2019独角兽企业重金招聘Python工程师标准>>> 
Jsoup
Jsoup简介
1. Jsoup来自官方的释义:是一款Java的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
2. Externallinks:
① Jsoup官网:http://jsoup.org/ ② Github地址:https://github.com/jhy/jsoup ③ jar包及API下载:https://jsoup.org/download
3. 作者介绍: Jonathan HedleyWeb scale工程师、Technology Leader。 美国亚马逊公司技术主管、location位于美国华盛顿州,西雅图。 Jonathan Hedley的个人站主页:https://jhy.io/
4. 许可状态:
Jsoup基于MIT许可协议(The MIT License)发布、遵循MIT协议可用于商业使用。
5. 由Jsoup提供技术支持的项目:
Hibernate Validator Engine、google的OpenRefine data-wrangling tool等
6. 最新release版本: https://jsoup.org/download
jsoup release1.11.3 maven 坐标
org.jsoup
jsoup
1.11.3
官方示例
1.介绍
1. 解析和遍历文档
要解析HTML文档:
String html =
"First parse "
+ "Parsed HTML into a doc.
";
Document doc = Jsoup.parse(html);
(有关详细信息,请参阅从字符串中解析文档。)
无论HTML是否格式正确,解析器都会尝试从您提供的HTML中创建一个干净的解析。它处理:
-
未封闭的标签(例如
Lorem
Ipsum
Lorem
Ipsum
-
隐式标签(例如裸体
Table data ...) 可靠地创建文档结构(
html含有head和body,只有适当的头部内的元件)文档的对象模型
文档由Elements和TextNodes(以及其他几个misc节点组成:请参阅节点包树)。
继承链是:
DocumentextendsElementextendsNode。TextNode延伸Node。元素包含子节点列表,并具有一个父元素。它们还仅提供子元素的筛选列表。
2.输入
2.1. 从String解析文档
问题
您在Java String中有HTML,并且您希望解析该HTML以获取其内容,或确保其格式正确或修改它。字符串可能来自用户输入,文件或来自Web。 解析
使用静态
Jsoup.parse(String html)方法,或者Jsoup.parse(String html, String baseUri)如果页面来自Web,并且您希望获得绝对URL(请参阅[working-with-urls])。String html = "First parse " + "Parsed HTML into a doc.
"; Document doc = Jsoup.parse(html);IDEA 实例:
@Test public void Demo01() { String html = "First parse " + "Parsed HTML into a doc.
"; //该parse(String html, String baseUri)方法将输入HTML解析为新的Document Document doc = Jsoup.parse(html); System.out.println(doc); }结果:
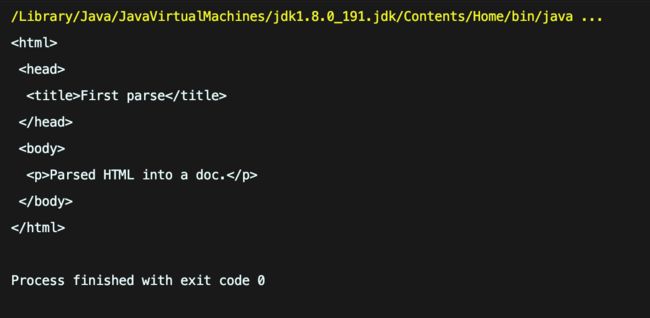
描述
该
parse(String html, String baseUri)方法将输入HTML解析为新的Document。该base URI参数用于将相对URL解析为绝对URL,并应设置为从中获取文档的URL。如果这不适用,或者您知道HTML有base元素,则可以使用该parse(String html)方法。只要传入一个非空字符串,就可以保证有一个成功的,合理的解析,一个包含(至少)a
head和一个body元素的Document .(BETA:如果你确实收到了异常,或者是一个糟糕的解析树,请提交一个错误。)获得Document后,您可以使用Document及其supers
Element和中的相应方法获取数据Node。2.2. 解析一个body
问题
您有一个要解析的正文HTML片段(例如,
div包含几个p标记;而不是完整的HTML文档).也许它是由用户提交评论或在CMS中编辑页面正文提供的。解析
使用该
Jsoup.parseBodyFragment(String html)方法。``` String html = "Lorem ipsum.
