新春红包项目,作为每年用户基数最大的支付宝活动之一,对整个项目组的技术都是一个很大的考验。而作为前端,我们的技术考验就是如何在保证稳定性的同时,为用户不断带来更好的创新体验。
而今年的新春红包项目相比以前,多了不少互动图形方面技术的运用,尤其是第一次对 3D(WebGL)技术的引进。对于新春这个亿万量级的活动而言,这无疑是个巨大的挑战。但作为合格的工程师,效果和稳定性的平衡是我们的一贯的追求,经过了前期的积累,我们使用自研的 Web3D 游戏引擎以及特效编辑器,学习了许多在整个横向前端领域、做的相对最好的游戏领域的经验,最终达到了比较复杂 3D 场景下极低的异常率。
我们的成果
我们在此次新春活动的两个场景中都达到了极好的效果和稳定性的平衡:
- 首页 3D 展示:5 个复杂模型的内存总开销为峰值 30M,稳定 20M,对整体稳定性无影响。
- 福满全球:3D+UI 总内存开销峰值 70M,稳定 40M,加 Webview 总开销 100M。
为了最好的效果
技术的使命只有一个——为用户带去最好的体验。所以在项目最初肯定是先按照最高视觉效果来,针对新春中的两个使用到了 3D 的场景,我们首先进行了尝试,然后发现了问题。
并非最佳体验
在这种情况下,我发现虽然视觉效果达到了最优,但又出现了很多其他方面的问题,这使得最终的用户体验反而并不是很好:
- 加载时间过长
- 用户体感卡顿
- 相对高发的崩溃(主要是 OOM)
而这某种程度上也符合我们一开始的预测,因为在移动端 Web 这种技术方案中,有些限制是不可避免的,而这些不安定要素会在亿万用户的量级被无限放大。在经过数据的详细的分析,我们找到了针对这两个场景的瓶颈共性。
瓶颈在何处
为了找到瓶颈,让我们先来看一些数据。
首先是首页 3D 动画,首页总共五个场景模型,使用的资源包括:

可见统计下来,3D 部分最终可以预计的传输大小为 15M,峰值内存为 65M,而稳定下来最好情况也有 30M 内存开销(这种策略下一般达不到最好,预计 40M 左右)。同时由于单场景 5W 三角形,对于中低端机的帧率也有较大挑战。
其次是福满全球页面,福满全球的模型资源开销基本可以忽略,但却有其他方面的问题:

可见,福满全球 3D 部分的主要开销是在峰值 70M 的纹理,以及高清屏大量透明物体的渲染开销。
死磕解决方案
通过瓶颈分析可知,问题主要集中在内存、传输体积和运行性能三个方面,而这三者又互相关联。那么自然的,我想到了从相对容易解决同时收益又大的方面入手。
削减模型大小
首先就是削减模型大小了,注意这个大小指的是三角形 / 顶点数量。为什么这个如此重要呢?很简单——模型的大小可以直接影响到以上的三个要素:
1. 内存:模型的大小和其占据的内存是线性正相关的。
2. 传输体积:和内存一致。
3. 运行性能:单帧三角形数量越多,顶点着色器的压力越大,尤其是在首页 3D 模型这种具有骨骼动画的情况下。
所以削减模型大小显然是必须要做的,那么我们如何去做呢?一般来讲,这件事应该交由设计同学,让他们去降低模型精度来达到一个可以接受的程度,但是结果不容乐观,经过研究,我们最终采用了以下两个策略:
1. 使用工具减模
首先是寻求能否使用工具自己进行减模,我们自研的 Web3D 游戏引擎使用 Unity 进行场景编辑,而 Unity 作为身经百战、扩展性极强的一个游戏引擎,有没有这么一个工具来帮助我们呢?答案是有的—— UnityMeshSimplify 就提供了让我们在 Unity 中自由调整模型精度并序列化的能力。而也正是使用了它,在视觉效果损失较低的情况下,平均降低了所有场景 30% 的图元数据大小:
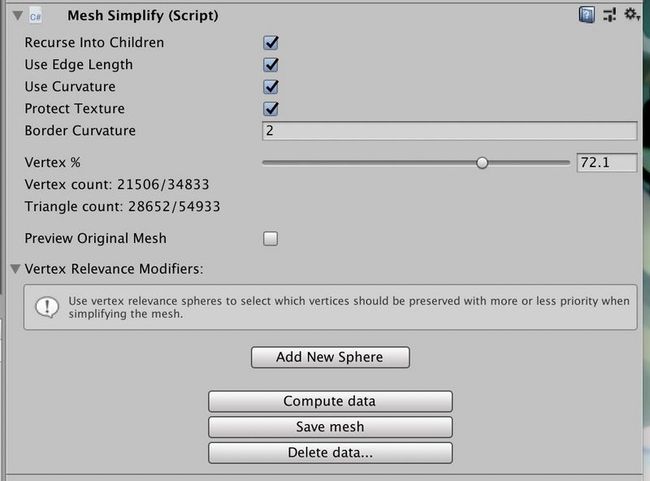
2. 削减不必要的数据
在工具减模以后,图元数据大小从 12M 降到了 7.5M,但这显然还是不够,那么还有什么办法呢?在思考后发现了一个关键点——处于性能考量,此次模型的光影是烘焙到纹理的,也就是说整个场景没有光照。
这里就需要我们了解一些细节了,即顶点数据的构成。
图元的最基本单元是顶点,一个顶点有包含着若干信息,在绘制时这些顶点数据将会被送入顶点着色器进行一系列处理,然后进入光栅化阶段。而一个顶点的信息,最常见来看,包含:

而其中的法线和切线在首页 3D 展示中并没有作用,所以可以将其删除,我在 UnityToolkit 中添加了 Unlit(No Normals) 选项来让导出时可以自动剔除这两项:

而最终效果也令人满意,图元数据大小进一步降低到了 5MB。
3.成果小结
模型裁剪主要是针对首页 3D 展示的,经过优化,我们得到了成果:
(1)单场景最大三角形数量从 5.5W 降到 2.9W;
(2)所有场景图元和动画数据大小从 12MB 降到 5MB。
可见,我们成功将成功将图元数据 + 动画大小缩减了一半,还保证了最复杂的场景的三角形数量也缩减了将近一半,使得内存开销低了不少,同时传输体积小了不少,还大幅优化了渲染性能开销。
但显然传输体积还是太大了,这里我们还进行了进一步的优化。
使用压缩纹理
解决了模型图元大小,接下来就是纹理的开销了。通过上面的瓶颈分析可知,福满全球项目的开销主要就是在纹理方面。
1. 何为纹理
纹理读者也可以理解为贴图、图片。一般来讲,我们存储的图片都是以 JPG、PNG 等格式存储的,而格式决定的是什么呢?其实是压缩和编码算法。实际上,无论我们把一张 JPG 或者 PNG 图片压缩得再小,它最终被解码后在内存中还是以 Bitmap 的形式存在的,而且在浏览器中,基本都是以 RGBA 的像素格式存在的。
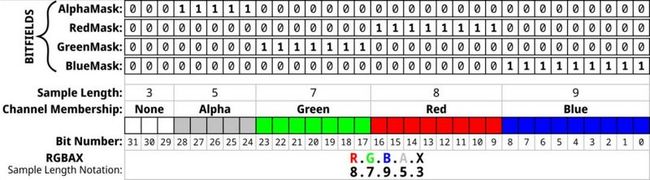
无论使用那种方式编码存储,最终都会被解码为 RGBA32 的 Bitmap,一个像素 4 字节。
这就意味着无论我们将图片的存储体积压缩到多么小,其内存开销总是固定的,比如 512x512 的图片内存开销就是 1M,而 1024x1024 的就是 4M。那么有没有办法解决这个问题呢?当然有——游戏业界为了解决这个问题,提出了压缩纹理技术。
2. 压缩纹理
压缩纹理是一种游戏领域常用的纹理压缩技术,其依赖于特定硬件实现,本质上可以以固定速率交由 GPU 即时解压,其有如下优势:
(1)内存:大幅节省内存开销。
(2)解码:免去图片解码开销,直接丢给 GPU,提升启动性能。
(3)采样:提升纹理随机采样性能。
(4)可控:由于其本身就是在 JSHeap 上申请的 buffer,所以在 Web 容器下,提供了一个可以精确控制内存的方式。

PVRTC 的 Block 说明
经过调研和一些测试,我们最终选择了安卓下使用 ASTC 和 iOS 下使用 PVRTC 的策略来进行纹理压缩,其中更为细节的配置暂且不表(都是中等精度压缩),最终在项目中得出的成果如下:
(1)首页 3D 展示:

(2)福满全球:
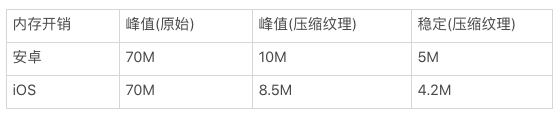
