CNI插件之bridge plugin
CNI网络插件bridge plugin
- CNI网络插件bridge plugin
- Bridge插件概念
- Bridge功能使用
- 准备Kubernetes环境
- 安装配置bridge插件
- 安装ningx容器验证
- 使用cnitool验证
- Bridge工作原理
- 基本原理
- 主要流程
- 模拟试验
- Bridge源码分析
- NetConf结构体
- cmdAdd创建网络
- cmdDel删除网络
- cmdCheck检查网络
- 写在最后
CNI网络插件bridge plugin
Bridge插件是典型的CNI基础插件,其工作原理类似物理交换机,通过创建虚拟网桥将所有容器连接到一个二层网络,从而实现容器间的通信。
Bridge插件使用了Linux 原生网桥技术,功能单一结构简单,拥有较高的可靠性,在故障排查上也比较容易。Bridge对比其他网络插件,一方面更容易上手,有利于通过简单实验来揭示cni工作原理;另一方面被很多上层插件依赖,对理解和学习其他插件也有帮助;下面将循序渐进的展开说明该插件的原理和使用方法。
本文首先结合nginx应用来熟悉bridge插件使用,然后通过cnitool观察插件与外部交互行为,再通过模拟试验进一步剥开插件机制,最后分析源码阐述原理和实现;建议先上手操作后再带着问题分析原理,效果会更好。
下面将依次介绍:
- Bridge插件是什么
- Bridge插件安装配置
- Bridge结合ningx应用
- 通过cnitool验证Bridge
- Bridge原理和试验
- Bridge代码分析
Bridge插件概念
Bridge作为最基础的CNI网络插件,它的作用是将容器依附到网桥上实现与宿主机的通信,通过网桥机制建立连接是kubernetes实现容器通信的一种典型方式。bridge插件结合IPAM等插件来管理pod的网络设备和地址配置,在pod创建和删除过程中发挥作用。
如图所示,当容器创建时会建立一个虚拟网桥,可类比物理交换机,刚创建的网桥只接入了协议栈,其他端口未被使用;要让网桥用起来还需要生成一个虚拟网卡对veth pair,它相当于一条网线,其一端接在容器内另一端连到虚拟网桥上,以此来将容器接入网络。
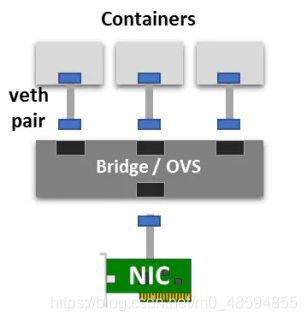
veth pair设备总是成对出现,两个设备彼此相连,一个设备上收到的数据会被转发到另一个设备上,效果类似于管道,在这里配合网桥作用,就是把一个 namespace 发出的数据包转发到另一个 namespace,实现容器内外交互。
bridge与macvlan等插件属于同一层级,下图展示了相关插件与CNI的关系。

Bridge功能使用
这里先结合nginx说明bridge插件使用方法,按以下步骤操作,并确保每个阶段的状态检查正常后再进入下一步。
准备Kubernetes环境
(以下步骤略去细节,详细内容可以参考kubernetes快速安装部署实践)
-
启动docker和kubelet服务
systemctl start docker
systemctl start kubelet
确保所有节点均启用服务,这里为了保证后续操作不受干扰,对于已经安装过k8s环境的机器需要通过kubeadm reset命令重置。 -
master节点初始化
kubeadm init --pod-network-cidr=192.166.0.0/16
注意分配给容器使用的虚拟地址不能和node地址同网段,此后所有pod都会从该地址池分配IP。 -
添加工作节点
kubeadm join 192.168.122.17:6443 --token xxx(需使用上一步init返回的结果)
所有工作节点直接使用master节点上kubeadm init执行后返回的join命令串。 -
检查各node状态
在Master节点运行命令,确保所有节点处于ready状态,至此k8s环境生效。
kubectl get node -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
k8s-nfv-master Ready master 47h v1.14.3 192.168.122.17 CentOS Linux 7 (Core) 3.10.0-957.el7.x86_64 docker://18.9.2
k8s-nfv-node1 Ready 47h v1.14.3 192.168.122.18 CentOS Linux 7 (Core) 3.10.0-957.el7.x86_64 docker://18.9.2
k8s-nfv-node2 Ready 47h v1.14.3 192.168.122.19 CentOS Linux 7 (Core) 3.10.0-957.el7.x86_64 docker://18.9.2
安装配置bridge插件
- 准备二进制文件
kubernetes版本1.14.3安装后默认包含bridge插件,其二进制可执行文件位于主节点的/opt/cni/bin目录中;如需通过源码编译生成可以按如下命令操作。
git clone https://github.com/containernetworking/plugins.git
cd plugins
./build_linux.sh
- 准备配置文件
在/etc/cni/net.d中增加cni配置文件10-bgnet.conf,指定使用的cni组件及参数;需要在所有节点配置该文件,各节点分配的IP范围可通过kubectl describe 查看 ;配置文件更新后,kubenet将会自动调用组件配置网络参数;也可以重启服务使配置立即生效。
systemctl restart docker
systemctl restart kubelet
Master配置:
{
"cniVersion":"0.3.1",
"name": "bgnet",
"type": "bridge",
"bridge": "cni0",
"isGateway": true,
"forceAddress": false,
"ipMasq": true,
"hairpinMode": true,
"ipam": {
"type": "host-local",
"subnet": "192.166.0.0/24",
"rangeStart": "192.166.0.100", //可选
"rangeEnd": "192.166.0.200", //可选
"gateway": "192.166.0.1", //可选
"routes": [
{ "dst": "0.0.0.0/0" }
]
}
}
配置字段详细说明:
- cniVersion: 使用的CNI版本 name: 网络名称,在管理域中唯一 type: 插件类型,即插件名称,这里是bridge
- bridge:网桥接口名称,如cni0 isGateway:是否为网桥分配IP地址,以便连到网桥的容器可以将其用作网关
- isDefaultGateway: 设置为true时将网桥配置为虚拟网络的默认网关,默认值为false
- forceAddress:如果先前的IP已更改,则要求插件分配一个新的IP,默认为false ipMasq:是否创建IP
- masquerade,即为出口流量启用SNAT将源地址改为网桥IP,默认为false mtu: 设置MTU为指定值,默认使用内核数值
- hairpinMode:为网桥接口设置反射中继,打开则允许网桥通过接收了以太网帧的虚拟端口将其重新发送回去,即让POD是否可以通过Service访问自己,默认为false
- promiscMode: 设置网桥的混杂模式,默认为false vlan: 分配Vlan标签,默认为none
- ipam:
设置ip分配方案,对于L2-only模式,创建为空即可 type: 指定使用的方案,对应IPAM插件名称,这里是host-local - subnet: 分配的子网范围 rangeStart:开始的地址 rangeEnd:结束的地址 gateway: 容器内部网络的网关
- routes: 路由
Node1配置:
{
"cniVersion":"0.3.1",
"name": "bgnet",
"type": "bridge",
"bridge": "cni0",
"isGateway": true,
"ipMasq": true,
"ipam": {
"type": "host-local",
"subnet": "192.166.1.0/24",
"rangeStart": "192.166.1.100",
"rangeEnd": "192.166.1.200",
"gateway": "192.166.1.1",
"routes": [
{ "dst": "0.0.0.0/0" }
]
}
}
Node2配置:
{