"; Document doc = Jsoup.parseBodyFragment(html); Element body = doc.body(); ```IDEA 实例:
@Test public void Demo02() { String html = "Lorem ipsum.
"; Document doc = Jsoup.parseBodyFragment(html); Element body = doc.body(); System.out.println(body); }结果:

描述
该
parseBodyFragment方法创建一个空shell文档,并将解析后的HTML插入该body元素中。如果您使用普通Jsoup.parse(String html)方法,通常会得到相同的结果,但明确将输入视为正文片段可确保将用户提供的任何bozo HTML解析为body元素。该
Document.body()方法检索文档body元素的元素子元素; 它相当于doc.getElementsByTag("body")。注意
如果要接受用户的HTML输入,则需要小心避免跨站点脚本攻击。请参阅
Whitelist基于清洁器的文档,并使用清洁输入clean(String bodyHtml, Whitelist whitelist)。2.3. 从URL加载文档
问题
您需要从Web获取并解析HTML文档,并在其中查找数据(屏幕抓取)。
解析
使用
Jsoup.connect(String url)方法:Document doc = Jsoup.connect("https://jsoup.org/").get(); String title = doc.title();IDEA 实例:
@Test public void Demo03() throws IOException { //请求jsoup主页并获取到网页的标题 Document doc = Jsoup.connect("https://jsoup.org").get(); String title = doc.title(); System.out.println("获取jsoup页面的标题:" + title); }结果:
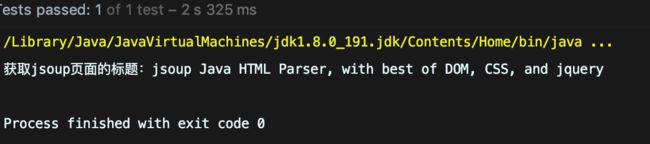
描述
该
connect(String url)方法创建一个新的Connection,并get()提取和解析HTML文件。如果在获取URL时发生错误,它将抛出一个IOException,您应该适当处理。该
Connection接口设计用于方法链接以构建特定请求://您可以添加数据,Cookie和标头; 设置user-agent,referrer,method; 然后执行。 Document doc = Jsoup.connect("https://jsoup.org") .data("query", "Java") .userAgent("Mozilla") .cookie("auth", "token") .timeout(3000) .post();此方法仅支持Web URL(
http和https协议); 如果需要从文件加载,请改用该parse(File in, String charsetName)方法。2.4. 从文件加载文档
问题
磁盘上有一个包含HTML的文件,您要加载和解析,然后可以操作或提取数据。
解析
使用静态
Jsoup.parse(File in, String charsetName, String baseUri)方法:File input = new File("/tmp/input.html"); Document doc = Jsoup.parse(input, "UTF-8", "http://example.com/");描述
该
parse(File in, String charsetName, String baseUri)方法加载并解析HTML文件。如果在加载文件时发生错误,它将抛出一个IOException,你应该适当处理。baseUri解析器使用该参数在有一个姐妹方法
parse(File in, String charsetName)使用文件的位置作为baseUri。如果您正在处理文件系统本地站点并且它指向的相对链接也在文件系统上,这将非常有用。3.提取数据
3.1. 使用DOM方法
问题
您有一个要从中提取数据的HTML文档。您通常知道HTML文档的结构。
解析
在将HTML解析为a后,使用类似DOM的方法
Document。``` Document doc = Jsoup.connect("https://jsoup.org") Element content = doc.getElementById("content"); Elements links = content.getElementsByTag("a"); for (Element link : links) { String linkHref = link.attr("href"); String linkText = link.text(); } ```IDEA 实例:
