Python之pandas使用
欢迎关注
微信公众号:想进化的猿
头条号:python进阶者
一、pandas基本概念
pandas是基于NumPy构建的一种数据处理工具,被誉为Python中的Excel,主要是为了解决数据分析任务而创建的。pandas中含有大量的数据处理运算相关库以及一些标准的数据模型,提供了高效操作大型数据集必备的工具。利用pandas提供的函数和方法能使我们快速便捷高效地处理数据。
二、pandas基本数据结构
pandas主要包括三类数据结构:Series、DataFrame和Panel。
Series:类似于NumPy中的一维ndarray,能保存不同种数据类型,包括字符串、boolean值、数字等。除了可以使用NumPy中一维ndarray可用的函数或方法外,还可以通过索引标签的方式获取数据,具有索引的自动对齐功能。
DataFrame:二维的表格型数据结构。功能非常类似于R语言中的data.frame。从结构上来看,我们可以将DataFrame理解为Series的容器。
Panel:三维数据结构。从结构上来看,我们可以理解为DataFrame的容器。
三、Series和DataFrame的基本创建
Series和DataFrame是pandas中我们最常用的两个数据结构,我们分别来看一下它们的基本创建方法。(Series和DataFrame有多种创建方法,这里暂时先分别介绍建一个基本创建方法,等具体讲到两种数据结构时再详细介绍。)
创建Series
Series可以通过NumPy的一维ndarray简单创建,基本用法如下。
import numpy as np
import pandas as pd
arr = np.arange(10)
print(arr)
print("---------------")
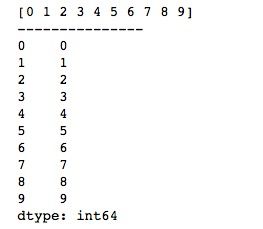
series = pd.Series(arr)
print(series)我们首先创建一个一维ndarray,然后通过pandas的Series()函数,传入一维ndarray。运行结果如下所示,可以看到,相比于NumPy的一维ndarray,Series多了一个默认从0开始的索引。
如果我们想要修改Series的默认索引,只需要在使用Series()函数的时候多传一个index列表参数即可。需要注意的是,index的长度必须要与Series的长度保持一致。
import numpy as np
import pandas as pd
arr = np.arange(10)
print(arr)
print("---------------")
series = pd.Series(arr, index=list('abcdefghij'))
print(series)我们传入一个‘abcdefghij’的列表序列作为index,再次运行, Series的索引就改变了。运行结果如下所示。

创建DataFrame
与Series类似,由于DataFrame相当于NumPy中二维ndarray的表格型数据结构,我们可以通过NumPy的二维ndarray来创建DataFrame,基本用法如下。
import numpy as np
import pandas as pd
arr = np.arange(12).reshape(3, 4)
print(arr)
print("---------------")
data_frame = pd.DataFrame(arr)
print(data_frame)通过pandas的DataFrame()函数,传入二维ndarray。运行结果如下所示,可以看到,相比于NumPy的二维ndarray,DataFrame的排列格式更像是一个Excel表格,行列都具有默认从0开始的索引。

同样的,我们可以修改DataFrame的默认行列索引,在使用DataFrame()函数的时候传入index列表参数修改行索引,传入columns列表参数修改列索引。其中,index和columns的长度分别必须与DataFrame的行长度和列长度保持一致。
import numpy as np
import pandas as pd
arr = np.arange(12).reshape(3, 4)
print(arr)
print("---------------")
data_frame = pd.DataFrame(arr, index=list('abc'), columns=list('ABCD'))
print(data_frame)我们将index设置为‘abc’的列表序列,columns设置为‘ABCD’的列表序列,再次运行,默认的行列索引都成功改变了。

四、Series
Series是带有标签的一维ndarray,可以存储任何数据类型的元素,其中,轴标签称为索引。
Series创建方法
Series有多种创建方法,除了上述介绍的利用NumPy中的一维ndarray创建外,还可以通过标量、字典、pandas中的DataFrame创建,我们分别看一下这几种创建方法。
1、通过NumPy中的一维ndarray创建
此方法已在上述内容中有介绍,这里做个简单回顾,将一维ndarray传入pandas的Series()函数即可创建一个Series。
import numpy as np
import pandas as pd
arr = np.arange(10)
print(arr)
print("---------------")
series = pd.Series(arr, index=list('abcdefghij'))
print(series)index为可选参数,用于修改Series的默认索引。运行结果如下所示。

2、通过标量创建Series
当我们创建一组值都一样的Series时,可以直接通过标量创建,用法如下。
import numpy as np
import pandas as pd
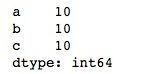
series = pd.Series(10, index=['a', 'b', 'c'])
print(series)给pandas的Series()函数传入一个标量和一个索引列表index,标量就是生成的Series的所有元素值,index的大小决定了生成的Series的大小,若不设置index,默认Series大小为1。上述代码我们创建了一个大小为3,值为10的Series,运行结果如下所示。
3、通过字典创建Series
Series的索引和值就类似于字典中的键值对,所以我们可以通过字典来创建Series,基本用法如下。
import numpy as np
import pandas as pd
dic = {'a': 1, 'b': 2, 'c': 3, 666: 4, True:5}
print(dic)
print("---------------")
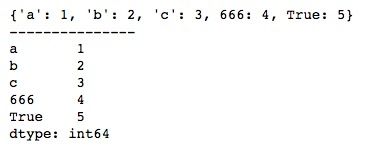
series = pd.Series(dic)
print(series)向Series()函数传入一个字典,字典的key就是Series的索引,value就是Series的值。 运行结果如下所示。
4、从DataFrame中创建Series
之前提到,pandas中Series与DataFrame的关系相当于NumPy中一维ndarray与二维ndarray的关系,因此,我们可以直接从DataFrame中获取Series。
import numpy as np
import pandas as pd
arr = np.arange(12).reshape(3, 4)
print(arr)
print("---------------")
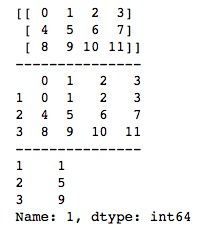
data_frame = pd.DataFrame(arr, index=[1, 2, 3])
print(data_frame)
print("---------------")
series = data_frame[1]
print(series)我们首先创建一个DataFrame,然后使用索引即可获取一个Series。运行结果如下所示,可以看到,通过对DataFrame直接索引获取的是列的值,其实也可以通过loc和iloc方法获取行的值,只是获取行的值得到的依然是DataFrame,这里暂时不做展开,等详细介绍DataFrame的时候再介绍。
Series索引与切片
1、下标索引
下标索引与一维ndarray一样,只需根据序列获取所在位置上的值即可。我们创建一个Series,然后获取第7个位置上(从0开始计)的值。这里需要特别注意的是,Series的下标索引不支持通过-1来获取最后一个位置上的值。
import numpy as np
import pandas as pd
arr = np.random.rand(10)
series = pd.Series(arr, index=list('abcdefghij'))
print(series)
print("---------------")
print(series[6])
print(type(series[6]))
print(series[6].dtype)运行结果如下所示。我们打印了获取的值的数据类型,可以看到,Series存储浮点型数据时自动保留了小数点后六位。事实上,pandas对浮点型数据的存储都会自动保留一定的小数位数,不同版本的pandas自动保留的位数可能会有出入。
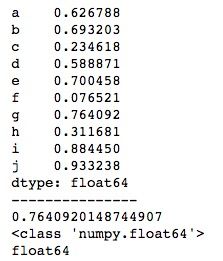
2、标签索引
Series的标签特性使它也可以通过标签进行索引,用法就类似于字典,传入标签索引即可获取对应的值。
import numpy as np
import pandas as pd
arr = np.random.rand(10)
series = pd.Series(arr, index=list('abcdefghij'))
print(series)
print("---------------")
print(series[6])
print(series['g'])运行结果如下所示,通过下标索引和标签索引都能获取到对应的值。
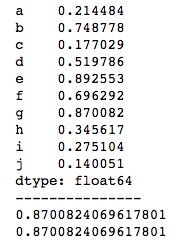
3、切片索引
Series的切片索引与ndarray中的切片索引用法基本一致,区别在于Series的切片索引除了使用下标外还可以对标签进行切片。另外,虽然Series的下标索引不能使用-1,但是在切片中是可以使用-1来表示最后一个位置的。
import numpy as np
import pandas as pd
arr = np.random.rand(5)
series = pd.Series(arr2, index=list('edcba'))
print(series)
print("---------------")
print(series[1:3])
print("---------------")
print(series['d':'b']) # 包含末端
print("---------------")
print(series[:-1])通过对下标切片或对标签切片都可以进行切片索引,但是需要注意两者间的区别,对下标切片索引时,是包头去尾的,即包括小的,不包括大的,而对标签切片索引时,是包含末端的。运行结果如下所示。
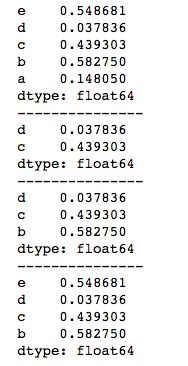
4、布尔型索引
Series的布尔型索引与NumPy中布尔型索引的功能一样,会取出满足条件的值组成一个新的Series。基本用法如下。
import numpy as np
import pandas as pd
arr = np.random.rand(5)
series = pd.Series(arr)
print(series)
print("---------------")
bool = series > 0.5
print(bool)
print("---------------")
print(series[bool])运行结果如下所示。
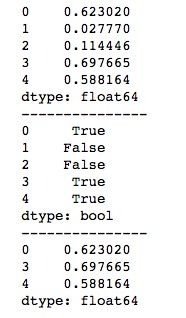
Series常用功能
1、通过head()和tail()查看Series数据
当Series数据较多,且我们只需要查看前几个或后几个元素时,打印整个Series就会显得特别臃肿,这时我们可以使用head()函数和tail()函数分别查看前几个元素和最后几个元素。基本用法如下。
import numpy as np
import pandas as pd
arr = np.random.rand(100)
series = pd.Series(arr)
# 默认为5
print(series.head())
print("---------------")
print(series.head(2))
print("---------------")
print(series.tail())
print("---------------")
print(series.tail(3))head()函数和tail()函数默认会取5个元素,当想查看指定个数的元素时,只需要将个数值传入即可。运行结果如下所示。
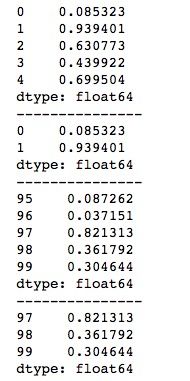
2、使用reindex()函数重新索引
这里的重新索引并不是重新设置索引,而是从源Series中获取索引所对应的数据,若源Series中没有相关索引,会使用缺失值NaN填充,我们看一下效果。
import numpy as np
import pandas as pd
arr = np.random.rand(5)
series1 = pd.Series(arr, index=list('abcde'))
print(series1)
print("---------------")
# 根据索引取值,若无对应值默认会有缺失值NaN
series2 = series1.reindex(list('bcdef'))
print(series1)
print("---------------")
print(series2)上述代码我们创建了一个索引为“abcde”的Series,然后通过reindex()函数重新索引为“bcdef”,reindex()函数只是生成一个新的Series,并不改变源Series。运行结果如下所示,我们可以看到, 对于源Series(series1)中有的索引“bcde”,新生成的Series(series2)会将数据取出来,而对于series1中没有的索引“e”,series2会以缺失值NaN填充。
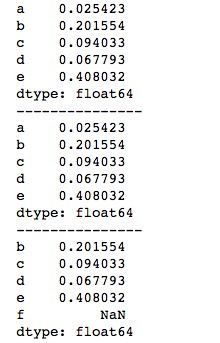
有时我们不想让缺失值NaN出现,可以传入fill_value参数给缺失的索引设置一个默认填充值。
import numpy as np
import pandas as pd
arr = np.random.rand(5)
series1 = pd.Series(arr, index=list('abcde'))
print(series1)
print("---------------")
# 根据索引取值,若无对应值默认会有缺失值NaN
series2 = series1.reindex(list('bcdef'), fill_value=0)
print(series2)运行后可以发现, 在缺失的索引位置上,值变成了我们设置的默认填充值。
3、Series的自动对齐特性
当多个Series进行运算时,Series会根据索引值自动对齐,对共有的索引对应值进行相关运算,不共有的索引对应值则分别以缺失值NaN填充。
import numpy as np
import pandas as pd
series1 = pd.Series(np.random.rand(3), index=list('abc'))
print(series1)
print("---------------")
series2 = pd.Series(np.random.rand(4), index=list('bcde'))
print(series2)
print("---------------")
print(series1 + series2)运行结果如下。对于共有索引“bc”,对应值会进行相加,而对于非共有索引“ade”,对应的值为NaN。
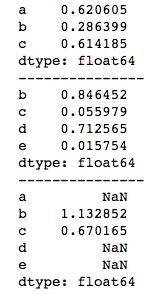
对于缺失值的处理这里暂时不做展开,后面会单独详细介绍。
4、Series删除元素函数drop()
pandas中,我们使用drop()函数来删除Series中的元素,传入要删除的索引标签或索引标签序列可以删除一个或多个元素。
import numpy as np
import pandas as pd
series = pd.Series(np.random.rand(5), index=list('abcde'))
print(series)
print("---------------")
series1 = series.drop(labels='a')
series2 = series.drop(labels=['b', 'c'])
print(series)
print("---------------")
print(series1)
print("---------------")
print(series2)上述代码中drop()函数传入的参数也可以是index='a',index=['b', 'c'],运行结果如下所示。 需要特别注意的是,Series不支持传下标来进行删除元素,上述代码中若使用drop(index=0)就会报错,无法成功删除第一个元素。

与reindex()函数一样,drop()函数也只是生成新的Series,而不会改变源Series。但有时我们就是想删除源Series的元素,这个时候可以设置参数inplace,该参数默认情况下为False,即不改变源Series,当我们将inplace设置成True时,源Series就改变了,但请注意,此时它将不再生成新Series。
import numpy as np
import pandas as pd
series = pd.Series(np.random.rand(5), index=list('abcde'))
print(series)
print("---------------")
series2 = series.drop('a', inplace=True)
print(series2)
print("---------------")
print(series)运行结果如下所示。可以看到,当设置inplace=True时,源Series成功得到了改变,但用于接收的series2为None,可见没有生成新的Series。
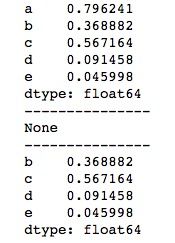
除此之外,pandas中还有用于删除空值或缺失值的dropna()函数和用于删除重复值的drop_duplicates()函数,用法如下。
import numpy as np
import pandas as pd
arr = np.array([1, 2, 1, 3, None, 2, 4, 5, None, 1, 2, 3])
series = pd.Series(arr)
print(series)
print("---------------")
series.dropna(inplace=True)
print(series)
print("---------------")
series.drop_duplicates(inplace=True)
print(series)我们创建一个既有重复值又有空值的Series,然后分别使用dropna()函数和drop_duplicates()函数分别删除空值和重复值,为了便于比较,我们设置inplace=True,直接在源Series上修改。运行结果如下所示。

5、Series添加元素
给Series添加元素可以通过直接添加元素和使用append()函数连接Series的方式,基本使用方法如下。
import numpy as np
import pandas as pd
series1 = pd.Series(np.random.rand(5))
series2 = pd.Series(np.random.rand(5), index=list('abcde'))
print(series1)
print("---------------")
print(series2)
print("---------------")
series1[5] = 1
series2['f'] = 2
series2[5] = 2
series1 = pd.Series(np.array([1, 2, 3, 4, 5]), index=list('abcde'))
series2 = pd.Series(np.array([2, 3, 4, 5, 6]), index=list('bcdef'))
print(series1)
print("---------------")
print(series2)
print("---------------")
series3 = series1.append(series2)
print(series3)不同于drop()函数无法使用下标索引,添加元素除了使用标签索引外,使用下标索引的方式也是可以直接给Series添加对应元素的。append()函数连接两个Series,生成的新Series将忽视标签的重复,包含源Series中的所有元素。运行结果如下所示。

