elasticsearch源码解析笔记
第一章 走进ElasticSearch
基本概念
1.1.1 索引结构
ES是面向文档的,各种文本内容以文档的形式存储在ES中
在存储结构上, index、type、id标识一个唯一的文档
类比RDBMS的概念,可以快速理解概念,但本质上是完全不同的概念
RDBMS ES
库 index
表 type
行 文档数据
在实际应用中,当数据模型不同时,应该使用不同的index而不是使用不同的_type,在ES6.x版本每个index只允许存在一个type,ES7.x完全删除type的概念
ES7.x移除type的原因:数据库中两个不同的表拥有同名的字段是相互隔离、互补影响的,但是ES是基于lucene存储的,不同type的同名字段在lucene中存储时是一个字段,这就带来了字段冲突,会影响ES的处理效率
1.1.2 分片
单机无法存储巨量的数据,纵向扩展除了会带来几何倍数增长的成本外同时具有较低的瓶颈限制。因此,需要将数据拆分到各个机器上,然后通过某种路由策略可以根据条件找到数据所在的位置。
为了保证数据的可靠性,ES还提供了副本机制,副本是基于分片来做的,可分为主分片、副分片
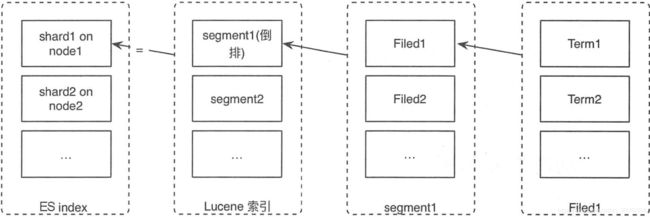
分片与副本的关系如图:

分片是底层读写的基本单元,目的就是分割巨大的索引,让读写可以并行操作。读写最终会落到某个分片上,每个分片都是一个完整的Lucene索引,可以单独执行搜索任务。一个Lucene索引包含多个Lucene分段,每次执行refresh操作时,都会生成一个新的Lucene分段,每个Lucene分段中包含部分文档数据,针对文档中的每个字段会建立一个倒排索引,倒排索引由单词词典和倒排列表组成,单词词典就是Term集合,倒排列表由倒排项组成,每个倒排项包括单词以及单词出现的所有文档的信息(这里的文档信息存储的内容可以由index_options进行控制,包括文档的ID、词频、词出现的偏移量)
在创建索引的时候,就应该确定主分片数,ES5.x之前主分片数是不可修改的,ES5.x开始可以使用shrink API减小主分片数
但其实在实际应用中,不应该一直往单个索引中添加数据,因为数据老化后难以删除,以_id为单位删除文档不会立即释放磁盘空间,需要进行Lucene段合并才会将数据从磁盘彻底删除,即使手动触发段合并,也会带来较大的IO压力,并且可能因为分段巨大而导致剩余的磁盘空间不足(新分段的大小大于剩余磁盘空间)。所以建议是周期性创建新索引,比如每天创建一个新索引,使用索引别名关联这些索引,业务方读取时通过索引别名进行读取名称不变,当需要删除老化数据时,直接删除整个索引即可。
索引别名就类似于一个软链接,不同的是它可以指向一个也可以指向多个索引
1.1.3 动态更新索引
lucene分段具有不可变性,好处就是不需要加锁,读取时可以被文件系统缓存
新添加的文档如何被搜索到?答案是每次新添加的文档都会在一个新的lucene分段中,搜索时是遍历所有的lucene分段
更新、删除文档时,是将旧文档标记为删除,记录到单独的位置,删除文档不会立即释放磁盘空间