@Test public void Demo05() throws IOException { //解析html Document doc = Jsoup.connect("https://jsoup.org").get(); //根据标签名查找 Elements links = doc.getElementsByTag("a"); for (Element link : links) { System.out.println("link-----------"+link); //获取和attr(String key, String value)设置属性 String linkHref = link.attr("href"); System.out.println("获取和attr(String key, String value)设置属性---"+linkHref); //获取和text(String value)设置文本内容 String linkText = link.text(); System.out.println("获取和text(String value)设置文本内容----"+linkText); } }结果:
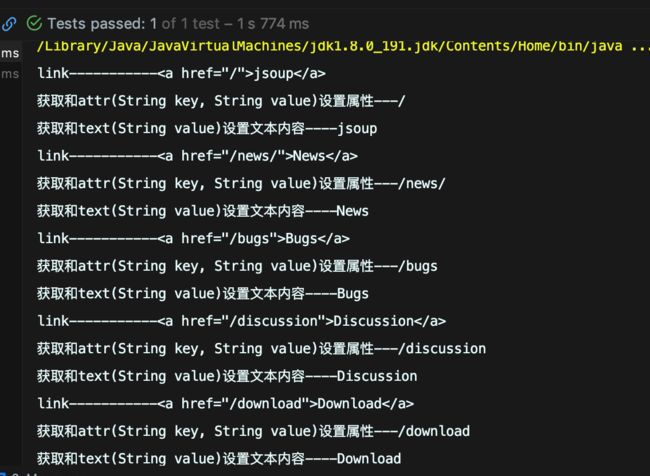
描述
元素提供了一系列类似DOM的方法来查找元素,并提取和操作它们的数据。DOM getter是上下文的:在父文档上调用它们在文档下找到匹配的元素; 他们在一个子元素上调用了那个孩子下面的元素。通过这种方式,您可以了解所需的数据。
寻找元素
- `getElementById(String id)` //根据ID 查询 - `getElementsByTag(String tag)` //根据标签名 - `getElementsByClass(String className)` //根据class 名 - `getElementsByAttribute(String key)` (及相关方法) - 元素的兄弟姐妹:`siblingElements()`,`firstElementSibling()`,`lastElementSibling()`,`nextElementSibling()`,`previousElementSibling()` - 图:`parent()`,`children()`,`child(int index)`元素数据
- `attr(String key)`获取和`attr(String key, String value)`设置属性 - `attributes()` 获得所有属性 - `id()`,`className()`和`classNames()` - `text()`获取和`text(String value)`设置文本内容 - `html()`获取和`html(String value)`设置内部HTML内容 - `outerHtml()` 获取外部HTML值 - `data()`获取数据内容(例如`script`和`style`标签) - `tag()` 和 `tagName()`处理HTML和文本
- `append(String html)`, `prepend(String html)` - `appendText(String text)`, `prependText(String text)` - `appendElement(String tagName)`, `prependElement(String tagName)` - `html(String value)`3.2. 使用selector-syntax查找元素
问题
您希望使用CSS或类似jquery的选择器语法来查找或操作元素。
解析
使用
Element.select(String selector)和Elements.select(String selector)方法:```java Document doc = Jsoup.connect("https://jsoup.org").get(); // 查询所有的a 标签 Elements links = doc.select("a[href]"); // 查询以.png结尾的src标签 Elements pngs = doc.select("img[src$=.png]"); // 查询以 div 与 class=masthead 的标签 Element masthead = doc.select("div.masthead").first(); // direct a after h3 Elements resultLinks = doc.select("h3.r > a"); ```IDEA 实例:
@Test public void Demo06() throws IOException { Document doc = Jsoup.connect("https://mall.littleswan.com/search?mtag=30058.1.1#nolink").get(); /// 获取所有的a 标签 Elements links = doc.select("a[href]"); // System.out.println(links); //获取所有img 标签 jpg 结尾的标签 Elements pngs = doc.select("img[src$=.jpg]"); System.out.println(pngs); // img with src ending .png //带有类的元素 Element masthead = doc.select("div.ft_message").first(); System.out.println(masthead); // div with class=masthead //在h3之后引导a // Elements resultLinks = doc.select("h3.r > a"); // System.out.println(resultLinks); }结果:
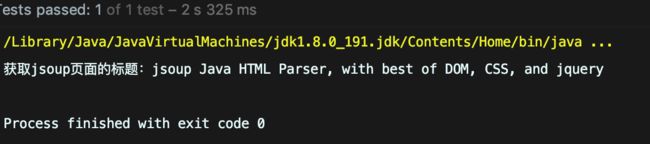
描述
jsoup元素支持[CSS](http://www.w3.org/TR/2009/PR-css3-selectors-20091215/)(或[jquery](http://jquery.com/))之类的选择器语法来查找匹配元素,从而允许非常强大和健壮的查询。 该`select`方法在一个可用`Document`,`Element`或在`Elements`。它是上下文的,因此您可以通过从特定元素中进行选择或通过链接选择调用来进行过滤。 Select返回一个Elements列表(as `Elements`),它提供了一系列提取和操作结果的方法。选择器概述
- `tagname`:按标签查找元素,例如 `a` - `ns|tag`:在命名空间中按标记`fb|name`查找`选择器组合
- `el#id`:具有ID的元素,例如 `div#logo` - `el.class`:带有类的元素,例如 `div.masthead` - `el[attr]`:具有属性的元素,例如 `a[href]` - 任何组合,例如 `a[href].highlight` - `ancestor child`:从祖先下降的子元素,例如在类“body”的块下的任何位置`.body p`查找`p`元素 - `parent > child`:直接从父级下降的子元素,例如`div.content > p`查找`p`元素; 并`body > *`找到body标签的直接子节点 - `siblingA + siblingB`:找到兄弟B元素之后紧接着兄弟A,例如 `div.head + div` - `siblingA ~ siblingX`:找到兄弟A前面的兄弟X元素,例如 `h1 ~ p` - `el, el, el`:对多个选择器进行分组,找到与任何选择器匹配的唯一元素; 例如`div.masthead, div.logo`伪选择器
- `:lt(n)`:找到其兄弟索引(即它在DOM树中相对于其父节点的位置)小于的元素`n`; 例如`td:lt(3)` - `:gt(n)`:查找兄弟索引大于的元素`n`; 例如`div p:gt(2)` - `:eq(n)`:查找兄弟索引等于的元素`n`; 例如`form input:eq(1)` - `:has(selector)`:查找包含与选择器匹配的元素的元素; 例如`div:has(p)` - `:not(selector)`:查找与选择器不匹配的元素; 例如`div:not(.logo)` - `:contains(text)`:查找包含给定文本的元素。搜索不区分大小写; 例如`p:contains(jsoup)` - `:containsOwn(text)`:查找直接包含给定文本的元素 - `:matches(regex)`:查找文本与指定正则表达式匹配的元素; 例如`div:matches((?i)login)` - `:matchesOwn(regex)`:查找自己的文本与指定正则表达式匹配的元素 - 注意,上面的索引伪选择器是基于0的,即第一个元素是索引0,第二个元素是1,等等 有关`Selector`完整支持的列表和详细信息,请参阅API参考。3.3. 从元素中提取属性,文本和HTML
问题
在解析文档并找到一些元素之后,您将需要获取这些元素中的数据。
解析
- 要获取属性的值,请使用该`Node.attr(String key)`方法 - 对于元素(及其组合子元素)上的文本,请使用 `Element.text()` - 对于HTML,使用`Element.html()`或`Node.outerHtml()`适当例如:
```java String html = "An example link.
"; Document doc = Jsoup.parse(html); Element link = doc.select("a").first(); // "An example link" String text = doc.body().text(); // "http://example.com/" String linkHref = link.attr("href"); // "example"" String linkText = link.text(); String linkOuterH = link.outerHtml(); // "example" String linkInnerH = link.html(); // "example" ```IDEA 实例:
@Test public void Demo07() { String html = "An " + "" + "example" + " link.
