近期,Netfilter 和 Mellanox 联合开发了flowtable hardware offload 功能,使flowtable成为一种标准的conntrack卸载方案,并实现了Linux标准的Netfilter 硬件offload接口。作为一个新功能,还存在一些缺陷和不完善的地方。
对此,我们做了大量的硬件卸载开发工作,进行问题修复、功能优化,帮助完善kernel功能并提升性能,后续也计划将该功能合并至UCloud外网网关,进一步提升系统性能和管理能力。
优化后的性能飞跃
首先,来看一组简单粗暴的数据。
在所有硬件卸载开发工作完成后,我们基于flowtable的conntrack offload,从bps、pps、cpu使用率等维度分别进行了系列性能对比测试,测试结果如下:
- 非硬件卸载模式:
①单条流带宽测试为12GBps,耗费2个host CPU;
②多条流小包包量测试为1Mpps,耗费8个host CPU;
- 硬件卸载模式:
①单条流带宽测试为23GBps,耗费 0 host CPU;
②多条流小包包量测试为8Mpps,耗费 0 host CPU;
可以看到在硬件卸载模式下bps、pps性能提升显著,不仅做到了CPU无损耗,性能还分别提升1倍、8倍之多。不过对于新建连接率cps并没有太显著的提升,分析原因为该性能由conntrack在软件协议栈中完成,与硬件无关。在已有层面,一旦该特性应用于产品上,预估将带来极大的性能飞跃。
当然,性能提升的背后离不开每一个细微技术的打磨:我们对conntrack offload与NAT功能分别进行了问题修复与优化,并在此基础上,还与Netfilter、Mellanox合作开发了tunnel offload的新特性。 接下来,就来详细聊聊我们所做的工作。
Flowtable offload背景简介
Linux内核在版本4.16引入了flow offload功能,它为IP forward提供了基于流的卸载功能。当一条新建连接完成首回合原方向和反方向的报文时,完成路由,Firewall和NAT工作后,在处理反方向首报文的forward hook,根据报文路由、NAT等信息创建可卸载flow到接收网卡ingress hook上。后续的报文可以在接收ingress hook上直接转发,不需要再进入IP stack处理。 这种模式实现了完成建立连接的conntrack软件offload,不过目前flowtable offload只支持TCP和UDP协议的卸载。
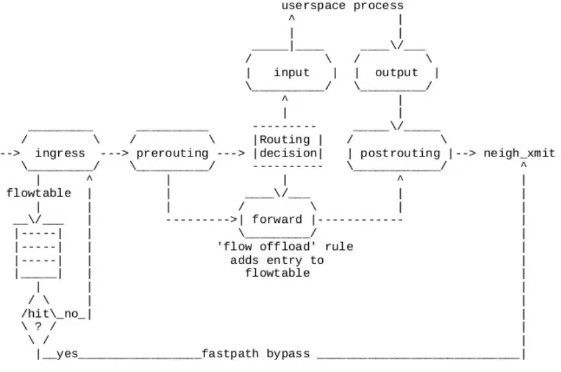
图:Flowtable offload图示
当前内核中硬件支持offload的标准只有Network TC subsystem的tc flower接口。
_Pablo Neira Ayuso_首先将tc flower相应的offload接口进行公共化为network子系统flow offload,然后在flowtable offload中支持HW的flow offload接口。这样便可在驱动层面上完全统一使用flow offload接口。
_Paul Blakey_将flowtable offload指定到TC_SETUP_FT域,实现在驱动层来区分不同的subsystem。
在所有基本功能完善后,我们在review commit的代码后发现flowtable HW offload的建立并没有指定到正确的TC_SETUP_FT类型。对此,我们进行了简单的修复,并将patch提交至社区:
① Netfilter:nf_flow_table_offload:Fix block setup as TC_SETUP_FT cmd(https://git.kernel.org/pub/sc...)
②Netfilter:nf_flow_table_offload:Fix block_cb tc_setup_type as TC_SETUP_CLSFLOWER(https://git.kernel.org/pub/sc...)
