DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现各种异构数据源之间高效的数据同步功能。最近,阿里云cassandra团队为datax提供了cassandra读写插件,进一步丰富了datax支持的数据源,可以很方便实现cassandra之间以及cassandra与其他数据源之间的数据同步。本文简单介绍如何使用datax同步cassandra的数据,针对几种常见的场景给出配置文件示例,还提供了提升同步性能的建议和实测的性能数据。
datax快速入门
使用datax同步数据的方法很简单,一共只需要三步:
- 部署datax。
- 编写同步作业配置文件。
- 运行datax,等待同步作业完成。
datax的部署和运行都很简单,可以通过datax官方提供的下载地址下载DataX工具包,下载后解压至本地某个目录,进入bin目录,即可运行同步作业:
$ cd {YOUR_DATAX_HOME}/bin
$ python datax.py {YOUR_JOB.json}同步作业的配置格式可以参考datax文档。
一个典型的配置文件如下:
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"sliceRecordCount": 10,
"column": [
{
"type": "long",
"value": "10"
},
{
"type": "string",
"value": "hello,你好,世界-DataX"
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "UTF-8",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": 5
}
}
}
}一个同步作业的配置文件主要包括两部分,setting包括任务调度的一些配置,content描述同步任务的内容,里面包含reader插件的配置和writer插件的配置。例如我们需要从mysql同步数据到cassandra,那么我们只需要把reader配置为mysqlreader,writer配置为cassandrawriter,并提供相应的插件配置信息即可。在datax项目页面上面可以看到datax支持的插件列表,点击对应的链接就可以查看相关插件的文档了解插件需要的配置内容和格式要求。例如,cassandra插件的文档可点击如下链接:读插件 写插件。
以下列举几种常见的场景。
场景一 cassandra之间的数据同步
最常见的场景是把数据从一个集群同步到另一个集群,例如机房整体迁移、上云等。这时需要先手动在目标集群创建好keyspace和表的schema,然后使用datax进行同步。作为例子,下面的配置文件把数据从cassandra的一个表同步到另一个表:
{
"job": {
"setting": {
"speed": {
"channel": 3
}
},
"content": [
{
"reader": {
"name": "cassandrareader",
"parameter": {
"host": "localhost",
"port": 9042,
"useSSL": false,
"keyspace": "test",
"table": "datax_src",
"column": [
"id",
"name"
]
}
},
"writer": {
"name": "cassandrawriter",
"parameter": {
"host": "localhost",
"port": 9042,
"useSSL": false,
"keyspace": "test",
"table": "datax_dst",
"column": [
"id",
"name"
]
}
}
}
]
}
}场景二 从mysql同步到cassandra
datax支持多种数据源,可以很方便做到cassandra和其他数据源之间的数据同步。下面的配置把数据从mysql同步到cassandra:
{
"job": {
"setting": {
"speed": {
"channel": 3
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "root",
"column": [
"id",
"name"
],
"splitPk": "db_id",
"connection": [
{
"table": [
"table"
],
"jdbcUrl": [
"jdbc:mysql://127.0.0.1:3306/database"
]
}
]
}
},
"writer": {
"name": "cassandrawriter",
"parameter": {
"host": "localhost",
"port": 9042,
"useSSL": false,
"keyspace": "test",
"table": "datax_dst",
"column": [
"id",
"name"
]
}
}
}
]
}
}场景三 只同步cassandra中的一部分数据
我们在读插件的配置中提供了where关键字,可以用来只同步一部分数据。例如对于时序数据等场景定期同步的情况,就可以通过增加where的条件来实现只同步增量数据。where条件的格式和cql相同,例如"where":"textcol='a'"的作用类似于使用select * from table_name where textcol = 'a'进行查询。另外还有allowFiltering关键字配合where使用,作用和cql中的ALLOW FILTERING关键字也是相同的。下面给出一个配置的例子:
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "cassandrareader",