"cniVersion":"0.3.1",
"name": "bgnet",
"type": "bridge",
"bridge": "cni0",
"isGateway": true,
"ipMasq": true,
"ipam": {
"type": "host-local",
"subnet": "192.166.2.0/24",
"rangeStart": "192.166.2.100",
"rangeEnd": "192.166.2.200",
"gateway": "192.166.2.1",
"routes": [
{ "dst": "0.0.0.0/0" }
]
}
}
- 检查pod状态
在主节点输入命令,查询所有pod均为Running状态,且有分配到地址;比如其中coredns的pod分配到地址192.166.0.105,状态为Running,至此cni插件已生效。
kubectl get pod -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
coredns-fb8b8dccf-r4hkc 1/1 Running 2 47h 192.166.0.104 k8s-nfv-master
coredns-fb8b8dccf-v8zc6 1/1 Running 2 47h 192.166.0.105 k8s-nfv-master
etcd-k8s-nfv-master 1/1 Running 2 47h 192.168.122.17 k8s-nfv-master
kube-apiserver-k8s-nfv-master 1/1 Running 2 47h 192.168.122.17 k8s-nfv-master
kube-controller-manager-k8s-nfv-master 1/1 Running 2 47h 192.168.122.17 k8s-nfv-master
kube-proxy-4f7vr 1/1 Running 2 47h 192.168.122.17 k8s-nfv-master
kube-proxy-6gb2d 1/1 Running 0 47h 192.168.122.19 k8s-nfv-node2
kube-proxy-n8wxq 1/1 Running 0 47h 192.168.122.18 k8s-nfv-node1
kube-scheduler-k8s-nfv-master 1/1 Running 2 47h 192.168.122.17 k8s-nfv-master
安装ningx容器验证
- 创建configMap
ConfigMap提供了向容器中注入配置文件的功能,目的就是为了让镜像和配置文件解耦,以便实现镜像的可移植性和可复用性。注入方式有两种,一种将configMap做为存储卷,一种是将configMap通过env中configMapKeyRef注入到容器中,这里用前者。
以下是nginx.conf配置文件:
user nginx;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
#gzip on;
#include /etc/nginx/conf.d/*.conf;
server {
listen 80;
server_name localhost;
root /home/wwwroot/test;
index index.html;
}
}
在默认ns下,运行创建命令
kubectl create configmap confnginx --from-file nginx.conf
查看创建结果
kubectl get configmap
NAME DATA AGE
confnginx 1 41h
- 创建Replication Controller
RC可以保证在任意时间运行Pod的副本数量,保证Pod总是可用的。如果实际Pod数量比指定的多就结束掉多余的,如果实际数量比指定的少就新创建一些Pod,当Pod失败、被删除或者挂掉后,RC会去自动创建新的Pod来保证副本数量,这里使用RC来管理ngnix Pod。
apiVersion: v1
kind: ReplicationController //指明RC类型
metadata: //设置元数据
name: nginx-controller //RC自身命名
spec: //定义RC具体配置
replicas: 2 //设置pod数量维持在2个
selector: //通过selector来匹配相应pod的标签
name: nginx //服务名称
template: //设置pod模板
metadata:
labels: //设置标签
name: nginx
spec:
containers:
- name: nginx //容器名称
image: docker.io/nginx:alpine //使用的镜像
ports:
- containerPort: 80 //容器端口配置
volumeMounts:
- mountPath: /etc/nginx/nginx.conf //容器内部的配置目录
name: nginx-config
subPath: nginx.conf
- mountPath: /home/wwwroot/test //挂载节点主机目录
name: nginx-data
volumes:
- name: nginx-config //通过挂载存储卷注入configMap
configMap:
name: confnginx
- name: nginx-data
hostPath:
path: /home/wwwroot/test
创建nginx的RC pod,后续RC将按配置自动运行相应数量的ngnix容器
kubectl create -f nginx-rc.yaml
查看创建结果:
kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-controller-ggg2z 1/1 Running 0 30h 192.166.1.100 k8s-nfv-node1
nginx-controller-s84rt 1/1 Running 0 30h 192.166.2.100 k8s-nfv-node2
- 创建nginx的Service
Service可以看作是一组提供相同服务的Pod对外的访问接口,借助Service应用可以方便地实现服务发现和负载均衡。
nginx-svc.yaml如下:
apiVersion: v1
kind: Service // 指明service类型
metadata:
name: nginx-service-nodeport //指定服务名称
spec:
ports:
- port: 8000 //Service将会监听8000端口,并将所有监听到的请求转发给其管理的Pod
targetPort: 80 //Service监听到8000端口的请求会被转发给其管理的Pod的80端口
protocol: TCP
nodePort: 30080 //Service将通过Node上的30080端口暴露给外部
type: NodePort //此模式下访问任意一个NodeIP:nodePort都将路由到ClusterIP
selector:
name: nginx //指定service将要使用的标签,即会管理所有ngnix标签的pod
通过命令创建服务
kubectl create -f nginx-svc.yaml
查看服务状态:
kubectl get svc -A
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default kubernetes ClusterIP 10.96.0.1 443/TCP 2d
default nginx-service-nodeport NodePort 10.103.145.249 8000:30080/TCP 31h
kube-system kube-dns ClusterIP 10.96.0.10 53/UDP,53/TCP,9153/TCP 2d
其中10.103.145.249为服务对外提供的地址,端口为8000
-
验证连通性
1)Node1
通过node地址访问:wget http://192.168.122.18:30080/index.html
通过pod地址访问:wget http://192.166.1.100:80/index.html
通过service地址访问:wget http://10.103.145.249:8000/index.html
2)Node2
通过node地址访问:wget 192.168.122.19:30080
通过pod地址访问:wget http://192.166.2.100:80/index.html
