
背景
随着4G的普及和5G的推出,内容消费的诉求越来越受到人们的重视。2019年互联网趋势报告指出在移动互联网行业整体增速放缓的大背景下,短视频行业异军突起,成为“行业黑洞”抢夺用户时间,尽管移动互联网人口红利见顶,新的增长点难以寻觅,但中国短视频人均使用时长及头部短视频平台日均活跃用户均持续增常(如图1所示)。

在淘宝,短视频业务一直以来都是非常重要的业务,是淘宝app从单一的商品导购app走向商品导购+内容消费的多元化app的关键所在。相较于单一的商品导购,商品导购+内容消费的模式有效增加用户粘性,提高用户的停留时长,最终获得GMV的持续增长。不仅如此,2019年视频营销发展趋势白皮书指出目前视频内容的转发量已达到图文的12倍,视频营销已经成为品牌最爱的营销方式,使用视频营销比不使用视频营销收入增长速度快49%,且从搜索获得的网站流量多41%。现如今淘宝每年新增内容数达数十亿,其中视频数占比持续提升,预计到2022年视频的占比会超过50%。如何对规模如此庞大的视频进行内容化理解,高效赋能视频运营和个性化分发变得极为关键。
视频类目体系
视频内容化理解的首要问题是构建一个完备的、层次化的类目体系,相比于传统的淘宝商品类目体系,视频类目体系需要解决两大问题。
- 一是提高运营的精细化能力,提供内容的盘货和定向生产、以及快速搭建会场的能力;
- 二是针对新生产的视频提供冷启动能力,提升分发的效率。
虽然淘宝的商品类目体系可以部分代替视频类目体系的功能,但会导致短视频业务的用户心智和商品导购业务同质化,因此构建一套属于短视频业务自己的视频类目体系已经迫在眉睫。有了构建完成的视频类目体系,另外一个更重要的问题是产出高效的视频分类算法,用于对海量的视频进行标签生成。为了获得好的点击效果,视频生产者往往会采用吸引眼球的封面图或者标题,但是和视频本身的内容关联性很弱。此外,淘宝的视频天然和商品有强关联性,如何利用好商品的信息也非常关键。
不同于抖音美拍等其他视频的内容体系从新闻、科技、金融等领域做分类划分,淘宝的视频类目体系从商品导购、产品功能展示、商品知识获取等角度出发,由行业经验丰富的运营进行设计,包含了30+一级类目和150+二级类目,其中一级类目是对视频的领域的划分,例如服饰/家居日用/美食/萌宠等,二级类目是在一级类目的基础之上对视频的子领域的划分,例如一级类目服饰下的熟女穿搭/少女穿搭/儿童服饰/中老年穿搭等,图2是视频类目体系的几个案例。在这个体系之上多媒体算法团队投入近半年的时间提出了基于模态注意力机制的多模态分层视频分类算法。