Conntrack offload测试优化实践
接着,我们对conntrack offload卸载功能进行了实操测试,发现其中存在部分卸载规则问题,对其进行了修复优化。
| 测试复现
创建一台虚拟机,配置虚拟机地址为10.0.0.75。host创建user1的vrf,将虚拟机对应的VF representor mlx_pf0vf0以及PF mlx_p0加入到user vrf。PF对端连接物理机地址为10.0.1.241。Host作为虚拟机和对端物理机之间的虚拟机路由器。

创建firewall规则,允许访问虚拟机的icmp和tcp 5001端口,并且把VFrepresentor port和PF port加入到flowtable做offload。
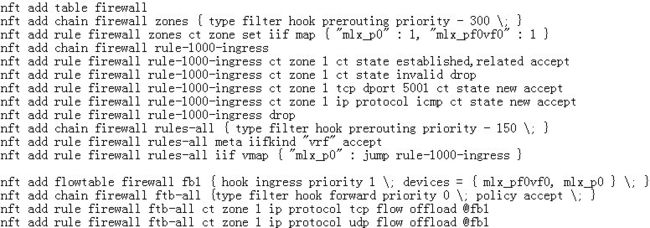
开启netperf测试,10.0.1.241访问10.0.0.75:5001。发现连接能成功建立,但是后续带宽跑不上来。
| 问题定位
在Host上的确抓不到相应的报文,说明卸载成功,并且在虚拟机中抓包发现收报文的收到和回复的报文都是正确的。但是在对端物理机上抓包却发现dst_mac全为0。 我们猜测应该是卸载规则出现了问题,为验证结论,我们查看相关源码并进行分析:

通过源码可以发现dst_neigh正确获取,但是由于dst_neigh_lookup会为没有neighbor项的地址创建一个新的neighbor,导致值为0。(由于整个测试环境刚部署好,没有进行过任何通信,所以两端的neighbor是没有的)
仔细分析下offload规则下发的时机,第一个original方向的SYN报文从10.0.1.241->10.0.0.75:5001通过协议栈能转入到虚拟机,虚拟机发出reply方向的SYN+ACK报文10.0.0.75:5001->10.0.1.241,同时在Host的netfilter forward表会建立offload规则下发给硬件。这时链接两个方向的报文都进行了鉴权,conntrack项也变成established,形成完整的转发规则。
但是reply方向的ip_dst 10.0.1.241的neighbor还是没有,原因在于协议栈上的报文还没真正发送触发arp流程。
针对上诉分析,由于flowtable offload并不支持icmp协议,我们先进行了ping探测让两端的neighbor项建立成功,然后再继续测试。此时发现,正式化硬件offload可以正常的工作。
| 提交patch:
针对conntrack offload 中neighbor无效导致卸载错误的情况,我们提交patch进行了修复。简单总结为:在获得无效neighbor的时候先不进行卸载:
Netfilter: nf_flow_table_offload: checkthe status of dst_neigh(https://git.kernel.org/pub/sc...)
NAT功能测试优化实践
接着,我们继续对flowtableoffload中NAT功能项进行了实操测试,对部分卸载规则问题进行了优化改善。
| 测试复现:
创建一台虚拟机,配置虚拟机地址为10.0.0.75,具有外部地址2.2.2.11。host创建user1的vrf,将虚拟机对应的VF representor mlx_pf0vf0以及PF mlx_p0加入到user vrf。PF对端连接物理机地址为1.1.1.7。Host就作为虚拟机和对端物理机之间的虚拟nat网关。
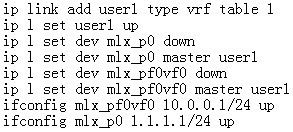
同样创建firewall规则,允许访问虚拟机的icmp和tcp 5001端口,并且把VFrepresentor port和PF port加入到flowtable做offload。
接着创建nat转发规则,dst ip address 2.2.2.11 dnat to 10.0.0.75, src ip address 10.0.0.75snat to 2.2.2.11。

开启netperf测试,1.1.1.7访问至2.2.2.11:5001。发现连接能成功建立,但是后续带宽值很低。
| 问题定位:
在Host上的确抓不到相应的报文,说明卸载成功,在虚拟机中抓包发现收报文的dst mac不正确,值同样也为0(测试代码没合入,无效neighbor的时候先不进行卸载的patch)。
由于original方向的SYN报文1.1.1.7访问2.2.2.11:5001转换成1.1.1.7到10.0.0.75:5001成功发送给了虚拟机,这时10.0.0.75对应的neighbor是存在的,不应该出现获取不到的情况。
我们猜测应该还是卸载规则出现了问题,查看源码进行分析:

通过源码可知,在NAT场景下original方向的tuple->dst_cache的device确实是mlx_pf0vf0,但是tuple->dst_v4却仍旧是原来的2.2.2.11,不是10.0.0.75。10.0.0.75应该通过remote_tuple->src_v4获取。