1.1.4 近实时搜索
ES写数据时,是先将数据写到Index buffer,每隔一秒调用操作系统的write接口将数据写入磁盘,write接口将数据写到操作系统缓存中就返回成功了,并不会立即刷盘,需要手动执行flush或者操作系统通过一定的策略将数据刷到磁盘,但是当write接口返回成功时,即使数据没有写到磁盘,数据也对搜索可见
每隔一秒写入的这批数据就是一个lucene段
由于写入的数据是先在内存中,然后写入磁盘,在这期间如果机器宕机,那么就存在丢失数据的风险。通用的做法是记录事务日志,对ES进行的操作做记录,当ES重启时,重放translog中最后一次提交点后的操作。
集群内部原理
1.2.1 集群节点角色
- 主节点
主节点负责集群层面的工作,管理集群变更
通过配置node.master : true(默认)让节点成为master_eligible节点即有资格成为master的节点
为避免网络分区时出现脑裂,配置discover.zen.min_master_nodes为(master_eligible_nodes / 2) + 1 - 数据节点
负责保存数据,执行数据相关的操作;CRUD、聚合、搜索
通过配置node.data : true(默认)来让节点成为数据节点 - 预处理节点
这是从ES5.0开始引入的概念, 作用就是在写入数据前,通过事先定义好的一系列处理器对数据进行处理、转换,然后在将数据写入
默认,所有节点都会启用预处理功能,可以通过node.ingest : false关闭 - 协调节点
协调节点就是接收客户端请求的节点,该节点知道任意文档的位置,然后将请求转发给数据节点,对数据节点返回的结果进行合并,最后将合并的结果返回给客户端
默认每个节点都是协调节点,如果需要一个单纯的协调节点,可以进行如下设置:
node.master:false
node.data:false
node.ingest:false
1.2.2 集群健康状态
集群健康状态分为3种:
1. Green
主、副分片都分配正常
2. Yellow
副分片未正常分配
3. Red
主分片未正常分配
1.2.3 集群状态
集群状态是全局信息,包括内容路由和配置信息,内容路由描述了哪个分片位于哪个节点
主节点负责维护集群状态,从数据节点接收更新,将这些更新广播到集群的其他节点,让每个节点上的集群状态保持最新。ES2.0之后,更新的集群状态是增量的并且是压缩过的。
1.2.4 集群扩容
当扩容集群,添加节点时,分片会均匀地分配到各个节点
分片分配过程中除了让节点间分片分配均匀,还要保证主副分片不在同一节点,避免单个节点故障引起数据丢失
如下:起初,NODE1上有个三个主分片,没有副分片
P代表主分片、R代表副分片

添加第二个节点后,副分片被分配到NODE2
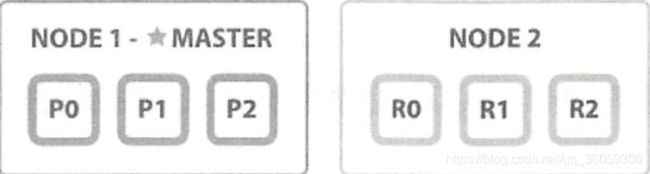
添加第三个节点后,6个分片被均匀分配到3个节点,主副分片不会在同一个节点

当主节点出现异常,集群会重新选举主节点;当某个主分片出现异常时,也会将副分片升级为主分片
疑问:副分片可以分配在同一个节点吗???????
