android 显示系统初步总结
最近研究了一下android的显示系统,参考了一些文档,做一点简单的总结
1,废话不多说,先来一张 surfacefinger源码的source tree

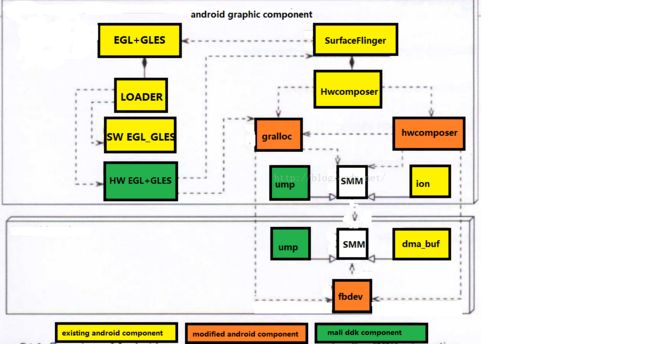
2,再上一张surfacefinger的组件图。(硬件平台是exynos CPU + MALI GPU)
3,名词解释
UMP :unified memory provider
这是由ARM定义的一种内存管理方式,主要用在Mali GPU
允许同一段内存被不同的进程空间映射。
这样可以共享内存,避免了内存的拷贝
最显著的应用,就是视频播放: OMX进程把解码后的数据放入到一段内存,surfacefilnger进程也共享这段内存,从而把这段内存的YUV数据,作为 openGL的纹理进行渲染
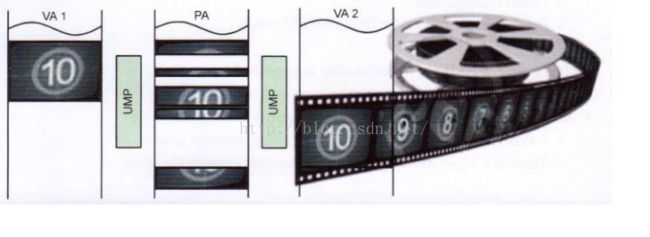
share memory management
framebufer driver
由app或者GPU在绘画的buffer,暂时还没有送到屏幕上
参考:http://blog.csdn.net/wan8180192/article/details/50269405
on-screen buffers:
数据就绪,可以直接拿来显示的buffer参考:http://blog.csdn.net/wan8180192/article/details/50719123
4,介绍一下几个底层模块
4.1 grallocgralloc是surfaceflinger向底层申请和维护graphic buffer的接口
使用共享内存来申请off-screen buffers
使用framebuffer内存来申请on-screen buffers
通过usage flag来设置buffer类型,例如GRALLOC_USAGE_HW_FB,GRALLOC_USAGE_HW_COMPOSER
gralloc也是surfaceflinger设置屏幕显示需要的物理参数的接口
初始化framebuffer 驱动的配置,例如colour depth, double buffering,screen size,
double buffering场景下,需要负责交换on-screen buffers
采用HWComposer类的形式体现给surfaceflinger,供上层使用
hwcomposer负责为surfaceflinger提供接口,来讲off-screen buffers中的内容,组合到on-screen buffers
采用HWComposer类的形式体现给surfaceflinger,供上层使用
能够声明自己的API版本号,这样上层就知道他的 capability
能够与gralloc互相交互,来访问off-screen buffers ,on-screen buffers
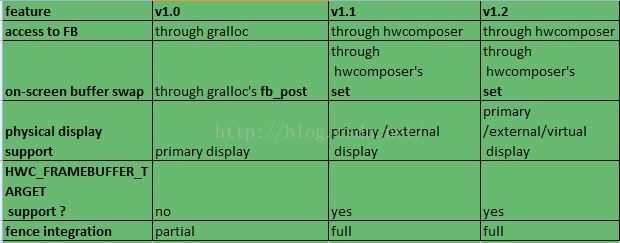
hwcomposer API capability 表格如下
Fence是一种同步机制,在Android里主要用于图形系统中GraphicBuffer的同步。那它和已有同步机制相比有什么特点呢?它主要被用来处理跨硬件的情况,尤其是CPU,GPU和HWC之间的同步,另外它还可以用于多个时间点之间的同步。GPU编程和纯CPU编程一个很大的不同是它是异步的,也就是说当我们调用GL command返回时这条命令并不一定完成了,只是把这个命令放在本地的command buffer里。具体什么时候这条GL command被真正执行完毕CPU是不知道的,除非CPU使用glFinish()等待这些命令执行完