解决该问题后,我们再次开启netperf测试,1.1.1.7:32315访问2.2.2.11:5001。发现连接依然能成功建立,但是带宽还是跑不上来。
在虚拟机上抓包发现接收报文dst port异常为32315。即1.1.1.7: 32315到10.0.0.75: 32315。我们判断卸载规则仍存在其他问题,查看源码进行分析:
可以看到在DNAT场景下会将original方向的dst port改为reply方向的dstport即32315, 将reply方向的dst port改为original方向的source port。这个逻辑明显有误。

同样在SNAT下也存在类似的转换问题, 会将original方向的srcport改为reply方向的dst port, 将reply方向的src port改为original方向的source port。
举个例子,比如10.0.0.75:32200访问1.1.1.75:5001会将reply的报文改为1.1.1.75: 32200到2.2.2.11:32200。 所以NAT模式下的portmangle存在问题,正确的逻辑应该是:
- DNAT:
original方向的dst port应该改为reply方向的src port;
reply方向的src port应改为original 方向的dst port。
- SNAT:
Original方向的src port应该改为reply方向的dstprt;
Reply方向的dst port应该改为original方向的src port。
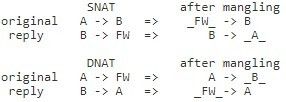
| 提交patch:
最终,针对NAT测试问题,我们也提交了相关patch进行修复:
① Netfilter: nf_flow_table_offload: fix incorrect ethernet dst address(https://git.kernel.org/pub/sc...)
② Netfilter: nf_flow_table_offload: fix the nat port mangle.(https://git.kernel.org/pub/sc...)
新特性开发:SDN网络下的Tunnel offload
我们发现flowtable hardware offload无法支持tunnel设备。对于SDN网络而言,tunnel是一项关键性的指标。 最终,我们从conntrack offload与NAT功能的优化修复过程中得到启发,在新思考的推动下,与 Netfilter 维护者Pablo NeiraAyuso 和 Mellanox 驱动工程师Paul Blakey通力合作,共同开发出了tunnel 卸载的新特性。
以下是开发细节的详细介绍。
1、在Flowtable上设置tunnel device实现卸载
在tc flower softwarefilter规则中, 所有的tunnel meta match、tunnel decap action均设置在tunnel device的ingress qdisc上,只有在tunnel device 接收入口才能获取meta信息。
因此tc flower offload模式下的卸载规则也会follow这个逻辑,下发到tunnel device上。但是tunnel device都是虚拟的逻辑device,需要找到lower hardware device进行设置卸载——即采用indirect block的方式来实现。
首先驱动程序注册监听tunnel创建的事件。当tunnel被创建,驱动会给对应tunnel device设置一个tc flower规则的callback。通过这种indirect block的方式来实现tunnel device与hardware device的关联。
| 提交patch:
我们先提交了series(http://patchwork.ozlabs.org/c... )——在flow offload 中支持indirect block方式,主要包括以下patch:
① cls_api:modify the tc_indr_block_ing_cmd parameters.
② cls_api:remove the tcf_block cache
③ cls_api:add flow_indr_block_call function
④ flow_offload:move tc indirect block to flow offload
⑤ flow_offload:support get multi-subsystem block
引入上面的series后,flowtable就能通过indirect block卸载tunnel device。
①Netfilter: flowtable: addnf_flow_table_block_offload_init()(https://git.kernel.org/pub/sc...)
②Netfilter: flowtable: addindr block setup support(https://git.kernel.org/pub/sc...)
