模块,每个模块都是一个组件(Module),开发的过程中我们可以让这些组件相互依赖或者单独调试部分组件等,但是最终发布的时候是将这些组件合并统一成一个apk,这就是组件化开发。
插件化开发和组件化开发略有不用,插件化开发时将整个app拆分成很多模块,这些模块包括一个宿主和多个插件,每个模块都是一个apk(组件化的每个模块是个lib),最终打包的时候将宿主apk和插件apk分开或者联合打包。
28.WebView性能分析与优化
参考文章:
WebView性能、体验分析与优化
70%以上业务由H5开发,手机QQ Hybrid 的架构如何优化演进?
#数据结构与算法篇
1.java堆和栈在内存中的区别/应用?
参考文章:
java堆内存和栈内存的区别
JAVA中堆和栈的区别
区别
1、应用程序所有的部分都使用堆内存,然后栈内存通过一个线程运行来使用。
2、不论对象什么时候创建,他都会存储在堆内存中,栈内存包含它的引用。栈内存只包含原始值变量和堆中对象变量的引用。
3、存储在堆中的对象是全局可以被访问的,然而栈内存不能被其他线程所访问。
4、栈中的内存管理使用LIFO的方式完成,而堆内存的管理要更复杂了,因为它是全局被访问的。堆内存被分为,年轻一代,老一代等等,更多的细节请看,这篇文章
5、栈内存是生命周期很短的,然而堆内存的生命周期从程序的运行开始到运行结束。
6、我们可以使用-Xms和-Xmx JVM选项定义开始的大小和堆内存的最大值,我们可以使用-Xss定义栈的大小
7、当栈内存满的时候,Java抛出java.lang.StackOverFlowError异常而堆内存满的时候抛出java.lang.OutOfMemoryError: Java Heap Space错误
8、和堆内存比,栈内存要小的多,因为明确使用了内存分配规则(LIFO),和堆内存相比栈内存非常快。
9.堆溢出:不断的new 一个对象,一直创建新的对象; 栈溢出:死循环或者是递归太深
应用
1、类变量(static修饰的变量):在程序加载时系统就为它在堆中开辟了内存,堆中的内存地址存放于栈以便于高速访问。静态变量的生命周期–一直持续到整个"系统"关闭
2、实例变量:当你使用java关键字new的时候,系统在堆中开辟并不一定是连续的空间分配给变量(比如说类实例),然后根据零散的堆内存地址,通过哈希算法换算为一长串数字以表征这个变量在堆中的"物理位置"。 实例变量的生命周期–当实例变量的引用丢失后,将被GC(垃圾回收器)列入可回收“名单”中,但并不是马上就释放堆中内存
3、局部变量:局部变量,由声明在某方法,或某代码段里(比如for循环),执行到它的时候在栈中开辟内存,当局部变量一但脱离作用域,内存立即释放
2.写出快速排序和冒泡排序
参考文章:
视觉直观感受 7 种常用的排序算法
必须知道的八大种排序算法
/**
* 冒泡排序
* 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
* 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
* 针对所有的元素重复以上的步骤,除了最后一个。
* 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
* @param numbers 需要排序的整型数组
*/
public static void bubbleSort(int[] numbers)
{
int temp = 0;
int size = numbers.length;
for(int i = 0 ; i < size-1; i ++)
{
for(int j = 0 ;j < size-1-i ; j++)
{
if(numbers[j] > numbers[j+1]) //交换两数位置
{
temp = numbers[j];
numbers[j] = numbers[j+1];
numbers[j+1] = temp;
}
}
}
}
public class FastSort{
public static void main(String []args){
System.out.println("Hello World");
int[] a = {12,20,5,16,15,1,30,45,23,9};
int start = 0;
int end = a.length-1;
sort(a,start,end);
for(int i = 0; istart){
//从后往前比较
while(end>start&&a[end]>=key) //如果没有比关键值小的,比较下一个,直到有比关键值小的交换位置,然后又从前往后比较
end--;
if(a[end]<=key){
int temp = a[end];
a[end] = a[start];
a[start] = temp;
}
//从前往后比较
while(end>start&&a[start]<=key)//如果没有比关键值大的,比较下一个,直到有比关键值大的交换位置
start++;
if(a[start]>=key){
int temp = a[start];
a[start] = a[end];
a[end] = temp;
}
//此时第一次循环比较结束,关键值的位置已经确定了。左边的值都比关键值小,右边的值都比关键值大,但是两边的顺序还有可能是不一样的,进行下面的递归调用
}
//递归
if(start>low) sort(a,low,start-1);//左边序列。第一个索引位置到关键值索引-1
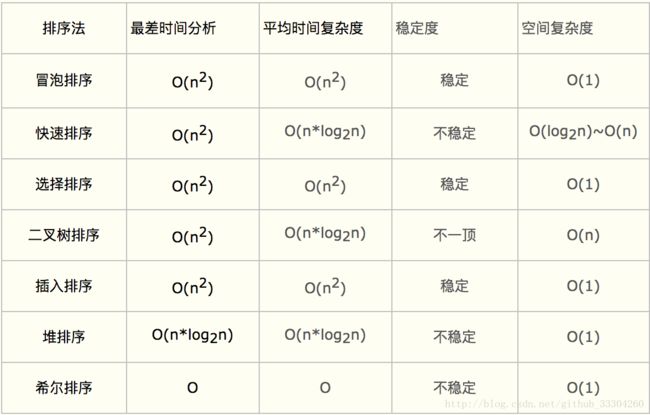
if(end 3.你所知道的排序时空复杂度和稳定性
参考文章:
视觉直观感受 7 种常用的排序算法
必须知道的八大种排序算法
#网络篇
未完待续。。。
#设计模式篇
1.观察者模式
Android设计模式–观察者模式
观察者模式是一个使用频率非常高的模式,他最常用的地方是GUI系统和订阅-发布系统。
该模式的最重要的作用就是解耦,使观察者和被观察者之间依赖尽可能小,甚至好无依赖。
未完待续。。。
未完待续。。。。。。。持续更新中。。。。。。。。。。
未完待续。。。。。。。持续更新中。。。。。。。。。。
未完待续。。。。。。。持续更新中。。。。。。。。。。
未完待续。。。。。。。持续更新中。。。。。。。。。。
童鞋们,请持续关注本文,会持续跟新!!!!!!
扫码关注公众号“伟大程序猿的诞生“,更多干货新鲜文章等着你~

公众号回复“资料获取”,获取更多干货哦~
有问题添加本人微信号“fenghuokeji996” 或扫描博客导航栏本人二维码