go pv uv 统计
go pv uv 统计
更多干货
-
分布式实战(干货)
-
spring cloud 实战(干货)
-
mybatis 实战(干货)
-
spring boot 实战(干货)
-
React 入门实战(干货)
-
构建中小型互联网企业架构(干货)
-
python 学习持续更新
-
ElasticSearch 笔记
-
kafka storm 实战 (干货)
-
scala 学习持续更新
-
RPC
-
深度学习
-
GO 语言 持续更新
概述
当你网站访问量过大时 第3方统计系统就不愿意了,这时就需要自己来设计个流量统计了。
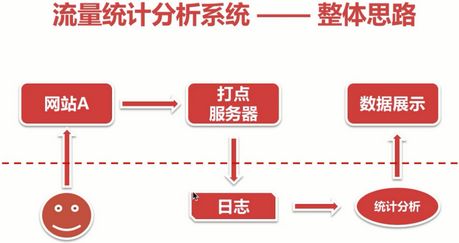
流量分析系统是用来分析NGINX的日志数据的,NGINX的日志数据是用户网站访问后生成的,所以我们需要搭建一个网站,来产生一些用户行为数据。然后通过javascript快速上报到打点服务器,然后打点服务器再上报到nginx,nginx会生成用户行为日志,再通过我们用GO开发的流量统计系统分析处理后中,再由前台数据展示出来。
在一个比较大的WEB网站,几百万几千万流量的上报打点请求,如果我们用一个低性能的WEBSERVER做打点服务器,会非常卡,影响效率,所以最好用好一些的服务器。 我们的打点服务器需要用到nginx的一个模块,ngx_http_empty_gif_module,这个模块,这个module可以生成1x1像素大小的透明的gif图片。非常小的
打点js 参照:
-
[js获取客户端time,cookie,url,ip,refer,user_agent信息](https://blog.csdn.net/qq_27384769/article/details/81009884)
-
[nginx空白图片 访问打点](https://blog.csdn.net/qq_27384769/article/details/81012625)
第三方库
go get github.com/sirupsen/logrusgo get github.com/mgutz/strgo get github.com/mediocregopher/radix.v2代码
package main
import (
"flag"
"github.com/sirupsen/logrus"
"time"
"os"
"bufio"
"io"
"strings"
"github.com/mgutz/str"
"net/url"
"crypto/md5"
"encoding/hex"
"github.com/mediocregopher/radix.v2/pool"
"strconv"
)
const HANDLE_DIG = " /dig?"
const HANDLE_MOVIE = "/movie/"
const HANDLE_LIST = "/list/"
const HANDLE_HTML = ".html"
type cmdParams struct {
logFilePath string
routineNum int
}
type digData struct{
time string
url string
refer string
ua string
}
type urlData struct {
data digData
uid string
unode urlNode
}
type urlNode struct {
unType string // 详情页 或者 列表页 或者 首页
unRid int // Resource ID 资源ID
unUrl string // 当前这个页面的url
unTime string // 当前访问这个页面的时间
}
type storageBlock struct {
counterType string
storageModel string
unode urlNode
}
var log = logrus.New()
func init() {
log.Out = os.Stdout
log.SetLevel( logrus.DebugLevel )
}
func main() {
// 获取参数
logFilePath := flag.String( "logFilePath", "/Users/pangee/Public/nginx/logs/dig.log", "log file path" )
routineNum := flag.Int( "routineNum", 5, "consumer numble by goroutine" )
l := flag.String( "l", "/tmp/log", "this programe runtime log target file path" )
flag.Parse()
params := cmdParams{ *logFilePath, *routineNum }
// 打日志
logFd, err := os.OpenFile( *l, os.O_CREATE|os.O_WRONLY, 0644 )
if err == nil {
log.Out = logFd
defer logFd.Close()
}
log.Infof( "Exec start." )
log.Infof( "Params: logFilePath=%s, routineNum=%d", params.logFilePath, params.routineNum )
// 初始化一些channel,用于数据传递
var logChannel = make(chan string, 3*params.routineNum)
var pvChannel = make(chan urlData, params.routineNum)
var uvChannel = make(chan urlData, params.routineNum)
var storageChannel = make(chan storageBlock, params.routineNum)
// Redis Pool
redisPool, err := pool.New( "tcp", "localhost:6379", 2*params.routineNum );
if err != nil{
log.Fatalln( "Redis pool created failed." )
panic(err)
} else {
go func(){
for{
redisPool.Cmd( "PING" )
time.Sleep( 3*time.Second )
}
}()
}
// 日志消费者
go readFileLinebyLine( params, logChannel )
// 创建一组日志处理
for i:=0; i列表页≥首页
pos1 := str.IndexOf( url, HANDLE_MOVIE, 0)
if pos1!=-1 {
pos1 += len( HANDLE_MOVIE )
pos2 := str.IndexOf( url, HANDLE_HTML, 0 )
idStr := str.Substr( url , pos1, pos2-pos1 )
id, _ := strconv.Atoi( idStr )
return urlNode{ "movie", id, url, t }
} else {
pos1 = str.IndexOf( url, HANDLE_LIST, 0 )
if pos1!=-1 {
pos1 += len( HANDLE_LIST )
pos2 := str.IndexOf( url, HANDLE_HTML, 0 )
idStr := str.Substr( url , pos1, pos2-pos1 )
id, _ := strconv.Atoi( idStr )
return urlNode{ "list", id, url, t }
} else {
return urlNode{ "home", 1, url, t}
} // 如果页面url有很多种,就不断在这里扩展
}
}
func getTime( logTime, timeType string ) string {
var item string
switch timeType {
case "day":
item = "2018-01-02"
break
case "hour":
item = "2018-01-02 15"
break
case "min":
item = "2018-01-02 15:04"
break
}
t, _ := time.Parse( item, time.Now().Format(item) )
return strconv.FormatInt( t.Unix(), 10 )
}