通过service地址访问:wget http://10.103.145.249:8000/index.html验证节点内部访问正常,但节点之间无法访问,还需配置路由和转发规则
-
配置iptable规则
1)增加路由实现不同网段的跨节点访问
node1:
ip route add 192.166.2.0/24 via 192.168.122.19 dev ens3
node2:
ip route add 192.166.1.0/24 via 192.168.122.18 dev ens32)增加转发规则实现同节点上容器间和网桥的通讯
node1 & node2:
iptables -t filter -A FORWARD -s 192.166.0.0/16 -j ACCEPT
iptables -t filter -A FORWARD -d 192.166.0.0/16 -j ACCEPT3)增加NAT规则实现容器内部网络与外部网络的通讯
node1:
iptables -t nat -A POSTROUTING -s 192.166.1.0/24 ! -o cni0 -j MASQUERADE
node2:
iptables -t nat -A POSTROUTING -s 192.166.2.0/24 ! -o cni0 -j MASQUERADE此时在各节点使用wget测试,节点之间能相互连通,wget验证外网地址正常;由于service有进行负载均衡处理,在wget中可能散列到不同节点上获取文件。
-
进入容器验证
使用contain2ns.sh enter_ns.sh工具进入容器内部终端
1)查看接口:
Node1
ifconfig
eth0: flags=4163,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.166.1.100 netmask 255.255.255.0 broadcast 192.166.1.255
ether 2e:ab:58:fc:45:3e txqueuelen 0 (Ethernet)
RX packets 365 bytes 29668 (28.9 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 288 bytes 31042 (30.3 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
Node2
ifconfig
eth0: flags=4163,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.166.2.100 netmask 255.255.255.0 broadcast 192.166.2.255
ether 9e:ef:6f:db:d3:a6 txqueuelen 0 (Ethernet)
RX packets 192 bytes 14800 (14.4 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 146 bytes 14159 (13.8 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
2)测试容器到容器连通性
在node1上ping node2:ping 192.166.2.100
tcpdump抓包显示:
14:36:32.233236 IP 192.166.1.100 > 192.166.2.100: ICMP echo request, id 30854, seq 1, length 64
14:36:32.234221 IP 192.166.2.100 > 192.166.1.100: ICMP echo reply, id 30854, seq 1, length 64
Node2:
14:35:07.696705 IP 192.168.122.18 > 192.166.2.100: ICMP echo request, id 30768, seq 1, length 64
14:35:07.696800 IP 192.166.2.100 > 192.168.122.18: ICMP echo reply, id 30768, seq 1, length 64
3)测试容器到外网连通性
在node1上ping 外网:ping www.163.com
tcpdump抓包:
11:32:37.551205 IP 192.166.1.100.42476 > 192.168.122.1.domain: 38486+ A? www.163.com. (29)
11:32:37.571188 IP 192.168.122.1.domain > 192.166.1.100.42476: 38486 3/0/0 CNAME www.163.com.163jiasu.com., CNAME www.163.com.lxdns.com., A 222.79.64.33 (112)
11:32:37.571920 IP 192.166.1.100 > 222.79.64.33: ICMP echo request, id 29965, seq 1, length 64
11:32:37.579104 IP 222.79.64.33 > 192.166.1.100: ICMP echo reply, id 29965, seq 1, length 64
11:32:37.579518 IP 192.166.1.100.43713 > 192.168.122.1.domain: 2761+ PTR? 33.64.79.222.in-addr.arpa. (43)
11:32:37.599167 IP 192.168.122.1.domain > 192.166.1.100.43713: 2761 NXDomain 0/1/0 (96)
至此通过ngnix容器的上手操作,我们对bridge插件作用有个基本认识了。
使用cnitool验证
为了进一步理解bridge插件功能,下面使用官方提供的cnitool工具进行验证。
- 编译cni工具
git clone https://github.com/containernetworking/cni.git
cd ../cni/cnitool
go build cnitool.go
- 创建测试隔离空间
ip netns add test1
ip netns add test2 - 模拟创建网络
默认引用路径/etc/cni/net.d的配置文件
CNI_PATH=/opt/cni/bin/ ./cnitool add bgnet /var/run/netns/test1
执行完后,返回json串结果,包含接口IP路由信息。
{
"cniVersion": "0.3.1",
"interfaces": [
{
"name": "cni0",
"mac": "62:9f:2d:69:2c:70"
},
{
"name": "vethfa87a37b",
"mac": "1a:ad:4d:c5:83:b5"
},
{
"name": "eth0",
"mac": "0e:a3:d6:23:d3:fa",
"sandbox": "/var/run/netns/test1"
}
],
"ips": [
{
"version": "4",
"interface": 2,
"address": "192.166.0.108/24",
"gateway": "192.166.0.1"
}
],
"routes": [
{
"dst": "0.0.0.0/0"
}
],
"dns": {}
}
从返回的结果可以反映出插件有哪些操作:
1) 创建一个虚拟网桥cni0
2) 创建虚拟网卡对,一端连到host为vethfa87a37b
3)另一端连到/var/run/netns/test1隔离空间的容器并改名为eth0
4)按配置文件设置eth0地址为192.166.0.108,网关为192.166.0.1
类似的创建test2网络:
”CNI_PATH=/opt/cni/bin/ ./cnitool add bgnet /var/run/netns/test2
{
"cniVersion": "0.3.1",
"interfaces": [
{
"name": "cni0",
"mac": "62:9f:2d:69:2c:70"
},
{
"name": "veth14d6d026",
"mac": "96:74:bb:94:e4:f7"
},
{
"name": "eth0",
"mac": "da:82:f0:88:5b:10",
"sandbox": "/var/run/netns/test2"
}
],
"ips": [
{
"version": "4",
"interface": 2,
"address": "192.166.0.109/24",