多模态分层视频分类算法
▐ 视频分类的难点
多模态:淘宝短视频的信息是非常丰富的,有视频/封面图/文本/音频/商品等模态,分别刻画了短视频不同维度的信息,这些信息的展示形式都是非结构化的,如何将非结构化的信息转化成结构化的特征是一大难点。不同模态的信息在不同的视频中对类别的贡献度也是不一样的,小部分视频通过标题就可以简单地推测出类别,但大部分视频的标题有效信息过少,需要兼顾其他模态信息才能推测出类别,因此在算法的训练中如何协同不同模态的特征,达到不同模态特征互补的效果又是另一个难点。
层次化label:单独使用二级类目的label虽然也可以进行算法的训练,但是无法使算法达到最优的效果,因为不同一级类目下面的二级类目之间的差距是远大于同一个一级类目下面的二级类目之间的差距的,单独使用二级类目的label无法学习到这个信息。因此如何在算法的训练中充分利用一级类目+二级类目的层次化label同样是一个难点。
模态信息缺失:淘宝视频包含多种不同的模态信息,然而这些视频不一定包含全部的模态信息,有些视频没有外挂商品,有些视频没有对应的视频标题或者摘要,还有的视频没有封面图。如何让算法能够自适应模态缺失的情况也是一个难点。
▐ 多模态分层视频分类算法框架图
针对建立高效准确的视频分类算法的迫切需求,解决视频分类中存在的诸多挑战,我们提出了基于模态注意力机制的多模态分层视频分类算法,算法总体框架如图3所示。算法的核心主要分为3个部分:
(1) 预训练模型的选择,
(2) 模态融合方法的设计,
(3) 多目标的分类器的设计。
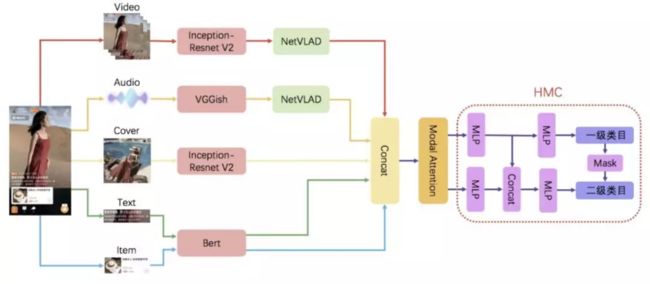
▐ 预训练模型的选择
随着硬件水平的提高以及大规模的预训练数据集的推出,迁移学习在深度学习任务中扮演的角色越来越重要。尤其是在缺乏训练数据的情况下,使用预训练模型进行迁移学习能够加速loss收敛并显著提升下游任务的准确率。
(1) 视觉模态:视频和封面图共同构成了视觉模态信息,视频是视频内容的主体,包含了主要的内容信息,封面图是视频内容的精华,两者可以互相补充。在VGG16、Inception 系列模型、ResNet等经典的图像分类模型中,我们选择了Inception-Resnet v2[1]作为视觉特征提取的模型。这个模型是2016年Google推出的大规模图像分类模型,既具有Inception系列模型的优势,能够通过堆叠不同的Inception Block增加网络的宽度提高算法的准确率,还加入了Resnet的残差学习单元(如图4所示),残差学习单元的输出由多个卷积层级联的输出和输入元素间相加,能够缓解网络退化的问题,增加深度网络的层数,有效提高视觉特征的的泛化性。
视频特征序列相较于普通的图像特征包含了更加丰富的信息,不同特征之间具有时序相关性。我们采用NetVLAD(如图3所示)作为视频特征的聚合网络。NetVLAD常出现在近几年国内外视频分类大赛的top方案中,以CNN的网络结构实现VLAD算法,构成了新生成的VLAD层,VLAD算法(如公式1所示)统计的是特征x和其相应的聚类中心c的残差和,a决定c是否是特征x距离最近的聚类中心。相比于Average Pooling,NetVLAD[2]可以通过聚类中心将视频序列特征转化为多个视频镜头特征,然后通过可以学习的权重对多个视频镜头加权求和获得全局特征向量。

(2) 音频模态:淘宝视频中包含大量的教程类视频,这些视频内容的关键信息通过音频表现出来,因此在淘宝视频分类中音频模态至关重要。我们首先从淘宝视频中分离音频信号,通过计算MFCC特征将音频信号转换为图像输入,然后使用VGGish[3]提取音频特征序列。音频特征序列与视频特征序列类似,使用NetVLAD提取不同镜头对应的音频特征,然后通过可学习的权重融合生成音频模态的全局特征向量。
(3)文本模态:视频内容中的文本包含了视频标题和视频摘要,是视频描述内容的大致概括,对视频分类起到指导性的作用。文本模态,我们使用Bert模型生成视频标题和视频摘要的全局特征向量。Bert是18年Google推出的大规模文本预训练模型,可谓是nlp领域大力出奇迹的代表,Bert用12层的transformer encoder将nlp任务的benchmark提高了一大截。相较于普通的word2vec,经过海量文本预训练的Bert能够在视频分类算法中引入更多的迁移知识,提供更精准的文本特征。
(4) 商品模态:商品模态是淘宝视频区别于站外视频的标志,是体现我们的视频分类算法优势的关键所在。我们沿用文本模态的Bert模型生成商品模态的全局特征向量。商品模态在推荐领域常用item_id lookup到商品的embedding矩阵再接入下游网络,然而我们的视频分类算法是离线学习的,对于新发现的item_id不能很迅速地获得它的embedding特征,因此我们使用Bert模型提取商品的标题和类目名称的文本特征,作为商品模态的全局特征向量。