可见压缩纹理对于内存的开销有着极大的优化,基本完全解决了内存问题。
3. 条件和代价
当然,这世界上并没有免费的午餐,我们接受了压缩纹理的优点,就要相对得付出代价以及接受它的约束:
(1)压缩纹理是有损压缩,会对图片的质量有一定减损,这个需要视项目而定。
(2)压缩纹理的传输体积可能比 JPG/PNG 方案要高 1~4 倍。
(3)压缩纹理要求 POT,即长宽都是二的幂次。
(4)对于 iOS 的 PVRTC,还要求长宽相等。
(5)由于压缩纹理格式在不同平台不能通用,加上降级需要三份资源,对于离线加速技术不友好。
对于某些代价,比如视觉质量损失、传输体积我们是可以自行调整的,不属于原则性难题,但这个 POT 对于很对前端应用可真是个原则性问题了,比如福满全球中的地标和红包贴图,就不是 POT 的,那么怎么办呢?有办法——使用图集。
4. 纹理标准化 - 图集
图集是一种纹理标准化的方式,在游戏领域常常用于处理 UI、2D 精灵等,简单来讲,图集就是将许多图片拼到一张上,不错就是我们常说的雪碧图(精灵图):

如图,我们将四个 500x500 的地标图片拼到了一张 1024x1024 的图集中,来满足压缩纹理的需求。那么我们又如何去使用这个图集呢?很简单,我们的引擎内置了 AtlasManager,可以让你非常简单得使用它,并且在引擎标准的开发流程中,依赖于 Unity+Webpack 工作流,这个能力能够十分方便得引入——在 Unity 中直接编辑图集,后面会说到。
图集还有别的优势,就是减少内存碎片,减少数据提交次数,某些情况下还可以减少资源请求。
精确掌控内存
目前我们拥有了削减模型和压缩纹理两种策略,大幅降低了内存开销,并降低了一部分传输体积,但通过上面的论述不难发现其实我们还可以更进一步——我们很容易发现,在整个过程中,同一份数据可能在 CPU 和 GPU 端同时存在,尤其是移动设备 CPU 和 GPU 是共享内存的。所以我们一定有办法再更进一步去解决这个问题。
这也就是我选用压缩纹理的另一个理由——压缩纹理本质上是 JSHEAP 上的 ArrayBuffer,我们可以很好得通过控制引用来帮助 GC,这也就是为何上面的数据分析中能保证稳定开销是峰值的一半。
在我们引擎的设计中,这个功能是可选的,通过纹理的 isImageCanRelease 来开启,而如果遵守标准工作流,这一切都是自动的,无需开发者操心。
当然这也有代价,就是在 GL 上下文丢失后无法恢复,请酌情使用。
进一步减少传输体积
到目前为止,内存已经被控制得很好了,但是在传输体积上还是有更大的优化空间,在这个方面我首先考虑的就是内部的 Hilo3d 团队提供的模型压缩方案。
1. 模型压缩
我们采用的模型压缩方案原理很简单,针对移动端使用的模型,并不需要每个顶点数据都是 32bits 的 float 型,一般来讲 13bits 或者 14bits 就够用了,所以这里有很大的可压缩空间。而事实上经过测试,发现确实如此,但当然这也是有代价的,通过模型压缩:

也就是说,模型压缩后,首页的所有资源大小达到了安卓 5.8M、iOS5.2M。但代价是增加了解压时间和 1.5M 的峰值内存。相对于收益,开销是可以接受的。
然而即便如此,5M 的资源大小对于亿万 UV 的量级还是有些大,我们还有更多的办法吗?有,这时候就要请出我们的老朋友 GZIP 了。
2. GZIP