"gateway": "192.166.0.1"
}
],
"routes": [
{
"dst": "0.0.0.0/0"
}
],
"dns": {}
}
- 查看状态
进入ns查看创建的网卡
sh-4.2# ifconfig
eth0: flags=4163,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.166.0.108 netmask 255.255.255.0 broadcast 192.166.0.255
inet6 fe80::d882:f0ff:fe88:5b10 prefixlen 64 scopeid 0x20
ether da:82:f0:88:5b:10 txqueuelen 0 (Ethernet)
RX packets 16 bytes 1228 (1.1 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 18 bytes 1300 (1.2 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
sh-4.2# ifconfig
eth0: flags=4163,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.166.0.109 netmask 255.255.255.0 broadcast 192.166.0.255
inet6 fe80::ca3:d6ff:fe23:d3fa prefixlen 64 scopeid 0x20
ether 0e:a3:d6:23:d3:fa txqueuelen 0 (Ethernet)
RX packets 12 bytes 796 (796.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 10 bytes 740 (740.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
sh-4.2# ip route
default via 192.166.0.1 dev eth0
192.166.0.0/24 dev eth0 proto kernel scope link src 192.166.0.109
同ngnix例子在增加转发规则后可互相ping通。
- 删除网络
CNI_PATH=/opt/cni/bin/ ./cnitool del bgnet /var/run/netns/test1
CNI_PATH=/opt/cni/bin/ ./cnitool del bgnet /var/run/netns/test2
重复上一步的状态查看可以发现虚拟网卡对vethfa87a37b和eth0已经被删除,相关路由和iptables规则也被清除。 - 删除隔离空间
ip netns del test1
ip netns del test2
通过上面的试验,我们已经弄清楚了bridge插件的行为,以及输入参数和返回结果的关系,接下来将展开分析插件原理。
Bridge工作原理
基本原理
bridge插件首先创建一个虚拟网桥,其功能类似物理交换机,将所有容器接入一个二层网络;容器接入是通过创建的veth pair(虚拟网卡对)实现,将网卡对的一端放在容器中并分配IP地址,另一端放在host的namespace内连上虚拟网桥,网桥上可以配置IP作为容器的网关,通过网桥连接了两个不同namespace内的网卡,容器内发出的数据包可通过网桥转发到host网络协议栈或进入另一个容器,最终实现容器之间、容器和主机间、容器和服务间的通信。
主要流程
-
创建容器时的动作
1)按名称检查网桥是否存在,若不存在则创建一个虚拟网桥
2)创建虚拟网卡对,将host端的veth口连接到网桥上
3)IPAM从地址池中分配IP给容器使用,并计算出对应网关配置到网桥
4)进入容器网络名称空间,修改容器端的网卡ip并配置路由
5)使用iptables增加容器内部网段到外部网段的masquerade规则
6)获取当前网桥信息,返回给调用者 -
删除容器时的动作
1)按输入参数找到要删除容器的IP地址,调用ipam插件删除地址并将IP归还地址池
2) 进入容器网络隔离ns,根据容器IP找到对应的网络接口并删除
3) 在节点主机上删除创建网络时添加的所有iptables规则
模拟试验
下面使用shell命令来模拟插件的行为
-
创建网桥并设置为网关:
ip link add cni0 type bridge
ip link set dev cni0 up
ifconfig cni0 192.166.1.1/24 up -
Ns1添加网络:
ip link add veth0 type veth peer name veth1 //创建网卡对
- host端
ip link set dev veth1 up
ip link set dev veth1 master cni0 //host端关联网桥 - pod端
ip netns add ns1
ip link set veth0 netns ns1 - 进入ns1
ip link set dev veth0 up
ifconfig veth0 192.166.1.101/24 up
ip route add default via 192.166.1.1 dev veth0
ip link show veth0
ping 192.166.1.102
- Ns2添加网络:
ip link add veth2 type veth peer name veth3 //创建网卡对
- host端
ip link set dev veth3 up
ip link set dev veth3 master cni0 //host端关联网桥 - pod端
ip netns add ns2
ip link set veth2 netns ns2 - 进入ns2
ip link set dev veth2 up
ifconfig veth2 192.166.1.102/24 up
ip route add default via 192.166.1.1 dev veth2
ip link show veth2
ping 192.166.1.101
- 测试连通性
增加转发规则
iptables -t filter -A FORWARD -s 192.167.0.0/16 -j ACCEPT
iptables -t filter -A FORWARD -d 192.167.0.0/16 -j ACCEPT
ns之间互ping:
ns1:ping 192.166.1.102
ns2:ping 192.166.1.101
Bridge源码分析
NetConf结构体
实现容器网络配置加载,可与之前的配置文件项目一一对应。
type NetConf struct {
types.NetConf //name:网络名称 //type:使用brigde
BrName string `json:"bridge"` //网桥名称,默认为cni0
IsGW bool `json:"isGateway"` //是否将网桥配置为网关
IsDefaultGW bool `json:"isDefaultGateway"` //分配默认路由
ForceAddress bool `json:"forceAddress"` // 是否清除已配置的网桥地址
IPMasq bool `json:"ipMasq"` // 是否配置内部网段到外部的NAT规则
MTU int `json:"mtu"` //设置mtu值
HairpinMode bool `json:"hairpinMode"` //设置发夹模式
PromiscMode bool `json:"promiscMode"` //设置混杂模式
Vlan int `json:"vlan"` //设置vlan
}
cmdAdd创建网络
func cmdAdd(args *skel.CmdArgs) error {
var success bool = false
n, cniVersion, err := loadNetConf(args.StdinData) //解析配置文件
if err != nil {
return err
}
isLayer3 := n.IPAM.Type != "" //判断L2模式还是L3模式
if n.IsDefaultGW { //检查是否配置网关
n.IsGW = true
}
if n.HairpinMode && n.PromiscMode { //检查hairpin和promisc模式
return fmt.Errorf("cannot set hairpin mode and promiscous mode at the same time.")
