TensorRT5,TensorRT6不兼容pytorch1.2,1.3,1.4导出的ONNX模型解决方案
特别注意,onnx-tensorrt项目目前发布了几个版本
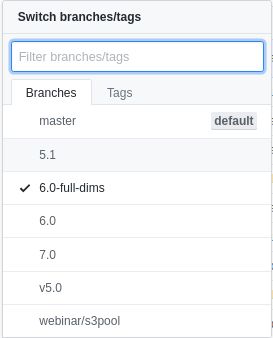
TensorRT5对应的版本是5.1,TensorRT6对应的版本是6.0而不是6.0-full-dims,6.0-full-dims支持的是早期发布的tensorrt7.0测试版,同时也支持tensorrt7.0正式版(我没有找到下载源,但是用tensorrt7.0正式版编译测试通过了),7.0对应的是tensorrt7.0正式版。
错误点
使用pytorch1.2,1.3导出的ONNX模型,如下面这个resnet18的代码:
import torch
import torch.nn as nn
import math
dummy_input = torch.randn(10, 3, 224, 224, device='cuda')
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000):
self.inplanes = 64
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AvgPool2d(7, stride=1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
#x = x.view([int(x.size(0)), -1])
x = x.flatten(1)
x = self.fc(x)
return x
def resnet18(pretrained=False, **kwargs):
"""Constructs a ResNet-18 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(BasicBlock, [2, 2, 2, 2], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet18']))
return model
model = resnet18(pretrained=False).cuda()
# Providing input and output names sets the display names for values
# within the model's graph. Setting these does not change the semantics
# of the graph; it is only for readability.
#
# The inputs to the network consist of the flat list of inputs (i.e.
# the values you would pass to the forward() method) followed by the
# flat list of parameters. You can partially specify names, i.e. provide
# a list here shorter than the number of inputs to the model, and we will
# only set that subset of names, starting from the beginning.
input_names = [ "actual_input_1" ] + [ "learned_%d" % i for i in range(16) ]
output_names = [ "output1" ]
torch.onnx.export(model, dummy_input, "resnet.onnx", verbose=True, opset_version=8, input_names=input_names, output_names=output_names)
使用TensorRT5或者TensorRT6就会报这个错误,需要特别注意的是TensorRT7没有这个错误:
./trtexec --onnx=/home/shining/work/Optimization/maskrcnn-benchmark/demo/resnet.onnx --saveEngine=/home/shining/work/Optimization/maskrcnn-benchmark/demo/test.trt
&&&& RUNNING TensorRT.trtexec # ./trtexec --onnx=/home/shining/work/Optimization/maskrcnn-benchmark/demo/resnet.onnx --saveEngine=/home/shining/work/Optimization/maskrcnn-benchmark/demo/test.trt
[I] onnx: /home/shining/work/Optimization/maskrcnn-benchmark/demo/resnet.onnx
[I] saveEngine: /home/shining/work/Optimization/maskrcnn-benchmark/demo/test.trt
----------------------------------------------------------------
Input filename: /home/shining/work/Optimization/maskrcnn-benchmark/demo/resnet.onnx
ONNX IR version: 0.0.4
Opset version: 8
Producer name: pytorch
Producer version: 1.2
Domain:
Model version: 0
Doc string:
----------------------------------------------------------------
WARNING: ONNX model has a newer ir_version (0.0.4) than this parser was built against (0.0.3).
[I] Engine has been successfully saved to /home/shining/work/Optimization/maskrcnn-benchmark/demo/test.trt
[I] Average over 10 runs is 2.11649 ms (host walltime is 2.29903 ms, 99% percentile time is 4.69494).
[I] Average over 10 runs is 1.83926 ms (host walltime is 2.16407 ms, 99% percentile time is 1.86864).
[I] Average over 10 runs is 1.85446 ms (host walltime is 2.00289 ms, 99% percentile time is 1.9159).
[I] Average over 10 runs is 1.86921 ms (host walltime is 2.02806 ms, 99% percentile time is 1.9281).
[I] Average over 10 runs is 1.6989 ms (host walltime is 2.01449 ms, 99% percentile time is 1.91136).
[I] Average over 10 runs is 1.59095 ms (host walltime is 1.89619 ms, 99% percentile time is 1.66589).
[I] Average over 10 runs is 1.57186 ms (host walltime is 1.77435 ms, 99% percentile time is 1.59123).
[I] Average over 10 runs is 1.58843 ms (host walltime is 1.78037 ms, 99% percentile time is 1.65168).
[I] Average over 10 runs is 1.57083 ms (host walltime is 1.81921 ms, 99% percentile time is 1.58486).
[I] Average over 10 runs is 1.58289 ms (host walltime is 1.86758 ms, 99% percentile time is 1.62566).
&&&& PASSED TensorRT.trtexec # ./trtexec --onnx=/home/shining/work/Optimization/maskrcnn-benchmark/demo/resnet.onnx --saveEngine=/home/shining/work/Optimization/maskrcnn-benchmark/demo/test.trt
(base) ➜ bin ./trtexec --onnx=/home/shining/work/Optimization/maskrcnn-benchmark/demo/resnet.onnx --saveEngine=/home/shining/work/Optimization/maskrcnn-benchmark/demo/test.trt
&&&& RUNNING TensorRT.trtexec # ./trtexec --onnx=/home/shining/work/Optimization/maskrcnn-benchmark/demo/resnet.onnx --saveEngine=/home/shining/work/Optimization/maskrcnn-benchmark/demo/test.trt
[I] onnx: /home/shining/work/Optimization/maskrcnn-benchmark/demo/resnet.onnx
[I] saveEngine: /home/shining/work/Optimization/maskrcnn-benchmark/demo/test.trt
----------------------------------------------------------------
Input filename: /home/shining/work/Optimization/maskrcnn-benchmark/demo/resnet.onnx
ONNX IR version: 0.0.4
Opset version: 8
Producer name: pytorch
Producer version: 1.3
Domain:
Model version: 0
Doc string:
----------------------------------------------------------------
WARNING: ONNX model has a newer ir_version (0.0.4) than this parser was built against (0.0.3).