大家都熟知的 GZIP 其实在很多时候都能发挥意想不到的作用,而在我们的工作链路下,模型压缩会提升 GZIP 的效果,而压缩纹理也能获得收益,在 GZIP 后:
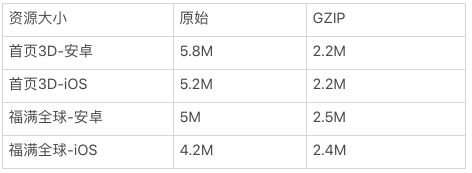
可见,我们让资源体积再减半,和一开始相比缩减了六倍。
3. 一般图片资源
当然除了 3D 相关的资源,我们也提供了方法来对普通图片进行了压缩,主要是将 PNG 图片编码压缩成了索引色,这是一种有损压缩,也就是大家常用的 TinyPNG 的策略,当然这个并没有什么神奇的,我们已经将这种算法作为了一个插件融入了工具链中,可以通过 Webpack 工作流直接无缝整合,最终普遍带来了 2~4 倍的体积压缩。
减少资源请求
到了这里我们解决了大部分主要问题,但还有一些边角问题会对体验的极致构成影响。这一点就是资源请求数量,我们不难发现,对于两个场景而言,3D 场景的资源请求数量都接近 20 个,而这个问题并非不可解。
对 3D 领域有一定了解的读者想必是知道 glTF 这个格式的,而我们自研引擎的场景序列化也是使用了这个格式。为了应对某些场合,glTF 有它的二进制形式 GLB,其可以将索引、纹理、图元数据等等都打包到一个二进制文件中,大幅降低请求数量,在两个新春场景中,请求数量均被降到了 1 次。
而打包 GLB 的功能也被我们整合进了 Webpack 链路中,开发者可以零成本将其引入。
剩余的性能问题
以上问题解决完成后,基本就可以保证项目稳定了。对于福满全球大量透明物体和高清屏的问题,经过业务层面的调优,最终发现在可控范围内。这个是由于业务性质决定的,否则我们当然可以采用强制最大画布尺寸来降低开销。
除此之外,还有一点需要注意的是我们很可能忽略的一点——运行时的 GPU 资源提交。由于引擎的设计是用到了在提交的原则(当然这很符合规范),但对于这两个项目,保证用户操作时不卡顿的优先级是很高的,而同时经过了上面的内存优化我们也已经保证了即使所有资源都被提交也可控,所以就需要一个策略将所有资源先提交到 GPU,并预编译所有 Shader。
为了做到这一点,我们采取了一个简单的策略:在第一帧将所有物体渲染一遍,再结束 Loading,这增加了些许的加载时间,但保证了整个过程中不会卡顿。
而对于首页 3D 展示,为了做到极致的效果,我们设计了渐进式展示的策略。
渐进式展示
做这个策略是考虑到项目用户量级极大,网络情况不一,所以不可能等待 Loaing 结束才展示页面,那样首次性能会很差,所以我们敲定方案——总是先展示静态图片,3D 资源加载、解析、提交 GPU 成功后,才无缝切换为 3D 动画。
首页 3D 动画的这种策略是值得很多展示型项目参考的,这里还需要注意的的一点是:若模型比较复杂,首帧渲染会卡住用户操作。所以针对本项目的场景,我们采用了时间分片的策略,将五个模型拆分为五次渲染,每次间隔 200ms,留给用户操作的时间:
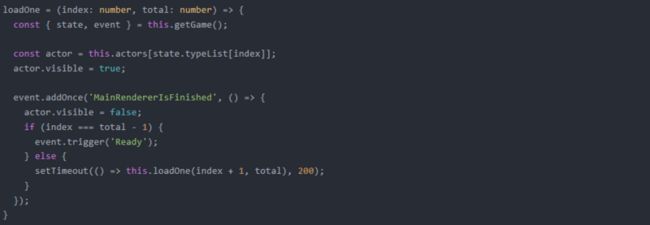
并且我们还保证静态图片和 3D 场景的姿态完全一致,从而达到视觉上无缝切换的目的。
酷炫易用 - 粒子特效
我们在大促的时候都需要炫酷的页面来吸引用户,但是动画通常都是开发的噩梦,通常我们在做动画会遇到以下三个问题:
- 动画粗糙,不能打动用户;
- 还原度不高,和设计差距较大;
- 性能优化不足,兼容性不好。
这次的新春红包项目大量使用了 3D 场景,在 3D 中加入了很多粒子特效,那么这些特效是如何产出并且解决以上三个问题的?
