Android脚本插件系列(一):安卓国际化多语自动合入脚本
Android脚本插件系列(一):安卓国际化多语自动合入脚本
android-scripts 把平时碰到和Android有关的手动操作、人工检查等写成脚本或插件,提高效率和准确度。
Android脚本插件系列(一):安卓国际化多语自动合入脚本
Android脚本插件系列(二):自动打包安装并语音提示脚本
背景
如今越来越多的IT公司都在走国际化,相应的APP也支持国际化。应用国际化首先就是多语言的支持,Android开发支持多语操作比较简洁,在AndroidStudio中分别为不同语言建立相应的values文件夹即可并在其中创建strings.xml(如values、values-ar、values-zh-rCN)。
在这里强调一下values、values-ar这两个文件夹。其中values里的strings.xml是默认使用的文案,在当前手机语言的strings.xml找不到的时候会使用values里的文案,所以一定别忘在values里添加默认的文案,一般添加英文的。values-ar为阿拉伯语言,是一种RTL语言(从右向左)。
一般合入多语的流程是这样的,首先先整理出一份英文的所有的文案,并将该文案写入values文件夹下的strings.xml。然后将该文案交给翻译公司翻译,待翻译的多语返回之后手动把文案写入相应的strings.xml。
碰到的问题
每次发版都要手动合入22种语言的文案,操作僵硬,效率低下。
不同语言返回的文案很有可能出现未转义的特殊字符(例如法语的
j'aime),导致编译失败,从而要手动一个一个去加转义符。对于
%在某些情况下会出现不易察觉的问题,如之前向翻译公司提了一条文案为Save %s%%,是”节省百分之几的意思”(Save 50%、Save 66%等等)。%s是占位符,%是特殊字符且用反斜杠转义无效,要用%来转义。然而翻译公司在返回多语时,将%%都返回为%(如英文的Save %s%、中文的节省%s%、阿拉伯语的حفظ %s%)。
手动合入多语之后编译是可以通过的,如果合入者不仔细看的话会忽略该问题,当代码运行到使用该多语的对方会Crash抛出UnknownFromatConversionException异常。合入者没有转义%的情况还是较容易发现的,因为在不同语言下只要代码运行相应对方必现Crash。
下面详细分析一下合入者在转义了该%从而产生的问题,之前的合入者合入多语后,在lint的帮助下发现了返回的文案中%没有转义。于是手动添加%进行转义,大功告成提交代码,手动测试没有Crash,之后上线进行灰度。一灰的时候发现线上有一个Crash特别高,一看是UnknownFromatConversionException而且报的就是Save %s%%这个文案的地方,emmmm这个文案之前合入的时候已经手动把%转义了,不应该抛这个异常的。
看来是合入者在转义的时候转错了,排查的时候发现出现Crash的语言都是ar。ar中的文案为حفظ %s%%乍一看好像没什么问题,按照从左往右看是没什么毛病的。不过别忘阿拉伯语是从右往左的,现在在来看看右边两个%%转义之后就是%,占位符的%就没了所以阿拉伯语中使用该文案会crash,正确的转义写法是حفظ %%s%。
脚本能做的事
针对以上问题编写了一个脚本,主要功能如下
- 自动合入多语,提高效率
- 对返回的文案进行单双引号正确性检测,并自动纠正
- 对返回的文案进行%正确性检测,发现隐患并自动纠正
效果
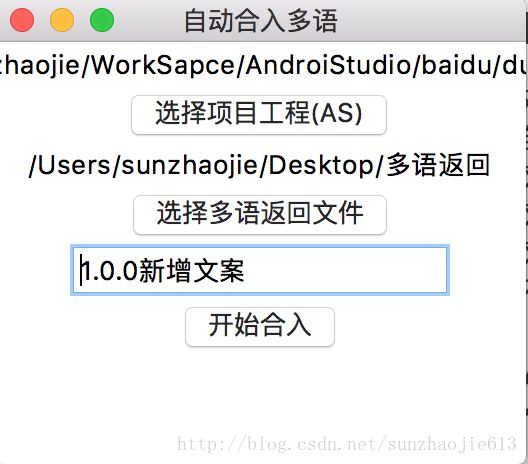
因为要输入项目地址、多语返回地址等,所以采用界面化的形式。
选择完项目地址、多语返回地址,输入本次合入注释之后,点击开始合入。
实现
自动合入
自动合入最关键的就是映射关系,附上我的映射关系,这里大家可以根据实际情况映射。
LANGUANGE_MAPPED_1 = {
"en": "values/",
"ar-eg": "values-ar/",
"de-de": "values-de/",