While parsing node number 0 [Conv]:
ERROR: ModelImporter.cpp:288 In function importModel:
[5] Assertion failed: tensors.count(input_name)
[E] failed to parse onnx file
[E] Engine could not be created
[E] Engine could not be created
&&&& FAILED TensorRT.trtexec # ./trtexec --onnx=/home/shining/work/Optimization/maskrcnn-benchmark/demo/resnet.onnx --saveEngine=/home/shining/work/Optimization/maskrcnn-benchmark/demo/test.trt
简言之就是:
Assertion failed: tensors.count(input_name)
错误原因
For the assertion failure, I checked the ModelImport.cpp. I assume it’s because the code finds that one of the nodes have 0 input? Though I checked the graph of my model, don’t think that’s the case.
for( size_t node_idx : topological_order ) {
_current_node = node_idx;
::ONNX_NAMESPACE::NodeProto const& node = graph.node(node_idx);
std::vector<TensorOrWeights> inputs;
for( auto const& input_name : node.input() ) {
ASSERT(tensors.count(input_name), ErrorCode::kINVALID_GRAPH);
inputs.push_back(tensors.at(input_name));
}
// ...
}
On a separate note, have you run the onnx checker after exporting?
import onnx
onnx.checker.check_model(onnx_model)
The checker threw a warning for me:
Nodes in a graph must be topologically sorted, however input 'conv2d_31_Relu_0' of node:
input: "conv2d_31_Relu_0" output: "transpose_output7" name: "Transpose21" op_type: "Transpose" attribute { name: "perm" ints: 0 ints: 2 ints: 3 ints: 1 type: INTS } doc_string: "" domain: ""
is not output of any previous nodes.
感谢https://github.com/pango99 提供解决方案
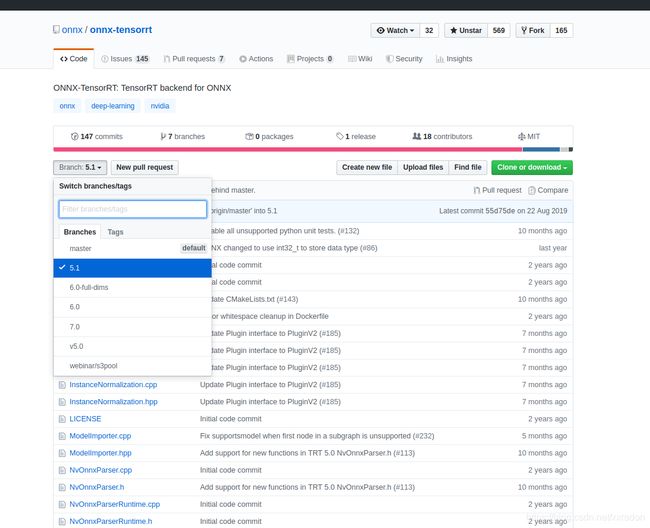
首先,进入https://github.com/onnx/onnx-tensorrt/tree/5.1下载源码(注意根据自己的tensorrt版本选择对应版本号的branch),修改onnx-tensorrt项目的ModelImport.cpp源码,然后根据源码提示进行编译。
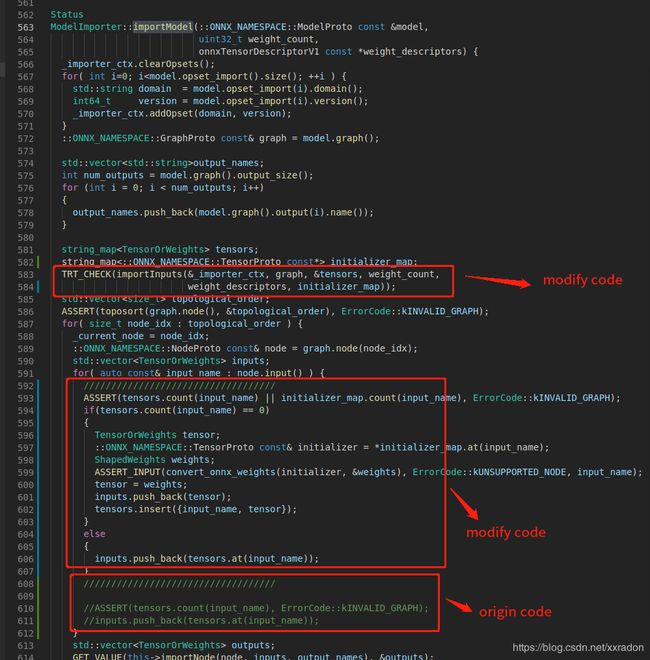
以下是修改过后的ModelImport.cpp源码:
/*
* Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
*
* Permission is hereby granted, free of charge, to any person obtaining a
* copy of this software and associated documentation files (the "Software"),
* to deal in the Software without restriction, including without limitation
* the rights to use, copy, modify, merge, publish, distribute, sublicense,
* and/or sell copies of the Software, and to permit persons to whom the
* Software is furnished to do so, subject to the following conditions:
*
* The above copyright notice and this permission notice shall be included in
* all copies or substantial portions of the Software.
*
* THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
* IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
* FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
* THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
* LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
* FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
* DEALINGS IN THE SOFTWARE.
*/
#include "ModelImporter.hpp"
#include "toposort.hpp"
#include "onnx_utils.hpp"
#include "onnx2trt_utils.hpp"
#include