让动画设计更精美
我们在首页切换的时候增加旋转的粒子特效,效果如下:
这个是设计同学的原稿,由于 Lottie 技术的普及,设计同学做动画大多使用 After Effect 在 AE 中制作好的 transform 动画(仅使用 translate、scale、rotate 变化)导出可使用 Lottie 播放,大大降低开发成本。而 AE 本身是一个视频后期软件,里面除了可以制作简单的 transform 动画,还可以开启 3D 渲染,进行图像跟踪,加滤镜等等。这个粒子特效就是用 AE 里 Particular 插件制作的,所以 AE 的上限就是设计师设计的上限。
设计师的设计工具将直接决定设计产物的质量。如果没有 particular 插件,那么我们的设计产物永远都只会是 transform 动画,很多影视级别的特效就不会出现在产品页面中,所以提高设计工具能力将直接决定动画产出的质量。当然还有一个值得焦虑的问题,我们的产品开发并不知知道 particular 的插件是怎么实现的,那么很大概率是无法还原的,所以既要提高设计工具的质量,也要限制设计随意使用设计工具导致无法实现。
新春红包项目的粒子特效设计全部在工具里实现:
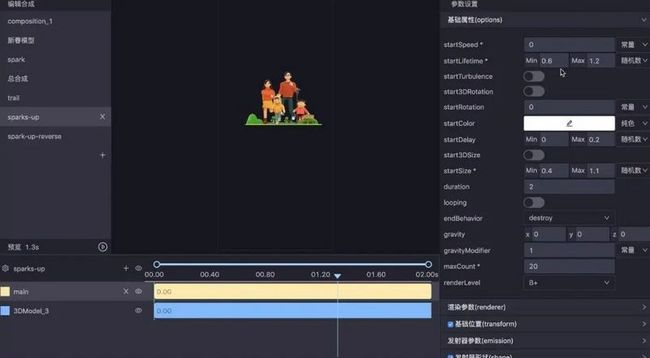
如果是手写代码还原设计稿的话,恐怕最要命的就是函数曲线的还原,动画为了更加顺滑会加入很多曲线来控制,比如说刚才的旋转上升的星星,会有一个先加速再减速的过程:
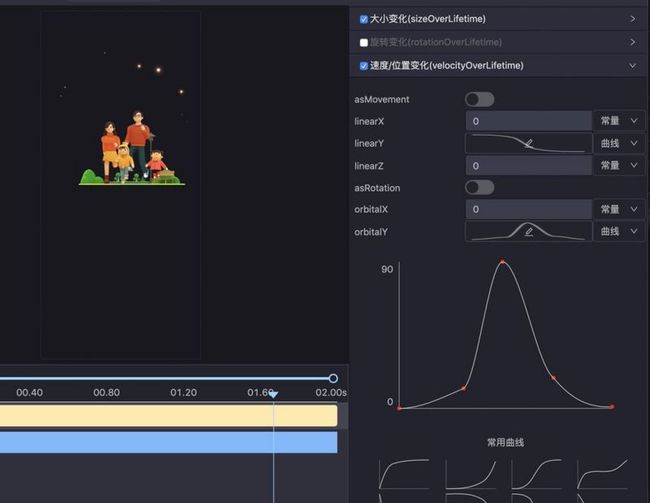
一个复杂的粒子系统有 60 多个属性,如果开发通过肉眼还原数据,哪怕是复制粘贴属性值,都可能会出问题。
最好的还原方法是不写代码。编辑器直接导出动画数据,在手机上进行播放,开发完全不用关心各种参数。而产物很容易使用,直接保存项目工程,通过 webpack 进行加载,像使用图片一样简单。
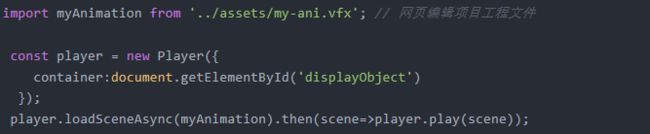
新春红包项目中 3D 场景由 引擎 搭建渲染,使用的时候也是类似的方式,将编辑器工程作为资源引入,直接播放就可以了。动画播放起来之后就是开发最关心的问题了。
保证动画性能
其实任务首页的粒子效果还很少,谈不上性能瓶颈,而福满全球大量使用粒子,特别是烟花作为常驻特效,需要特别进行优化。这里我们参考了游戏领域粒子系统的许多优化策略,将其运用到了本次的优化中。