2、Tunnel 信息匹配及Action 设计
完成第一步后,flowtable便可以成功的将卸载规则设置到tunnel device上,但是此时还存在一个问题:无法支持tunnel信息匹配以及decap、encap操作。
针对这一问题,首先我们想到Linux内核在4.3版本中引入的轻量级隧道Lightweight tunneling,它提供了通过route方式设置tunnel属性的方法:创建隧道设备时指定external模式,利用路由设置的轻量级隧道通过tun设备发送报文。

Flowtable规则设置也是完全基于route信息去完成,沿着这一思路:tunnel信息也可以通过route信息获取。
| 提交patch:
我们提交了flowtable中tunnelmatch和encap/decap action的offloadpatches:
①Netfilter: flowtable: add tunnel match offload support(https://git.kernel.org/pub/sc...)
②Netfilter: flowtable: add tunnel encap/decap actionoffload support(https://git.kernel.org/pub/sc...)
3、Mlx5e在TC_SETUP_FT中支持Indirect block
接着,我们又发现了第3个问题:mlx5e驱动中flowtable offload的规则被指定到TC_SETUP_FT域中,但该驱动中并不支持indirect block。
| 提交patch:
发现这一点后,我们向社区提交了patch实现该功能的完善:
① net/mlx5e:refactor indr setup block(https://git.kernel.org/pub/sc...)
②net/mlx5e:add mlx5e_rep_indr_setup_ft_cb support(https://git.kernel.org/pub/sc...)
4、Tunnel offload 功能验证
完成上述开发步骤后,我们也按照前文的测试思路进行了功能验证,确认功能的完善与准确性。
| 测试验证:
创建一台虚拟机,配置虚拟机地址为10.0.0.75,具有外部地址2.2.2.11。host创建user1的vrf,创建key 1000的gretap tunnel device tun1。将虚拟机对应的VF representor mlx_pf0vf0和tun1加入到user1 vrf。PF mlx_p0配置underlay地址172.168.152.75/24。PF对端连接物理机网卡配置地址172.168.152.208/24, 创建gretap tunnel tun, tun设备的remote为172.168.152.75,key为1000,设置地址为1.1.1.7。 首先,虚拟机与对端物理机tun设备通过tunnel相互访问:
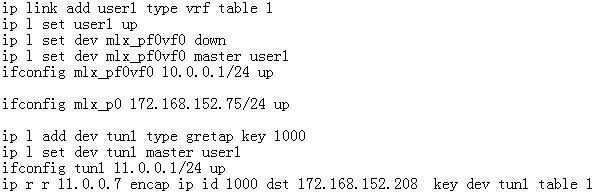
接着,创建firewall规则,允许访问虚拟机的icmp和tcp 5001端口,并且把VF representor port和tun 1隧道设备加入到flowtable做offload。 最后,创建NAT转发规则:dst ip address 2.2.2.11 dnat to 10.0.0.75、src ip address 10.0.0.75 snat to 2.2.2.11。
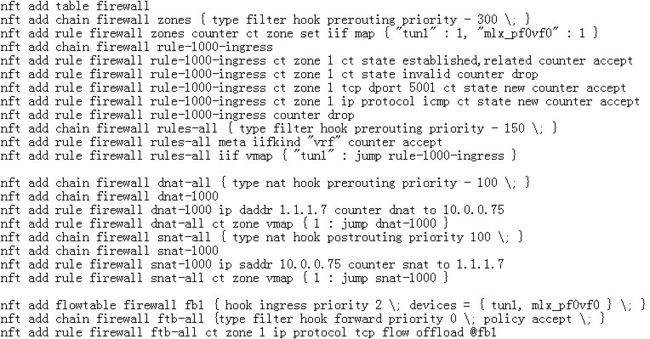
测试后最终确认各个功能完整正常,至此,我们实现了SDN网络下tunnel offload卸载的能力。
写在最后
以上是本项目涉及的部分核心问题,我们把这期间贡献的patch整理成了一份列表,希望能为开发者提供帮助,读者可以点击“阅读原文”阅览完整patch list。
Flow Offload开源技术为行业内带来了革命性的思路,但在技术的更新迭代过程中,一些新特性在实际应用上也会存在稳定性、兼容性等方面的问题。作为开源技术的同行者,UCloud一直积极探索、丰富开源技术功能,帮助提高开源技术稳定性。
作者简介:文旭,UCloud虚拟网络平台研发工程师,Linux kernel network 活跃开发者,Netfilter flowtable offload 稳定维护者