"es-xl": "values-es/",
"es-us": "values-es-rUS/",
... // 剩略其他语言,保持博客的整洁性
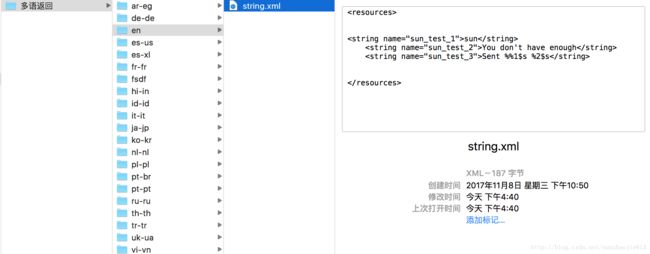
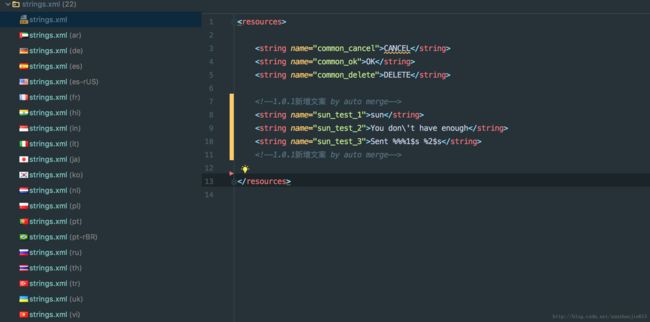
}映射关系确定好了,接着就是递归遍历所有文件,然后提取文件内的多语,经过处理后再写入相应values中的strings.xml中。文案被脚本自动纠,会输出相应日志(旧文案和纠正后的文案)供使用者确认。正对返回多语文案的文件格式没有要求,只要保证具体的单条多语是
同时考虑到多语公司返回文案有可能格式不太规范,脚本会使用放宽条件的正则匹配寻找返回多语中的文案条数,然后和合入的文案条数进行对比,不符则输出提示
代码注释比较完善,具体代码如下
def mergeSingleStrings(pathIn, pathOut, annotation):
'''
合并单个多语言
pathIn: 返回多语具体语言的地址 如/Users/sunzhaojie/Desktop/多语返回/ar-eg/string.xml
pathOut: 项目中对应strings.xml的地址如/Users/sunzhaojie/WorkSapce/AndroiStudio/baidu/demo/app/src/main/res/values-ar/strings.xml
annotation: 合入多语的注释
'''
# 自动添加开始处的注释
strs = '\n \n'
f = open(pathIn)
# 读取待合入文案的所有内容
lines = f.readlines()
# 记录合入的文案条数
count = 0
for line in lines:
# 过滤头尾空白字符
line = line.strip()
lineTemp = line
# 通过正则匹配注释,是注释直接加入
if re.match(r'^\s*\s*$', lineTemp):
strs = strs + ' ' + line + '\n'
continue
# 通过正则提取具体的文案(... )
lineTemps = re.split(
r'^\s*<\s*string\s+name\s*=\s*\".+\"\s*>|\s*$', lineTemp)
# 不是文案,继续下面一行
if len(lineTemps) != 3:
continue
# 是文案,提取文案内容
contet = lineTemps[1]
# 对文案内容进行特殊字符格式检查并自动纠正,目前包括%、和单双引号
lineTemp = lineTemp.replace(contet, checkSpecialChars(contet))
# 文案特殊字符使用错误进行自动纠正之后,输出原文和纠正之后的文案,方便用户进行判断
if line != lineTemp:
print '#########################注意 START #########################'
print '#########################返回文案是[%s],格式检查自动纠正为[%s],请确认!' % (line, lineTemp)
print '#########################注意 END #########################'
# 每行前面添加一个TAB(自动格式化)
strs = strs + ' ' + lineTemp + '\n'
count = count + 1
# 自动添加结尾处的注释
strs = strs + ' \n'
# 最后一行添加
strs = strs + '\n'
f.close()
# 有文案要合入
if count > 0:
# 读取项目中具体语言的strings.xml
f = open(pathOut, 'r+')
all_the_lines = f.readlines()