}
br, brInterface, err := setupBridge(n) //创建网桥
if err != nil {
return err
}
netns, err := ns.GetNS(args.Netns) //获取当前的namespace
if err != nil {
return fmt.Errorf("failed to open netns %q: %v", args.Netns, err)
}
defer netns.Close()
hostInterface, containerInterface, err := setupVeth(netns, br, args.IfName, n.MTU, n.HairpinMode, n.Vlan) //创建veth pair
if err != nil {
return err
}
- 1) loadNetConf:
func loadNetConf(bytes []byte) (*NetConf, string, error) {
n := &NetConf{
BrName: defaultBrName,
}
if err := json.Unmarshal(bytes, n); err != nil {
return nil, "", fmt.Errorf("failed to load netconf: %v", err)
}
if n.Vlan < 0 || n.Vlan > 4094 {
return nil, "", fmt.Errorf("invalid VLAN ID %d (must be between 0 and 4094)", n.Vlan)
}
return n, n.CNIVersion, nil
}
解析配置文件获取NetConf结构体信息,其中使用json.Unmarshall来解析数据。
- 2)setupBridge:
func setupBridge(n *NetConf) (*netlink.Bridge, *current.Interface, error) {
vlanFiltering := false
if n.Vlan != 0 {
vlanFiltering = true
}
// create bridge if necessary
br, err := ensureBridge(n.BrName, n.MTU, n.PromiscMode, vlanFiltering) //创建bridge然后返回bridge信息
if err != nil {
return nil, nil, fmt.Errorf("failed to create bridge %q: %v", n.BrName, err)
}
return br, ¤t.Interface{
Name: br.Attrs().Name,
Mac: br.Attrs().HardwareAddr.String(),
}, nil
}
setupBridge通过调用ensureBridge创建并启用网桥,类似 ip link add cni0 type bridge和ip link set dev cni0 up,最后返回网桥信息。
func ensureBridge(brName string, mtu int, promiscMode, vlanFiltering bool) (*netlink.Bridge, error) {
br := &netlink.Bridge{ //创建netlink的bridge
LinkAttrs: netlink.LinkAttrs{
Name: brName,
MTU: mtu,
// Let kernel use default txqueuelen; leaving it unset
// means 0, and a zero-length TX queue messes up FIFO
// traffic shapers which use TX queue length as the
// default packet limit
TxQLen: -1,
},
}
if vlanFiltering {
br.VlanFiltering = &vlanFiltering
}
err := netlink.LinkAdd(br) //调用netlink添加bridge
if err != nil && err != syscall.EEXIST {
return nil, fmt.Errorf("could not add %q: %v", brName, err)
}
if promiscMode { //若打开promisc则配置混杂模式
if err := netlink.SetPromiscOn(br); err != nil {
return nil, fmt.Errorf("could not set promiscuous mode on %q: %v", brName, err)
}
}
// Re-fetch link to read all attributes and if it already existed,
// ensure it's really a bridge with similar configuration
br, err = bridgeByName(brName) //重新获取bridge信息
if err != nil {
return nil, err
}
// we want to own the routes for this interface
_, _ = sysctl.Sysctl(fmt.Sprintf("net/ipv6/conf/%s/accept_ra", brName), "0") //对ipv6启用接收RA包
if err := netlink.LinkSetUp(br); err != nil { //启动bridge接口
return nil, err
}
return br, nil
}
ensureBridge中会创建netlink.Bridge,然后调用LinkAdd添加bridge;如果设置了promisc模式,则调用SetPromiscOn来启用混杂模式;对ipv6需要打开接收RA包;调用bridgeByName重新获取bridge信息,最后调用LinkSetUp启动bridge。
- 3)setupVeth:
setupVeth用于创建veth pair
func setupVeth(netns ns.NetNS, br *netlink.Bridge, ifName string, mtu int, hairpinMode bool, vlanID int) (*current.Interface, *current.Interface, error) {
contIface := ¤t.Interface{}
hostIface := ¤t.Interface{}
err := netns.Do(func(hostNS ns.NetNS) error {
// create the veth pair in the container and move host end into host netns
hostVeth, containerVeth, err := ip.SetupVeth(ifName, mtu, hostNS) //在容器中创建veth pair 将一端移到宿主机并启用
if err != nil {
return err
}
contIface.Name = containerVeth.Name
contIface.Mac = containerVeth.HardwareAddr.String()
contIface.Sandbox = netns.Path()
hostIface.Name = hostVeth.Name
return nil
})
if err != nil {
return nil, nil, err
}
// need to lookup hostVeth again as its index has changed during ns move
hostVeth, err := netlink.LinkByName(hostIface.Name) //移动后发生变化需要重新获取主机端veth
if err != nil {
return nil, nil, fmt.Errorf("failed to lookup %q: %v", hostIface.Name, err)
}
hostIface.Mac = hostVeth.Attrs().HardwareAddr.String()
// connect host veth end to the bridge
if err := netlink.LinkSetMaster(hostVeth, br); err != nil { //将宿主机端veth连到bridge
return nil, nil, fmt.Errorf("failed to connect %q to bridge %v: %v", hostVeth.Attrs().Name, br.Attrs().Name, err)
}
// set hairpin mode
if err = netlink.LinkSetHairpin(hostVeth, hairpinMode); err != nil { //设置hairpin模式
return nil, nil, fmt.Errorf("failed to setup hairpin mode for %v: %v", hostVeth.Attrs().Name, err)
}
if vlanID != 0 {
err = netlink.BridgeVlanAdd(hostVeth, uint16(vlanID), true, true, false, true) //配置宿主机veth的vlan-id
if err != nil {
return nil, nil, fmt.Errorf("failed to setup vlan tag on interface %q: %v", hostIface.Name, err)
}
}
return hostIface, contIface, nil
}
首先进入容器ns调用ip.SetupVeth创建veth pair,内部会调用makeVeth在容器里创建veth0-veth1虚拟网络接口对,作用同管道,类似ip link add veth0 type veth peer name veth1;
然后调用LinkSetUp启动容器端网卡veth0,类似ip link set dev veth0 up
调用LinkSetNsFd将host端网卡veth1加入host-ns中 ,类似ip link set veth1 netns default
调用LinkSetUp启动host端网卡veth1,类似ip link set dev veth1 up
