YOLO Nano:一种高度紧凑的只看一次的卷积神经网络用于目标检测
Alexander Wong1,2, Mahmoud Famuori1,2, Mohammad Javad Shafiee1,2
Francis Li2, Brendan Chwyl2, and Jonathan Chung2
1Waterloo Artificial Intelligence Institute, University of Waterloo, Waterloo, ON, Canada
2DarwinAI Corp., Waterloo, ON, Canada
Abstract
目标检测仍然是计算机视觉领域的一个活跃研究领域,通过设计用于处理目标检测的深卷积神经网络,在这一领域取得了长足的进展和成功。尽管取得了这些成功,但在边缘和移动场景中广泛部署此类对象检测网络面临的最大挑战之一是高计算和内存需求。因此,针对边缘和移动应用的高效深层神经网络体系结构的设计越来越受到人们的关注。在本研究中,我们将介绍一种高度紧密的深度卷积神经网路YOLO Nano,来完成目标侦测的任务。利用人机协同设计策略创建YOLO Nano,其中基于YOLO系列单镜头目标检测网络架构的设计原则的原则性网络设计原型,与machinedriven设计探索相结合,创建一个具有高度定制模块级宏体系结构和为嵌入式对象检测任务定制的微体系结构设计的紧凑网络。所提出的YOLO Nano具有∼4.0MB的模型尺寸(分别比微小的YOLOv2和微小的YOLOv3小>15.1×和>8.3×),并且需要4.57B的操作进行推断(比微小的YOLOv2和微小的YOLOv3低>34%和∼17%,同时在VOC 2007数据集上仍然获得了69.1%的地图(分别比Tiny YOLOv2和Tiny YOLOv3高12%和10.7%)。在Jetson-AGX-Xavier嵌入式模块上进行了不同功耗下的推理速度和功耗效率实验,进一步证明了YOLO-Nano对嵌入式场景的有效性。
1 Introduction
计算机视觉领域中的一个活跃领域是目标检测,其目标不仅是在场景中定位感兴趣的对象,还为这些感兴趣的对象中的每一个指定一个类标签。最近在目标检测领域取得的相当大的成功来自于深度学习的现代进步[8,7],特别是利用深度卷积神经网络。最初的重点是提高准确性,导致越来越复杂的目标检测网络,如SSD[11]、R-CNN[2]、Mask R-CNN[3]和这些网络的其他扩展变体[6、9、18]。虽然这些网络展示了最先进的目标检测性能,但由于计算和内存限制,它们在边缘和移动设备上部署是非常具有挑战性的,甚至是不可能的。事实上,在嵌入式处理器上运行时,即使是更快的变体,如更快的R-CNN[15],在低的单位数帧速率下也有推断速度。这极大地限制了此类网络在无人机、视频监控、需要本地嵌入式处理的自动驾驶等广泛应用中的广泛应用。
为了解决实现嵌入式目标检测的这一挑战,人们对探索和设计更适合边缘和移动设备的高效目标检测深层神经网络体系结构越来越感兴趣[12、13、14、23、4、17]。特别有趣的预印本。正在审查中。arXiv:1910.01271v1[cs.CV]2019年10月3日围绕效率设计的对象检测网络家族是YOLO神经网络架构家族[12、13、14],它利用许多设计原则创建单点架构,可以在高端桌面gpu上实现嵌入式对象检测性能。然而,对于许多边缘和移动场景(例如,在YOLVO3架构的情况下,240MB),这些网络架构仍然太大,并且由于计算复杂度(例如,在YOLVO3的情况下,>65×B操作),它们的推理速度在边缘和移动处理器上运行时显著下降。为了解决这个问题,Redmon等人。介绍了网络体系结构的小YOLO家族,它以牺牲目标检测性能为代价大大减小了模型大小。
在本研究中,我们将探讨一种人机协同设计策略,以设计高度紧密的深卷积神经网路来进行目标侦测,其中原则性的网路设计原型与机器驱动的设计探索相结合。更具体地说,我们在这个人机协同设计策略中利用YOLO系列单镜头目标检测网络架构的设计原则来创建YOLO Nano,一个高度紧凑的网络,具有高度定制的模块级宏体系结构和为嵌入式对象检测任务定制的微体系结构设计。
2 Methods