"; Document doc = Jsoup.parse(html); //获取到a标签 Element link = doc.select("a").first(); System.out.println("link----"+link); // "An example link" String text = doc.body().text(); System.out.println("text----"+text); // "http://example.com/" //获取到超链接 String linkHref = link.attr("href"); System.out.println("linkHref----"+linkHref); // "example"" //获取到文本 String linkText = link.text(); System.out.println("linkText----"+linkText); String linkOuterH = link.outerHtml(); System.out.println("linkOuterH----"+linkOuterH); // "example" // "example" String linkInnerH = link.html(); System.out.println("linkInnerH----"+linkInnerH); }结果:

描述
上述方法是元素数据访问方法的核心。还有其他人: - `Element.id()` - `Element.tagName()` - `Element.className()` 和 `Element.hasClass(String className)` 所有这些访问器方法都有相应的setter方法来更改数据。也可以看看
- 参考文档`Element`和集合`Elements`类 - [使用URL](https://jsoup.org/cookbook/extracting-data/working-with-urls) - [使用CSS选择器语法查找元素](https://jsoup.org/cookbook/extracting-data/selector-syntax)3.4. 使用URL
问题
您有一个包含相对URL的HTML文档,您需要将其解析为绝对URL。
解析
-
确保
base URI在解析文档时指定(在从URL加载时隐式),以及 -
使用
abs:属性前缀解析属性的绝对URL:Document doc = Jsoup.connect("http://jsoup.org").get(); Element link = doc.select("a").first(); String relHref = link.attr("href"); // == "/" String absHref = link.attr("abs:href"); // "http://jsoup.org/"
IDEA 实例:
@Test public void Demo08() throws IOException { Document doc = Jsoup.connect("http://jsoup.org").get(); //解析到第一个a标签 Element link = doc.select("a").first(); System.out.println(link); // == "/" String relHref = link.attr("href"); // "http://jsoup.org/" System.out.println(relHref); String absHref = link.attr("abs:href"); System.out.println(absHref); }结果:
描述
在HTML元素中,URL通常是相对于文档的位置编写的:`...`。当您使用该`Node.attr(String key)`方法获取href属性时,它将按照源HTML中的指定返回。 如果要获取绝对URL,则会有一个属性键前缀`abs:`,该前缀将导致根据文档的基URI(原始位置)解析属性值:`attr("abs:href")` 对于此用例,在解析文档时指定基URI非常重要。 如果您不想使用`abs:`前缀,还有一个方法`Node.absUrl(String key)`可以执行相同的操作,但可以通过自然属性键进行访问。3.5. 示例程序:列出链接
-
此示例程序演示了如何从URL获取页面; 提取链接,图像和其他指针; 并检查他们的URL和文本。
指定要获取的URL作为程序的唯一参数。
package org.jsoup.examples; import org.jsoup.Jsoup; import org.jsoup.helper.Validate; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; import java.io.IOException; /** * Example program to list links from a URL. */ public class ListLinks { public static void main(String[] args) throws IOException { Validate.isTrue(args.length == 1, "usage: supply url to fetch"); String url = args[0]; print("Fetching %s...", url); Document doc = Jsoup.connect(url).get(); Elements links = doc.select("a[href]"); Elements media = doc.select("[src]"); Elements imports = doc.select("link[href]"); print("\nMedia: (%d)", media.size()); for (Element src : media) { if (src.tagName().equals("img")) print(" * %s: <%s> %sx%s (%s)", src.tagName(), src.attr("abs:src"), src.attr("width"), src.attr("height"), trim(src.attr("alt"), 20)); else print(" * %s: <%s>", src.tagName(), src.attr("abs:src")); } print("\nImports: (%d)", imports.size()); for (Element link : imports) { print(" * %s <%s> (%s)", link.tagName(),link.attr("abs:href"), link.attr("rel")); } print("\nLinks: (%d)", links.size()); for (Element link : links) { print(" * a: <%s> (%s)", link.attr("abs:href"), trim(link.text(), 35)); } } private static void print(String msg, Object... args) { System.out.println(String.format(msg, args)); } private static String trim(String s, int width) { if (s.length() > width) return s.substring(0, width-1) + "."; else return s; } } org/jsoup/examples/ListLinks.java