调用LinkByName重新获取host端的veth1,因为移动后信息可能发生变化。
调用LinkSetMaster 将host端veth1连到网桥cni0上,类似ip link set dev veth1 master cni0
调用LinkSetHairpin设置hairpin模式
如果有vlan,则调用BridgeVlanAdd给host的veth1配置vlan id。
- 4) ipam ExecAdd:
if isLayer3 {
// run the IPAM plugin and get back the config to apply
r, err := ipam.ExecAdd(n.IPAM.Type, args.StdinData) //调用IPAM插件返回IP配置信息
if err != nil {
return err
}
// release IP in case of failure
defer func() {
if !success {
ipam.ExecDel(n.IPAM.Type, args.StdinData) //异常时清除IP配置
}
}()
// Convert whatever the IPAM result was into the current Result type
ipamResult, err := current.NewResultFromResult(r)
if err != nil {
return err
}
若为L3模式下,ExecAdd调用ipam插件获取信息,得到分配给容器的IP地址,对结果进行类型转换,并返回配置信息。
- 5) calcGateways:
func calcGateways(result *current.Result, n *NetConf) (*gwInfo, *gwInfo, error) {
gwsV4 := &gwInfo{}
gwsV6 := &gwInfo{}
for _, ipc := range result.IPs {
// Determine if this config is IPv4 or IPv6
var gws *gwInfo
defaultNet := &net.IPNet{}
switch {
case ipc.Address.IP.To4() != nil:
gws = gwsV4
gws.family = netlink.FAMILY_V4
defaultNet.IP = net.IPv4zero
case len(ipc.Address.IP) == net.IPv6len:
gws = gwsV6
gws.family = netlink.FAMILY_V6
defaultNet.IP = net.IPv6zero
default:
return nil, nil, fmt.Errorf("Unknown IP object: %v", ipc)
}
defaultNet.Mask = net.IPMask(defaultNet.IP)
// All IPs currently refer to the container interface
ipc.Interface = current.Int(2)
// If not provided, calculate the gateway address corresponding
// to the selected IP address
if ipc.Gateway == nil && n.IsGW {
ipc.Gateway = calcGatewayIP(&ipc.Address)
}
// Add a default route for this family using the current
// gateway address if necessary.
if n.IsDefaultGW && !gws.defaultRouteFound {
for _, route := range result.Routes {
if route.GW != nil && defaultNet.String() == route.Dst.String() {
gws.defaultRouteFound = true
break
}
}
if !gws.defaultRouteFound {
result.Routes = append(
result.Routes,
&types.Route{Dst: *defaultNet, GW: ipc.Gateway},
)
gws.defaultRouteFound = true
}
}
// Append this gateway address to the list of gateways
if n.IsGW {
gw := net.IPNet{
IP: ipc.Gateway,
Mask: ipc.Address.Mask,
}
gws.gws = append(gws.gws, gw)
}
}
return gwsV4, gwsV6, nil
}
根据IPAM返回结果,收集每个IP地址的网关信息计算出容器对应的网关,并配置默认路由;
- 6) ConfigureIface:
// Configure the container hardware address and IP address(es)
if err := netns.Do(func(_ ns.NetNS) error {
// Disable IPv6 DAD just in case hairpin mode is enabled on the
// bridge. Hairpin mode causes echos of neighbor solicitation
// packets, which causes DAD failures.
for _, ipc := range result.IPs {
if ipc.Version == "6" && (n.HairpinMode || n.PromiscMode) {
if err := disableIPV6DAD(args.IfName); err != nil { //禁用IPV6-DAD
return err
}
break
}
}
// Add the IP to the interface
if err := ipam.ConfigureIface(args.IfName, result); err != nil { //配置接口IP
return err
}
return nil
}); err != nil {
return err
}
进入容器namespace中获取端口,调用ConfigureIface设置IP地址和mac地址到容器端的虚拟网络接口上,host端不设置地址,禁用IPV6-DAD后设置为hairpin模式,按需配置网桥为网关,类似ifconfig veth0 192.166.1.105/24 up。
- 7) GratuitousArpOverIface:
// Send a gratuitous arp
if err := netns.Do(func(_ ns.NetNS) error {
contVeth, err := net.InterfaceByName(args.IfName)
if err != nil {
return err
}
for _, ipc := range result.IPs {
if ipc.Version == "4" {
_ = arping.GratuitousArpOverIface(ipc.Address.IP, *contVeth) //发送arp通告
}
}
return nil
}); err != nil {
return err
}
在ns中设置ARP广播信息发送通告。
- 8) ensureVlanInterface
// Set the IP address(es) on the bridge and enable forwarding
for _, gws := range []*gwInfo{gwsV4, gwsV6} {
for _, gw := range gws.gws {
if gw.IP.To4() != nil && firstV4Addr == nil {
firstV4Addr = gw.IP
}
if n.Vlan != 0 {
vlanIface, err := ensureVlanInterface(br, n.Vlan) //创建vlan接口
if err != nil {
return fmt.Errorf("failed to create vlan interface: %v", err)
}
if vlanInterface == nil {
vlanInterface = ¤t.Interface{Name: vlanIface.Attrs().Name,
Mac: vlanIface.Attrs().HardwareAddr.String()}
result.Interfaces = append(result.Interfaces, vlanInterface)
}
err = ensureAddr(vlanIface, gws.family, &gw, n.ForceAddress) //配置vlan接口IP和mac信息
if err != nil {
return fmt.Errorf("failed to set vlan interface for bridge with addr: %v", err)
}
} else {
err = ensureAddr(br, gws.family, &gw, n.ForceAddress)
if err != nil {
return fmt.Errorf("failed to set bridge addr: %v", err)
}
}
}
func ensureVlanInterface(br *netlink.Bridge, vlanId int) (netlink.Link, error) {
name := fmt.Sprintf("%s.%d", br.Name, vlanId)
brGatewayVeth, err := netlink.LinkByName(name) //获取bridge对应vlan端口
if err != nil {
if err.Error() != "Link not found" {
return nil, fmt.Errorf("failed to find interface %q: %v", name, err)
}
hostNS, err := ns.GetCurrentNS()
if err != nil {
return nil, fmt.Errorf("faild to find host namespace: %v", err)
}