在这项研究中,我们介绍了YOLO Nano,一种高度紧凑的深卷积神经网络,用于使用人机协同设计策略设计的嵌入式目标检测[21]。YOLO Nano的人机协同设计策略包括两个主要的设计阶段:一是原则性的网络设计原型,二是机器驱动的设计探索。
2.1原则性网络设计原型
创建YOLO Nano的第一个设计阶段是一个原则性的网络设计原型阶段,在这个阶段中,我们根据人类驱动的设计原则创建一个初始的网络设计原型(表示为ɕ),以指导机器驱动的设计探索阶段。更具体地说,我们构建了一个初始的网络设计原型,该原型基于YOLO系列单点架构的设计原则[12,13,14]。YOLO网络体系结构家族的一个突出特点是,与基于区域建议的网络不同,基于区域建议的网络依赖于构建区域建议网络来生成场景中对象所在位置的建议,然后对生成的建议进行分类,相反,它们利用单一的网络架构来处理输入图像并生成输出结果。因此,针对单个图像的所有目标检测预测都是在单个前向过程中进行的,而对于基于区域建议的网络,需要执行数百到数千个过程才能得到最终结果。这使得YOLO系列网络架构的运行速度大大加快,因此更适合于嵌入式对象检测。
本研究中使用的初始设计原型从YOLO网络体系结构家族中获得灵感,由一堆特征表示模块组成,模块之间的快捷连接如[14]。此外,与[14]一样,特征表示模块以类似于特征金字塔网络[10]的方式配置,使得其能够以三种不同的比例表示特征。这些特征表示模块后面跟着几个卷积层,其输出是一个三维张量,对三个不同尺度的包围盒、对象和类预测进行编码。因此,这种初始设计原型架构设计允许高效的多尺度目标检测。
最终YOLO Nano网络架构中各个模块和层的实际宏架构和微架构设计,以及网络模块的数量,留给机器驱动的设计探索阶段,以自动确定给定的数据以及设计的人为指定的设计要求和约束尤其是边缘和移动场景,计算和存储能力有限。
2.2机械驱动设计探索
利用最初的网络设计原型(ɕ)、数据以及满足边缘和移动使用的人类指定设计要求作为指导,然后利用机器驱动的设计探索阶段来确定所提议的YOLO Nano网络架构的模块级宏架构和微架构设计。更具体地说,本研究以生成性合成的形式实现了机器驱动的设计探索[22],它能够在人类指定的需求和约束条件下确定最终网络体系结构的最优宏体系结构和微体系结构设计。生成综合的总体目标是学习生成机器,生成满足设计要求和约束的深层神经网络,可以描述如下。这是在生成性的概念中形成的合成作为一个约束优化问题,用于确定给定一组种子S的发生器G,可以生成网络{NS’s s },最大化通用性能函数U(例如,(20)),同时满足通过指示器函数1R(·)定义的需求和约束:
![]()
由于求解方程1中约束优化问题的全局最优解是难以计算的,考虑到可行域的极大性,我们通过迭代优化来求解近似解G,其中初始解G0是由y、u和1r(·)引导的,并逐步更新。每一个近似的近似解GK比以前的近似解(即,G1,…)达到更高的U。…,ˆGk-1等),同时仍受1r(·)的约束。最后的近似解g,然后用于创建所提出的YOLO纳米网络。
引导生成合成过程学习生成机器,生成用于边缘和移动场景的对象检测网络,该网络不仅高效、紧凑,而且提供强大的对象检测性能,其中一个关键步骤是配置指示器功能1r(·),以实施适当的设计要求和约束。在本研究中,建立了指标函数1r(·):i)VOC 2007的平均精度(mAP)≥65%,ii)计算成本≤5B操作,以及iii)8位权重精度。计算成本约束的设置使得产生的YOLO-Nano网络的计算成本低于微型YOLOv3的计算成本[14],后者是用于嵌入式对象检测的最流行的紧凑型网络之一。
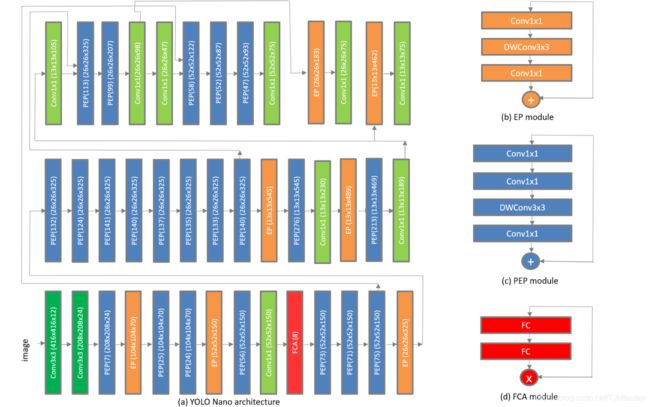
图1:YOLO Nano网络架构。注意,PEP(x)表示剩余PEP模块的第一投影层中的x个通道,FCA(x)表示x的压缩比
3Yolo Nano结构设计
图1显示了所提出的用于嵌入式对象检测的YOLO Nano网络的网络结构,下面有几个有趣的观察值得讨论。
3.1 Residual Projection-Expansion-Projection Macroarchitecture