6、Series元素排序
pandas中可以使用sort_index()函数或sort_values()函数分别对Series的索引及元素值进行排序,ascending参数用于设置正序或倒序,默认为True正序,设置ascending为False时倒序排序。
import numpy as np
import pandas as pd
series = pd.Series(np.random.randn(5), index=list('bdeac'))
print(series)
print("---------------")
print(series.sort_index())
print("---------------")
print(series.sort_index(ascending=False))
print("---------------")
print(series.sort_values())
print("---------------")
series.sort_values(ascending=False, inplace=True)
print(series)运行结果如下所示。同样地,sort_index()函数和sort_values()函数只是生成新的Series,而不影响源Series,要修改源Series,需要设置inplace=True。
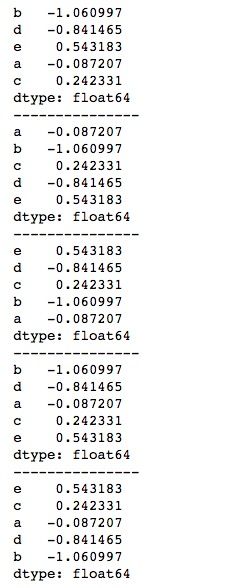
五、DataFrame
DataFrame是一个表格型的数据结构,包含一组有序的列,它的值类型可以是数值、字符串、布尔型等各种数据类型。DataFrame中的数据以一个或多个二维块存储,但它不是列表、字典或一维数组结构。
DataFrame创建方法
1、通过二维ndarray创建DataFrame
DataFrame在结构上类似于NumPy中的二维ndarray,因此我们可以通过二维ndarray来创建DataFrame,基本用法如下。
import numpy as np
import pandas as pd
arr = np.random.rand(12).reshape(3, 4)
print(arr)
print("---------------")
df1 = pd.DataFrame(arr)
df2 = pd.DataFrame(arr, index=list('abc'), columns=list('ABCD'))
print(df1)
print("---------------")
print(df2)首先,创建一个二维ndarray,然后使用pandas的DataFrame函数,将该ndarray传入即可。该方法创建一个与传入的ndarray相同形状的DataFrame,我们可以显示地指定DataFrame的行索引(index)和列索引(columns),若不指定index和columns,则行索引和列索引均返回默认的数字标签格式。运行结果如下所示。
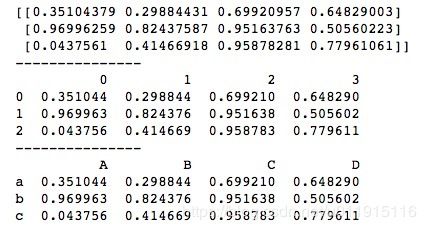
我们可以利用type()函数看一下DataFrame的行标签、列标签以及值的数据类型。
import numpy as np
import pandas as pd
arr = np.random.rand(12).reshape(3, 4)
frame = pd.DataFrame(arr, index=list('abc'), columns=list('ABCD'))
print(frame)
print("---------------")
print(frame.index) # 行标签
print(type(frame.index))
print("---------------")
print(frame.columns) # 列标签
print(type(frame.columns))
print("---------------")
print(frame.values) # 值
print(type(frame.values))运行结果如下所示。可以看到,无论是行标签index,还是列标签columns,都属于索引标签类Index。而DataFrame的值values,跟我们想的一样,它是一个NumPy的ndarray,事实上, DataFrame只是给二维ndarray添加了行标签和列标签。

2、通过数组字典创建DataFrame
给pandas的DataFrame()函数传入一个数组字典也可以创建DataFrame,其中字典的key将会作为生成的DataFrame的列标签columns,行标签index默认为数字标签。可以对行标签index进行修改,但是长度必须要一致。
import numpy as np
import pandas as pd
# 列长度需要保持一致
data1 = {'a': [11, 12, 13],
'b': [21, 22, 23],
'c': [31, 32, 33]}
data2 = {'a': np.random.rand(3),
'b': np.random.rand(3)} # 3改为4列长度不一会报错
print(data1)
print("---------------")
print(data2)
print("---------------")
d1 = pd.DataFrame(data1, index=list('ABC'))
d2 = pd.DataFrame(data2)
print(d1)
print("---------------")
print(d2)需要注意的是,使用数组字典创建DataFrame时,列长度必须保持一致,否则会报错,无法生成DataFrame。运行结果如下所示。
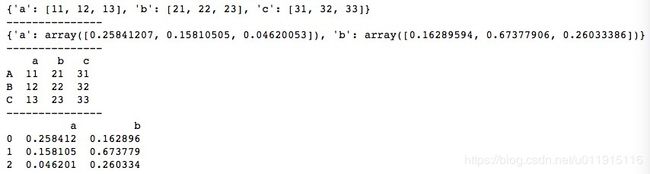
使用数组字典创建DataFrame时,若在DataFrame()函数中传入columns,作用并不是重新设置列索引,而是重新指定列的顺序。如果现有数据中无该列,则会生成缺失值NaN来填充,此时传入的columns是可以少于原数据的列数量的。我们给上述代码中data1创建时的DataFrame()函数传入一个columns,代码如下。
import numpy as np
import pandas as pd
data = {'a': [11, 12, 13],
'b': [21, 22, 23],
'c': [31, 32, 33]}
print(pd.DataFrame(data, index=list('ABC')))
print("---------------")
d = pd.DataFrame(data, index=list('ABC'), columns=list('bd'))
print(d)运行结果如下所示,我们将列索引设置为b、d,对于原数据的列中包含的索引b,新DataFrame会将该列的值取下来,而对于不包含的新索引d,新DataFrame会使用缺失值NaN填充该列。

3、通过Series字典创建DataFrame
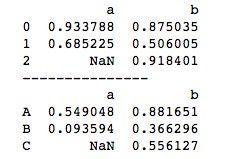
由Series组成的字典与数组字典类似,在用Series字典创建DataFrame时,只需在DataFrame()函数中传入一个Series字典即可,字典的key作为生成的DataFrame的列标签columns,行标签index默认为数字标签。与数组字典创建DataFrame不同的是,使用Series字典创建DataFrame时,Series的长度是可以不一样的,新生成的DataFrame会自动使用缺失值NaN进行填充。基本使用方法如下。
import numpy as np
import pandas as pd
# 列长度可以不一致
data1 = {'a': pd.Series(np.random.rand(2)),
'b': pd.Series(np.random.rand(3))}
data2 = {'a': pd.Series(np.random.rand(2), index=list('AB')),
'b': pd.Series(np.random.rand(3), index=list('ABC'))}
d1 = pd.DataFrame(data1)
d2 = pd.DataFrame(data2)
print(d1)
print("---------------")
print(d2)运行结果如下所示。
4、 通过嵌套字典创建DataFrame
在DataFrame()函数中传入一个嵌套字典也可以创建DataFrame,父字典的key就是生成的DataFrame的列标签columns,子字典的key则作为生成的DataFrame的行标签index。在使用DataFrame()函数时,使用columns参数可以增加和减少序列,空值用NaN填充,但是我们不能改变原有index。
import numpy as np
import pandas as pd
data = {'aa': {'a1': 1, 'a2': 2, 'a3': 3},
'bb': {'b1': 1, 'b2': 2, 'b3': 3},
'cc': {'c1': 1, 'c2': 2}}
print(data)
print("---------------")
df1 = pd.DataFrame(data)
print(df1)
print("---------------")
df2 = pd.DataFrame(data, columns=['aa', 'dd'])
print(df2)在使用columns参数时,DataFrame会自动舍弃该列空值。上述代码中,我们设置列索引columns为bb、dd,对于原列索引中有的索引bb,新DataFrame会取该列值,但是舍弃了为空值的b1、b2、b3、c1、c2行,然后对于未包含在原列索引中的索引dd,直接用NaN填充。运行结果如下所示。

5、通过字典列表创建DataFrame
通过字典列表创建DataFrame即向DataFrame()函数传入一个字典列表,字典的key即为生成的DataFrame的列标签columns,不同字典间的不同key将合并组成生成的DataFrame的列。对于列表中的字典,如果有相同的key,则会生成不同的行,行标签index默认为数字索引。如果列表中的每个字典间都没有相同key存在,那么将生成一个单行的DataFrame。
import numpy as np
import pandas as pd
data1 = [{'a': 1, 'b': 2}, {'a': 3, 'd':4, 'e': 5}]
data2 = [{'a': 1, 'b': 2}, {'c': 3, 'd':4, 'e': 5}]
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
print(df1)
print("---------------")
print(df2)运行结果如下所示。
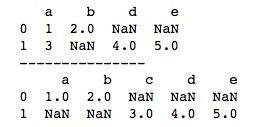
对于通过字典列表创建的DataFrame,我们可以设置行标签index和列标签columns。
import numpy as np
import pandas as pd
data = [{'a': 1, 'b': 2}, {'a': 3, 'd':4, 'e': 5}]
df1 = pd.DataFrame(data)
df2 = pd.DataFrame(data, index=list('AB'))
df3 = pd.DataFrame(data, columns=list('afg'))
print(df1)
print("---------------")
print(df2)
print("---------------")
print(df3)设置行标签index为修改原行索引标签,所以index的数量必须与原行索引数量保持一致。设置列标签与其他方法创建的DataFrame类似,对于原数据的列中包含的索引,新DataFrame会取出该列的值,而对于不包含的新索引,则以缺失值NaN填充。运行结果如下所示。

DataFrame索引和切片
DataFrame有行索引和列索引,可以看做是由Series组成的字典。
1、基于列的索引和切片
pandas中,对DataFrame进行列的索引和切片使用类似数组索引的DataFrame[]方法,传入列的索引标签。索引单列只需将该列的索引标签传入即可,索引多列时用“,”隔开,并用中括号包裹再传入DataFrame[]。这里需要注意的是,DataFrame[]方法通过列标签索引多列是不支持使用切片形式的。基本用法如下。
import numpy as np
import pandas as pd
data = np.random.rand(12).reshape(3, 4) * 100
df = pd.DataFrame(data, index=list('abc'), columns=list('ABCD'))
print(df)
print("---------------")
data1 = df['A']
print(data1) # Series
print("---------------")
data2 = df[['A', 'C']] # DataFrame
print(data2)运行结果如下所示。当索引单列时,得到的结果是一个Series;索引多列时,得到的结果是对应列数的DataFrame。
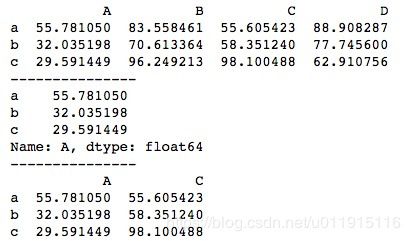
DataFrame[]方法传入索引标签时默认选择列,因此我们在创建DataFrame时一般都会单独指定列索引columns,而不会使用默认数字作为列名,以免和index冲突。
DataFrame[]方法是不支持传入行标签的,上述代码若使用df['a']来索引获取第一行将会报错。DataFrame[]我们一般不用于进行基于行的索引和切片,如果硬要使用,只能使用数字,DataFrame[]方法在传入数字时默认会选择行,但是它只支持切片的索引,而不能单独一个数字索引。我们来看一下效果。
import numpy as np
import pandas as pd
data = np.random.rand(12).reshape(3, 4) * 100
df = pd.DataFrame(data, index=list('abc'), columns=list('ABCD'))
print(df)
print("---------------")
# df[2]会报错
data = df[:2]
print(data)运行结果如下所示。当传入数字切片时,会获取DataFrame的对应行,但是不能传入单个数字,否则会报错。

现在我们来总结一下DataFrame[]的用法。首先,如果传入的是索引标签,那么默认进行列的索引,且DataFrame[]不支持对行的标签索引。其次,如果传入的是数字,且必须是切片形式的数字,那么默认进行基于行的切片索引。
基于以上几点,我们一般不使用DataFrame[]来进行基于行的索引和切片。
2、基于行的索引和切片
pandas中,我们使用DataFrame的loc[]方法和iloc[]方法来进行基于行的索引和切片。其中,loc[]方法用于行标签的索引和切片,iloc[]方法用于行数字的索引和切片。基本用法如下。
import numpy as np
import pandas as pd
data = np.random.rand(12).reshape(3, 4) * 100
df = pd.DataFrame(data, index=list('abc'), columns=list('ABCD'))
print(df)
print("---------------")
data1 = df.loc['a']
print(data1) # Series
print("---------------")
data2 = df.loc[['a', 'c']] # DataFrame
print(data2)
print("---------------")
data3 = df.iloc[[0, 2]] # DataFrame
print(data3)
print("---------------")
data4 = df.loc['a':'c'] # DataFrame 末端包含
print(data4)
data4 = df.iloc[0:2] # DataFrame 末端不包含
print(data4)loc[]方法和iloc[]方法都支持切片,不同的是iloc[]方法进行数字索引切片时是末端不包含的,而loc[]方法进行标签索引切片时是末端包含的。运行结果如下所示。
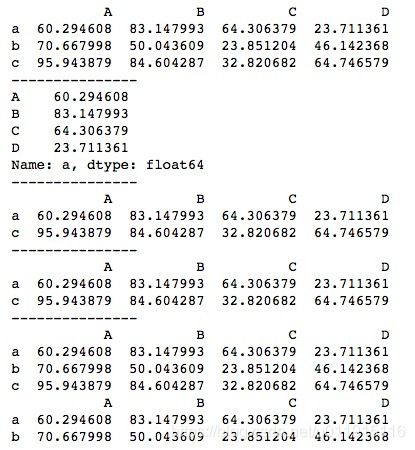
3、基于布尔型的索引和切片
与Series的布尔型索引和切片类似,DataFrame也支持基于布尔型的索引和切片。基本用法如下。
import numpy as np
import pandas as pd
data = np.random.rand(12).reshape(3, 4) * 100
df = pd.DataFrame(data, index=list('abc'), columns=list('ABCD'))
print(df)
print("---------------")
# 不做索引对每个数据进行判断
b1 = df < 30
print(b1)
print(df[b1])直接对DataFrame进行条件判断,得到一个形状相同的布尔型DataFrame,然后进行DataFrame[]索引,True的地方会取出对应位置上的数据,而False所对应的位置上则会以NaN填充。运行结果如下所示。
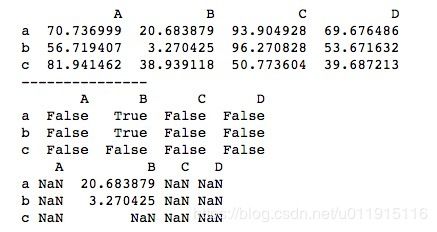
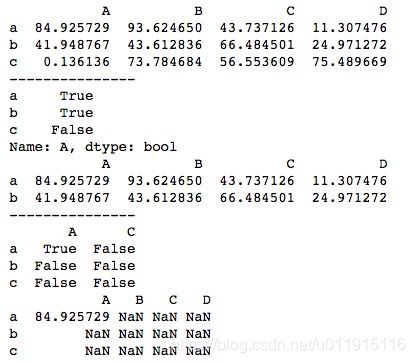
我们也可以先对行或列进行条件判断再进行布尔型索引和切片。我们先看一下对列的判断。
import numpy as np
import pandas as pd
data = np.random.rand(12).reshape(3, 4) * 100
df = pd.DataFrame(data, index=list('abc'), columns=list('ABCD'))
print(df)
print("---------------")
# 单列判断 索引结果会保留其他列的数据
b2 = df['A'] > 30
print(b2)
print(df[b2])
print("---------------")
# 多列判断 索引结果会保留所有数据 但是会以NaN填充
b3 = df[['A', 'C']] > 80
print(b3)
print(df[b3])对列的判断可以单列和多列。单列判断时,会得到一个布尔型的Series,为True时,取出原数据,为False时,舍弃该数据对应的行。得到的结果除了该列外,还会取出其他所有列对应的数据。多列判断时,会得到一个布尔型的DataFrame,与单列判断的区别在于,对于False对应位置上的值不是舍弃,而是用NaN填充。同时对除了判断列以外的其他列的数据都以NaN填充,而不是像单列判断时取原数据。运行结果如下所示。
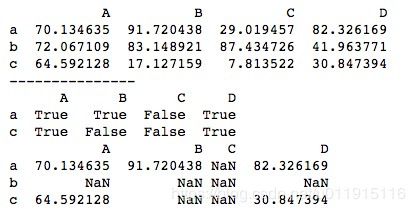
对行的判断仅支持多行判断,无法支持单行的判断,这跟单行判断后得到的布尔型结果有关。
import numpy as np
import pandas as pd
data = np.random.rand(16).reshape(4, 4) * 100
df = pd.DataFrame(data, index=list('abcd'), columns=list('ABCD'))
b2 = df.loc['a'] > 30
print(b2)运行结果如下所示。可以看到,单行判断时获取到的是一个行为基础的布尔型Series,结构上相当于将行作为了列,索引时是无法匹配的。