优化一:粒子运动完全 GPU 运算
对于粒子系统来说,因为粒子数量大,使用曲线控制后运动计算复杂,如果通过 CPU 计算粒子的运动,那么网页将不堪重负,所以粒子的运动旋转和颜色变化计算全部放在 GPU 中,通过定制 shader 完成,在 shader 中计算曲线是比较复杂的事情(此处省略 3 千字)。
优化二:优化粒子发射器
可以看到进度条的粒子持续产生,因为粒子有生命周期,所以会有老的粒子死亡,新的粒子出生,繁衍不息。首先我们在内存中开辟一块固定的地址,有一个按照粒子的生命周期排序的双向列表,每一帧需要产生新粒子的时候,检查列表最先死亡的粒子,如果此粒子已经死亡,那么会把这个粒子的地址写入新粒子的数据,同时将此列表元素从后插入。大概类似如下过程:
这样的列表可以保证粒子插入的速度,假设一个粒子系统有 200 个粒子,每帧其实只有 3-4 个新粒子的插入,在 CPU 中的计算量很小。
优化三:合并发射器
一个烟花是由两个发射器组成的,构成了双层烟花的效果,同时每个烟花增加一个拖尾效果,烟花飞过的地方就有个小尾巴。编辑效果如下:
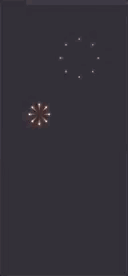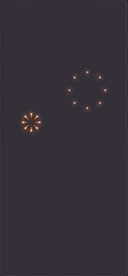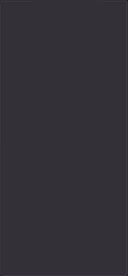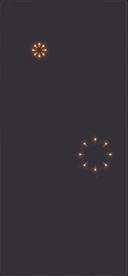
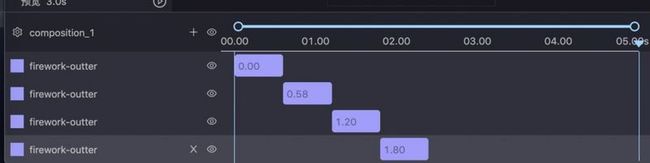
可以看到烟花以相同的模式爆炸了 6 次,但是每次爆炸的位置不一样,通常情况下我们在编辑器会做好一次的爆炸,然后复制 6 次,时间轴类似如下:
但这样的话会导致频繁创建销毁绘制元素,性能消耗很大,所以编辑器提供了合并粒子爆炸的选项,并且每次可以修改爆炸的位置。对于习惯了复制粘贴的设计师来说,很容易复制很多相同元素导致性能开销过大,将六个绘制元素合并成一个元素可以大大降低开销,同时重复利用内存。
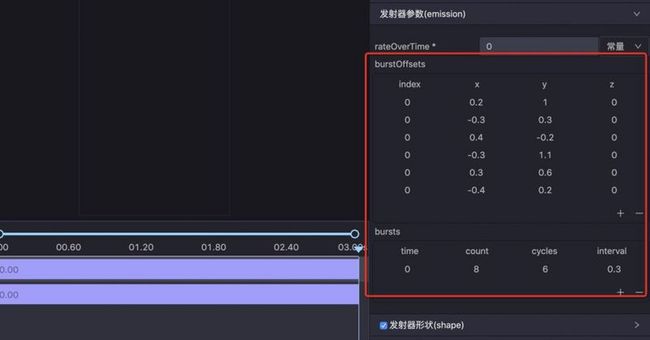
优化四:减少拖尾使用
拖尾就是飞线,在粒子运动过的地方生成一个顶点,绘制的时候连成一条线,这样就有流星划过的感觉。但是因为粒子的计算都是在 GPU 中的,所以每帧如果要生成新的顶点,必须在 CPU 中也重新计算粒子的位置,这样的计算量是很大的。如果烟花只是进场爆炸一次,那么开销可以忽略,但是有一些烟花是常驻的,隔一段时间就会播放一次,那么对于常驻的动画,就要避免使用拖尾。这次我们选择了用贴图缩放的方法来替代拖尾。