1.4 主要内部模块简介
-
Cluster
Cluser模块是主节点执行集群管理的封装实现
主要功能如下:- 管理集群状态,将最新的集群状态广播给各个节点
- 调用allocation模块执行分片分配,决策哪些分片应该分配到哪个节点。(因此负责创建索引)
- 在集群各个节点中直接迁移分片,保持数据平衡
-
allocation
封装了分片分配相关的功能和策略,包括主分片分配和副分片分配,本模块由主节点调用。创建索引、集群完全重启都需要进行分片分配 -
Discovery
发现模块负责发现集群中的节点、主节点选举以及维护集群拓扑。当节点加入或离开集群时,主节点采取相应措施 -
gateway
负责对收到Master广播下来的集群状态数据做持久化存储,并且在集群完全重启时恢复它们 -
Indices
索引模块管理全局级的索引设置,不包括索引级的。它还封装了索引数据恢复功能,例如启动阶段的主分片恢复和副分片恢复。 -
HTTP
HTTP模块允许通过JSON over HTTP的方式访问ES的API,HTTP模块本质上是完全异步的,这意味着没有阻塞线程等待响应 -
Transport
传输模块用于集群内节点之间的通信
本质上是完全异步的
传输模块使用TCP通信,每个节点和其他节点维持13个TCP长连接 -
Engine
Engine模块封装了对Lucene的操作及translog的调用,它是对一个分片读写操作的最终提供者
1.4.2 模块结构
一个典型的模块由Service和Module类组成,Service用于实现业务功能,Module类配置绑定Service的实现类
1.4.3 模块管理
定义好的模块由ModulesBuilder类统一管理,该类对外提供两个方法
1. add方法:添加定义好的模块
2. createInjector:返回injector对象,后续通过injector获取响应的Service类的实例
模块化的封装让ES易于扩展,插件本身也是一个模块,节点启动时被模块管理器添加进来
第三章 集群启动流程
3.1 选举主节点
集群启动的第一件事就是选举主节点,选主之后的流程由主节点触发
ES选主的思路是对节点ID排序,取ID值最大的节点作为主节点,选择出的主节点不一定具有最新的集群元信息,后面在想办法获取最新的集群元信息(非集群状态信息)
选举主节点有三个约束条件:
1. master_eligible节点数要达到quorum值(多数),选出临时的主。为什么是临时的主呢?因为每个节点选举出的ID最大的节点不一定相同。例如,集群有5台机器,ID分别是1、2、3、4、5,由于产生网络分区或者启动速度差异较大,节点1看到的是1、2、3、4,选出4;节点2看到的是2、3、4、5,选出5,结果就不一致了
2. 节点得票数过半即加入该节点的节点数过半,才确认主节点,解决第一个问题
3. 当探测到节点离开时,必须判断master_eligible节点数是否达到quorum值,如果达不到quorum值那么要放弃master身份,重新加入集群。如果不这么做,设想一下:假设5台机器,产生网络分区,2台一组,3台一组,原来的master在2台中的一个,3台一组的节点会重新选举出一个master,产生双主,俗称脑裂。
quorum值就是配置 discovery.zen.minimum_master_nodes的值
3.2 选举集群元信息
选举出的Master第一个任务是选举集群元信息,让各节点把各自存储的集群元信息发过来,根据版本号确定最新的集群元信息,然后把这个信息广播到每一个节点
集群元信息的选举包括两个级别:集群级、索引级
为了集群一致性,参与选举的元信息数量需要过半,Master发布集群状态成功的规则也是发布成功的节点数过半
集群元信息选举完毕后,Master首次发布集群状态,然后开始选举shard级元信息
3.3 allocation过程
初始化阶段,所有分片都是未分配状态,通过分片分配决定哪个分片位于哪个节点,重构内容路由表。此时,首先要做的就是分配主分片。
1. 分配主分片
Master向所有节点询问指定分片的元数据信息,然后根据策略选举一个分片作为主分片
ES 5.x之前是根据分片元信息的版本来决定谁是主分片,但是存在一个问题:拥有高版本分片的节点可能在后面启动,导致决定出错
ES 5.x开始给每个分片分配一个UUID,然后在集群元信息中记录哪个分片是最新的。由于ES是先写主分片,再写副分片,所以主分片肯定是最新的
3.4 Index Recovery
分片分配完成后,进行数据恢复阶段,主分片的恢复不需要等待副分片分配完成,副分片的恢复需要等待主分片恢复完成
为什么要进行数据恢复呢?