多行判断得到的是一个布尔型的DataFrame,索引结果会保留包括其他行在内的所有数据,但是对于False对应的位置和未参与判断的行对应的数据都会以NaN填充。
import numpy as np
import pandas as pd
data = np.random.rand(12).reshape(3, 4) * 100
df = pd.DataFrame(data, index=list('abc'), columns=list('ABCD'))
print(df)
# 行索引
print("---------------")
# 多行判断 索引结果会保留所有数据 但是False的值会以NaN填充
b3 = df.loc[['a', 'c']] > 30
print(b3)
print(df[b3])运行结果如下所示。
4、多重索引
我们还可以同时使用多种方法来进行索引,例如先索引行再索引列,先布尔型索引再索引列等等。
import numpy as np
import pandas as pd
data = np.random.rand(12).reshape(3, 4) * 100
df = pd.DataFrame(data, index=list('abc'), columns=list('ABCD'))
print(df)
print("---------------")
print(df[['A', 'C']].loc[['a', 'c']])
print("---------------")
print(df[['A', 'C']].iloc[1:3])
print("---------------")
print(df[df > 50].loc[['a', 'c']])运行结果如下所示。

DataFrame基本技巧
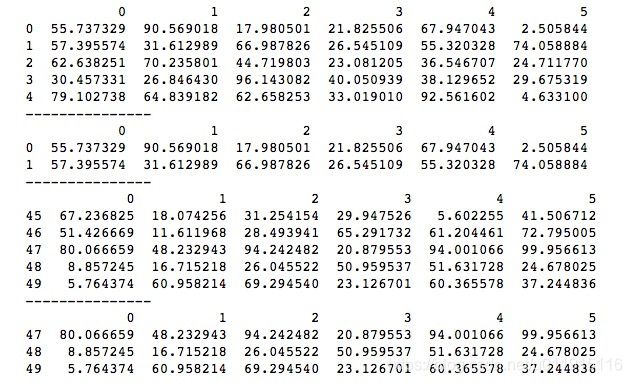
1、通过head()和tail()查看DataFrame数据
head()函数和tail()函数的用法与查看Series数据时一样,只是对于DataFrame,它们查看的是DataFrame的行。
import numpy as np
import pandas as pd
data = np.random.rand(300).reshape(50, 6) * 100
df = pd.DataFrame(data)
print(df.head())
print("---------------")
print(df.head(2))
print("---------------")
print(df.tail())
print("---------------")
print(df.tail(3))head()函数和tail()函数分别查看DataFrame的前几行和最后几行,当不传参数时,默认为前5行和后5行,想看指定行数时,传入对应数字即可。运行结果如下所示。
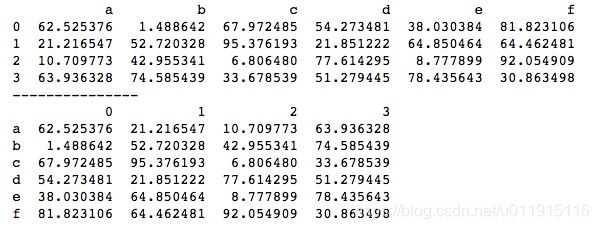
2、DataFrame的转置
对于DataFrame数据的查看,我们并不总是只想查看前几行或后几行,有时候我们想要查看前几列或后几列,这时可以利用DataFrame的转置,将原来的列变成行,再对转置后的DataFrame使用head()函数和tail()函数就可以顺利查看原DataFrame的前几列或后几列了。
由于DataFrame在结构上类似于NumPy的二维ndarray,可以将它当矩阵进行转置处理,DataFrame也拥有“T”属性用于转置,基本用法如下。
import numpy as np
import pandas as pd
data = np.random.rand(24).reshape(4, 6) * 100
df = pd.DataFrame(data, columns=list('abcdef'))
print(df)
print("---------------")
print(df.T)使用“T”属性对DataFrame进行转置,结果生成一个新的DataFrame,并不改变原DataFrame。转置后相当于对原DataFrame的行和列做了交换,运行结果如下所示。
对转置后的DataFrame使用head()函数和tail()函数就可以顺利查看原DataFrame的前几列和后几列了。
import numpy as np
import pandas as pd
data = np.random.rand(24).reshape(4, 6) * 100
df = pd.DataFrame(data, columns=list('abcdef'))
print(df)
print("---------------")
df_T = df.T
print(df_T.head(2))
print("---------------")
# 对结果再做一次转置可得到原DataFrame的列的形式
print(df_T.tail(3).T)虽然这种方法本质上查看的是转置后DataFrame的行,但其实我们顺利得到了原DataFrame的列。若要保持原DataFrame列的形式,只需要对查看转置后DataFrame的数据再做一次转置即可。上述代码中,我们在获取转置后DataFrame的最后3行后对其进行转置,结果就像是获取了原DataFrame的最后3列一样。运行结果如下所示。
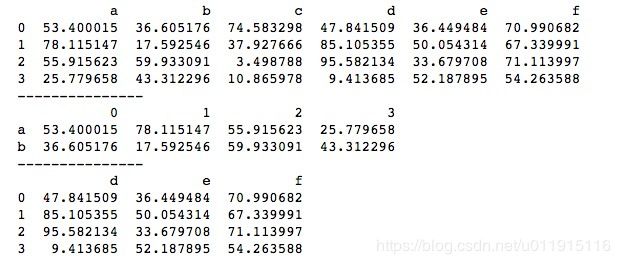
3、DataFrame的添加和修改
DataFrame的添加和修改基于DataFrame的索引,分别使用DataFrame[]和loc[]或iloc[]对DataFrame的列和行进行添加和修改,对于原DataFrame中没有的行索引或列索引,DataFrame会自动进行新增行或列的操作;对于原DataFrame中已有的行索引或列索引,DataFrame会自动进行修改指定行或列的操作。基本用法如下。
import numpy as np
import pandas as pd
data = np.random.rand(12).reshape(3, 4) * 100
df = pd.DataFrame(data, index=list('abc'), columns=list('ABCD'))
print(df)
print("---------------")
# 新增列/行
df['E'] = 1
print(df)
print("---------------")
df.loc['d'] = 2
print(df)
print("---------------")
# 修改列/行
df['E'] = 10
print(df)
print("---------------")
df.loc['d'] = 20
print(df)这里需要注意,不同于索引可以支持多行多列索引,DataFrame的添加和修改一次只能单行单列操作。运行结果如下所示。
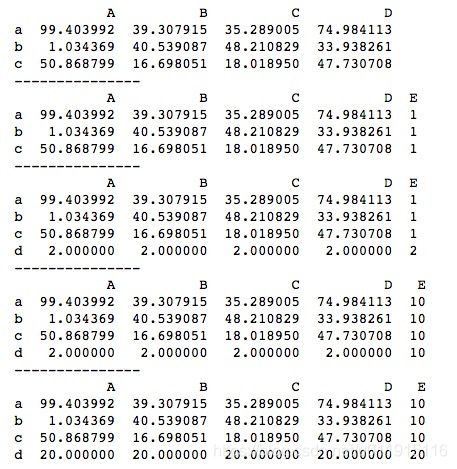
以上是对一整行或一整列的添加和修改,我们也可以对指定某个位置上的值进行修改。
import numpy as np
import pandas as pd
data = np.random.rand(12).reshape(3, 4) * 100
df = pd.DataFrame(data, index=list('abc'), columns=list('ABCD'))
print(df)
print("---------------")
df['D'].loc['a'] = 1
print(df)我们将D列a行位置上的数据修改为1,运行结果如下所示。
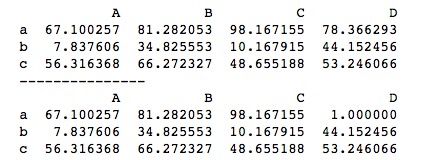
添加操作只支持整行或整列,若试图添加某个单独位置,则会报错。
4、DataFrame的删除
pandas中分别使用“del”关键字和drop()函数来删除DataFrame的列和行。其中drop()函数的inplace参数默认为False,即返回一个新的DataFrame,若想改变原DataFrame,需将inplace参数设置为True。“del”关键字和drop()函数的基本用法如下。
import numpy as np
import pandas as pd
data = np.random.rand(12).reshape(3, 4) * 100
df = pd.DataFrame(data, index=list('abc'), columns=list('ABCD'))
print(df)
print("---------------")
# 删除列
del df['A']
print(df)
print("---------------")
# 删除行
df.drop(['a'], inplace=True)
print(df)
# drop删除列
df.drop(['B'], axis = 1, inplace=True)
print(df)与DataFrame的添加操作一样, DataFrame的删除只支持整行或整列操作,若想删除某个指定位置上的数据,可以将该位置上的数据修改为NaN。
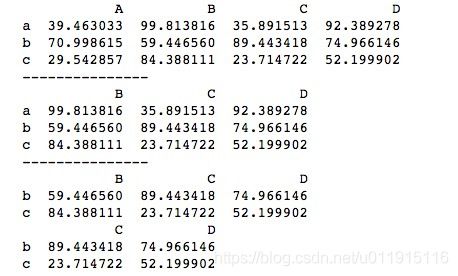
5、DataFrame的自动对齐特性
当多个DataFrame进行运算时,DataFrame会根据行索引和列索引自动对齐,对共有的索引对应值进行相关运算,不共有的索引对应值则分别以缺失值NaN填充。
import numpy as np
import pandas as pd
data1 = np.random.rand(12).reshape(3, 4) * 100
df1 = pd.DataFrame(data1, index=list('abc'), columns=list('ABCD'))
data2 = np.random.rand(12).reshape(4, 3) * 100
df2 = pd.DataFrame(data2, index=list('abcd'), columns=list('ABC'))
print(df1)
print("---------------")
print(df2)
print("---------------")
print(df1 + df2)运行结果如下所示。可以看到,运算结果会包含参与运算的DataFrame的所有行索引和列索引。实际上,上述的df1和df2在运算前先进行了对齐,df1补了一个值全为NaN的行d,df2补了一个值全为NaN的列D,然后再进行运算,与NaN运算的结果就是NaN。

6、DataFrame的排序
pandas中使用sort_values()函数和sort_index()函数分别对DataFrame的数据值和索引进行排序。
我们先看一下对数据值的排序,sort_values()函数中传入要排序的行索引或列索引,注意必须是列表格式。ascending参数默认为True正序,设置ascending=False时为倒序。axis默认为0,按列排序,所以当按行排序时,传入行索引的同时必须设置axis=1。基本用法如下。
import numpy as np
import pandas as pd
data = np.random.rand(12).reshape(3, 4) * 100
df = pd.DataFrame(data, index=list('abc'), columns=list('ABCD'))
print(df)
print("---------------")
# 按列排序
print(df.sort_values(['A']))
print("---------------")
print(df.sort_values(['A'], ascending=False))
print("---------------")
# 按行排序
print(df.sort_values(['a'], axis=1))运行结果如下所示。
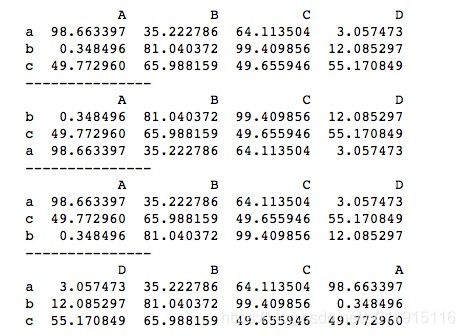
我们也可以同时对多行或多列排序。以多列为例,排序规则为首先按第一个索引列进行排序,若有相同值,则比较第二个索引列对应位置上的值,依次类推。
import numpy as np
import pandas as pd
# 多列排序 当A中有相同值时再按C排序
data = np.array([[1, 2, 4, 3], [2, 2, 1, 2], [1, 2, 1, 1]])
df = pd.DataFrame(data, index=list('abc'), columns=list('ABCD'))
print(df)
print("---------------")
print(df.sort_values(['A', 'C']))运行结果如下所示。A列中,a行与c行的值都为1,则看C列中a行与c行位置上的值,c位置上的值更小,所以c行排前面,最终顺序为c、a、b。
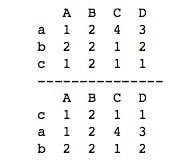
对索引值的排序使用sort_index()函数,用法类似sort_values()函数,基本用法如下。
import numpy as np
import pandas as pd
data = np.random.rand(12).reshape(3, 4) * 100
df = pd.DataFrame(data, index=list('acb'), columns=list('DBAC'))
print(df)
print("---------------")
print(df.sort_index())
print("---------------")
print(df.sort_index(ascending=False))
print("---------------")
print(df.sort_index(axis=1))
print("---------------")
print(df.sort_index(axis=1, ascending=False))运行结果如下所示。 ascending参数默认为True正序,设置ascending=False时为倒序。axis参数默认为0,对列索引排序,想要对行索引排序时,需将axis设置为1。
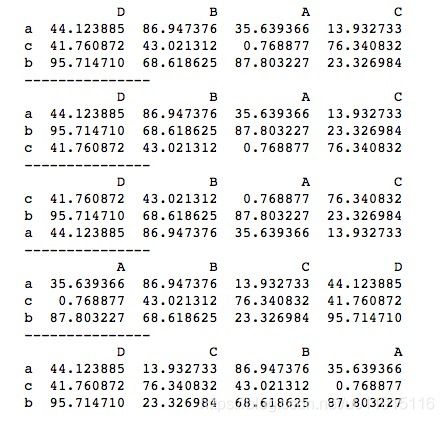
六、时间序列
在金融等领域里,数据分析经常会用到时间序列。
时间序列是指将同一统计指标的数值按其发生的时间先后顺序排列而成的数列。时间序列分析的主要目的是根据已有的历史数据对未来进行预测。根据观察时间的不同,时间序列中的时间可以是年份、季度、月份或其他任何时间形式。
Python自带时间模块
Python中有自带的时间模块datetime。datetime模块以简单和复杂的方式提供用于操作日期和时间的类。虽然datetime支持日期和时间算法,但它实现的重点主要是输出格式和操作的有效属性提取。 datetime主要包括timedelta、date、datetime、time、tzinfo、timezone等类。
1、timedelta类
timedelta类表示持续时间,即两个日期或时间之间的差异。创建一个时间差对象使用datetime.timedelta(),可传参数包括days天,seconds秒,microseconds微秒,milliseconds毫秒,minutes分,hours时,weeks周,默认为天。基本使用方法如下。
import datetime
t_now = datetime.datetime(2019, 4, 4, 15, 30)
# 默认单位为天
t1 = datetime.timedelta(100)
print(t_now + t1) # 100天后
print("---------------")
t2 = datetime.timedelta(weeks=1)
print(t_now - t2) # 1周前
print("---------------")
t3 = datetime.timedelta(hours=3)
print(t_now + t3) # 3小时周后
print("---------------")
t4 = datetime.timedelta(days=3, weeks=1, hours=2, minutes=10)
print(t_now + t4) # 1周零3天2小时10分钟后 datetime()可以创建一个时间,后面马上会具体介绍。timedelta()当不指定属性名时,传入的值默认设置days。timedelta()支持传一个属性,也可以同时传多个属性。原时间加一个timedelta,得到的新时间为原时间经过timedelta时间差后;原时间减一个timedelta,新时间为原时间在timedelta时间差前的时间。运行结果如下所示。
2、date类
date类表示理想化日历中的日期,即以年、月、日表示,当前的公历在两个方向上无限延长。1年的1月1日称为1日,1年的1月2日称为2日,以此类推。这与Dershowitz的“无神论公历”和Reingold的《历法计算》一书中的“无神论公历”的定义相匹配,它是所有计算的基准日历。《历法计算》介绍了在公历序数和许多其他日历系统之间转换的算法。
创建一个date对象使用datetime.date(),参数包括year年,month月,day日,且必须都传。基本使用方法如下。
import datetime
date = datetime.date(2019, 10, 1)
print(date)
print("---------------")
today = datetime.date.today()
print(today)
print("---------------")
print(today.year)
print(today.month)
print(today.day)
print("---------------")
print(today.max)
print(today.min)date类方法today()可以获取今天的日期,date对象可以分别获取年(year)、月(month)、日(day)的值,max和min可以分别获取最大最小日期,可以看到,最大日期为9999年的最后一天,最小日期为0001年的第一天。运行结果如下所示。

date对象有很多实用的方法,常用的包括以下几个。
weekday():返回当前日期在当前周里的序数,从0开始计,例如周四的序数是3。
toordinal():返回日期的公历序数,0001-01-01为第1天。
isoweekday():以整数形式返回星期几,其中星期一为1,星期日为7。
isocalendar():返回一个包含年、当前年的周序数(第几周)、当前周的序数(weekday)的一个元组。
replace(year, month, day):重新设置年、月、日,可以只修改其中任意一个,也可以全部修改。
我们看一下这些方法的基本用法。
import datetime
date = datetime.date(2019, 4, 4)
print(date)
print("---------------")
print(date.weekday())
print("---------------")
# 返回日期的公历序数
print(date.toordinal())
print("---------------")
# 以整数形式返回星期几,其中星期一为1,星期日为7
print(date.isoweekday())
print("---------------")
# 以整数返回年,周序号,weekday
print(date.isocalendar())
print("---------------")
print(date.replace(2018))运行结果如下所示。

