kafka
一、kafka简介
1、kafka的版本变化:搜apache kafka new feature list---->more improvements and fixes
2、kafka有很多厂商,最初由linkedIn打造,然后捐给了apache
3、kafka-characteristics:persistent messaging、high throughput、distributed、multiple client support、real time、consumer pull(amq comsumer is broker push)
4、kafka use cases:log aggregatior、stream processing、commit logs、click stream tracking、message-queue
二、keyword
(一)、kafka术语
1、message:
2、key:路由,消息放在哪个partition
3、batches:批处理,减少网络带宽
4、schema:while messages are opaque byte arrays to kafka iteself, it is recommended that additional structure, or schema, be imposed on the message content so that it can be easily understood--->serialize and deserialize
5、topic:
6、partition:
7、producer:
8、consumer:传统mq是broker去push message to consumer(容易把应用压死,ri),kafka-consumer-client is pull message from broker
9、consumer group:
10、broker:
11、cluster:
12、controller:cluster中的master-broker,kafka选主机制:谁先启动,谁先注册到zk,谁就是master
13、partition-leader:只有partition-leader才能读写数据(与producer、consumer交互)
14、multiple cluster:多机房部署,灾备
(二)、消息传递的三种语义:
1、至少一次:即生产者向消费者至少一次的发送,不会丢数据,可能重复(kafka)
2、最多一次:即生产者向消费者至多一次的发送,有可能丢消息
(场景:生产者给消费者发送一条数据,消费者给生产者发送ack,但生产者没有收到ack,生产者就给消费者发送了同样的一条数据)
3、有且只有一次:生产一条消息,消费一条消息,不会重复,也不会丢失
(三)、两种消费模型
分区消费模型:
1、更灵活
2、需要自己处理各种异常情况
3、需要自己管理offset(以实现消息传递的其他语义)
组消费模型:
1、更简单,但不灵活
2、不需要自己处理异常情况,不需要自己管理offset
3、只能实现kafka默认的最少一次的消息传递语义
三、kafka安装
(一)、简单安装(使用自带的zk)
1、cd /kafka 解压:tar -zxvf kafka_2.10-0.10.2.1.tgz
注:scala的版本是2.10
2、cd /kafka 、mkdir data、mkdir data/zk -p、mkdir data/kafka -p
3、cd /kafka/kafka_2.10-0.10.2.1/config 修改zk配置:vim zookeeper.properties
注:zk配置
dataDir=/opt/app/kafka/data/zk
clientPort=2181
maxClientCnxns=100
判断时候有进程占用2181:netstat -ntlp|grep 2181
4、cd /kafka/kafka_2.10-0.10.2.1/config 修改broker配置:vim server.properties
注:broker配置
broker.id=0--->cluster中唯一
log.dirs=/opt/app/kafka/data/kafka
num.partitions=1--->创建topic时,默认partition的个数
zookeeper.connect=ip:2181--->连接的zk配置
listeners=PLAINTEXT://(ip):9092--->有不同的协议,默认用plaintext。ip不加的话默认是localhost
5、启动zk bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
判断zk是否启动:netstat -ntlp|grep 2181
6、启动broker bin/kafka-server-start.sh -daemon config/server.properties
判断broker是否启动:netstat -na|grep 9092
7、判断broker是否与zk连接(登录zk的客户端):bin/zookeeper-shell.sh localhost:2181
验证:
ls /
get /cluster/id--->kafka-cluster的id
get /brokers/ids/0--->单个broker的数据
8、验证kafka的功能
创建topic:bin/kafka-topics.sh --create --topic test --zookeeper localhost:2181 --partitions 1 --replication-factor 1
创建producer:bin/kafka-console-producer.sh --topic test --broker-list 192.168.171.17:9092
创建consumer:bin/kafka-console-consumer.sh --topic test --bootstrap-server 192.168.171.17:9092
创建consumer:bin/kafka-console-consumer.sh --topic test --bootstrap-server 192.168.171.17:9092 --from-beginning (收到所有的数据)
9、查看topic的描述:bin/kafka-topics.sh --describe --topic test --zookeeper localhost:2181
字段说明:
Toptic(主题):test
Partition(分区):0(分区号)
Leader(partition-leader所在的brokerid):0(brokerid)、
Replicas(该partition所在的所有brokerid,包括leader和follow):2,1,0(brokerids)
Isr(有资格成为leader的partition所在的brokerid):2,0(brokerids)
10、producer生产消息时报错:
报错:ERROR Error when sending message to topic test with key: null, value: 2 bytes with error: (org.apache.kafka.clients.producer.internals.ErrorLoggingCallback)
org.apache.kafka.common.errors.TimeoutException: Failed to update metadata after 60000 ms.