f.seek(0)
f.truncate()
for line in all_the_lines:
# 将项目中具体语言的strings.xml中的替换为处理后的文案
line = line.replace('', strs)
f.write(line)
f.close()
print '合入文案:%d条' % (count)
# 考虑到多语公司返回文案有可能格式不太规范,这里用放宽条件的正则匹配寻找返回多语中的文案条数,然后和合入的文案条数进行对比,不符则输出提示
originCount = len(re.findall(
r'<\s*string\s*name\s*=\s*\".+\"\s*>', ''.join(lines), re.I))
if(originCount != count):
print '#########################警告 START #########################'
print '#########################返回文案有%d条,只合入了%d条文案,请确认' % (originCount, count)
print '#########################注警告 END #########################'单双引号检测纠正
通过正则找到没有转义的单双引号,将其替换为转义后的字符(具体转义有两种做法,直接添加反斜杠或者使用相应的html实体符)。
在这里匹配的正则使用了环视,环视具体见下面的引用
环视只进行子表达式的匹配,不占有字符,匹配到的内容不保存到最终的匹配结果,是零宽度的。环视匹配的最终结果就是一个位置。
环视的作用相当于对所在位置加了一个附加条件,只有满足这个条件,环视子表达式才能匹配成功。
环视按照方向划分有顺序和逆序两种,按照是否匹配有肯定和否定两种,组合起来就有四种环视。顺序环视相当于在当前位置右侧附加一个条件,而逆序环视相当于在当前位置左侧附加一个条件。
表达式说明(?<=Expression)
逆序肯定环视,表示所在位置左侧能够匹配Expression(?
逆序否定环视,表示所在位置左侧不能匹配Expression(?=Expression)
顺序肯定环视,表示所在位置右侧能够匹配Expression(?!Expression)
顺序否定环视,表示所在位置右侧不能匹配Expression
def checkQuotationMarks(contet):
'''
检查单双引号的正确性并自动纠正
'''
result = contet
# 具体转义有两种做法,直接添加反斜杠或者使用相应的html实体符
result = re.sub(r'(?, '\\\'', result)
# re.sub(r'(?
result = re.sub(r'(?, '\\\"', result)
# re.sub(r'(?
return result%检测纠正
主要实现分为三大步
第一步: 将文案中的 \% 替换为 %%
第二步:通过正则找到是占位符的 %,并进行分割
第三步:遍历分割之后的文案,找到未转义的 % ,替换为 %%
def checkPercent(contet):
'''
检查并自动纠正%的使用正确性
功能:
1.将\%替换为%%
2.将除占位符之外的未转义的%替换为%%
注意点:
1.对于一个%会优先检查是不是符合占位符,因而在某些情况下会出现歧义.
比如"%%sx"这种情况,第二个%是和后面的s连起来成为占位符第一个%未转义呢,还是%%就是转义的%呢?
因而使用者在具体使用的时候要观察输出日志,如果出现自动纠正%的时候进行判断一下是否符合自己的场景
2.正则查找未转义的%,因为一个未转义的%前面有可能有若干个连续的%%,所以会用到可变长度的逆序环视.
而Python自带的正则解释器re不支持可变长度的逆序环视,如果要使用该正则匹配未转义的%确保安装了regex(安装方法:sudo pip install regex).
也提供了不使用regex替换未转义%的方法, 代码见下面.