关于YOLO Nano网络体系结构的第一个值得注意的观察是,它与YOLO网络家族显著不同,它由具有独特剩余投影扩展投影(PEP)宏体系结构的模块组成,此外还有扩展投影(EP)宏体系结构,如[16,19,1]中所述。剩余PEP宏结构包括:i)1×1卷积投影层,将输出信道投影到低维输出张量;ii)1×1卷积扩展层,将信道数扩展到高维,iii)深度卷积层,对来自扩展层的每个单独输出信道使用不同的滤波器执行空间卷积,以及iv)具有1×1卷积的投影层,其将输出信道投影到具有较低三维度的输出张量。剩余PEP宏体系结构的使用使得架构和计算复杂度显著降低,同时保持了模型的表达能力。
3.2全连接注意宏结构
关于YOLO Nano网络架构的第二个值得注意的观察是,通过机器驱动的设计探索过程,在网络中战略性地引入了轻量级全连接注意力(FCA),这与其他设计探索方法中的固定模块级引入不同[19]。与文献[5]一样,FCA宏体系结构由两个完全连接的层组成,这两个层学习信道之间的动态、非线性相互依赖关系,并产生调制权重,以便通过信道相乘重新加权信道。FCA的使用有助于基于全局信息的动态特性重新校准,从而更加关注信息特性,从而更好地利用可用的网络容量。这反过来又允许在减少的架构和计算复杂性和模型表达之间的很强的平衡。
3.3宏体系结构和微体系结构异构性
关于YOLO纳米网络体系结构的第三个值得注意的观察是,不仅在宏体系结构(PEP模块、EP模块、FCA以及单个3×3和1×1卷积层的不同组合)方面,而且在单个特征表示模块和层,网络中的每个模块或层具有唯一的微体系结构。在YOLO纳米网络体系结构中具有高的微体系结构异质性的好处是,它使网络体系结构的每个组件都被唯一地定制,以在体系结构和计算复杂度和模型表现性之间实现非常强的平衡。YOLO Nano中的这种体系结构多样性也证明了利用机械驱动的设计探索策略作为生成合成的灵活性是有利的,因为对于人类设计者来说是不可能的,或者其他设计探索方法如[19, 1 ]将网络体系结构定制到这一层次的体系结构粒度。
4实验结果与讨论
为了研究YOLO-Nano对嵌入式目标检测的有效性,我们在PASCAL-VOC数据集上测试了其模型大小、目标检测精度和计算成本。为了比较的目的,微YOLVO2网络〔13〕和微型YOLVO3网络〔14〕被用作基线参考,鉴于它们的小模型尺寸和低计算复杂度,它们是嵌入对象检测中最流行的紧凑型深度神经网络。VOC2007/2012数据集由20种不同类型的对象注释的自然图像组成。使用VOC2007/2012训练数据集训练深部神经网络,并根据VOC2007测试数据集计算平均精度(mAP),以评估深部神经网络的目标检测精度,这是研究文献中的标准做法。
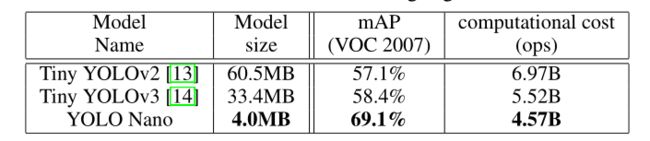
表1显示了所提出的YOLO纳米网络以及微小YOLOv2和微小YOLOv3的模型大小和目标检测精度。首先,我们观察到YOLO Nano的模型大小为4.0MB,分别比Tiny YOLOv2和Tiny YOLOv3小15.1×和8.3×以上,这对于考虑内存限制的边缘和移动场景非常重要。其次,YOLO Nano虽然模型尺寸小得多,但在VOC 2007测试数据集上实现了69.1%的映射,分别比Tiny YOLOv2和Tiny YOLOv3高出12%和10.7%。第三,YOLO Nano只需要45.7亿次运算就可以进行推断,比微小的YOLOv2低34%,比微小的YOLOv3低17%。
表1:VOC 2007测试集上测试的紧凑型网络的目标检测精度结果。所有被测网络的输入尺寸为416×416。最好的结果用粗体突出显示。
最后,为了研究YOLO Nano在嵌入式场景中的实际性能,我们评估了在Jetson AGX-Xavier嵌入式模块上运行的YOLO Nano在不同功率预算下的推理速度和功率效率。在15W和30W的功率预算下,YOLO Nano分别实现了26.9 FPS和48.2 FPS的推断速度,从而分别实现了1.97图像/秒/瓦和1.61图像/秒/瓦的功率效率。这些实验结果表明,提出的YOLO纳米网络,通过人机协同设计策略创建,提供了一个强大的平衡之间的准确性,大小和计算复杂度,使其非常适合嵌入式对象检测的边缘和移动场景。
References
[1] X. Chu, B. Zhang, R. Xu, and J. Li. Fairnas: Rethinking evaluation fairness of weight sharing neural
architecture search. arXiv preprint arXiv:1907.01845, 2019.