示例输出(修剪)
```java Fetching http://news.ycombinator.com/... Media: (38) * img:4.修改数据
4.1. 设置属性值
问题
您有一个已解析的文档,您希望在将其保存到磁盘之前更新属性值,或者将其作为HTTP响应发送。
解析
使用属性setter方法
Element.attr(String key, String value),和Elements.attr(String key, String value)。如果需要修改
class元素的属性,请使用Element.addClass(String className)和Element.removeClass(String className)方法。该
Elements集合具有批量归属和类方法。例如,要为div中的rel="nofollow"每个a元素添加一个属性:doc.select("div.comments a").attr("rel", "nofollow");描述
与其他方法一样
Element,这些attr方法返回当前Element(或者Elements从select中处理集合时)。这允许方便的方法链接:doc.select("div.masthead").attr("title", "jsoup").addClass("round-box");4.2 修改元素的HTML
问题
您需要修改元素的HTML。
解析
使用HTML setter方法
Element:Element div = doc.select("div").first(); // div.html("lorem ipsum
"); //div.prepend("lorem ipsum
First
"); div.append("Last
"); // now:Element span = doc.select("span").first(); // One span.wrap("First
lorem ipsum
Last
- "); // now:
- One
讨论
- `Element.html(String html)` 清除元素中的任何现有内部HTML,并将其替换为已解析的HTML。 - `Element.prepend(String first)`并分别`Element.append(String last)`将HTML添加到元素内部HTML的开头或结尾 - `Element.wrap(String around)`围绕元素的**外部** HTML 包装HTML 。也可以看看
您还可以使用`Element.prependElement(String tag)`和`Element.appendElement(String tag)`方法创建新元素,并将它们作为子元素插入到文档流中。4.3. 设置元素的文本内容
问题
您需要修改HTML文档的文本内容。
解析
使用以下文本setter方法
Element:// 先查到需要更改的div Element div = doc.select("div").first(); //five > four//清除元素中的任何现有内部HTML,并将其替换为提供的文本。 div.text("five > four"); //添加文本节点到元素的内部HTML的开始 div.prepend("First "); //添加文本节点到元素的内部HTML的结束时 div.append(" Last"); // now:First five > four Last讨论 文本setter方法镜像HTML setter方法: -
Element.text(String text)清除元素中的任何现有内部HTML,并将其替换为提供的文本。 -Element.prepend(String first)和Element.append(String last)添加文本节点到元素的内部HTML的开始或结束时,分别 文本应提供未编码:喜欢文字<,>等会为文字,而不是HTML处理。5.清理HTML
5.1. 清理不受信任的HTML(以防止XSS)
问题
您希望允许不受信任的用户为您网站上的输出提供HTML(例如,作为评论提交)。您需要清理此HTML以避免跨站点脚本(XSS)攻击。
解析
将jsoup HTML
Cleaner与a指定的配置一起使用Whitelist。String unsafe = ""; String safe = Jsoup.clean(unsafe, Whitelist.basic()); // now:讨论
针对您网站的跨站点脚本攻击可能会毁了您的一天,更不用说您的用户了。许多站点通过不允许在用户提交的内容中使用HTML来避免XSS攻击:它们仅强制执行纯文本,或使用其他标记语法,如wiki-text或Markdown。这些对用户来说很少是最佳解决方案,因为它们会降低表现力,并迫使用户学习新语法。
更好的解决方案可能是使用富文本WYSIWYG编辑器(如CKEditor或TinyMCE)。这些输出HTML,并允许用户直观地工作。但是,它们的验证是在客户端完成的:您需要应用服务器端验证来清理输入并确保HTML可以安全地放置在您的站点上。否则,攻击者可以避免客户端Javascript验证并将不安全的HMTL直接注入您的站点
jsoup白名单清理程序通过解析输入HTML(在安全的沙盒环境中),然后遍历解析树并仅允许已知安全标记和属性(和值)进入清理后的输出来工作。
它不使用不适合此任务的正则表达式。
jsoup提供一系列
Whitelist配置以满足大多数要求; 如有必要,可以对它们进行修改,但请注意。清洁器是不仅用于避免XSS,而且在限制元件,用户可以提供的范围有用:您可以与文本行
a,strong元素,但不是结构性div或table元件。也可以看看
- 请参阅XSS备忘单和过滤规避指南,作为常规表达式过滤器不起作用的示例,以及为什么基于安全白名单解析器的消毒剂是正确的方法。
Cleaner如果要获取Document而不是返回String,请参阅参考- 请参阅
Whitelist不同固定选项的参考,以及创建自定义白名单 - 该nofollow的链接属性
转载于:https://my.oschina.net/ch66880/blog/3024993
你可能感兴趣的:(jsoup 入门祥细官方示例)