3、time类
time类表示一天中的(本地)时间,独立于任何特定日期。创建一个时间差对象使用datetime.time()方法,主要参数包括hour时,minute分,second秒,microsecond微秒。基本用法如下。
import numpy as np
import pandas as pd
import datetime
time = datetime.time(12, 59, 13, 13)
print(time)
print("---------------")
print(time.max)
print("---------------")
print(time.min)运行结果如下所示。 time的最大值和最小值分别为23:59:59.999999和00:00:00,由此可见,hour、minute、second和microsecond的范围分别为[0,23)、[0,60)、[0,60)、[0,1000000)。
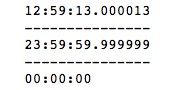
4、datetime类
datetime类包含日期和时间的所有信息。像日期对象一样,datetime假定当前公历向两个方向扩展;像时间对象一样,datetime假定每天正好有3600*24秒。创建一个时间差对象使用datetime.datetime()方法,参数包括了date()方法和time()方法的所有参数,主要有year年,month月,day日,hour时,minute分,second秒,microsecond微秒,其中year年,month月,day日是必传参数,其他可选。
import datetime
now = datetime.datetime.now()
print(now)
print("---------------")
print(now.max)
print(now.min)
print("---------------")
t1 = datetime.datetime(2019, 10, 1, 5, 1, 34)
t2 = datetime.datetime(2019, 11, 1, 9, 1, 1)
print(t1)
print("---------------")
print(t2)
print("---------------")
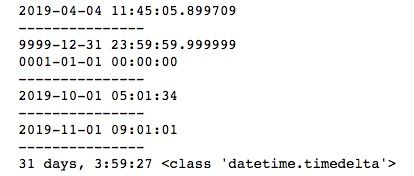
print(t2 - t1, type(t2 - t1))datetime可以看成是date和time的综合,now()方法获取当前时间,我们打印datetime的max和min可以看到,其实就是date和time的最大值或最小值的结合。两个时间之间的差就是时间差。
字符串转日期时间
python中的dateutil库有专门处理字符串转日期时间的函数parser.parse(),支持各种格式的日期时间字符串转换。基本用法如下。
from dateutil.parser import parse
date1 = '04/02/2019' # 月在前
date2 = '20/04/2019' # 日在前(日如果小于12就会被当月处理)
date3 = '02/04/2019'
date4 = 'Apr 2, 2019 09:10:20'
print(parse(date1))
print("---------------")
print(parse(date2))
print("---------------")
print(parse(date3))
print("---------------")
print(parse(date3, dayfirst=True))
print("---------------")
print(parse(date4))
print("---------------")
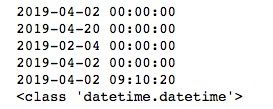
print(type(parse(date1)))需要注意的是,使用“日/月/年”格式的时间字符串时,如果“日”小于12会被当“月”处理,即变成“月/日/年”,这时我们需要设置dayfirst参数为True来显示指定第一个数字为“日”,运行结果如下所示。
pandas中的时刻数据Timestamp
pandas中的Timestamp代表的是时刻数据,是pandas中的时间数据类型,是将值与时间点相关联的最基本的时间序列数据类型。创建Timestamp有两种方法:Timestamp()构造方法和to_datetime()方法。
1、使用Timestamp()构造方法创建Timestamp对象
调用pandas的Timestamp()函数直接生成pandas的时刻数据Timestamp对象,我们来创建一个简单的Timestamp,并查看它的数据类型,代码如下。
import pandas as pd
import datetime
date1 = '20190404'
date2 = datetime.datetime(2019, 4, 4)
t1 = pd.Timestamp(date1)
t2 = pd.Timestamp(date2)
print(t1)
print("---------------")
print(t2)
print("---------------")
print(type(t1))
print("---------------")
print(type(t2))
print("---------------")
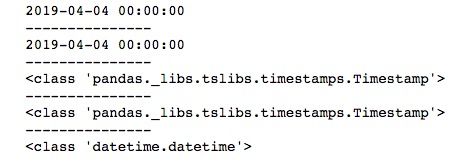
print(type(date2))无论是字符串还是Python自带时间库生成的日期时间,调用Timestamp()函数都可以生成pandas的时刻数据,类型为Timestamp。运行结果如下所示。
2、使用to_datetime()方法创建Timestamp对象
调用pandas中的to_datetime()方法也可以用于创建Timestamp对象。
import pandas as pd
import datetime
date1 = '20190404'
date2 = datetime.datetime(2019, 4, 4)
t1 = pd.to_datetime(date1)
t2 = pd.to_datetime(date2)
print(t1)
print("---------------")
print(t2)
print("---------------")
print(type(t1))
print("---------------")
print(type(t2))运行结果如下所示。

to_datetime()方法除了用于创建Timestamp对象外,还可以用于创建DatetimeIndex时间索引。当to_datetime()方法传入的参数为数组列表时,就会转换为DatetimeIndex时间索引。
import pandas as pd
from datetime import datetime
date1 = [datetime(2019, 4, 1), datetime(2019, 4, 2), datetime(2019, 4, 3)]
date2 = ['2019-04-04', '2019-04-05']
t1 = pd.to_datetime(date1)
t2 = pd.to_datetime(date2)
print(t1)
print("---------------")
print(t2)
print("---------------")
print(type(t1))
print("---------------")
print(type(t2))运行结果如下所示。

如果我们传入的数组列表中包含非时间格式的字符串时就会报错。我们可以使用errors参数来规避报错。errors参数可以传ignore或coerce两种值。如果传ignore,表示忽略错误,此时当有非时间格式的字符串不可解析时会返回原始数据,从而直接生成一个一维ndarray。如果传coerce,则表示不可扩展,此时若有非时间格式的字符串不可解析时将以缺失值处理,缺失值返回NaT(Not a Time),生成的仍然为一个DatetimeIndex时间索引。
import pandas as pd
date = ['2019-04-04', '2019-04-05', 'xzq']
# ignore 不可解析时返回原始数据 直接生成ndarray
t1 = pd.to_datetime(date, errors='ignore')
print(t1)
print("---------------")
print(type(t1))
print("---------------")
# coerce 不可扩展 缺失值返回NaT(Not a Time) 结果保持DatetimeIndex
t2 = pd.to_datetime(date, errors='coerce')
print(t2)
print("---------------")
print(type(t2))运行结果如下所示。我们在使用to_datetime()时一般都是为了生成DatetimeIndex时间索引,所以在传errors参数时,一般设置为coerce。

TimeSeries
TimeSeries就是以时间序列为索引的Series。首先创建一个DatetimeIndex时间索引,然后使用pandas的Series()方法将时间索引赋值给index参数。
import pandas as pd
import numpy as np
dt = pd.DatetimeIndex(['4/4/2019', '4/5/2019', '4/6/2019', '4/7/2019', '4/8/2019'])
ts = pd.Series(np.random.rand(len(dt)), index=dt)
print(ts)
print(type(ts))
print(type(ts.index))运行结果如下所示。 TimeSeries的类型就是Series,索引类型为时间序列索引DatetimeIndex。
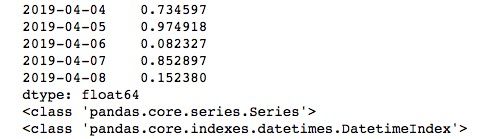
时间范围生成
在使用时间序列时,我们不可能每次都通过列表的形式将时间一个一个写进去。pandas中给我们提供了生成时间范围的函数date_range(),主要参数包括start,end,periods,freq,tz,normalize,name和closed,各参数含义与作用如下。
start:时间范围的开始时间,包括本身。
end:时间范围的结束时间,包括本身。
periods:偏移量。一般单独使用start或end时与之配合生成时间范围。
freq:频率,默认为“D”天。
tz:时区。
normalize:正则化时间。为True时忽略时分秒,False时将使用时分秒。
name:索引对象名称。
closed:可选值包括left和right。left表示不包括start本身,right表示不包括end本身。
时间范围的生成有两个方法:1、使用start和end参数生成时间范围。2、使用start或end加上偏移量periods生成时间范围。两种方法的基本用法如下。
import pandas as pd
range1 = pd.date_range("4/1/2019", "4/10/2019")
range2 = pd.date_range(start='2019-04-01', periods=10)
range3 = pd.date_range(end='4/10/2019 16:00:00', periods=10, freq='H')
print(range1)
print("---------------")
print(range2)
print("---------------")
print(range3)start和end可以使用多种时间格式的字符串,periods默认为天,上述代码中range2生成的是2019-04-01按每天往后共10天的时间范围。如果不想使用一天为间隔,可以使用freq参数,range3我们将freq设为‘H’,就变成2019-04-10 16:00:00按每小时往前共10小时的时间范围了。运行结果如下所示。
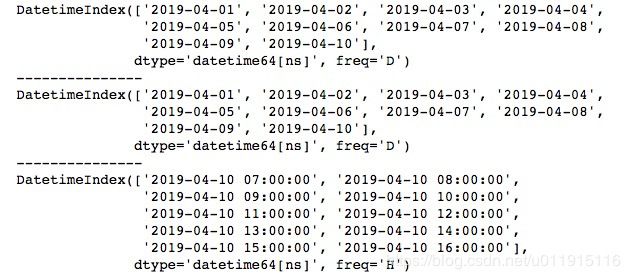
在使用时间序列时,有时我们会只关心工作日,即除去包括周六、周日的非法定工作时间,这时我们会使用bdate_range()方法,该方法使用时和date_range()方法基本一致。
import pandas as pd
range1 = pd.bdate_range("4/1/2019", "4/10/2019")
range_1 = pd.date_range("4/1/2019", "4/10/2019", freq='B')
print(range_1)
range2 = pd.bdate_range(start='2019-04-01', periods=10)
print(range1)
print("---------------")
print(range2)运行结果如下所示。实际上,bdate_range()方法就是date_range()方法将freq参数设置为‘B’时的情况。
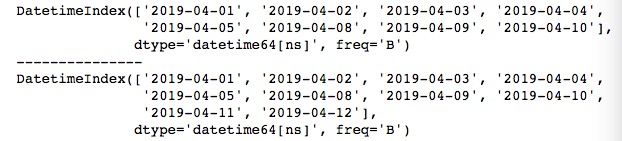
时间范围频率
在使用date_range()时,我们用得较多的就是频率参数freq。传入不同的freq可以获取各种不同的时间范围。
import pandas as pd
print(pd.bdate_range("4/1/2019", "4/10/2019"))
print("---------------")
print(pd.bdate_range("4/1/2019", "4/10/2019", freq='B')) # 每工作日
print("---------------")
print(pd.bdate_range("4/1/2019", "4/2/2019", freq='H')) # 每小时
print("---------------")
print(pd.bdate_range("4/1/2019 16:00:00", "4/1/2019 16:05:00", normalize=False, freq='T')) # 每分
print("---------------")
print(pd.bdate_range("4/1/2019 16:00:00", "4/1/2019 16:00:10", normalize=False, freq='S')) # 每秒
print("---------------")
print(pd.date_range("4/1/2019", "6/1/2019", freq='W-MON')) # 每周的指定星期几
print("---------------")
print(pd.date_range("4/1/2019", "6/1/2019", freq='WOM-2MON')) # 每月的第几个星期几(每月第2个星期一)默认的freq参数是‘D’,表示以天为单位。除了上述提到的‘B’表示工作日为单位,还有‘H’、‘T’、‘S’分别表示以时、分、秒为单位。此外,W-*模式表示指定每周的星期几,上述代码中的‘W-MON’表示取时间范围内的每周的星期一。WON-*模式表示每月的第几个星期几,上述代码中‘WON-2MON’表示取时间范围内每月的第2个星期一。运行结果如下所示。
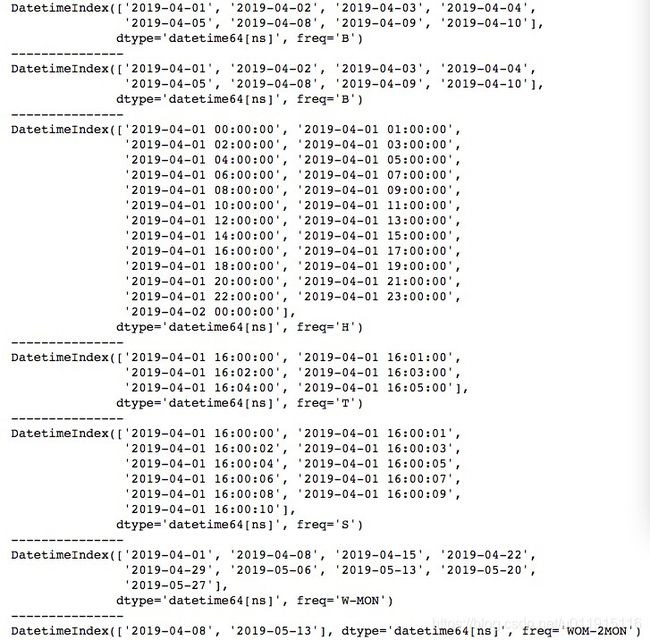
在提取以时间序列为索引的数据时,我们常常会特别关注开头或结尾的时间上,例如每月的第一天、最后一天,每个季度的第一天、最后一天等。我们使用‘M’表示取每月的最后一天,‘Q-*’模式表示取每个季度的最后一个月的最后一天,‘A-*’模式表示取指定月的最后一天。其中,季度的划分是自由的,‘*’处填入的月份表示季度结束月,例如我们使用‘Q-DEC’表示最后一个季度的最后一个月为12月,那么季度的划分就变成1-3月、4-6月、7-9月、10-12月这四个季度。
import pandas as pd
# 每月最后一个日历日
print(pd.date_range("2019-01-01", "2019-12-31", freq='M'))
print("---------------")
# 每个季度末最后一个月的最后一个日历日 (DEC 12月为季度的结束月)
print(pd.date_range("2019-01-01", "2020-12-31", freq='Q-DEC'))
print("---------------")
print(pd.date_range("2019-01-01", "2020-12-31", freq='Q-JAN'))
print("---------------")
# 每年指定月的最后一个日历日 (DEC 12月为季度的结束月)
print(pd.date_range("2019-01-01", "2020-12-31", freq='A-DEC'))
print("---------------")
# 第一个日历日
print(pd.date_range("2019-01-01", "2019-12-31", freq='MS'))
print("---------------")
print(pd.date_range("2019-01-01", "2020-12-31", freq='QS-DEC'))
print("---------------")
print(pd.date_range("2019-01-01", "2020-12-31", freq='QS-JAN'))
print("---------------")
print(pd.date_range("2019-01-01", "2020-12-31", freq='AS-DEC'))运行结果如下所示。若想取第一天,只需要在相应的freq后面加S即可。