[2] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and
semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition,
pages 580–587, 2014.
[3] K. He, G. Gkioxari, P . Dollar, and R. Girshick. Mask r-cnn. ICCV, 2017.
[4] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam.
Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint
arXiv:1704.04861, 2017.
[5] J. Hu, L. Shen, S. Albanie, G. Sun, and E. Wu. Squeeze-and-excitation networks. IEEE TPAMI, 2019.
[6] J. Huang, V . Rathod, C. Sun, M. Zhu, A. Korattikara, A. Fathi, I. Fischer, Z. Wojna, Y . Song, S. Guadarrama,
et al. Speed/accuracy trade-offs for modern convolutional object detectors. In IEEE CVPR, 2017.
[7] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural
networks. In NIPS, 2012.
[8] Y . LeCun, Y . Bengio, and G. Hinton. Deep learning. Nature, 2015.
[9] T.-Y . Lin, P . Dollár, R. Girshick, K. He, B. Hariharan, and S. Belongie. Feature pyramid networks for
object detection. In CVPR, volume 1, page 4, 2017.
[10] T.-Y . Lin, P . Dollar, R. Girshick, K. He, B. Hariharan, and S. Belongie. Feature pyramid networks for
object detection. IEEE Conference on Computer Vision and Pattern Recognition, 2017.
[11] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y . Fu, and A. C. Berg. SSD: Single shot multibox
detector. In European conference on computer vision, pages 21–37. Springer, 2016.
[12] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi. Y ou only look once: Unified, real-time object detection.
In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 779–788, 2016.
[13] J. Redmon and A. Farhadi. YOLO9000: better, faster, stronger. arXiv preprint, 1612, 2016.
[14] J. Redmon and A. Farhadi. Y olov3: An incremental improvement. arXiv preprint arXiv:1804.02767, 2018.
[15] S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: Towards real-time object detection with region
proposal networks. In Advances in neural information processing systems, pages 91–99, 2015.
[16] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen. Mobilenetv2: Inverted residuals and
linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,
pages 4510–4520, 2018.
[17] M. J. Shafiee, B. Chywl, F. Li, and A. Wong. Fast YOLO: A fast you only look once system for real-time
embedded object detection in video. arXiv preprint arXiv:1709.05943, 2017.
[18] A. Shrivastava, A. Gupta, and R. Girshick. Training region-based object detectors with online hard example
mining. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages
761–769, 2016.
[19] M. Tan, B. Chen, R. Pang, V . V asudevan, and Q. V . Le. Mnasnet: Platform-aware neural architecture
search for mobile. arXiv preprint arXiv:1807.11626, 2018.
[20] A. Wong. Netscore: Towards universal metrics for large-scale performance analysis of deep neural
networks for practical usage. arXiv preprint arXiv:1806.05512, 2018.
[21] A. Wong, Z. Q. Lin, and B. Chwyl. Attonets: Compact and efficient deep neural networks for the edge via
human-machine collaborative design. arXiv preprint arXiv:1903.07209, 2019.
[22] A. Wong, M. J. Shafiee, B. Chwyl, and F. Li. Ferminets: Learning generative machines to generate efficient
neural networks via generative synthesis. Advances in neural information processing systems Workshops,
2018.
[23] B. Wu, F. Iandola, P . H. Jin, and K. Keutzer. Squeezedet: Unified, small, low power fully convolutional
neural networks for real-time object detection for autonomous driving. arXiv preprint arXiv:1612.01051,