主分片可能有一些数据没有来得及刷盘;副分片可能有一些数据没有刷盘,也可能有一些数据主分片写成功而副分片没有写,主副分片数据不一致
恢复过程:
1. 主分片恢复
重放最后一次提交后的translog事物日志。一次提交就是一次fsync异步刷盘。
2. 副分片恢复
分为两个阶段:
phase1:
在主分片获取translog保留锁保证主分片translog不被删除,然后调用lucene接口对主分片数据进行快照,这是已经刷盘的数据。把这些数据复制到副分片。
在phase1结束前会告诉副分片启动Engine,在phase2开始之前,副分片就可以正常处理写请求了。
phase2:
对主分片translog做快照,这个快照包含从phase1开始到执行translog快照期间的所有操作,将这些translog发送到副分片进行回放
在副分片节点,重放translog时,translog中的操作和副分片在phase1和phase2阶段的写操作会有冲突,在写流程中通过对比版本号来过滤掉过期操作
第四章 节点的启动与关闭
4.1 启动流程做了什么
解析配置,包括配置文件和命令行参数
检查外部环境和内部环境
初始化内部资源,创建内部模块,初始化探测器
启动各个子模块和keepalive线程
4.2 启动流程分析
4.2.1 启动脚本
当通过启动脚本bin/elasticsearch启动ES时,会对命令行参数、config/jvm.options、elasticsearcg.yml、log4j2.properties配置文件进行解析
当前支持的命令行参数:
-E 设置某项配置,例如设置集群名称-E “cluster.name=my_cluster”
-V 打印版本号信息
-d 后台启动
-h 打印帮助信息
-p 启动时在指定路径创建一个pid文件,其中保存了当前进程的pid
-q 关闭控制台的标准输出和标准错误输出
-s 终端输出最少信息
-v 终端输出详细信息
4.2.3 加载安全配置
安全配置就是敏感配置信息,不适合明文放在配置文件,ES把这些敏感配置放在config/elasticsearch.keystore中,然后提供一些命令查看、添加和删除配置
4.2.4 检查内部环境
内部环境指ES软件包本身的完整性和正确性
1. 检查lucene版本,ES各版本对lucene的版本有要求
2. 检查jar冲突
4.2.5 外部环境检查
-
堆大小检测
检测JVM初始堆大小和最大堆大小的值是否相同。不相同会导致在使用期间JVM堆大小动态调整出现停顿。 -
文件描述符检查
ES进程需要很多的文件描述符,例如一个分片包含很多分段,每个分段又包含很多文件,同时ES节点又要和其他节点保持很多的网络连接等
需要调整系统的默认设置,在Linux下执行 ulimit -n 65536(只对当前终端生效),或者在/etc/security/limits/conf文件中配置"* - nofile 65536" -
内存锁定检查
ES允许进程只使用物理内存,而不使用交换分区。建议生产环境直接禁用操作系统的交换分区,因为对于服务器来说,当内存用完时,交换到硬盘上会引起更多的问题。
开启bootstrap.memory_lock选项让ES锁定内存 -
最大线程数检查
ES将请求分解为多个阶段执行,每个阶段使用不同的线程池来执行,因此ES需要创建很多线程。
修改/etc/security/limits.conf文件的nprocs来设置 -
最大虚拟内存检查
Lucene使用mmap映射部分索引到进程地址空间,最大虚拟内存确保ES进程拥有足够多的地址空间
修改/etc/security/limits.conf文件,设置as为unlimited -
最大文件大小检查
Lucene分段文件和事务日志文件存储在磁盘,可能会非常大,如果超过最大文件大小会导致写入失败,因此最好将最大文件大小设置为无限
修改/etc/security/limits.conf文件,修改fsize为unlimited -
虚拟内存区域最大数量检查
Lucene需要将部分索引映射到地址空间,因此ES需要很多虚拟内存映射区,本项检查确保内核允许创建至少262144个内存映射区