"parameter": {
"host": "localhost",
"port": 9042,
"useSSL": false,
"keyspace": "test",
"table": "datax_src",
"column": [
"deviceId",
"time",
"log"
],
"where":"time > '2019-09-25'",
"allowFiltering":true
}
},
"writer": {
"name": "cassandrawriter",
"parameter": {
"host": "localhost",
"port": 9042,
"useSSL": false,
"keyspace": "test",
"table": "datax_dst",
"column": [
"deviceId",
"time",
"log"
]
}
}
}
]
}
}提高同步速度
以cassandra之间的数据同步为例。如下这些配置会对数据同步任务的性能产生影响:
(1)并行度
可以通过调大任务的并行度来提高同步速度。这主要通过job.setting.speed.channel从参数来实现。例如下面这个配置的效果是会有10个线程并行执行同步任务。
"job": {
"setting": {
"speed": {
"channel": 10
}
},
...需要注意的是,cassandra读插件里面,切分任务是通过在cql语句中增加token范围条件来实现的,所以只有使用RandomPartitioner和Murmur3Partitioner的集群才能够正确切分。如果您的集群使用了其他的Partitioner,cassandrareader插件会忽略channel配置,只用一个线程进行同步。
(2)batch
可以通过配置batchSize关键字在cassandra写插件里面使用UNLOGGED batch来提高写入速度。但是需要注意cassandra中对batch的使用有一些限制,使用这个关键字之前建议先阅读《简析Cassandra的BATCH操作》([https://yq.aliyun.com/articles/719784?spm=a2c4e.11155435.0.0.65386b04OYOsvK))一文中关于batch使用限制的内容。
(3)连接池配置
写插件还提供了连接池相关的配置connectionsPerHost和maxPendingPerConnection。这两个参数的具体含义可以参考[java driver文档](https://docs.datastax.com/en/developer/java-driver/3.7/manual/pooling/)。
(4)一致性配置
读写插件中都提供了consistancyLevel关键字,默认的读写一致性级别都是LOCAL_QUORUM。如果您的业务场景里面可以允许两个集群的数据有少量不一致,也可以考虑不使用默认一致性级别来提高读写性能,例如使用ONE级别来读数据。
性能数据
我们通过一个测试来观察datax同步数据的性能。
服务端使用阿里云cassandra,源集群和目标集群均为3节点,规格为4CPU 8GB。客户端使用一台ECS,规则为4 CPU 16 GB。
首先使用cassandra-stress向源集群写入500w行数据:
cassandra-stress write cl=QUORUM n=5000000 -schema "replication(factor=3) keyspace=test" -rate "threads=300" -col "n=FIXED(10) size=FIXED(64)" -errors "retries=32" -mode "native cql3 user=$USER password=$PWD" -node "$NODE"写入过程的统计数据如下:
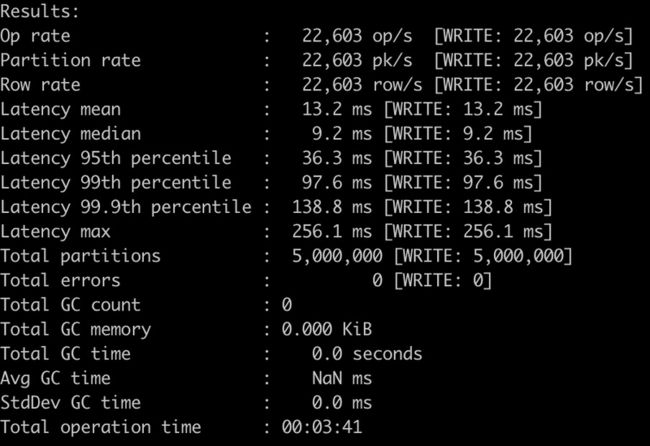
然后使用datax将这些数据从源集群同步到目标集群。配置文件如下:
{
"job": {
"setting": {
"speed": {
"channel": 10
}
},
"content": [
{
"reader": {
"name": "cassandrareader",
"parameter": {
"host": "<源集群NODE>",
"port": 9042,
"username":"",
"password":"",
"useSSL": false,
"keyspace": "test",
"table": "standard1",
"column": [
"key",
"\"C0\"",
"\"C1\"",
"\"C2\"",
"\"C3\"",
"\"C4\"",
"\"C5\"",
"\"C6\"",
"\"C7\"",
"\"C8\"",
"\"C9\""
]
}
},
"writer": {
"name": "cassandrawriter",
"parameter": {
"host": "<目标集群NODE>",
"port": 9042,
"username":"",
"password":"",
"useSSL": false,
"keyspace": "test",
"table": "standard1",
"batchSize":6,
"column": [
"key",
"\"C0\"",
"\"C1\"",
"\"C2\"",
"\"C3\"",
"\"C4\"",
"\"C5\"",
"\"C6\"",
"\"C7\"",
"\"C8\"",
"\"C9\""
]
}
}
}
]
}
} 同步过程的统计数据如下:

可见,datax同步数据的性能和cassandra-stress的性能相当,甚至要好一些。
本文作者:_陆豪
本文为云栖社区原创内容,未经允许不得转载。