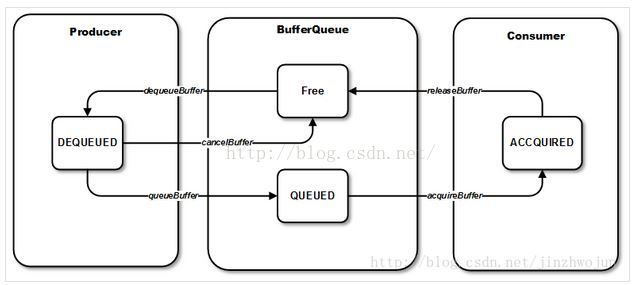
surfaceflinger使用bufferqueue来推送GraphicBuffer,bufferqueue有四种状态:dequeued,queued,free,accquired.但只指示了CPU里的状态,而GraphicBuffer的真正使用者是GPU。也就是说,当生产者把一个GraphicBuffer放入BufferQueue时,只是在CPU层面完成了归属的转移。但GPU说不定还在用,如果还在用的话消费者是不能拿去合成的。这时候GraphicBuffer和生产消费者的关系就比较暧昧了,消费者对GraphicBuffer具有拥有权,但无使用权,它需要等一个信号,告诉它GPU用完了,或者HWC用完了,消费者才真正拥有使用权。
这就是fence机制。所有的fence都是在kernel层实现的,androidHAL层只是把底层的一些接口的封装及扩展。
fence有好几类,它们有不同的作用,但几乎都是成对存在的。这里分析一下acquireFence 和 releaseFence
用来控制消费者消费时机。
禁止显示一个buffer的内容, 直到该fence被触发,触发表示这个buffer的生产者已经不在干预这个buffer了,消费者可以放心的使用了
如果这个graphicbuffer需要GPU来渲染,这个fence由生产者GPU驱动来创建。exynos平台上就是MALI DDK。当GPU渲染完成时,会触发acquireFence
surfaceflinger和hwcomposer会等待这个acquireFence,等到以后,才能读取buffer中的数据。
releaseFence:
用来控制生产者生产时机
这个Fence被触发,意味着属于这个layer的buffer已经不在被读取了,生产者可以放心的使用
由消费者surfaceflinger和hwcomposer来创建,当这个buffer被显示到屏幕上时,releaseFence被触发。
生产者GPU驱动Mali DDK 会等待这个fence被触发,然后才去渲染这个buffer
surfacefinger 通过BufferQueue来推送graphicbuffer
下面两个时机会向BufferQueue中queuebuffer:
buffer被GPU渲染完,或者APP写完,可以被hwcomposer合成的时候
buffer被被HWcomposer合成完,需要被显示的时候
下面两个时机会向BufferQueue中dequeuebuffer:
GPU需要渲染一个buffer,或者APP需要一个buffer时
HWcomposer需要一个buffer做合成时
4.5.1 ioctl api
screen information
double buffering
VSYNC
主要有 FBIOGET_FSCREENINFO,FBIOGET_VSCREENINFO,FBIOPUT_FSCREENINFO,FBIOPAN_DISPLAY,FBIO_WAITFORVSYNC,
4.5.2 buffermanagement
exynos平台上主要用了两种内存管理方式
UMP方式,这是由ARM定义的一种内存管理方式,主要用在Mali GPU
dma_buf+ion方式,这是google定义的一套方式。