如果我们只想对工作日进行操作,只需要将freq最开始分别加个‘B’就可以了,代码如下。
import pandas as pd
# 工作日
# 最后一天
print(pd.date_range("2019-01-01", "2019-12-31", freq='BM'))
print("---------------")
print(pd.date_range("2019-01-01", "2020-12-31", freq='BQ-DEC'))
print("---------------")
print(pd.date_range("2019-01-01", "2020-12-31", freq='BQ-JAN'))
print("---------------")
print(pd.date_range("2019-01-01", "2020-12-31", freq='BA-DEC'))
print("---------------")
# 第一天
print(pd.date_range("2019-01-01", "2019-12-31", freq='BMS'))
print("---------------")
print(pd.date_range("2019-01-01", "2020-12-31", freq='BQS-DEC'))
print("---------------")
print(pd.date_range("2019-01-01", "2020-12-31", freq='BQS-JAN'))
print("---------------")
print(pd.date_range("2019-01-01", "2020-12-31", freq='BAS-DEC'))运行结果如下所示。我们掌握了取最后一个日历日的使用方法后,只需通过加‘S’和‘B’即可提取第一个日历日、最后一个工作日、第一个工作日的时间。
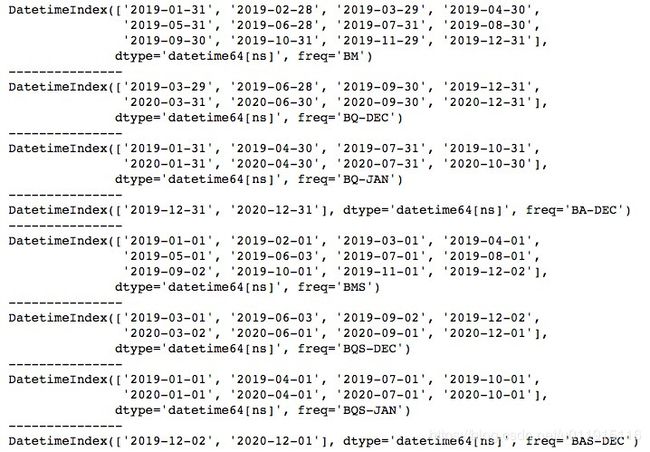
除上述提到的freq,我们还经常会用到复合频率,例如提取每隔一周的时间等,这时我们可以用数字(指定间隔)加字母(指定间隔单位)的组合进行操作。
import pandas as pd
# 隔7天
print(pd.date_range("2019-01-01", "2019-02-01", freq='7D'))
print("---------------")
# 每2.5小时
print(pd.date_range("2019-01-01", "2019-01-02", freq='2H30T'))
print("---------------")
# 每2月第一个日历日
print(pd.date_range("2019-01-01", "2019-12-31", freq='2MS'))运行结果如下所示。 通过这种方式我们可以提取任意频率间隔的时间。
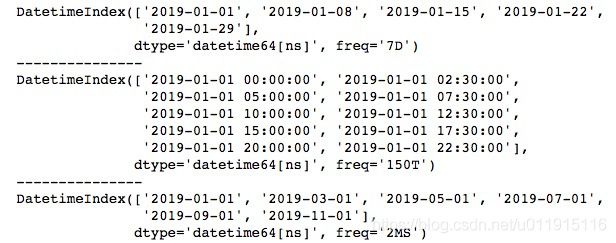
频率转换
频率转换使用asfreq()函数,可以重新设置时间序列的频率间隔。基本用法如下。
import pandas as pd
import numpy as np
ts = pd.Series(np.random.rand(4), index=pd.date_range('2019-04-06', '2019-04-09'))
print(ts)
print("---------------")
print(ts.asfreq('12H'))
print("---------------")
# method None:不填充 ffill用之前的值填充 bfill用之后的值填充
print(ts.asfreq('12H', method='ffill'))上述代码将以一天为间隔转换为以0.5天即12小时为间隔,可以看到多出的几个时间对应的数据是缺失值NaN,如果我们不想出现NaN,可以使用method参数,传入ffill或bfill分别以之前的值或之后的值进行填充。运行结果如下所示。
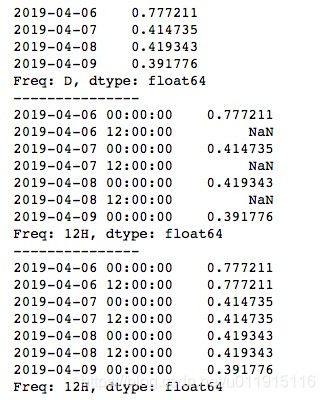
频率的超前与滞后
频率的超前与滞后是指对TimeSeries的时间索引或数据进行前移或后移,使用shift()函数,传入正数表示后移,负数表示前移,我们看一下效果。
import pandas as pd
import numpy as np
ts = pd.Series(np.random.rand(4), index=pd.date_range('2019-04-06', '2019-04-09'))
print(ts)
print("---------------")
# 正数:数值后移(滞后) 负数:数值前移(超前)
print(ts.shift(2))
print("---------------")
print(ts.shift(-2))运行结果如下所示。shift()函数默认是对TimeSeries的数据进行移动,例如shift(2)将数据前移2个单位,原来6-9号的数据变成了8-11号的数据,所以新的TimeSeries中6号与7号位置上的数据就为缺失值了。
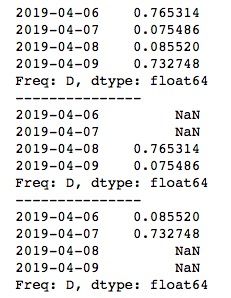
我们也可以移动时间索引,只需要使用参数freq,传入相应的频率单位即可。
import pandas as pd
import numpy as np
ts = pd.Series(np.random.rand(4), index=pd.date_range('2019-04-06', '2019-04-09'))
print(ts)
print("---------------")
# 对时间索引移动
print(ts.shift(2, freq='D'))
print("---------------")
print(ts.shift(2, freq='H'))运行结果如下所示。
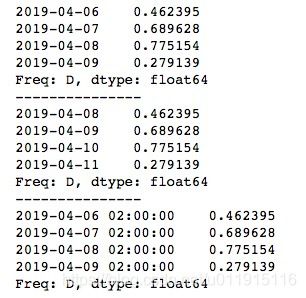
通过频率的超前与滞后,我们可以做许多事情,例如求每天的变化百分比。
import pandas as pd
import numpy as np
ts = pd.Series(np.random.rand(4), index=pd.date_range('2019-04-06', '2019-04-09'))
print(ts)
print("---------------")
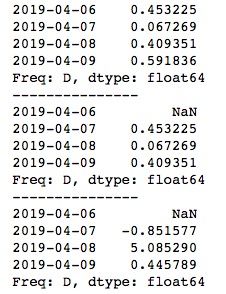
print(ts.shift(1))
print("---------------")
# 变化百分比
per = ts/ts.shift(1) - 1
print(per)使用shift(1)将数据前移1个单位后,可以看到对应时间上的数据相当于是前一日的数据,此时用原TimeSeries去除以新TimeSeries就是变化率了,再减去1来表示是涨还是跌。运行结果如下所示。
时间序列的重采样resample
时间序列的重采样指的是将时间序列从一个频率转换为另一个频率的过程,并且常常会伴随有数据的结合。重采样分为降采样和升采样两种。
降采样:高频数据-低频数据。例如,将一个以天为频率的时间序列转化为以月为频率的时间序列。
升采样:低频数据-高频数据。例如,将一个以年为频率的时间序列转化为以月为频率的时间序列。
pandas中我们使用resample()方法对时间序列进行重采样,基本用法如下:
import pandas as pd
import numpy as np
dr = pd.date_range('20190514', periods=12)
ts = pd.Series(np.arange(12), index=dr)
print(ts)
print("---------------")
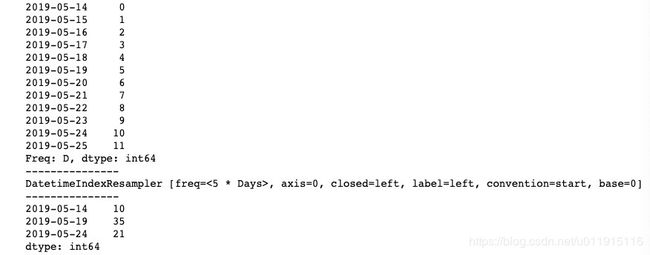
# 得到一个重采样构造器 频率被修改为5天
ts_re = ts.resample('5D')
print(ts_re)
print("---------------")
# 得到一个新的聚合后的Series 聚合方式为sum()求和
ts_re = ts.resample('5D').sum()
print(ts_re)我们创建了一个以天为频率的TimeSeries,然后使用resample()方法将它转化为以5天为频率的TimeSeries。运行结果如下图所示,可以看到,resample()方法返回的是一个重采样构造器,我们可以对它进行聚合从而生成新的TimeSeries,上述代码我们使用的聚合方式为求和。
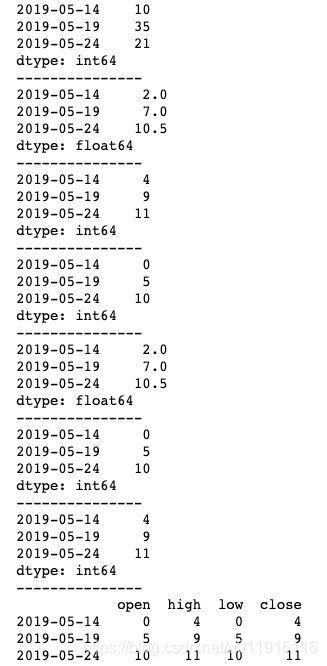
常见的聚合方式除了上述用到的求和外,还有求平均值、最大值、最小值、中值等,具体用法如下。
import pandas as pd
import numpy as np
dr = pd.date_range('20190514', periods=12)
ts = pd.Series(np.arange(12), index=dr)
print(ts)
print("---------------")
# 求和
print(ts.resample('5D').sum())
print("---------------")
# 求平均值
print(ts.resample('5D').mean())
print("---------------")
# 求最大值
print(ts.resample('5D').max())
print("---------------")
# 求最小值
print(ts.resample('5D').min())
print("---------------")
# 求中值
print(ts.resample('5D').median())
print("---------------")
# 返回第一个值
print(ts.resample('5D').first())
print("---------------")
# 返回最后一个值
print(ts.resample('5D').last())
print("---------------")
# OHLC重采样
print(ts.resample('5D').ohlc())OHLC重采样在金融领域里经常用到,它是金融领域的时间序列聚合方式,包括open(开盘)、high(最大值)、low(最小值)、close(收盘)四个值,熟悉股票的朋友可以发现,这是绘制K线图的必须参数。运行结果如下图所示。
降采样是从高频数据到低频数据,在使用resample()方法时,我们常常会用到两个参数:closed和label。
首先我们看一下closed的用法,closed默认值为“left”,可以将其修改为“right”,基本用法如下。
import pandas as pd
import numpy as np
dr = pd.date_range('20190514', periods=12)
ts = pd.Series(np.arange(12), index=dr)
print(ts)
print("---------------")
# 默认
print(ts.resample('5D').sum())
print("---------------")
print(ts.resample('5D', closed='left').sum())
print("---------------")
print(ts.resample('5D', closed='right').sum())运行结果如下图所示。咋一看,closed参数的作用有点难以理解,下面我们来细分这个过程。首先因为我们设置的频率为5天,所以0-11这12个值会根据5个值一组进行拆分,默认closed值为left,此时是左闭右开,就变成了[0, 5),[5, 10),[10, 15)这三组(最后一组补齐5个值),即[0, 1, 2, 3, 4],[5, 6, 7, 8, 9],[10, 11]。而当我们将closed值设置为right时就变成了左开右闭,几组值就相应地变为(0, 5],(5, 10],(10, 15],由于0这个值不再包含于第一组,所以就会独立出去,成为了[0],[1, 2, 3, 4, 5],[6, 7, 8, 9, 10],[11]四组值。明白了这一过程,再看运行结果就不难理解了。
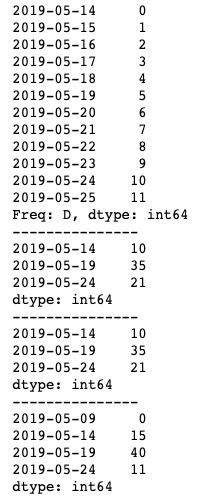
label参数与closed参数类似,也有left、right两种值,基本用法如下。
import pandas as pd
import numpy as np
dr = pd.date_range('20190514', periods=12)
ts = pd.Series(np.arange(12), index=dr)
print(ts)
print("---------------")
# 默认
print(ts.resample('5D').sum())
print("---------------")
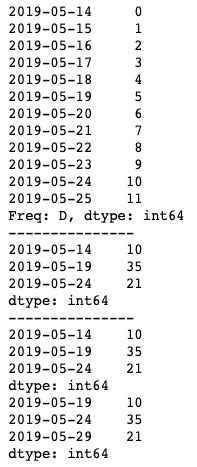
print(ts.resample('5D', label='left').sum())
print(ts.resample('5D', label='right').sum())运行结果如下图所示。可以看到,label默认值也为left,即降采样后的index会采用区间的左边值,而修改为right后就会采用区间的右边值。在明白closed参数的含义后,相信label就不难理解了。
升采样是从高频数据到低频数据,升采样我们关心的是如何插值,因此不需要使用closed和label参数,事实上,即使你使用这两个参数也是没有效果的。从高频数据到低频数据会产生没有默认值的新index索引,默认会以NaN填充,我们可以使用ffill()或bfill()方法对其进行向上填充或向下填充。基本用法如下。
import pandas as pd
import numpy as np
dr = pd.date_range('2019/5/14 11:0:0', periods=5, freq='H')
ts = pd.DataFrame(np.arange(15).reshape(5, 3), index=dr, columns=list('abc'))
print(ts)
print("---------------")
# 转为频率为15分钟
print(ts.resample('30T').asfreq())
print("---------------")
print(ts.resample('30T').ffill())
print("---------------")
print(ts.resample('30T').bfill())运行结果如下图所示。由于resample()方法的返回结果是重采样的构造器,因此我们使用asfreq()方法将其转化为TimeSeries。

pandas简单数值计算和统计基础
我们使用pandas的一个主要目的就是为了进行数据的数值计算和统计。常用的简单数值计算方法有:
count():统计非NaN值的数量。
max()、min():样本最大值、最小值。
sum():样本总和。
mean():样本平均值。
quantile():样本分位数,参数q确定位置,如q=0.25就是按一定顺序排序后1/4位置上的数。
median():样本中位数,其实就是quantile()中q=0.5情况下的分位数。
std():样本标准差。
skew():样本的偏度。偏度也称为偏态、偏态系数,是统计系数分布偏斜方向和程度的度量,是统计数据分布非对称程度的数字特征。
kurt():样本的峰度。峰度又称峰态系数。表征概率密度分布曲线在平均值处峰值高低的特征数。直观来看,峰度反映了峰部的尖度。样本的峰度是和正态分布相比较而言的统计量,如果峰度大于三,峰的形状比较尖,比正态分布峰要陡峭。反之亦然。
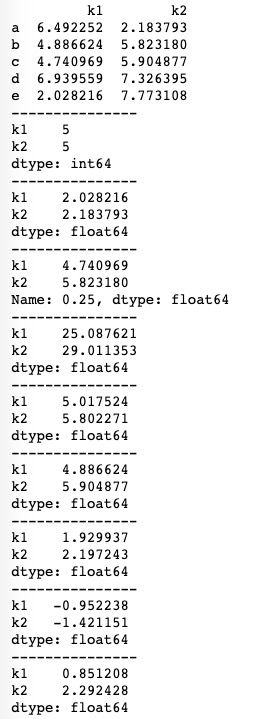
pandas中上述计算方法基本用法如下:
import pandas as pd
import numpy as np
df = pd.DataFrame({'k1':np.random.rand(5)*10, 'k2':np.random.rand(5)*10}, index=list('abcde'))
print(df)
print("---------------")
# 统计非NaN值的数量
print(df.count())
print("---------------")
# 统计最小值
print(df.min())
print("---------------")
# 统计分位数,参数q确定位置
print(df.quantile(q=0.25))
print("---------------")
# 求和
print(df.sum())
print("---------------")
# 求平均值
print(df.mean())
print("---------------")
# 求中位数 即q=0.5的分位数
print(df.median())
print("---------------")
# 求标准差
print(df.std())
print("---------------")
# 样本的偏度
print(df.skew())
print("---------------")
# 样本的峰度
print(df.kurt())运行结果如下图所示。
在计算的时候,我们经常会用到axis和skipna这两个参数。axis用于指定计算哪个轴上的数据,skipna用于指定是否过滤缺失值NaN。我们以求平均值mean()为例看一下这两个参数的基本用法。
import pandas as pd
import numpy as np
df = pd.DataFrame({'k1':[1, 2, 3, np.nan, 5], 'k2':[6, 7, np.nan, 8, 9], 'k3':[6, 7, np.nan, '8', 9]}, index=list('abcde'))
print(df)
print("---------------")
print(df.mean())
print("---------------")
# 计算结果会过滤掉字符串
print(df.mean(axis=1))
print("---------------")
print(df.mean(axis=1, skipna=False))axis默认为0,即以列为单位进行数值计算,当设置axis=1时,就会以行为单位进行计算。skipna默认为True,即过滤缺失值NaN值,如果我们在计算时不想过滤缺失值,只需要将skipna设置为False即可。运行结果如下所示。可以看到以列为单位进行计算时k3列的结果没有返回,那是因为k3中有字符类型的8,从而使整个k3列的数据类型都为字符类型(可以使用df['k3'].dtype查看k3列的数据类型),因此不做数值计算。