kafka_2.10-0.10.2.1/logs/kafkaServer.out报错:Could not initialize class kafka.network.RequestChannel
解决:vim /etc/hosts 192.168.171.17 host-192-168-171-17
(二)伪分布式
(三)、分布式
1、查看某个端口是tcp还是udp:lsof -i: port
2、查看有多少了topic:bin/kafka-topics.sh --list --zookeeper localhost:2181
3、配置说明:
a、log.retention.hours=168--->消费后默认存一周
b、log.retention.bytes--->针对每个partition
c、log.dirs--->可以有多个,用逗号分隔
d、num.recovery.threads.per.data.dir--->一般几个目录用几个线程
e、auto.create.topics.enable--->当生产或消费的toptic不存在时,自动创建
f、log.segment.bytes--->一个tipic由多个partition组成,一个partition由多个segment组成。状态为open的不可删,close的可删
g、log.segment.ms--->segment被关闭后,多久会被删除
h、message.max.bytes--->生产数据的最大值
四、producer
1、生产数据逻辑图
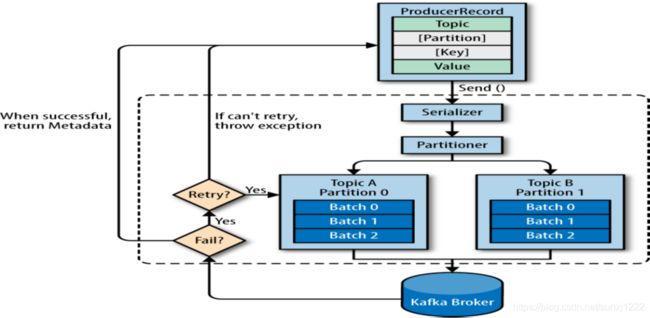
(一)、相关配置
http://kafka.apache.org/0110/documentation.html#configuration
1、acks
a、0:producer发送消息后,不管成功与否。且同步或异步的返回值中没有metadata
b、1:partition-leader收到后返回给producer,不管有没有同步到partition-follow
c、all:partition-leader收到后,并同步给isr中的partition-follow后返回给producer【可保证数据不丢】
2、buffer.memory
一个个的producerRecord会放在batch中,batch达到了一定的数量才发给broker
3、compression.type
压缩整个batch
a、snappy:google开发的,压缩率高,且对内存和cpu的使用率低
b、gzip:压缩效率比snappy高,但cpu使用率也高
4、retries
重试次数
5、batch.size
满足条件时,会发送batch
6、linger.time
满足条件时,会发送batch
7、client.id
kafka用其统计数据
8、max.request.size
9、receive.buffer.bytes、send.buffer.bytes
tcp的socket大小
10、自定义partition分配策略:props.put("partitioner.class", "com.share.producer.MyPartitioner");
五、consumer
(一)、consummer概念及逻辑图
1、概念:https://www.cnblogs.com/songanwei/p/9202803.html
注:消费者信息结构:Map
注:获取数据时(poll)返回的是一个集合
注:kafkaConsumer只允许一个线程获取数据,如果有多个会抛:KafkaConsumer is not safe for multi-threaded access
(二)、相关配置
1、需要将数据反序列化
org.apache.kafka.common.serialization.StringDeserializer
2、fetch.min.bytes
consumer一次至少找一个partition-leader要多少数据,数据不够就阻塞等待
3、fetch.max.wait.ms
一般与上一个参数共用,consumer找partition-leader要数据,最大的等待时间
4、max.partition.fetch.bytes
每个partition-leader最大返回的数据大小,默认是1m。比如一个consumer消费4个partition,那么records最大为4m
5、heartbeat.interval
consumer给coordinate(offset所在partition-leader所属的broker)发送心跳的时间间隔
6、session.timeout.ms
consumer与broker回话的超时时间,一般是heartbeat.interval的3倍
7、auto.offset.reset
props.put("auto.offset.reset","earliest");//没有这个配置,只能读partition中最新的数据。有了这个配置会读取partition中所有的数据,包括之前已读的
8、enable.auto.commit
是否自动提交,默认为true
9、auto.commit.interval.ms
客户端自己也维护了一个offset。默认多久将offset提交到broker,默认是5s一次
注:Runtime.getRuntime().halt(-1);---->默认将程序立即干掉,不会触发任何钩子程序(not wait for any running shutdown hooks or finalizers to finish their work)
10、partition.assignment.strategy
a、Range:kafka默认的方式。例:123,456
注:若有多个toptic,每个topic是独立分配的
b、RoundRobin:将partition分配的更加均匀。例:135,246
注:若想自己实现分配策略,需要自己实现PartitionAssignor,重写assign方法
11、client.id
可有可无,有的好处是broker日志中会有相应的标识,排查问题时比较容易
12、receive.buffer.bytes、send.buffer.bytes
tcp的socket大小
(三)commit offset
注:相当于一个producer将offest提交到toptic(_consummer.offset0~49)
1、同步的提交offset
props.put("enable.auto.commit","false");
kafkaConsumer.commitSync();
特点:retry、block
注:可恢复异常可以retry(如:commit超时),不可恢复异常不能retry(如:序列化或反序列化失败)
2、异步的提交offset
props.put("enable.auto.commit","false");
kafkaConsumer.commitAsync();
特点:no-retry、no-block
3、异步+同步提交offset【可以no-block的同时,异常时会retry】
try {
for(;;) {
//从toptic中获取数据