3.对于阿拉伯语言(RTL语言)%的检查纠正方法和正常语言保持一致,因为在把RTL语言语言合入values-ar的strings.xml中时,AS会自动进行左右变换。
如“حفظ %s%%”合入之后自动变为”%%s% حفظ”, 而“حفظ %%s%”合入之后却变为”%s%% حفظ”。
'''
result = contet
# 将\%替换为%%
result = result.replace('\%', '%%')
# 使用re.split(r'%(?=(\d+\$)?[sd])',result)正则划分,返回的结果却不是按照找到的%进行划分,会多出几个有规律的子串.
# 目前退而求其次使用ugly的替换在分割方法,待后续解决.
uglyStr = ''
result = re.sub(r'%(?=(\d+\$)?[sd])', uglyStr, result)
# 以占位符%进行分割字符串
strs = result.split(uglyStr)
result = ''
i = 0
# 遍历分割得到的所有字符串,进行检查纠正
for str in strs:
i = i + 1
'''
第一种方法
通过正则找到未转义的%,进行替换
Python自带的正则解释器re不支持可变长度的逆序环视,如果要使用该正则匹配未转义的%确保安装了regex(安装方法:sudo pip install regex).
使用下面正则别忘了import regex
'''
# str = regex.sub(r"(?<=(^|[^%])(%%)*)%(?!%)", '%%', str)
'''
第二种方法
未安装regex使用下面的代码,安装了的可以使用上面的正则
通过ugly的替换在替换方法进行替换为转义的%
'''
str = str.replace('%%', uglyStr)
str = str.replace('%', '%%')
str = str.replace(uglyStr, '%%')
# 添加占位符的%
result = result + str + '%'
if i > 0:
# 去除多余的最后一个%
result = result[:-1]
return result1. 将文案中的 \% 替换为 `%%
这个比较简单,result = result.replace('\%', '%%') .
2. 通过正则找到是占位符的 %,并进行分割
使用re.split(r'%(?=(\d+\$)?[sd])',result) 正则划分,返回的结果却不是按照找到的%进行划分,会多出几个有规律的子串. 目前退而求其次使用ugly的替换在分割方法,待后续解决.
uglyStr = ''
result = re.sub(r'%(?=(\d+\$)?[sd])', uglyStr, result)
# 以占位符%进行分割字符串
strs = result.split(uglyStr)3. 遍历分割之后的文案,找到未转义的 % ,替换为 %%
这里有两种方法,第一种使用正则进行匹配。第二种不使用正则先将%% 替换为一个特殊的字符串,然后将剩下% 替换为%%,最终将特殊的字符串替换回%%.
在这里讲一下第一张方法,使用正则匹配。先给出匹配未转义% 的正则(?<=(^|[^%])(%%)*)%(?!%),推荐大家使用在线工具来进行在线正则匹配,因为该网站在线正则匹配是支持环视的。对了,这里的前提是已经将占位符的%去除了,且已经将\%替换为%%。
我将该正则转换为相应的图形化界面方便大家理解,用的是Atom的regex-railroad-diagram插件转换的.
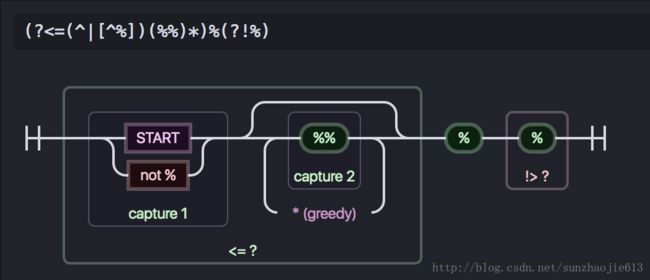
首先一个未转义%的右边肯定不是一个%, 使用顺序否定环视(?!%),表示所在位置右侧不能匹配%.
接着一个未转义%的左边肯定是偶数个连续%,使用逆序肯定环视(?<=(^|[^%])(%%)*),表示左边是偶数个连续%. 是偶数个连续%是以非%开始或者是字符串的起点,后面跟着大于大于0个%%.
注意点
对于阿拉伯语言(RTL语言)%的检查纠正方法和正常语言保持一致,因为在把RTL语言语言合入values-ar的strings.xml中时,AS会自动进行左右变换。如حفظ %s%%合入之后自动变为%%s% حفظ, 而حفظ %%s%合入之后却变为%s%% حفظ
千万不要按照从右往左的顺序对RTL语言进行%的进行转义,不然合入AS中会出现问题的
最后还是建议在strings.xml中特殊字符还是使用相应的HTML实体符比较稳妥