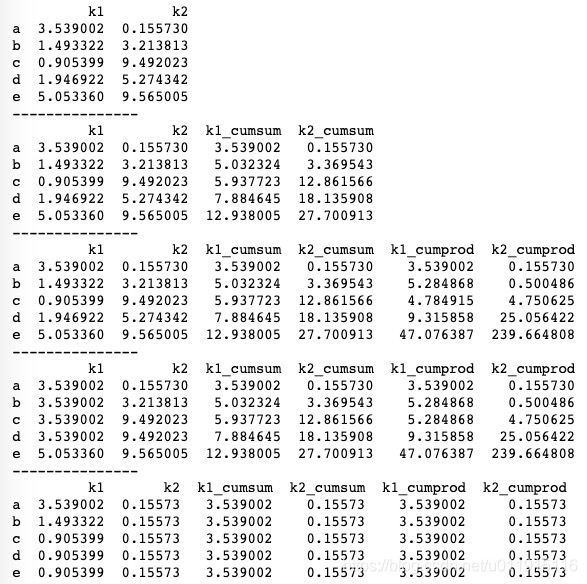
除上述常用的几个简单数值计算方法外,还有累计和、累计积这两个统计学上经常用到的方法。pandas中分别使用cumsum()和cumprod()进行累加和累乘运算。基本用法如下。
import pandas as pd
import numpy as np
df = pd.DataFrame({'k1':np.random.rand(5)*10, 'k2':np.random.rand(5)*10}, index=list('abcde'))
print(df)
print("---------------")
# 样本累计和
df['k1_cumsum'] = df['k1'].cumsum()
df['k2_cumsum'] = df['k2'].cumsum()
print(df)
print("---------------")
# 样本累计积
df['k1_cumprod'] = df['k1'].cumprod()
df['k2_cumprod'] = df['k2'].cumprod()
print(df)
print("---------------")
print(df.cummax())
print("---------------")
print(df.cummin())需要注意的是,cumsum()和cumprod()是针对某一个轴而言的,直接使用df.cumsum()是不可行的。此外,cumsum()和cumprod()的计算结果会插入到源DataFrame中,合并生成一个新的DataFrame。cummax()和cummin()通常用于统计最大值和最小值,对于上述代码而言,就是从a开始到e,如果有比当前值大(小)的就显示该值,因此最终e位置上的值就是该列的最大(小)值。运行结果如下图所示。
在统计数据的时候,筛选出唯一值也是比较常见的一种方式。pandas中我们可以使用求唯一值的unique()方法或者使用计数方法value_counts()。
我们首先看一下求唯一值的unique()方法的基本用法。
import pandas as pd
import numpy as np
s = pd.Series(list('abdswabcdefgbdswaws'))
print(s)
print("---------------")
sq = s.unique()
print(sq)
print("---------------")
sq.sort()
print(sq)
print("---------------")
print(pd.Series(sq))对于一个有重复值的Series,使用unique()方法可以得到一个唯一值列表,然后再使用这个列表重新生成Series即可得到一个唯一值Series。在生成新的Series前,我们还可以使用sort()方法对列表进行排序。运行结果如下图所示。

下面我们看一下计数方法value_counts(),value_counts()主要作用是计数,但它得到的结果也是一个唯一值,只是这个唯一值是作为索引出现的。value_counts()的基本用法如下。
import pandas as pd
import numpy as np
s = pd.Series(list('abdswabcdefgbdswaws'))
print(s)
print("---------------")
sc = s.value_counts(sort=False)
print(sc)对于一个有重复值的Series,使用value_counts()方法可以对其中的值出现的次数进行统计,参数sort表示是否对结果进行排序,注意,这里的排序是对出现次数的多少进行排序。运行结果如下图所示。

在统计数据的时候,我们有时也会需要知道某个值是否在数据集中,pandas中的成员资格方法isin()就是用于此功能的。Series和DataFrame都有isin()方法,isin()接收一个列表,即使只是探索一个值是否在数据集中,这个值也必须被包装成列表数据才能传入isin()。isin()方法的基本用法如下。
import pandas as pd
import numpy as np
s = pd.Series(np.arange(10, 15))
df = pd.DataFrame({'k1':list('abdswabcd'), 'k2':np.arange(1, 10)}, index=list('abcdefghi'))
print(s)
print("---------------")
print(df)
print("---------------")
print(s.isin([5, 10, 14]))
print(df.isin(list('abc')))isin()方法返回一个布尔类型的Series或DataFrame,存在的数据所在的位置上的值为True,其余位置上的值为False,运行结果如下图所示。

pandas数据合并
pandas具有全功能、高性能的在内存中的连接操作,这与SQL等关系型数据库非常相似。pandas中主要使用merge()和join()这两个方法来合并数据。
merge()方法接收要合并的两个DataFrame数据,并指明合并参考键。基本用法如下。
import pandas as pd
import numpy as np
df1 = pd.DataFrame({'key':['key0','key1','key2','key3'],
'A':['a0','a1','a2','a3'],
'B':['b0','b1','b2','b3']})
df2 = pd.DataFrame({'key':['key0','key1','key2','key3'],
'C':['c0','c1','c2','c3'],
'D':['d0','d1','d2','d3']})
print(df1)
print("---------------")
print(df2)
print("---------------")
# on参数表示合并参考键
print(pd.merge(df1, df2, on='key'))以上代码中的两个DataFrame数据中有个相同的键key,我们可以把它作为参考键,合并时只需要将两个DataFrame传入merge()方法,并将on参数指定两个DataFrame的共同键即可。运行结果如下图所示。

当DataFrame中有两个可以作为参考键的键时,我们可以给on参数传入一个列表,将DataFrame的两个参考键都传入即可。基本用法如下。
import pandas as pd
import numpy as np
df1 = pd.DataFrame({'K1':['key0','key0','key1','key2'],
'K2':['key0','key1','key0','key1'],
'A':['a0','a1','a2','a3'],
'B':['b0','b1','b2','b3']})
df2 = pd.DataFrame({'K1':['key0','key1','key1','key2'],
'K2':['key0','key0','key0','key0'],
'C':['c0','c1','c2','c3'],
'D':['d0','d1','d2','d3']})
print(df1)
print("---------------")
print(df2)
print("---------------")
print(pd.merge(df1, df2, on=['K1', 'K2']))上述代码中参考键on传入了K1、K2这两个键,合并时就会同时参考K1、K2,并取两者的交集。运行结果如下图所示。

merge()方法提供了how参数,有inner(交集)、outer(并集)、left(左边数据为参考)、right(右边数据为参考)四种值可选(默认为inner,取交集),可以指定采用哪种合并方式。 基本用法如下。
import pandas as pd
import numpy as np
df1 = pd.DataFrame({'K1':['key0','key0','key1','key2'],
'K2':['key0','key1','key0','key1'],
'A':['a0','a1','a2','a3'],
'B':['b0','b1','b2','b3']})
df2 = pd.DataFrame({'K1':['key0','key1','key1','key2'],
'K2':['key0','key0','key0','key0'],
'C':['c0','c1','c2','c3'],
'D':['d0','d1','d2','d3']})
print(df1)
print("---------------")
print(df2)
print("---------------")
# 默认inner:取交集
print(pd.merge(df1, df2, on=['K1', 'K2'], how='inner'))
print("---------------")
# outer:取并集 缺失值为NaN
print(pd.merge(df1, df2, on=['K1', 'K2'], how='outer'))
print("---------------")
# left:左边数据为参考合并,这里就是df1 缺失值为NaN
print(pd.merge(df1, df2, on=['K1', 'K2'], how='left'))
print("---------------")
# right:右边数据为参考合并,这里就是df2 缺失值为NaN
print(pd.merge(df1, df2, on=['K1', 'K2'], how='right'))运行结果如下图所示。当how传outer、left、right这三个值时,有可能出现缺失值,用默认缺失值NaN填充。

当左右两边的数据没有共同的键时,merge()方法为我们提供了left_on和right_on这两个参数,我们可以分别指定左右两边数据各自参考的键,从而顺利进行合并。基本用法如下。
import pandas as pd
import numpy as np
df1 = pd.DataFrame({'key1':list('aabbcc'), 'data1':np.arange(6)})
df2 = pd.DataFrame({'key2':list('abd'), 'data2':np.arange(3)})
print(df1)
print("---------------")
print(df2)
print("---------------")
print(pd.merge(df1, df2, left_on='key1', right_on='key2'))以上代码中,df1有个key1的键,而df2中没有相同的键,我们使用left_on和right_on分别将df1的参考键设为key1,将df2的参考键设为key2,再进行合并,依然可以得到df1和df2的合并并集。运行结果如下图所示。
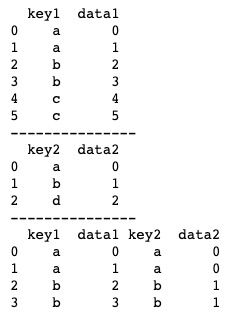
DataFrame数据并不一定都会有一个参考键,这时我们可以利用索引作为参考键,而merge()方法为我们提供了相应的参数。left_index、right_index默认为False,当我们把这两个参数设置为True时,对应的DataFrame就会以索引index作为参考键了。基本用法如下。
import pandas as pd
import numpy as np
df1 = pd.DataFrame({'key':list('aabbcc'), 'data1':np.arange(6)})
df2 = pd.DataFrame({'data2':np.arange(3)}, index=list('abc'))
print(df1)
print("---------------")
print(df2)
print("---------------")
print(pd.merge(df1, df2, left_on='key', right_index=True))上述代码中,df1有一个键key,但df2没有键,我们将right_index设置为True,让df2以索引index为参考键,合并结果如下图所示。

除了merge()方法,pandas中还可以使用join()方法实现合并功能。join()方法是DataFrame的成员方法,默认直接通过索引index进行连接,基本用法如下。
import pandas as pd
import numpy as np
df1 = pd.DataFrame({'A':['a0','a1','a2'], 'B':['b0','b1','b2']}, index=list('abc'))
df2 = pd.DataFrame({'C':['c0','c1','c2'], 'D':['d0','d1','d2']}, index=list('acd'))
print(df1)
print("---------------")
print(df2)
print("---------------")
print(df1.join(df2))
print("---------------")
print(df1.join(df2, how='outer'))
print("---------------")
print(df1.join(df2, how='left'))
print("---------------")
print(df1.join(df2, how='right'))运行结果如下图所示。 join()方法也可以设置on参数指定参考键,用法同merge()方法。

pandas叠加与修补
merge()和join()连接方法是按照一定条件合并的,得到的结果为两者的混合,并重新按照一定的规则排序。而有时我们需要将数据进行直接叠加,这时我们可以使用pandas中的concat()方法。
concat()方法是沿轴执行的连接操作,我们看一下它的基本用法。
import pandas as pd
import numpy as np
s1 = pd.Series([1, 2, 3])
s2 = pd.Series([2, 3, 4])
s3 = pd.Series([1, 2, 3], index=list('afc'))
s4 = pd.Series([2, 3, 4], index=list('edg'))
print(s1)
print("---------------")
print(s2)
print("---------------")
print(s3)
print("---------------")
print(s4)
print("---------------")
print(pd.concat([s1, s2]))
print("---------------")
print(pd.concat([s3, s4]).sort_index())以上代码创建了4个Series,使用concat()方法将要合并的Series组成列表后传入,运行结果如下图所示,可以看到,它只是对原先的Series进行了简单叠加。sort_index()可以对索引进行排序。

concat()方法同样适用于DataFrame,用法与Series的连接一致,基本用法如下。
import pandas as pd
import numpy as np
pd1 = pd.DataFrame({'key':['k0', 'k1', 'k0', 'k1'],
'A':['a0', 'a1', 'a2', 'a3'],
'B':['b0', 'b1', 'b2', 'b3']})
pd2 = pd.DataFrame({'C':['c0', 'c1'],
'D':['d0', 'd1']}, index=['a', 'b'])
print(pd1)
print("---------------")
print(pd2)
print("---------------")
print(pd.concat([pd1, pd2]))运行结果如下图所示。连接后缺失值使用NaN填充。

concat()方法提供了很多实用的参数。axis参数指定连接参考轴,默认axis=0,表示行+行,当我们设置axis=1时,连接时就变成了列+列了。基本用法如下。
import pandas as pd
import numpy as np
s1 = pd.Series([1, 6, 2, 3], index=list('abfc'))
s2 = pd.Series([2, 9, 3, 4], index=list('ebdg'))
print(s1)
print("---------------")
print(s2)
print("---------------")
# 默认axis=0 行+行
print(pd.concat([s1, s2]))
print("---------------")
# 设置axis=1 列+列
print(pd.concat([s1, s2], axis=1))运行结果如下图所示。可以看到,axis=0进行行+行的连接时得到的结果依然是Series,而当我们设置axis=1进行列+列的连接时,得到的结果就变成了DataFrame。

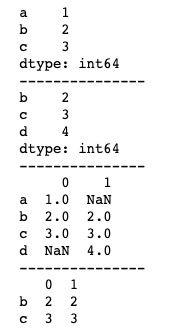
concat()方法默认的连接方式为并集,我们可以通过设置join参数修改concat()方法的连接方式。join参数有inner(交集)、outer(并集)两个值可以选,默认为outer。基本用法如下。
import pandas as pd
import numpy as np
s1 = pd.Series([1, 2, 3], index=list('abc'))
s2 = pd.Series([2, 3, 4], index=list('bcd'))
print(s1)
print("---------------")
print(s2)
print("---------------")
# 连接方式join可选inner、outer 默认并集outer
print(pd.concat([s1, s2], axis=1, sort=False))
print("---------------")
print(pd.concat([s1, s2], axis=1, sort=False, join='inner'))以上代码使用了sort函数,这是因为设置axis=1时运行结果可能会出现警告,使用sort参数可以消除这个警告。sort参数的作用是指定是否对连接结果的索引进行排序。运行结果如下图所示。
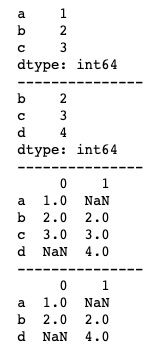
join_axes参数可以指定连接的索引index,即指定连接后的结果包含哪几个索引。基本用法如下。
import pandas as pd
import numpy as np
s1 = pd.Series([1, 2, 3], index=list('abc'))
s2 = pd.Series([2, 3, 4], index=list('bcd'))
print(s1)
print("---------------")
print(s2)
print("---------------")
print(pd.concat([s1, s2], axis=1, sort=False))
print("---------------")
# join_axes参数指定连接的索引index
print(pd.concat([s1, s2], axis=1, sort=False, join_axes=[['a', 'b', 'd']]))运行结果如下图所示。
keys参数可以设置使用指定键作为最外层的索引,默认为空。基本用法如下。
import pandas as pd
import numpy as np
s1 = pd.Series([1, 2, 3], index=list('cba'))
s2 = pd.Series([2, 3, 4], index=list('dcb'))
print(s1)
print("---------------")
print(s2)
print("---------------")
print(pd.concat([s1, s2], keys=['A', 'B']))
print("---------------")
print(pd.concat([s1, s2], axis=1, sort=True, keys=['A', 'B']))运行结果如下图所示。当设置axis=1进行列+列的方式生成DataFrame时,keys设置的索引就是该DataFrame的列索引。

