机器学习常用算法原理及优缺点
KNN
核心思想是:
物以类聚,人以群分
根据两点距离公式,计算距离,选择距离最小的前k个点,并返回分类结果。
假设一个未知样本数据x需要归类,总共有ABC三个类别,那么离x距离最近的有k个邻居,这k个邻居里有k1个邻居属于A类,k2个邻居属于B类,k3个邻居属于C类,如果k1>k2>k3,那么x就属于A类,也就是说x的类别完全由邻居来推断出来
算法步骤为:
1、计算测试对象到训练集中每个对象的距离
2、按照距离的远近排序
3、选取与当前测试对象最近的k的训练对象,作为该测试对象的邻居
4、统计这k个邻居的类别频率
5、k个邻居里频率最高的类别,即为测试对象的类别
KNN算法的优缺点
1、优点
非常简单的分类算法没有之一,人性化,易于理解,易于实现
适合处理多分类问题,比如推荐用户
2、缺点
属于懒惰算法,时间复杂度较高,因为需要计算未知样本到所有已知样本的距离
样本平衡度依赖高,当出现极端情况样本不平衡时,分类绝对会出现偏差
可解释性差,无法给出类似决策树那样的规则
向量的维度越高,欧式距离的区分能力就越弱
逻辑回归
1.1 什么是逻辑回归
逻辑回归(LR)名义上带有“回归”字样,第一眼看去有可能会被以为是预测方法,其实质却是一种常用的分类模型,主要被用于二分类问题,它将特征空间映射成一种可能性,在LR中,y是一个定性变量{0,1},LR方法主要用于研究某些事发生的概率。
假定有一个二分类问题,输出y∈{0,1}y∈{0,1},线性回归模型(公式1.1.1)
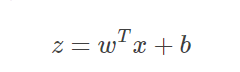
SigmoidFunctionSigmoidFunction(公式1.1.2):
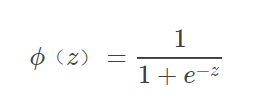
优点:
实现简单,广泛的应用于工业问题上;
速度快,适合二分类问题
简单易于理解,直接看到各个特征的权重
能容易地更新模型吸收新的数据
对逻辑回归而言,多重共线性并不是问题,它可以结合L2正则化来解决该问题;
缺点:
- 对数据和场景的适应能力有局限性,不如决策树算法适应性那么强。
- 当特征空间很大时,逻辑回归的性能不是很好;
- 容易欠拟合,一般准确度不太高
- 不能很好地处理大量多类特征或变量;
- 只能处理两分类问题(在此基础上衍生出来的softmax可以用于多分类),且必须线性可分,对于非线性特征,需要进行转换;
- 使用前提: 自变量与因变量是线性关系。
- 只是广义线性模型,不是真正的非线性方法
朴素贝叶斯
朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法。
对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。
– 概率模型
– 基于贝叶斯原理
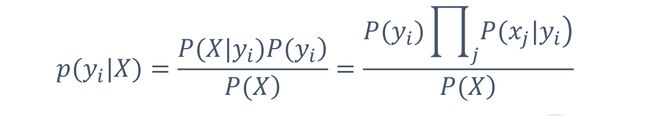
• P(X):待分类对象自身的概率,可忽略
• P(yi):每个类别的先验概率,如P(军事)
• P(X|yi):每个类别产生该对象的概率
• P(xi|yi):每个类别产生该特征的概率,如P(苹果|科技)
例子:
1 病人分类的例子让我从一个例子开始讲起,你会看到贝叶斯分类器很好懂,一点都不难。
某个医院早上收了六个门诊病人,如下表截图。

现在又来了第七个病人,是一个打喷嚏的建筑工人。请问他患上感冒的概率有多大?
根据贝叶斯定理:

可得:

假定"打喷嚏"和"建筑工人"这两个特征是独立的,因此,上面的等式就变成了:

这是可以计算的:
因此,这个打喷嚏的建筑工人,有66%的概率是得了感冒。同理,可以计算这个病人患上过敏或脑震荡的概率。
比较这几个概率,就可以知道他最可能得什么病。
这就是贝叶斯分类器的基本方法:在统计资料的基础上,依据某些特征,计算各个类别的概率,从而实现分类。
• 优点:
– 简单有效
– 结果是概率,对二值和多值同样适用
• 缺点:
– 朴素贝叶斯假设属性之间相互独立,这种假设在实际过程中往往是不成立的。在属性之间相关性越大,分类误差也就越大。
决策树
决策树种类:
分类树–对离散变量做决策树,衡量标准最大熵——预测分类标签值
回归树–对连续变量做决策树, 衡量标准是最小化均方差——预测实际数值
著名算法:
– ID3
– C4.5
在决策树算法中,ID3基于信息增益作为属性选择的度量, C4.5基于信息增益率作为属性选择的度量, CART基于基尼指数作为属性选择的度量
-
ID3算法:基于信息增益作为属性选择的度量
信息熵是信息论里面的概念,是信息的度量方式,不确定度越大或者说越混乱,熵就越大。
在ID3中选择熵减少程度最大的特征来划分数据(贪心),也就是“最大信息熵增益”原则。
步骤: -
求不同属性的平均信息期望
-
求不同属性的信息增益
-
从所有属性中选择信息增益最大的作为根节点或者内部节点
缺点:
– 倾向于挑选属性值较多的属性,有些情况可能不会提供太多有价值的信息
• 贪婪性
• 奥卡姆剃刀原理:尽量用较少的东西做更多的事
– 不适用于连续变量
原因:
信息增益反映的给定一个条件以后不确定性减少的程度,必然是分得越细的数据集确定性更高,也就是条件熵越小,信息增益越大 -
C 4 . 5算法:基于信息增益率作为属性选择的度量
• 相对于ID3:
– 克服了用信息增益选择属性时偏向选择取值多的属性的不足
– 支持连续变量
停止条件:
• 信息增益(比例)增长低于阈值,则停止
– 阈值需要调校
• 将数据分为训练集和测试集
– 测试集上错误率增长,则停止
• 没有用全部样本训练
决策树优缺点
优点:
1、易于理解和解释,可以可视化分析,容易提取出规则。
2、计算量相对不是很大
3、可以处理连续和种类字段
4、可以清晰的显示哪些字段比较重要(这一特性可以用于特征选择)
缺点:
(1)对于各类别样本数量不一致的数据, 在决策树中,进行属性划分时,不同的判定准则会带来不同的属性选择倾向,信息增益偏向于那些更多数值的特征
(2)容易过拟合但是随机森林可以很大程度上减少过拟合。
(3)容易忽略数据集中属性的相互关联。
(4)不支持在线学习,于是在新样本到来后,决策树需要全部重建
集成思想(Ensemble Learning)
• Bagging
代表:随机森林
– 对训练数据采样,得到多个训练集,分别训练模型
– 对得到的多个模型进行平均
• 分类问题:投票方式进行集成
• 回归问题:模型的输出进行平均
Bagging Method:
• 带放回采样
– 可能将一个样本采样多次
• 算法:
– 输入n个训练样本
– 循环M轮,每轮:
• 对样本进行带放回采样
• 根据采样得到的训练样本训练一个基准模型
• 适合:
– 弱分类器:
• 不稳定:随机采样会得到较不同的分类器
• 每个基分类器准确率略高于50%
• 例如:决策树
• 不适合
– 强分类器
• 稳定:随机采样对结果影响不大
• 反而可能不如不集成
– 每个基分类器只有更少的训练样本
• Boosting
代表:Adaboost、GBDT
– 对训练数据集进行采样,对错分样本加权采样
– 多个模型按照分类效果加权融合
Boosting集成
– 每个基分类器,基于之前的分类结果
• 已经分对的样本不用太多关心
• 集中力量对付分错样本
– 不等权投票
• 好的基分类器权重大
Boosting方法两类思想
– 传统Boost→ Adaboost:对正确、错分样本加权,每步的迭代,错误样本加权,正确样本降权
– Gradient Boosting:每次建模建立在之前模型损失函数的梯度下降方向
随机森林
Random Forest = Bagging + 决策树
随机森林生成方法:
– 从样本集中通过重采样的方式产生n个样本
– 建设样本特征数目为a,对n个样本选择a中的k个特征,用建立决策树的方式获得最佳分割点
– 重复m次,产生m棵决策树
– 多数投票机制进行预测
Random优点:
– 训练速度快、容易实现并行
– 训练完成后,反馈哪些是重要特征
– 抗过拟合能力强
– 可解决分类、回归问题
– 不平衡数据集,rf是平衡误差有效方法
Random缺点:
– 取值较多的属性,影响大
– 噪音大的分类、回归问题会过拟合
– 只能尝试参数和种子的选择,无法洞悉内部
AdaBoost( Adaptive Boosting 自适应增强)
思想:
– 训练多个基分类器
– 在带权重样本上训练基分类器,以前错分的样本权重大,分对的权重小
– 基分类器根据性能加权投票
AdaBoost( Adaptive Boosting 自适应增强)算法:
– 1、给数据中的每一个样本一个权重
– 2、训练数据中的每一个样本,得到第一个分类器
– 3、计算该分类器的错误率,根据错误率计算要给分类器分配的权重(注意这里是分类器的权重)
– 4、将第一个分类器分错误的样本权重增加,分对的样本权重减小(注意这里是样本的权重)
– 5、然后再用新的样本权重训练数据,得到新的分类器,到步骤3
– 6、直到步骤3中分类器错误率为0,或者到达迭代次数
– 7、将所有弱分类器加权求和,得到分类结果(注意是分类器权重)
优点
1、很好的利用了弱分类器进行级联。
2、可以将不同的分类算法作为弱分类器。
3、AdaBoost具有很高的精度。
4、相对于bagging算法和Random Forest算法,AdaBoost充分考虑的每个分类器的权重。
缺点
1、AdaBoost迭代次数也就是弱分类器数目不太好设定,可以使用交叉验证来进行确定。
2、数据不平衡导致分类精度下降。
3、训练比较耗时,每次重新选择当前分类器最好切分点。
GDBT( Gradient Boosting Decision Tree )
是一种迭代的决策树算法,该算法由多棵决策树组,所有树的结论累加起来做最终答案
三个概念组成:
– Regression Decistion Tree(DT、RT)
– Gradient Boosting(GB)
– Shrinkage(步长)
GBDT中的树,属于回归树,不是分类树
– 要求所有树的结果进行累加是有意义的
– GBDT是结果累加,而不是多数投票
GBDT核心:
– 每一棵树学的是之前所有树结论和的残差
– 残差就是一个加预测值后能得真实值的累加量
Shrinkage(缩减)
• 思想:每棵树只学到了真理的一小部分,累加的时候只累加一小部分,通过多学几棵树弥补不足
优点:
1、它能灵活的处理各种类型的数据;
2、在相对较少的调参时间下,预测的准确度较高。
缺点:
由于它是Boosting,因此基学习器之前存在串行关系,难以并行训练数据。