如果不用贴图的话,看起来就是一圈延展的小菊花,这是通过通过增加长方形长度实现的,换上我们尖角的贴图就非常像一条尾巴,最后常驻烟花没有使用拖尾,但是视觉效果仍然很像划过的流星,这样保证所有的计算都在 GPU 中进行,提高动画性能。
做到极致 - 工程自动化
当然,作为引擎开发者,除了将这些技术应用到新春项目中,使得更多开发者可以简便使用这些功能也是很重要的,所以我将这一切都封入了引擎的标准工作流中:
引擎工作流
引擎的工作流集成了以上所论述的所有优化策略,其主要包括 UnityToolkit 和 Webpack 链路两部分。
1. UnityToolkit
UnityToolkit 是 Unity 的一个插件,用于将 Unity 中的各种特性导出供引擎使用,整个流程集成度很高,目前已经支持了大量特性,包括但不限于 GameObject、模型、材质、纹理、动画、光源、摄像机、天空盒、图集、精灵、物理、音频、环境反射、环境照明、光照贴图的导出和导入,支持自定义扩展组件,支持脚本逻辑绑定等等。
2. Webpack 链路
然后就是 Webpack 链路了,我对 Webpack 链路做了深度定制,用于满足引擎的工作流的需求。上面提到的压缩纹理、模型压缩、资源预处理、资源自动化发布等都被集成到了其中,包括多平台适配也是通过 Webpack 插件实现的。
这里先大概介绍一下此次项目用到的最主要的链路:gltf-loader
这个 Loader 是整个链路中非常核心的一贯,其提供了加载 gltf 文件并进行复杂预处理的能力。使用它,我们可以做到:
(1)模型压缩。
(2)纹理压缩。
(3)打包 GLB。
(4)资源预处理:对 gltf 文件引用的资源进行预处理,通过定制 Processor 接口你可以实现任何你想要的任何预处理。
(5)资源发布器:自定义发布器,在 gltf 文件引用的资源(包括自身)被产出时,拦截并进行自动化处理。
而在这两个项目中,这几个功能都被用到了,也为最终项目的稳定可靠提供了重要的保障。
关于团队
本次分享来自于支付宝 Turandot Studio,Turandot Studio 致力于通过互动和图形技术,让前端变得更加具有创意,为用户带来更美好的体验,如果你有意加入我们,请联系我的邮箱:[email protected]。