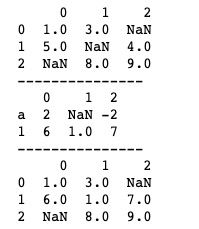
pandas中使用combine_first()方法进行数据修补。我们看一下它的基本用法。
import pandas as pd
import numpy as np
df1 = pd.DataFrame([[1, 3, np.nan], [5, np.nan, 4], [np.nan, 8, 9]])
df2 = pd.DataFrame([[2, np.nan, -2], [6, 1, 7]], index = ['a', 1])
print(df1)
print("---------------")
print(df2)
print("---------------")
print(df1.combine_first(df2))上述代码中我们用df2去修补df1的数据,根据索引index,df1中的空值会被df2中对应位置的非空值代替。如果df2的索引index中含有不同于df1的index(例如上述代码中df2的索引‘a’),则会直接更新到df1中进行合并。运行结果如下图所示。

pandas中还有另一种修补数据的方法update()方法, update()方法的作用是直接覆盖,会将df2中与df1相同索引下的数据直接更新到df1中。基本用法如下。
import pandas as pd
import numpy as np
df1 = pd.DataFrame([[1, 3, np.nan], [5, np.nan, 4], [np.nan, 8, 9]])
df2 = pd.DataFrame([[2, np.nan, -2], [6, 1, 7]], index = ['a', 1])
print(df1)
print("---------------")
print(df2)
print("---------------")
df1.update(df2)
print(df1)运行结果如下图所示。
pandas去重与替换
去重指的是不停的把后面不重复的元素移到前面来,也可以说是用不重复的元素占领重复元素的位置。之前内容中有介绍过unique()方法就是去重的一种方法,pandas中对于去重还提供了其他方法。
duplicated()方法的功能是用于判断Series中的元素、DataFrame中的记录行是否有重复,重复的为True,不重复的为False,返回的是一个布尔型的Series,默认为第一次出现的不算重复。
Series中的duplicated()方法如下:duplicated(keep='first')。它有一个keep参数,指定重复规则,默认为first,即第一次出现的不算重复。我们看一下它的基本用法。
import pandas as pd
import numpy as np
s = pd.Series([1, 2, 3, 4, 5, 1, 3, 5, 6, 2, 4, 6, 8])
print(s)
print("---------------")
# 判断是否重复,默认第一次出现的不算重复 返回一个布尔型Series
print(s.duplicated())
print("---------------")
# 通过布尔索引得到不重复的Series,功能类似于unique()
print(s[s.duplicated() == False])运行结果如下图所示。由于duplicated()方法返回结果是一个布尔型Series,我们需要使用布尔型索引来得到一个去重后的Series。
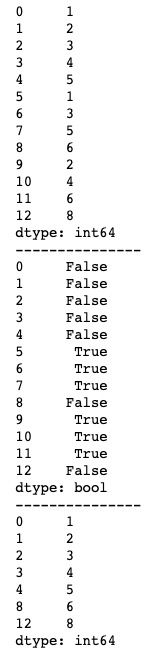
keep参数除默认的first外,还可以设置成last和False两种值。当设置成last时,则规定最后一次出现的元素为不重复;当设置成False时,则所有相同的元素都会被标记为重复。基本用法如下。
import pandas as pd
import numpy as np
s = pd.Series([1, 2, 3, 4, 5, 1, 3, 5, 6, 2, 4, 6, 8])
print(s)
print("---------------")
print(s.duplicated(keep='last'))
print("---------------")
print(s.duplicated(keep=False))运行结果如下图所示。可以看到,当keep='last'时,除了最后一次出现的元素外,其余位置上相同的元素都被标记为重复。而当keep=False时,凡是有相同的元素都被标记为了重复。

duplicated()方法同样可以用于DataFrame。DataFrame中的duplicated()方法如下:duplicated(subset=None, keep='first')。相比于Series的duplicated()方法,除了keep参数,DataFrame的duplicated()方法还有一个subset参数,用于识别重复的列标签或列标签序列,默认所有列标签。基本用法如下。
import pandas as pd
import numpy as np
df = pd.DataFrame({'A':[1, 1, 2, 4, 5],
'B':[1, 1, 2, 2, 7]})
print(df)
print("---------------")
print(df.duplicated())
print("---------------")
print(df.duplicated(['B']))运行结果如下图所示。当DataFrame的duplicated()方法不指定subset参数时,默认所有列标签,即只有所有列的当前位置上都满足是重复值时,才被标记为重复。

duplicated()方法的返回结果是一个布尔型Series,无法直接得到去重后的结果。因此pandas为我们提供了drop_duplicates()方法,用于删除Series或DataFrame中的重复元素,并返回删除重复元素后的结果。
Series和DataFrame的drop_duplicates()方法分别为drop_duplicates(keep='first', inplace=False)和drop_duplicates(self, subset=None, keep='first', inplace=False)。对比duplicated()方法我们可以发现,只是多了一个inplace参数,因此用法基本与duplicated()一致。drop_duplicates()方法的基本用法如下。
import pandas as pd
import numpy as np
s = pd.Series([1, 2, 3, 4, 5, 1, 3, 5, 6, 2, 4, 6, 8])
print(s)
print("---------------")
s_drop = s.drop_duplicates(keep='last')
print(s_drop)
print("---------------")
df = pd.DataFrame({'A':[1, 1, 2, 4, 5],
'B':[1, 1, 2, 2, 7]})
print(df)
print("---------------")
df_drop = df.drop_duplicates(keep='last')
print(df_drop)运行结果如下图所示。
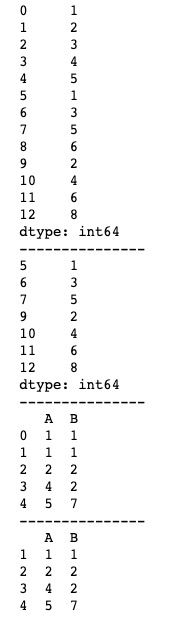
上述代码中我们使用了新的Series和DataFrame去接收drop_duplicates()方法去重后的返回结果,那是因为drop_duplicates()方法默认是生成新的Series或DataFrame,而不改变原Series或DataFrame。如果我们想直接改变原Series或DataFrame,这个时候就用上了inplace参数。inplace参数默认为False不改变原Series或DataFrame,当我们想直接改变原Series或DataFrame时只需设置inplace=True即可。基本用法如下。
import pandas as pd
import numpy as np
s = pd.Series([1, 2, 3, 4, 5, 1, 3, 5, 6, 2, 4, 6, 8])
print(s)
print("---------------")
s.drop_duplicates(keep='last', inplace=True)
print(s)
print("---------------")
df = pd.DataFrame({'A':[1, 1, 2, 4, 5],
'B':[1, 1, 2, 2, 7]})
print(df)
print("---------------")
df.drop_duplicates(keep='last', inplace=True)
print(df)pandas中使用replace()方法替换Series或DataFrame中的元素。replace()方法支持传入列表或字典,可一次性替换一个值或多个值,基本用法如下。
import pandas as pd
import numpy as np
s = pd.Series(list('abcaasbdc'))
print(s)
print("---------------")
print(s.replace('a', 1))
print("---------------")
print(s.replace(['a', 's'], 1))
print("---------------")
print(s.replace({'a':1, 'b':2, 'c':3}))运行结果如下图所示。replace()会遍历所有元素,并将对应的所有元素进行替换。

DataFrame的replace()方法与Series一样,并且会替换所有对应元素。基本用法如下。
import pandas as pd
import numpy as np
df = pd.DataFrame({'A':[1, 1, 2, 4, 5],
'B':[1, 1, 2, 2, 7]})
print(df)
print("---------------")
print(df.replace(1, 'a'))
print("---------------")
print(df.replace([1, 7], 'Hello World!'))
print("---------------")
print(df.replace({1:'a', 2:'b', 4:'d'}))运行结果如下。

pandas中的分组
在对数据进行处理的时候,我们常常会用到分组。pandas为我们提供了groupby()方法来进行分组。分组的具体过程如下:首先根据某些条件将数据拆分成组,然后对每个组独立应用函数方法进行相应的数据运算或处理,最后将结果合并到一个数据结构中。
pandas主要针对DataFrame进行分组操作。DataFrame可以在行(axis=0)或列(axis=1)上进行分组,将一个函数应用到各分组并生成一个新值,然后函数执行结果被合并到最终的结果对象中。下面我们看一下groupby()方法的基本用法。
import numpy as np
import pandas as pd
df = pd.DataFrame({'A':['a', 'b', 'a', 'b', 'a', 'b', 'a', 'a'],
'B':['c', 'c', 'd', 'e', 'b', 'b', 'a', 'c'],
'C':np.random.randn(8),
'D':np.random.randn(8)})
print(df)
print("---------------")
# groupby()返回结果是一个groupby对象,是一个中间数据,没有进行计算
print(df.groupby('A'))
print("---------------")
print(df.groupby('A').mean())运行结果如下图所示。注意,groupby()方法的返回结果只是一个groupby对象,是一个中间数据,只有进行计算后的结果才会生成一个新的DataFrame。上述代码中对列A进行分组,A中共有a、b两个值,所以会被分成两组,进行求平均值计算,而列B是字符数据,所以会自动过滤,对列C和列D进行分组后的计算。
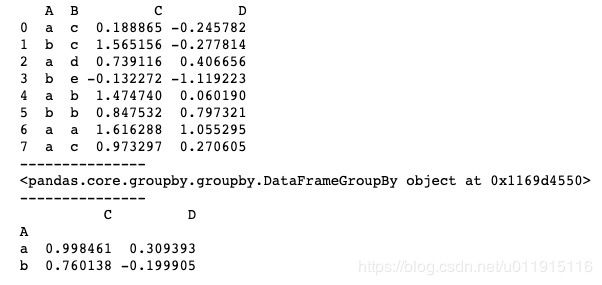
groupby()也支持多个参考分组,使用“[]”,基本用法如下。
import numpy as np
import pandas as pd
df = pd.DataFrame({'A':['a', 'b', 'a', 'b', 'a', 'b', 'a', 'a'],
'B':['c', 'c', 'd', 'e', 'b', 'b', 'a', 'c'],
'C':np.random.randn(8),
'D':np.random.randn(8)})
print(df)
print("---------------")
print(df.groupby(['A', 'B']).mean())上述代码中我们同时以“A”、“B”为参考进行分组,依次有“a c”、“b c”、“a d”、“b e”、“a b”、“b b”、“a a”、“a c”八个组合,分组后会将重复的组合合并计算,并自动进行排序。运行结果如下图所示。
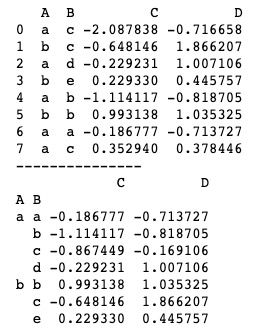
此外,我们还可以对分组后的结果进行指定序列计算。例如,我们以“A”为参考进行分组,然后只想得到对列“C”的运算结果,就可以使用groupby('A')['C']这样的方式实现。基本用法如下。
import numpy as np
import pandas as pd
df = pd.DataFrame({'A':['a', 'b', 'a', 'b', 'a', 'b', 'a', 'a'],
'B':['c', 'c', 'd', 'e', 'b', 'b', 'a', 'c'],
'C':np.random.randn(8),
'D':np.random.randn(8)})
print(df)
print("---------------")
# 以A分组求C的平均值
print(df.groupby('A')['C'].mean())
print("---------------")
print(df.groupby('A').mean())运行结果如下图所示。当我们使用groupby('A')['C']时,只得到了列C的运算结果。
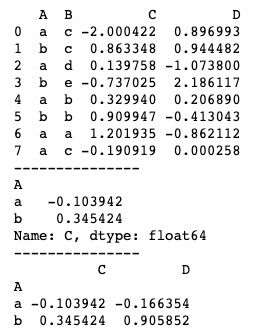
groupby()方法的返回结果虽然是一个groupby对象,但我们可以通过将它转换成列表得到一个可迭代的对象。
import numpy as np
import pandas as pd
df = pd.DataFrame({'A':['a', 'b', 'a', 'b'],
'B':[1, 2, 4, 3]})
print(df)
print("---------------")
# 生成可迭代的元组列表list
print(list(df.groupby('A')))
print("---------------")
list_df = list(df.groupby('A'))
print(list_df[0])
print("---------------")
# n是组名 df是分组后的DataFrame
for n, df in list_df:
print(n)
print("#####")
print(df)
print("---------------")我们将groupby对象转换成列表后进行遍历,可以看到,列表的每个元素都是一个元组,其中第一个元素是分组后的组名,第二个元素是分组后的DataFrame,运行结果如下图所示。

通过上述的操作我们知道groupby对象其实是可迭代的,所以我们可以提取分组后的DataFrame。pandas中为我们提供了两个方法:get_group()和groups。
首先看一下get_group(),传入要提取的组名即可。基本用法如下。
import numpy as np
import pandas as pd
df = pd.DataFrame({'A':['a', 'b', 'a', 'b'],
'B':[1, 2, 4, 3]})
print(df)
print("---------------")
list_df = df.groupby('A')
print(list_df.size())
print("---------------")
print(list_df.get_group('a'))
print("---------------")
print(list_df.get_group('b'))运行结果如下图所示。

groups是将分组后的groups转成字典,要注意的是,字典的value部分是原DataFrame的索引,即对应的分组组名所在的索引值。基本用法如下。
import numpy as np
import pandas as pd
df = pd.DataFrame({'A':['a', 'b', 'a', 'b'],
'B':[1, 2, 4, 3]})
print(df)
print("---------------")
list_df = df.groupby('A')
# 将分组后的groups转成字典
print(list_df.groups)
print("---------------")
print(list_df.groups['a'])运行结果如下图所示。

对于多个参考分组后的groupby对象,get_group()方法与groups同样适用,用法也基本一致。
import numpy as np
import pandas as pd
df = pd.DataFrame({'A':['a', 'b', 'a', 'b', 'a', 'b', 'a', 'a'],
'B':['c', 'c', 'd', 'e', 'b', 'b', 'a', 'c'],
'C':np.random.randn(8),
'D':np.random.randn(8)})
print(df)
print("---------------")
list_df = df.groupby(['A', 'B'])
print(list_df.groups)
print("---------------")
print(list_df.get_group(('a', 'c')))运行结果如下图所示。

groupby()方法除了可以对行或列分组外,还可以进行其他性质的分组。
如果一个DataFrame中的数据包含多种类型,我们可以根据数据类型对这个DataFrame进行分组。我们生成一个既有浮点型又有字符串型的DataFrame,看一下groupby()方法根据类型分组的基本用法。
import numpy as np
import pandas as pd
df = pd.DataFrame({'A':['a', 'b', 'a', 'b', 'a', 'b', 'a', 'a'],
'B':['c', 'c', 'd', 'e', 'b', 'b', 'a', 'c'],
'C':np.random.randn(8),
'D':np.random.randn(8)})
print(df)
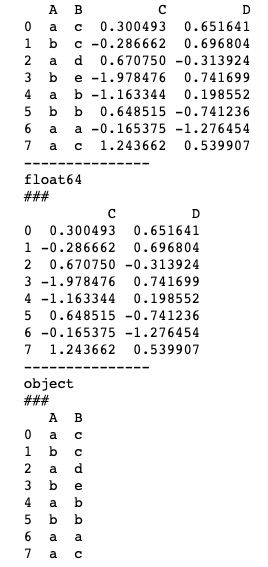
df_group = df.groupby(df.dtypes, axis=1)
for n, df in df_group:
print("---------------")
print(n)
print("###")
print(df)运行结果如下图所示。遍历分组后的groupby分组,可以看到,原DataFrame被分成了两组,一组float64(浮点型数据),一组object(字符串数据)。
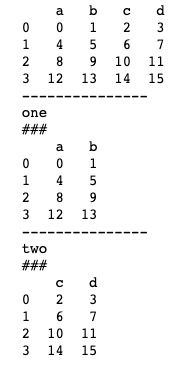
groupby()方法也支持通过字典dict或Series进行分组。我们首先看一下通过字典进行分组,基本用法如下。
import numpy as np
import pandas as pd
df = pd.DataFrame(np.arange(16).reshape(4, 4),
columns=list('abcd'))
print(df)
mapping = {'a':'one', 'b':'one', 'c':'two', 'd':'two'}
by_column = df.groupby(mapping, axis=1)
for n, df in by_column:
print("---------------")
print(n)
print("###")
print(df)通过字典dict进行分组,我们可以按自己的意愿对DataFrame进行分组。上述代码中我们将a、b分到'one'组,将c、d分到'two'。 运行结果如下图所示。
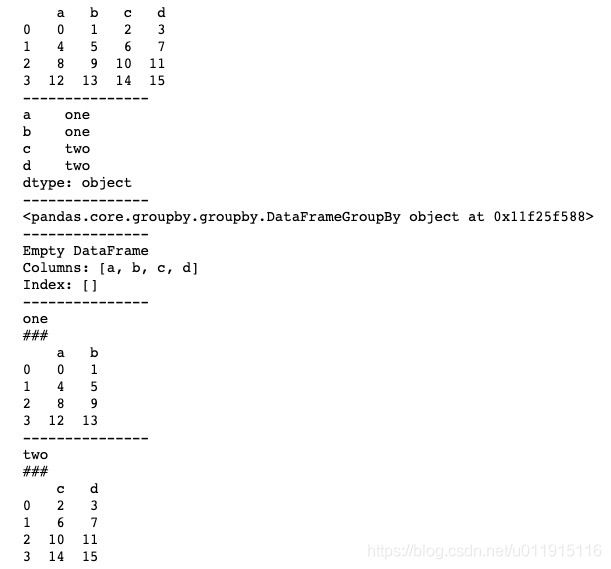
下面我们看一下groupby()方法通过Series进行分组的基本用法。其实通过Series进行分组与通过字典dict进行分组效果是一样的,Series其实就是对字典dict进行了一个包装而已。
import numpy as np
import pandas as pd
df = pd.DataFrame(np.arange(16).reshape(4, 4),
columns=list('abcd'))
print(df)
print("---------------")
mapping = {'a':'one', 'b':'one', 'c':'two', 'd':'two'}
s = pd.Series(mapping)
print(s)
by_series = df.groupby(s, axis=0)
print("---------------")
print(by_series)
print("---------------")
print(df.groupby(s, axis=0).count())
by_series_column = df.groupby(s, axis=1)
for n, df in by_series_column:
print("---------------")
print(n)
print("###")
print(df)上述代码中,我们尝试对行进行分组(即当groupby()方法的参数axis=0时)。我们发现,进行行分组后的DataFrame只包含了列索引a、b、c、d,却没有符合分组条件的数据,因为原DataFrame中的行索引是默认的0、1、2、3,用给定的Series进行分组显然是无效的。事实上,我们使用groupby()方法通过字典dict或Series进行分组时,往往是对列进行分组的。运行结果若下图所示。
此外,我们使用groupby()方法时也可以通过函数进行分组。基本用法如下。
import numpy as np
import pandas as pd
df = pd.DataFrame(np.arange(16).reshape(4, 4),
columns=list('abcd'),
index=['abc', 'bcd', 'aa', 'b'])
print(df)
print("---------------")
# 按照字母长度分组
print(df.groupby(len).sum())上述代码中,我们使用sum()函数指明groupby()方法按照字母长度进行分组。abc、bcd的字母长度为3,所以分到同一组,对应数据进行求和。运行结果如下图所示。