▐ 模态融合方法的设计
淘宝视频的多模态信息十分丰富,不同模态之间提供的信息内容并不是完全一致的。如何设计优秀的多模态特征融合方法,充分利用非结构化的多模态信息,将不同模态间的特征对齐到同一特征空间,使得不同模态信息之间取长补短,这是视频分类算法模型中最关键的模块。我们比较了多种不同的多模态特征融合方法,实验结果如图表格1所示。
(1) TFN和LMF(如图5所示)都是将多模态特征映射到不同模态间外积的高维特征空间进行特征融合。TFN[6]通过模态之间的外积计算不同模态的元素之间的相关性,但会极大的增加特征向量的维度,造成模型过大,难以训练。而LMF[7]是TFN的等价形式,利用低秩矩阵的分解,将原本的各模态间的先外积再全连接变换过程,等价为各个模态先单独线性变换到输出维度,之后多个维度点积,可以看作是多个低秩向量的结果的和,LMF相比TFN减少了很多参数量,是TFN的优化版本。但在视频分类的算法中,这2种方法的效果都不及预期,分析原因在于视频分类的模态特征长度都在千维左右,即使是LMF也会出现参数数量爆炸的情况,为了保证参数量不爆炸就必须先将每个模态特征降维,然而降维本身是有损的,导致降维后的模态特征再外积不如直接利用不同模态间特征拼接。

(2) 淘宝视频不同模态之间信息通常是不一致的,这些不一致的模态信息之间有些内容和类别标签息息相关,有些内容则相关性较低。为了关注那些与类别标签相关性更高的模态信息,降低对于不重要模态信息的关注程度,我们提出了基于Modal Attention的多模态特征融合方法。Modal Attention基于融合的特征向量预测一个模态个数维度的基于多模态联合特征的对于不同模态的重要性分布概率,这个模态分布概率与多模态融合特征做点积,得到对于不同模态特征重要性重新加权过后的新的多模态融合特征。从表格1可以看出,基于Modal Attention的多模态特征融合方法的准确率显著超过了TFN和LMF,验证了基于Modal Attention的多模态特征融合方法的优势。
(3) 为了应对淘宝视频中出现的模态缺失情况,我们使用了modal级别的dropout,在训练的时候以一定比例随机性去除某个模态信息,增加模型对于模态缺失的鲁棒性。在不添加modal dropout时,测试数据如果缺失10%的模态信息,测试精度会下降3.5%左右;在添加了modal dropout后,测试集精度下降不到0.5%,几乎可以忽略。同时添加modal dropout后,就算模态信息不缺失的情况下,还能够提升测试集精度,提高约0.4%。

▐ 层次化的分类器的设计
一般来说,分类任务只有单一的分类目标,然而,淘宝视频的标签体系是一种结构化的分层分类任务,同时具有一级类目和二级类目,一级类目和二级类目之间有依存关系,构成了一种树状的分类体系结构,例如:二级类目的熟女穿搭、少女穿搭、男士休闲等都属于一级类目的服饰类。针对这个任务,我们提出了分层多标签分类器(HMC)。
(1) 我们将HMC分类器与非常经典的MLP分类器做对比。MLP分类器直接预测淘宝视频的二级类目标签,然后根据一二级类目之间的对应关系获得一级类目标签。HMC分类器同时构建了一二级类目各自的分类通道,能够同时预测一二级类目标签,结构图如图2所示。这种分类器相比于MLP,能够隐形的学习一二级类目的依赖关系,能够互相促进,提高分类精度,表格1的实验结果证明了这一点。
(2) 基于HMC分类器,我们添加了基于类别不匹配的多目标损失函数,具体公式见公式2。损失函数L由三部分构成,分别是一级类目损失L1,二级类目损失L2,以及一二级类别不匹配损失LH。一级类目损失和二级类目损失是一二级类目的交叉熵损失,能够使得网络同时学习到多模态特征与一二级类目的条件概率分布,同时能够隐形的学习到一二级类目之间的依赖关系。然而,仅仅使用一二级类目损失无法保证一二级类目之间的依赖关系,为了缓解这个问题,我们加入了类别不匹配损失,用于惩罚一二级类目不匹配的情况。参数 λ 用来控制一级类目损失和二级类目损失之间的重要性相对程度,因为二级类目数量更多,学习更加困难,需要添加更大的权重去学习。参数 β 用来调节类别不匹配损失对于总体损失函数的重要性。添加类别不匹配损失之后,一二级类目不匹配的情况大幅度下降,同时分类准确率也获得了提升。

