概述
如果你用过Uber,你一定会注意到它的操作是如此的简单。你一键叫车,随后车就来找你了,最后自动完成支付,整个过程行云流水。但是,在这简单的流程背后其实是用Hadoop和Spark这样复杂的基础大数据架构来支撑的。
Uber 在现实世界和虚拟世界的十字路口有令人羡慕的一席之地。这令每天在各个城市穿行的数十万司机大军趋之若鹜。当然这也会一个相对浅显的数据问题。但是,就像Uber数据部门的主管 Aaron Schildkrout所说:商业计划的简单明了带给Uber利用数据优化服务的巨大机会。
“这本质上来说是一个数据问题”,Schildkrout 最近在一个Uber和Databricks的演讲记录中说道。“因为事情是如此浅显,我们想让用车体验变得自动化。在某种程度上,我们正在尝试为全世界的载客司机提供智能、自动化、实时的服务并且支撑服务的规模化。”
不论是Uber在峰时计价、帮助司机规避事故还是为司机寻找最优盈利位置,这一切 Uber 的计算服务都依赖于的数据。这些数据问题是一道数学和全球目的地预测的真正结晶。他说:”这使得这里的数据非常振奋人心,也驱动我们斗志昂扬地用Spark解决这些问题”
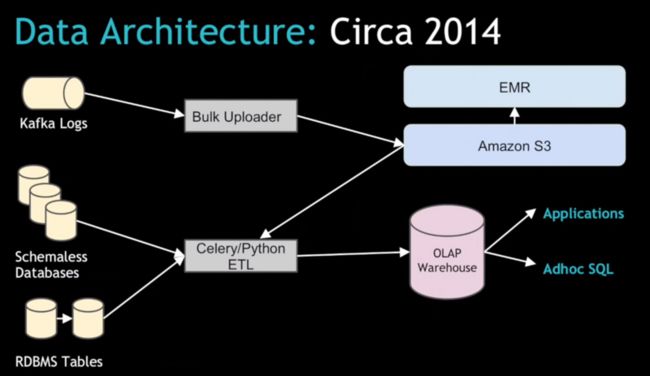
Uber 的大数据之道
在Data bricks的演讲中,Uber 工程师描述了(显然是首次公开演讲)一些在应用扩展和满足需求上公司遇到的挑战。
作为负责Uber 数据架构的总负责人,Vinoth Chandar说道:Spark 已经是”必备神器了”。
在旧的架构下,Uber依赖于Kafka的数据流将大量的日志数据传输到AWS的S3上,然后使用EMR来处理这些数据。然后再从EMR导入到可以被内部用户以及各个城市总监使用的关系型数据库中。
Chandar说道:”原来的 Celery+Python的ETL架构其实运转得挺好的,但是当Uber想要规模化时就遇到了一些瓶颈”。随着我们扩展的城市越来越多,这个数据规模也不断增加,在现有的系统上我们遇到了一系列的问题,尤其是在数据上传的批处理过程。
Uber 需要确保最重要的数据集之一的行程数据,这里成百上千的真实准确的消费记录将会影响到下游的用户和应用。Chandar 说道:”这个系统原来并不是为了多数据中心设计的。我们需要用一系列的融合方式将数据放到一个数据中心里面。”
解决方案演化出了一个所谓的基于Spark的流式IO架构,用来取代之前的Celery/Python ETL 架构。新系统从关系型数据仓库表模型将原始数据摄取做了必要的解耦。Chandar说:”你可以在HDFS上获取数据然后再依赖于一些像Spark这样的工具来处理大规模的数据处理。”
因此,取而代之的是在一个关系模型中从多个分布式数据中心聚合行程数据,公司新的架构使用Kafka从本地数据中心来提供实时数据日志,并且加载他们到中心化的Hadoop集群中。接着,系统用Spark SQL 将非结构化的JSON转化为更加结构化的可以使用Hive来做SQL分析的Parquet文件。
他说:”这解决了一系列我们遇到的额外问题,而且我们现在处在一个利用Spark和Spark Streaming 将系统变得长期稳定运行的节点上。我们也计划从访问和获取原始数据也都用Spark任务、Hive、机器学习以及所有有趣的组件,将Spark的潜能彻底释放出来。”
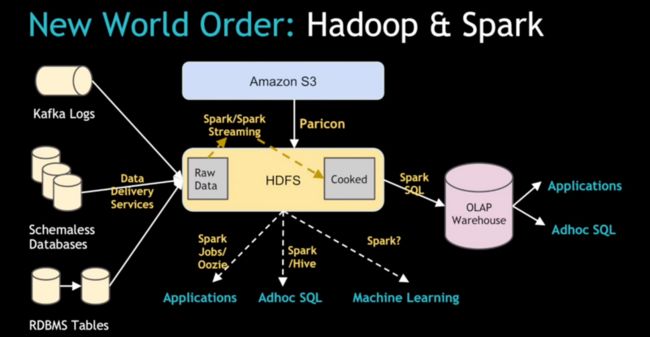
Paricon 和 Komondor
在 Chandar 给出了 Uber 涉险进入Spark的概况之后,另外两名 Uber 工程师,Kelvin Chu 和 Reza Shiftehfar 提供了关于 Paricon 和 Shiftehfar 的更多细节。而这其实是Uber 进军Spark的两个核心项目。