groupby()方法可以通过使用agg()方法的多函数计算来得到分组后数据的多个计算结果。例如我们想要同时得到分组后数据的求和以及求均值的结果,就可以使用groupby()方法的多函数计算来实现。基本用法如下。
import numpy as np
import pandas as pd
df = pd.DataFrame({'a':[1, 1, 2, 2],
'b':np.random.rand(4),
'c':np.random.rand(4),
'd':np.random.rand(4)})
print(df)
print("---------------")
print(df.groupby('a').agg(['mean', np.sum]))上述代码中,我们将mean()函数和sum()函数包装成列表传值给agg()方法,函数可以写成字符串或使用“np.”的形式。运行结果如下图所示,可以看到,最终得到了mean、sum两个结果。
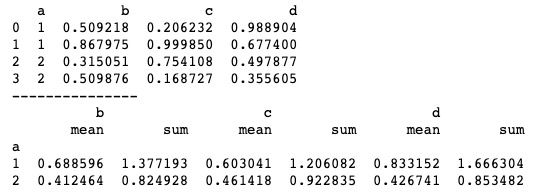
agg()方法包装多个函数除了支持list包装外,也支持字典dict包装。当使用字典dict包装时,dict的key值就是分组计算后的列索引值。基本用法如下。
import numpy as np
import pandas as pd
df = pd.DataFrame({'a':[1, 1, 2, 2],
'b':np.random.rand(4),
'c':np.random.rand(4),
'd':np.random.rand(4)})
print(df)
print("---------------")
print(df.groupby('a')['b'].agg({'result1':np.mean,
'result2':np.sum}))不过使用字典dict包装的方法在python3.6以后已经过时了,所以在运行代码时可能会出现相关警告。运行结果如下图所示。
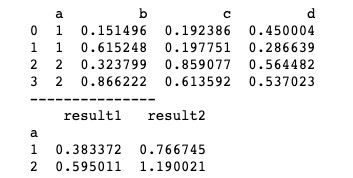
我们知道,DataFrame经过groupby()方法分组后可以进行函数运算,例如我们可以将一个DataFrame分组后求平均值。代码如下。
import numpy as np
import pandas as pd
df = pd.DataFrame({'data1': np.random.rand(5),
'data2': np.random.rand(5),
'key1': list('aabba'),
'key2': ['one', 'two', 'one', 'two', 'one']})
print(df)
print("---------------")
k_mean = df.groupby('key1').mean()
print(k_mean)
print("---------------")
print(pd.merge(df, k_mean, left_on='key1', right_index=True))上述代码中,我们将DataFrame按索引key1分组后调用mean()方法求均值,并将结果与原DataFrame聚合后生成一个新的DataFrame。运行结果如下图所示。
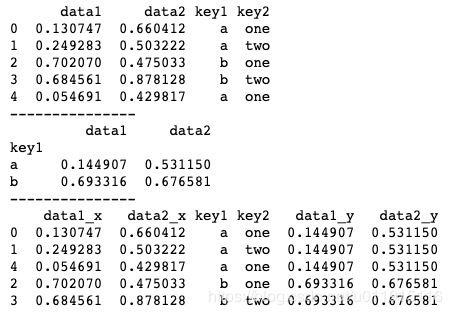
对于分组后的运算,除了直接在分组后调运算函数外,pandas还提供了其他方法来实现分组后的运算,transform()方法就是其中一个。transform()方法可以接收函数,对分组结果进行相应的函数操作。我们可以使用transform()方法实现上述需求。具体代码如下。
import numpy as np
import pandas as pd
df = pd.DataFrame({'data1': np.random.rand(5),
'data2': np.random.rand(5),
'key1': list('aabba'),
'key2': ['one', 'two', 'one', 'two', 'one']})
print(df)
print("---------------")
k_mean = df.groupby('key1').mean()
print(k_mean)
print("---------------")
print(df.groupby('key1').transform(np.mean))
print("---------------")
k_transform = df.groupby('key1').transform(np.mean)
print(pd.merge(df, k_transform, left_index=True, right_index=True))我们将DataFrame按索引key1分组后调用transform()方法,传入求均值函数np.mean,可以得到一个和原DataFrame结构一样的DataFrame。运行结果如下图所示,可以看到,利用transfrom()方法同样可以实现分组后的计算,并且相比于分组后直接调用运算函数,transfrom()方法还能够得到与原DataFrame结构一样的DataFrame。

transform()方法还支持传入自定义函数。例如现在我们需要对分组后的结果进行去均值操作(即对每个数据进行减去均值的操作),我们可以自定义一个去均值函数,然后传入transform()方法实现需求。具体代码如下。
import numpy as np
import pandas as pd
df = pd.DataFrame({'data1': np.random.rand(5),
'data2': np.random.rand(5),
'key1': list('aabba'),
'key2': ['one', 'two', 'one', 'two', 'one']})
print(df)
print("---------------")
print(df.groupby('key1').transform(np.mean))
print("---------------")
func = lambda arr:arr-arr.mean()
k_transform = df.groupby('key1').transform(func)
print(pd.merge(df, k_transform, left_index=True, right_index=True))运行结果如下图所示。为了便于观察,我们打印了均值结果,可以看到,data1_y和data2_y两列分组后的运算结果为去均值结果。
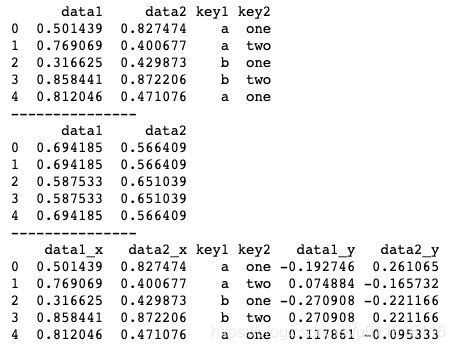
除了transform()方法,pandas中具有类似功能的还有apply()方法。apply()方法被称为一般化groupby方法,它可以直接运行其中的函数,并将分组结果作为传入函数的参数传递给函数,然后尝试将函数的返回结果组合起来。apply()方法的基本用法如下。
import numpy as np
import pandas as pd
df = pd.DataFrame({'data1': np.random.rand(5),
'data2': np.random.rand(5),
'key1': list('aabba'),
'key2': ['one', 'two', 'one', 'two', 'one']})
print(df)
print("---------------")
print(df.groupby('key1').apply(lambda x:x.describe()))上述代码中,我们将一个匿名函数传入apply()方法,这个匿名函数的作用是接收一个数组参数,并返回统计量。apply()方法会直接将groupby()方法的分组结果作为参数传递给这个匿名函数,从而实现对分组结果的相应处理。运行结果如下图所示。
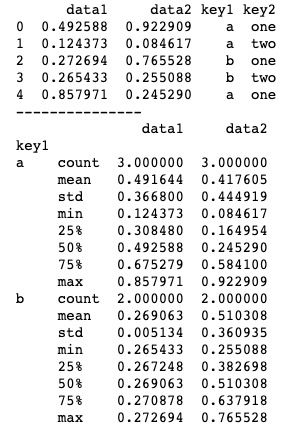
当然,除了匿名函数,我们也可以定义一些复杂函数,接收多参数来处理分组结果。
import numpy as np
import pandas as pd
# 返回排序后的前n行数据
def func1(d, n):
return d.sort_index()[:n]
# 返回分组后表的索引为k的列,结果为Series 层次化索引
def func2(d, k):
return d[k]
df = pd.DataFrame({'data1': np.random.rand(5),
'data2': np.random.rand(5),
'key1': list('aabba'),
'key2': ['one', 'two', 'one', 'two', 'one']})
print(df)
print("---------------")
print(df.groupby('key1').apply(func1, 2))
print("---------------")
print(df.groupby('key1').apply(func2, "data2"))上述代码中,我们定义了两个函数,功能分别为返回分组数据排序后的前n行数据、返回分组后索引为k的列数据。apply()方法的第一个参数接收函数名,后面的参数传入的则是接收函数所需的参数(apply()方法会将分组结果作为参数d直接传给func1和func2,故不需要再显示传入)。运行结果如下图所示。

pandas中的透视表与交叉表
数据透视表就是将数据的每一列作为输入,输出将数据不断细分成多个维度累计信息的二维数据表。简单来说,数据透视表更像是一种多维的groupb累计操作。pandas中使用pivot_table()方法来生成透视表,基本用法如下。
import numpy as np
import pandas as pd
date_range = pd.to_datetime(['2019-5-29', '2019-5-30', '2019-5-31']*3)
df = pd.DataFrame({'date':date_range,
'key': list('abcdabcdb'),
'values':np.random.rand(9)*10})
print(df)
print("---------------")
print(pd.pivot_table(df, values='values', index='date', columns='key', aggfunc=np.sum))pivot_table()方法接收一个DataFrame对象 ,values表示要聚合的列;index表示从原数据中筛选出列作为数据透视表中的index索引;columns表示从原数据中筛选出列作为数据透视表中的columns索引;aggfunc表示用于聚合的函数(支持Numpy计算函数),默认为np.mean,可以用字符串或“np.”两种形式表示。运行结果如下图所示。
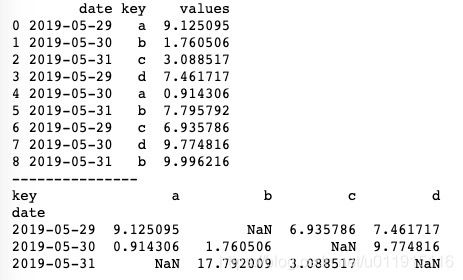
上述代码生成的数据透视表中有缺失值, pivot_table()方法对缺失值的处理默认以NaN填充。如果我们不想使用NaN,我们也可以通过设置fill_value来指定任意值作为缺失值的填充,基本用法如下。
import numpy as np
import pandas as pd
date_range = pd.to_datetime(['2019-5-29', '2019-5-30', '2019-5-31']*3)
df = pd.DataFrame({'date':date_range,
'key': list('abcdabcdb'),
'values':np.random.rand(9)*10})
print(df)
print("---------------")
print(pd.pivot_table(df, values='values', index='date', columns='key', aggfunc=np.sum, fill_value=0))再次运行可以发现,缺失值的地方填充值由原来的NaN变成了0。运行结果如下图所示。
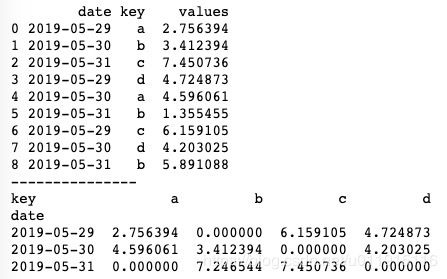
pivot_table()方法支持对多列数据同时做数据透视,我们只需给index传入一个包含多列索引的列表即可。例如上述代码中,我们给index参数传入['date', 'key'],pivot_table()方法就会对date列和key列共同做数据透视。代码如下。
import numpy as np
import pandas as pd
date_range = pd.to_datetime(['2019-5-29', '2019-5-30', '2019-5-31']*3)
df = pd.DataFrame({'date':date_range,
'key': list('abcdabcdb'),
'values':np.random.rand(9)*10})
print(df)
print("---------------")
print(pd.pivot_table(df, values='values', index=['date', 'key'], aggfunc=len))运行结果如下图所示。我们使用len作为聚合函数,由于原DataFrame中2019-5-31对应b有两组数据,所以返回长度为2。
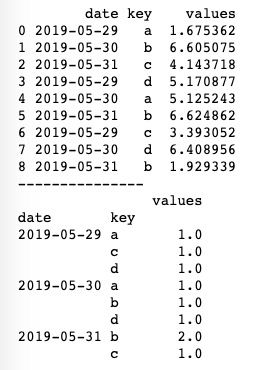
交叉表是一种常用的分类汇总表格,利用交叉表查询数据非常直观明了。pandas中使用crosstab()方法来生成交叉表,crosstab()方法一般用于计算因子的频率,可以对字符串类型的数据进行透视分析,基本用法如下。
import numpy as np
import pandas as pd
df = pd.DataFrame({'A':[1, 2, 2, 2, 2],
'B':['a', 'a', 'b', 'b', 'b'],
'C':[10, 10, np.nan, 10, 10]})
print(df)
print("---------------")
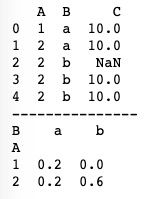
print(pd.crosstab(df['A'], df['B']))crosstab()方法如果只接收两个Series,那么会生成一个频率表。上述代码中传入了df['A']、df['B'],那么生成的频率表就是用A的唯一值去统计b的唯一值出现的次数。运行结果如下图所示,1对应‘a’出现的次数为1,2对应‘a’出现的次数为1,2对应‘b’出现的次数为3。

既然是频率表,我们往往希望看到的是占比情况,这时只需设置crosstab()方法中的normalize参数即可。基本用法如下。
import numpy as np
import pandas as pd
df = pd.DataFrame({'A':[1, 2, 2, 2, 2],
'B':['a', 'a', 'b', 'b', 'b'],
'C':[10, 10, np.nan, 10, 10]})
print(df)
print("---------------")
print(pd.crosstab(df['A'], df['B'], normalize=True))normalize参数默认为False,当我们设置normalize=True时,频率表中的所有值就会除以总和来进行归一化(计算占比)。运行结果如下图所示。
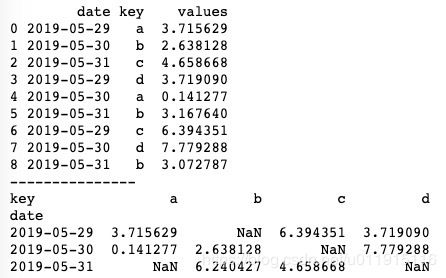
crosstab()方法中有两个参数:values和aggfunc,这两个参数跟生成透视表方法pivot_table()中的参数一样。事实上,crosstab()方法配合values和aggfunc这两个参数也能生成透视表。基本用法如下。
import numpy as np
import pandas as pd
date_range = pd.to_datetime(['2019-5-29', '2019-5-30', '2019-5-31']*3)
df = pd.DataFrame({'date':date_range,
'key': list('abcdabcdb'),
'values':np.random.rand(9)*10})
print(df)
print("---------------")
print(pd.crosstab(df['date'], df['key'], values=df['values'], aggfunc=np.sum))传入的前两个Series会分别作为透视表的index和columns索引,values为要聚合的列,运行结果如下图所示,可以看到,跟pivot_table()生成的透视表安全一样。
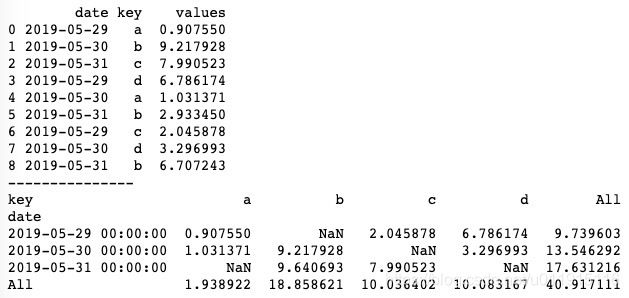
crosstab()方法可以通过设置margins参数给生成的表添加行/列边距,基本用法如下。
import numpy as np
import pandas as pd
date_range = pd.to_datetime(['2019-5-29', '2019-5-30', '2019-5-31']*3)
df = pd.DataFrame({'date':date_range,
'key': list('abcdabcdb'),
'values':np.random.rand(9)*10})
print(df)
print("---------------")
print(pd.crosstab(df['date'], df['key'], values=df['values'], aggfunc=np.sum, margins=True))margins参数默认为False,当我们设置margins=True时,会在生成的表上添加行/列,用于计算各行各列的和。运行结果如下图所示。
透视表pivot_table()方法是一种进行分组统计的函数,参数aggfunc决定统计类型;而交叉表crosstab()方法是一种特殊的pivot_table()方法,虽然也可以生成透视表,但我们一般将它专用于计算分组频率。