总结
Google AI掌门人Jeff Dean在NeurIPS举办期间指出在2020年多模态学习将会有很大的发展,能够解决更多单模态无法解决的问题。我们提出的基于模态注意力机制的多模态分层视频分类算法方案为淘宝的视频内容化理解奠定了坚实的基础,为淘宝视频的精细化运营能力和冷启动能力做出了应有的贡献。与此同时,我们的方案还根据业务需求提供了无成本的可扩展能力,不仅能够助力图文内容化理解,提升图文的理解深度,同时还能通过精细的视频向量化表达来解决相似视频召回、视频抄袭检测的问题。
基于模态注意力机制的多模态分层视频分类算法方案为淘宝的视频内容化理解开了一个好头,后续我们还会在视频内容化理解的领域内继续耕耘。目前我们正在尝试更细粒度的多模态视频标签算法,力图将目前的2级视频类目体系推向2级视频类目+多级视频标签的体系,通过视频类目+视频标签的组合形式持续提升淘宝视频的精细化运营能力和冷启动能力。在多模态技术上,我们会继续关注如何更高效地进行模态融合,尝试将预训练技术引入多模态中,通过误差重建的方法让多个模态相互学习,提升模态融合的能力。
reference
[1] Szegedy C, Ioffe S, Vanhoucke V, et al. Inception-v4, inception-resnet and the impact of residual connections on learning[C]//Thirty-First AAAI Conference on Artificial Intelligence. 2017.
[2] Arandjelovic R, Gronat P, Torii A, et al. NetVLAD: CNN architecture for weakly supervised place recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 5297-5307.
[3] Hershey S, Chaudhuri S, Ellis D P W, et al. CNN architectures for large-scale audio classification[C]//2017 ieee international conference on acoustics, speech and signal processing (icassp). IEEE, 2017: 131-135.
[4] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
[5] Wang W, Bi B, Yan M, et al. StructBERT: Incorporating Language Structures into Pre-training for Deep Language Understanding[J]. arXiv preprint arXiv:1908.04577, 2019.
[6] Zadeh A, Chen M, Poria S, et al. Tensor fusion network for multimodal sentiment analysis[J]. arXiv preprint arXiv:1707.07250, 2017.
[7] Liu Z, Shen Y, Lakshminarasimhan V B, et al. Efficient low-rank multimodal fusion with modality-specific factors[J]. arXiv preprint arXiv:1806.00064, 2018.
[8] Wehrmann J, Cerri R, Barros R. Hierarchical multi-label classification networks[C]//International Conference on Machine Learning. 2018: 5225-5234.
We are hiring
我们是淘系技术部多媒体算法团队,我们依托淘系数十亿级的视频数据,有丰富的业务场景和技术方向。我们持续以技术驱动产品和商品创新,不断探索和衍生颠覆型互联网新技术。我们不断吸引机器学习、视觉算法、音视频通信、端侧智能等领域全球顶尖专业人才加入,让科技引领面向未来的商业创新和进步。
请投递简历至邮箱:[email protected]
本文作者:阮彤枭(晓何)、燕保明(元年)、王琳(有邻)
本文为阿里云内容,未经允许不得转载。