_, brGatewayIface, err := setupVeth(hostNS, br, name, br.MTU, false, vlanId) //创建veth pair
if err != nil {
return nil, fmt.Errorf("faild to create vlan gateway %q: %v", name, err)
}
brGatewayVeth, err = netlink.LinkByName(brGatewayIface.Name)
if err != nil {
return nil, fmt.Errorf("failed to lookup %q: %v", brGatewayIface.Name, err)
}
}
return brGatewayVeth, nil
}
若在网关模式下配置了vlan,调用ensureVlanInterface创建vlan接口,获取到br对应vlan的端口,再调用setupVeth创建veth pair,然后返回veth pair对应的信息;最后调用ensureAddr配置IP,其中通过调用AddrAdd添加IP地址,然后调用LinkSetHardwareAddr设置bridge的mac。
- 9)enableIPForward:
if gws.gws != nil {
if err = enableIPForward(gws.family); err != nil { //配置网络转发
return fmt.Errorf("failed to enable forwarding: %v", err)
}
}
}
在配置网关地址后,调用enableIPForward启用网桥的ipv4和ipv6网络转发功能。
/proc/sys/net/ipv4/ip_forward=1
/proc/sys/net/ipv6/conf/all/forwarding=1
- 10) SetupIPMasq:
if n.IPMasq {
chain := utils.FormatChainName(n.Name, args.ContainerID)
comment := utils.FormatComment(n.Name, args.ContainerID)
for _, ipc := range result.IPs {
if err = ip.SetupIPMasq(&ipc.Address, chain, comment); err != nil { //配置IP伪装
return err
}
}
}
若有配置IPMasq,调用ip.SetupIPMasq设置IP伪装,
配合FormatChainName设置格式,配置iptable规则,增加snat规则,保证容器内部到外部网络能正常通讯。
- 11) 获取网桥信息
// Refetch the bridge since its MAC address may change when the first
// veth is added or after its IP address is set
br, err = bridgeByName(n.BrName) //经过以上变更后需要重新获取bridge信息
if err != nil {
return err
}
brInterface.Mac = br.Attrs().HardwareAddr.String()
result.DNS = n.DNS
// Return an error requested by testcases, if any
if debugPostIPAMError != nil {
return debugPostIPAMError
}
success = true
return types.PrintResult(result, cniVersion)
调用bridgeByName重新获取bridge信息,用于返回结果,因为在添加veth pair和配置ip之后,可能导致bridge信息发生变化。最后忽略多播包处理,返回网桥信息。
cmdDel删除网络
func cmdDel(args *skel.CmdArgs) error {
n, _, err := loadNetConf(args.StdinData) //解析配置文件
if err != nil {
return err
}
isLayer3 := n.IPAM.Type != ""
if isLayer3 { //若在L3模式则删除申请的IP地址
if err := ipam.ExecDel(n.IPAM.Type, args.StdinData); err != nil {
return err
}
}
if args.Netns == "" {
return nil
}
// There is a netns so try to clean up. Delete can be called multiple times
// so don't return an error if the device is already removed.
// If the device isn't there then don't try to clean up IP masq either.
var ipnets []*net.IPNet
err = ns.WithNetNSPath(args.Netns, func(_ ns.NetNS) error {
var err error
ipnets, err = ip.DelLinkByNameAddr(args.IfName) //进入容器删除端口和IP地址
if err != nil && err == ip.ErrLinkNotFound {
return nil
}
return err
})
if err != nil {
return err
}
if isLayer3 && n.IPMasq { //如果配置了IPMasq则删除相关NAT规则
chain := utils.FormatChainName(n.Name, args.ContainerID)
comment := utils.FormatComment(n.Name, args.ContainerID)
for _, ipn := range ipnets {
if err := ip.TeardownIPMasq(ipn, chain, comment); err != nil {
return err
}
}
}
return err
}
- 1) loadNetConf:加载配置文件信息。
- 2)ipam.ExecDel:若为L3模式,则通过ipam插件删除容器申请的IP地址,并归还到地址池。
- 3)DelLinkByNameAddr:进入容器ns删除对应的网络接口veth和IP地址。
- 4)TeardownIPMasq:若配置了IPMasq,则删除添加的iptable规则取消IP伪装。
cmdCheck检查网络
func cmdCheck(args *skel.CmdArgs) error {
n, _, err := loadNetConf(args.StdinData) //加载配置文件
if err != nil {
return err
}
netns, err := ns.GetNS(args.Netns) //获取对应namespace
if err != nil {
return fmt.Errorf("failed to open netns %q: %v", args.Netns, err)
}
defer netns.Close()
// run the IPAM plugin and get back the config to apply
err = ipam.ExecCheck(n.IPAM.Type, args.StdinData) //调用ipam插件check功能
if err != nil {
return err
}
// Parse previous result.
if n.NetConf.RawPrevResult == nil {
return fmt.Errorf("Required prevResult missing")
}
if err := version.ParsePrevResult(&n.NetConf); err != nil { //解析netconf内的RawPrevResult
return err
}
result, err := current.NewResultFromResult(n.PrevResult) //对解析结果进行转换
if err != nil {
return err
}
var errLink error
var contCNI, vethCNI cniBridgeIf
var brMap, contMap current.Interface
// Find interfaces for names whe know, CNI Bridge and container
for _, intf := range result.Interfaces { //获取bridge端口及容器ns中接口信息
if n.BrName == intf.Name {
brMap = *intf
continue
} else if args.IfName == intf.Name {
if args.Netns == intf.Sandbox {
contMap = *intf
continue
}
}
}
brCNI, err := validateCniBrInterface(brMap, n) //检测bridge是否合法
if err != nil {
return err
}
// The namespace must be the same as what was configured
if args.Netns != contMap.Sandbox { //检查result中的ns和参数ns是否一致
return fmt.Errorf("Sandbox in prevResult %s doesn't match configured netns: %s",
contMap.Sandbox, args.Netns)
}
// Check interface against values found in the container
if err := netns.Do(func(_ ns.NetNS) error {
contCNI, errLink = validateCniContainerInterface(contMap) //进入ns检测接口是否合法
if errLink != nil {
return errLink
}
return nil
}); err != nil {
return err
}
// Now look for veth that is peer with container interface.