ConsumerRecords
//异步提交offset
kafkaConsumer.commitAsync();
}
} finally {
//同步的提交offset:当异步提交发生异常时,可以在这里retry
kafkaConsumer.commitSync();
}
4、提交指定位置的offset
Map
TopicPartition tp = new TopicPartition("test", 1);
OffsetAndMetadata om = new OffsetAndMetadata(12, "no metaData");
offset.put(tp, om);
kafkaConsumer.commitSync(offset);//提交指定位置的offset
六、custom serializer and deserialize
注:就是给producer和consumer定义数据的编解码协议
(一)serializer(producer需要)
1、implements Serializer
(二)deserializer(consummer需要)
1、implements Deserializer
七、custom interceptor
注:producer的send之前对message进行改变,consumer的poll之前判断是否是需要的message,即使是不需要的message,也会自动提交该message的offset
(一)producer-interceptor
MyProducerInterceptor implements ProducerInterceptor
props.put(INTERCEPTOR_CLASSES_CONFIG, "com.share.interceptor.MyComsumerInterceptor")
(二)consumer-interceptor
MyComsumerInterceptor implements ConsumerInterceptor
props.put(INTERCEPTOR_CLASSES_CONFIG, "com.share.interceptor.MyComsumerInterceptor");
八、kafka内部原理
1、brokers注册到zk,且各个broker的id唯一,
2、broker/ids:中的0,1,2是临时节点(ephemeral)。
3、controller:就是broker-leader(一般是谁先启动,谁先注册到zk,谁就是controller),会号召partition-leader的选举,该节点也是临时节点(ephemeral)
4、controller_epoch:解决分布式的脑裂问题,保证cluster中只有一个master发号施令
5、producer和consumer都是将请求发送到partition-leader,partition-follow仅仅同步leader的数据
6、LEO是Log End Offset的缩写,它表示了当前日志文件中下一条待写入消息的offset,如上图offset为9的位置即为当前日志文件LEO,LEO的大小相当于当前日志分区中最
后一条消息的offset值加1。分区ISR集合中的每个副本都会维护自身的LEO,而ISR集合中最小的LEO即为分区的HW,对消费这而言只能消费HW之前的消息。
7、LSO特指LastStableOffset。它具体与kafka的事物有关。消费端参数——isolation.level,这个参数用来配置消费者事务的隔离级别。字符串类型,“read_uncommitted”和“read_committed”,表示消费者所消费到的位置,如果设置为“read_committed",那么消费者就会忽略事务未提交的消息,既只能消费到LSO(LastStableOffset)的位置,默认情况下,”read_uncommitted",既可以消费到HW(High Watermak)的位置。
注:follower副本的事务隔离级别也为“read_uncommitted",并且不可修改。
注:LSO≤HW≤LEO
注:https://blog.csdn.net/lukabruce/article/details/101012815
8、request processing(没有用netty,而是直接对nio的封装),如图:
注:produce request、fetch request,这两种请求只能由partation-leader来处理,若不是则报:not a leader for partition
注:kafka不会收到一个请求就去做这件事,而是组成batch,一块处理
9、kafka中master的概念:
controller:选partition-leader和Isr,监听broker(ids、toptic)的变化,同步metadate给其他的broker(每个broker都有metadata的缓存)
partition-leader:处理produce request、fetch request
coordinate:(某个consumer-group的offset所在的partition,该partition的leader-partition所在的broker就是coordinate)选举consumer-leader
consumer-leader:给出reblance方案
九、文件存储
(一)physical storage
1、kafka存的是commit log
(二)file management
1、kafka根据文件大小及时间判断是否保留
2、kafka会将partition分成n个segment(根据segment的大小或创建时间)。一个segment1(inactive-segment)写够了会被close,然后开启一个新的segment2(active-segment)。被close的segment是可过期的(可以清理的),新打开的segment是不能被清理的。
(三)file format
1、查看toptic-partition-segment信息
cd /opt/app/kafka/data/kafka/test-0
bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files /opt/app/kafka/data/kafka/test-0/00000000000000000000.log
内容格式如下:
offset: 12 position: 502 CreateTime: 1597232798406 isvalid: true payloadsize: 8 magic: 1 compresscodec: NONE crc: 1178879940 keysize: 1
(四)Indexes
数据的索引:00000000000000000000.index
(五)Compaction
inactive-segment日志压缩配置:log.cleaner.enabled=true
注:active-segment日志不能被压缩
十、推荐文档
1、consumer-group
2、ISR、AR、HW、LEO、LSO、LW的含义详解
3、kafka-controller