声明:作者原创,转载注明出处。作者:帅气陈吃苹果
一、环境准备
1、JDK安装与配置
2、Eclipse下载
下载解压即可,下载地址:https://pan.baidu.com/s/1i51UsVN
3、Hadoop下载与配置
下载解压即可,下载地址:https://pan.baidu.com/s/1i57ZXqt
配置环境变量:
在系统变量中新建变量:HADOOP_HOME,值:E:Hadoophadoop-2.6.5
在Path系统变量中添加Hadoop的/bin路径,值:E:Hadoophadoop-2.6.5bin
4、正常的集群状态
确保集群处于启动状态,并且windows本地机器与集群中的master可以互相ping通,并且可以进行SSH连接;
在 C:WindowsSystem32driversetchosts文件中,追加Hadoop集群master节点的IP地址和主机名映射,如下:
192.168.29.188 vnet
5、Eclipse-Hadoop插件下载
下载地址:https://pan.baidu.com/s/1o7791VG
下载后将插件放在Eclipse安装目录的plugins目录下,重启Eclipse即可。
6、Eclipse的Map/Reduce视图设置
1)重启Eclipse后,在左侧栏可以看到此视图:
打开Window--->Perspective--->Open Perspective--->Other...,选择Map/Reduce。若没有看到此选项,在确保插件放入plugins目录后已经重启的情况下,猜测可能是Eclipse或插件的版本问题导致,需重新下载相匹配的版本。
https://i.imgur.com/Twag1wi.p...; />
2)打开Window--->Preferences--->Hadoop Map/Reduce,配置Hadoop的安装目录。
https://i.imgur.com/1jCAkYr.p...; />
二、WordCount项目实战
1、Hadoop Location的创建与配置
在Eclipse底部栏中选择Map/Reduce Locations视图,右键选择New Hadoop Locations,如下图:
https://i.imgur.com/NPaZQXL.p...; />
具体配置如下:
https://i.imgur.com/vDAsRBj.p...; />
点击finish,若没有报错,则表示连接成功,在Eclipse左侧的DFS Locations中可以看到HDFS文件系统的目录结构和文件内容;
若遇到 An internal error occurred during: "Map/Reduce location status updater". java.lang.NullPointerExcept 的问题,则表示当前HDFS文件系统为空,只需在HDFS文件系统上创建文件,刷新DFS Locations后即可看到文件系统内容;
2、创建输入文件及目录
在master节点上创建输入文件,并上传到HDFS对应的输入目录中,如下:
vi input.txt //然后输入单词计数的文件内容,保存
hdfs dfs -put input.txt /user/root/input/ //将Linux本地文件系统的文件上传到HDFS上input.txt
hello world
hello hadoop
bye
bye hadoop3、创建Map/Reduce项目
File--->New--->Project--->Map/Reduce Project,填入项目名称,还需要选择Hadoop Library的路径,这里选择“Use default Hadoop”即可,就是我们之前在Eclipse中配置的Hadoop。
WordCount.java代码:
package com.wecon.sqchen;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class WordCount {
public static class WordCountMap extends
Mapper {
private final IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer token = new StringTokenizer(line);
while (token.hasMoreTokens()) {
word.set(token.nextToken());
context.write(word, one);
}
}
}
public static class WordCountReduce extends
Reducer {
public void reduce(Text key, Iterable values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
System.setProperty("hadoop.home.dir","E:/Hadoop/hadoop-2.6.5" );
Configuration conf = new Configuration();
Job job = new Job(conf);
job.setJarByClass(WordCount.class);
job.setJobName("wordcount");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(WordCountMap.class);
job.setReducerClass(WordCountReduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
右键打开Run AS ---> Run Configurations,配置Arguments,即程序中指定的文件输入目录和输出目录,如下:
https://i.imgur.com/pFqvNr2.p...; />
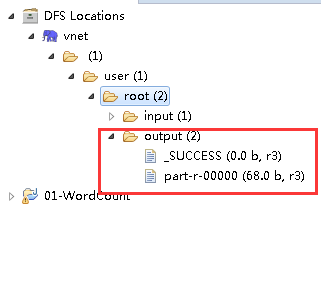
配置好后,Run AS---> Java Application,若无报错,则表示程序执行成功,在Eclipse左侧的
DFS Locations刷新后,可以看到输出目录和输出文件,如下:
4、解决遇到的问题
1)java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
解决方式:
在main方法中、job提交之前,指定本地Hadoop的安装路径,即添加下列代码:System.setProperty("hadoop.home.dir","E:/Hadoop/hadoop-2.6.5" );
2)`(null) entry in command string: null chmod 0700 E:tmphadoop-Administratormapredstaging
Administr`
解决方式:
参考链接:https://ask.hellobi.com/blog/...
链接中所需文件下载地址:https://pan.baidu.com/s/1i4Z4aVV
3)org.apache.hadoop.security.AccessControlException: Permission denied: user=Administrator, access=WRITE, inode="/user/root":root:supergroup:drwxr-xr-x
解决方式:
这是本地用户执行Application时,HDFS上的用户权限问题;
参考链接:http://blog.csdn.net/Camu7s/a...
采用第三种方法,在master节点机器上执行下列命令:
adduser Administrator
groupadd supergroup
usermod -a -G supergroup Administrator4)org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://vnet:9000/user/root/output already exists
解决方式:
这是因为该项目的输出目录在HDFS中已经存在,而输出目录是在程序运行过程中创建的,不允许提前存在,所以只需删除HDFS上的对应output目录即可。
5)
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.
MutableMetricsFactory).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.解决方式:
在项目的src目录下,New--->Other--->General--->File,创建文件“log4j.properties”,文件内容如下:
log4j.rootLogger=WARN, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n5、参考链接:
http://blog.csdn.net/bd_ai_io...
http://blog.csdn.net/songchun...