// Anything else wasn't created by CNI, skip it
for _, intf := range result.Interfaces {
// Skip this result if name is the same as cni bridge
// It's either the cni bridge we dealt with above, or something with the
// same name in a different namespace. We just skip since it's not ours
if brMap.Name == intf.Name {
continue
}
// same here for container name
if contMap.Name == intf.Name {
continue
}
vethCNI, errLink = validateCniVethInterface(intf, brCNI, contCNI) //检查bridge的veth和容器中的veth是否成对
if errLink != nil {
return errLink
}
if vethCNI.found {
// veth with container interface as peer and bridge as master found
break
}
}
if !brCNI.found {
return fmt.Errorf("CNI created bridge %s in host namespace was not found", n.BrName)
}
if !contCNI.found {
return fmt.Errorf("CNI created interface in container %s not found", args.IfName)
}
if !vethCNI.found {
return fmt.Errorf("CNI veth created for bridge %s was not found", n.BrName)
}
// Check prevResults for ips, routes and dns against values found in the container
if err := netns.Do(func(_ ns.NetNS) error {
err = ip.ValidateExpectedInterfaceIPs(args.IfName, result.IPs) //检查ip是否符合预期
if err != nil {
return err
}
err = ip.ValidateExpectedRoute(result.Routes) //检查route是否符合预期
if err != nil {
return err
}
return nil
}); err != nil {
return err
}
return nil
}
func validateCniBrInterface(intf current.Interface, n *NetConf) (cniBridgeIf, error) {
brFound, link, err := validateInterface(intf, false) //检查bridge是否存在,有则返回link信息
if err != nil {
return brFound, err
}
_, isBridge := link.(*netlink.Bridge) //判断link是不是bridge
if !isBridge {
return brFound, fmt.Errorf("Interface %s does not have link type of bridge", intf.Name)
}
if intf.Mac != "" { //检查配置mac信息是否符合实际mac
if intf.Mac != link.Attrs().HardwareAddr.String() {
return brFound, fmt.Errorf("Bridge interface %s Mac doesn't match: %s", intf.Name, intf.Mac)
}
}
linkPromisc := link.Attrs().Promisc != 0
if linkPromisc != n.PromiscMode { //如果配置打开promisc则检查模式是否正确
return brFound, fmt.Errorf("Bridge interface %s configured Promisc Mode %v doesn't match current state: %v ",
intf.Name, n.PromiscMode, linkPromisc)
}
brFound.found = true
brFound.Name = link.Attrs().Name
brFound.ifIndex = link.Attrs().Index
brFound.masterIndex = link.Attrs().MasterIndex
return brFound, nil
}
func validateCniContainerInterface(intf current.Interface) (cniBridgeIf, error) {
vethFound, link, err := validateInterface(intf, true) //检查容器端的veth是否存在,有则返回link信息
if err != nil {
return vethFound, err
}
_, isVeth := link.(*netlink.Veth) //检查link信息是否为veth类型
if !isVeth {
return vethFound, fmt.Errorf("Error: Container interface %s not of type veth", link.Attrs().Name)
}
_, vethFound.peerIndex, err = ip.GetVethPeerIfindex(link.Attrs().Name) //获取另一端的link信息
if err != nil {
return vethFound, fmt.Errorf("Unable to obtain veth peer index for veth %s", link.Attrs().Name)
}
vethFound.ifIndex = link.Attrs().Index
if intf.Mac != "" {
if intf.Mac != link.Attrs().HardwareAddr.String() { //检查mac地址是否匹配实际mac地址
return vethFound, fmt.Errorf("Interface %s Mac %s doesn't match container Mac: %s", intf.Name, intf.Mac, link.Attrs().HardwareAddr)
}
}
vethFound.found = true
vethFound.Name = link.Attrs().Name
return vethFound, nil
}
- 1)loadNetConf:加载解析配置文件
- 2)ExecCheck:调用ipam插件ExecCheck进行检查
- 3)validateCniBrInterface:检测bridge端口类型和mac地址
- 4)validateCniContainerInterface:检测容器接口类型和mac地址
- 5)validateCniVethInterface:检查bridge和容器的veth是否配对
- 6)ValidateExpectedInterfaceIPs:检查ip是否配置正确
- 7)ValidateExpectedRoute:检查route是否配置正确
写在最后
- 在验证连通性过程中若将宿主机eth0接口与网桥cni0关联绑定,可以不依赖配置的路由和转发规则,但在实际场景中不会这样使用,多节点配合上层插件使用时也是通过规则来建立连接的。
- 使用kubectl创建查询对象时注意确保名称空间一致,若有出现异常优先检查ns相关配置;验证连通性之前需要弄清node,pod,service三类IP地址的作用,以便对后续试验的理解。
1)Node IP:Kubernetes集群中节点的物理网卡IP,所有属于这个网络的服务器之间都可以直接通信,集群外要想访问内部的某个节点或者服务必须通过Node IP进行通信。
2)Pod IP:每个Pod的IP,是按照Kubernet主节点初始化时配置的网桥地址段进行分配的。
3)Cluster IP:是一个虚拟IP, 仅仅用于 Kubernetes Service对象, 由Kubernetes自行管理和分配地址,并没有一个真正的实体对象来响应, 只能结合 Service Port 来组成一个可以通信的服务。 - 由于Bridge插件功能比较单一,在多主机网络通信中还需要另外配置路由,所以实际使用中往往是结合Flannel等第三方插件来使用,下一篇将介绍 “CNI网络插件之flannel”,来看看它是如何结合Bridge实现更丰富功能的。