虽然非结构化数据可以轻松搞定,Uber最终还是需要通过数据管道生成结构化数据,因为结构化数据在数据生产者和数据使用者之间生成的”契约”可以有效避免”数据破损”。
这就是为什么Parino 会进入这个蓝图,Chu说道,Parino 这个工具是由4个 Spark为基础的任务组成的:转移、推断、转化并且验证。”因此不论谁想要改变这个数据结构,他们都将进入这个系统,并且必须使用我们提供的工具来修改数据结构。然后系统将运行多个验证和测试来确保这个改变不会有任何问题。”
Paricon 的一大亮点是所谓的”列式剪枝”。我们有许多宽表,但是通常我们每次都不会用到所有的列,因此剪枝可以有效节约系统的IO。他说道:”Paricon 也可以处理一些”数据缝合”工作。一些Uber的数据文件很大,但是大多数都是比HDFS区块来得小的,因此我司将这些小数据缝合在一起对齐HDFS文件大小并且避免IO的运转失常。加之Spark的”数据结构聚合”功能也帮助我们用Paricon 工作流工具直观简化的方式处理Uber数据。”
与此同时, Shiftehfar 为Komondor、Spark Streaming内建的数据摄取服务提供了架构级别的诸多细节。而数据源是”烹饪”的基础,原始非结构数据从Kafka流入HDFS然后准备被下游应用消费。

在 Komondor 之前,它是用来为每个独立应用确保数据准确性的工具(包括获取他们正在处理的数据的上游数据)并且在必要的时候做数据备份。现在通过 Komondor 可以自动处理或多或少的数据。如果用户需要加载数据,使用 Spark Streaming 就相对简单得多。

为了处理每天百万级的事件和请求正在重金投入 Spark 并且打算撬动更多的 Spark技术栈,包括使用MLib和GraphX库做机器学习和图计算。更多细节,可以观看下面演讲的整个视频。
Spark and Spark Streaming at Uber
参考资料
相关阅读
英文原文作者: Alex Woodie 译者: Harry Zhu
英文原文地址: http://www.datanami.com/2015/10/05/how-uber-uses-spark-and-hadoop-to-optimize-customer-experience/
更优阅读体验可直接访问译文地址:https://segmentfault.com/a/1190000005174590
作为分享主义者(sharism),本人所有互联网发布的图文均遵从CC版权,转载请保留作者信息并注明作者 Harry Zhu 的 FinanceR专栏:https://segmentfault.com/blog/harryprince,如果涉及源代码请注明GitHub地址:https://github.com/harryprince。微信号: harryzhustudio
商业使用请联系作者。