在/etc/sysctl.conf文件中添加一行 vm.max_map_count=26144,然后执行sysctl -p永久生效 -
JVM 模式检查
OpenJDK提供了两种JVM的运行模式:client JVM模式与server JVM模式。client调优了启动时间和内存消耗,server具有更高的性能。该项检测要求是server模式。 -
串行收集检查
串行垃圾回收器适合单CPU机器,不适合ES,本项检查就是检查是否使用了串行垃圾回收器。ES默认使用CMS垃圾回收器。 -
系统调用过滤器检查
由于某些系统漏洞,攻击者可能取得进程的权限,从而拥有启动该进程的用户权限可以执行一些操作。
系统调用过滤器可以限制进程可以操作的系统调用函数
使用普通用户启动进程最合适 -
Early-access 检查
OpenJDK 为即将发布的版本提供了early-access版本,但是这个版本不适合线上使用,要想通过此项检查,要运行在JVM的稳定版本 -
G1GC检查
JDK8早期版本有问题,JDK 8u40之前都会受影响,本项检查验证是否是早期版本
4.2.6 启动内部模块
环境检查完毕,开始启动内部模块,调用内部模块的start方法
内部模块开始初始化内部数据、创建线程池、启动线程池
4.2.7 启动keepalive线程
启动keepalive线程,该线程本身不做任何工作,目的是保证ES程序的运行。因为主线程执行完启动流程后就退出了,该线程是唯一的用户线程,在JAVA程序中,至少要有一个用户线程,否则程序会退出
4.2.8 节点关闭流程
ES进程会捕获SIGTERM信号,调用各模块的stop方法,让它们有机会停止服务,安全退出
如果是主节点关闭,则集群会重新选主。如果主节点是单独部署即仅仅是主节点不是其他类型节点,那么可以跳过gateway和recovery阶段;否则新主需要重新分配旧主持有的分片
如果是数据节点关闭,则读写请求的TCP连接被关闭,对客户端来说写操作执行失败,但是写流程已经到达Engine环节的会正常写完,只是客户端无法感知结果,此时客户端重试如果使用自动生成ID,
则数据内容会重复
4.4 节点关闭流程顺序
关闭快照和HTTPServer,不再响应用户REST请求
关闭集群拓扑管理,不再响应ping请求(内部节点间不响应了)
关闭网络模块,让节点离线
执行各个插件的关闭流程
关闭IndicesService
4.5 分片读写过程中关闭
写入过程中关闭。线程写入数据时,会对Engine加写锁,IndexServices关闭时也要对Engine加写锁,因此会等待写操作执行完在关闭IndexServices,但是节点已经离线了,客户端的连接已经断了感知不到结果会认为执行失败。
读取过程中关闭。线程读取数据时,会对Engine加读锁,IndexServices关闭时要对Engine加写锁,因此会等待读操作执行完在关闭IndexServices,但是节点已经离线了,客户端的连接已经断了感知不到结果会认为执行失败。
4.6 主节点关闭
主节点正常执行关闭流程,当关闭集群拓扑管理时,集群重新选举Master
第五章
5.2 为什么使用主从模式
除主从模式外,还有一种选择是分布式哈希表
分布式哈希表是什么????????
主从模式适合节点数较少,网络中不必经常处理节点的加入和离开,因此更适合ES
分布式哈希表适合节点数较多,网络中节点经常加入和离开
5.3 选举算法
1. Bully算法
每个节点都有一个唯一的ID,使用该ID对节点进行排序,ID最高的节点就是leader节点。优点是易于实现
2. Paxos算法
优点是灵活性更强,可以解决更复杂的情况;缺点是太复杂
paxos算法思路详解??????????
5.4 相关配置
1. discovery.zen.minimum_master_nodes:最小主节点数
该参数可以防止脑裂、防止数据丢失
多处使用地:
1. 触发选主:选主之前,参选的节点数需要达到该值
2. 决定Master:选出的临时Master,判断加入自己的节点数是否达到该值,如果是那么确认选举成功
3. gateway选举元信息:向Master_eligible节点发送请求,获取元信息,响应数必须达到该值
4. Master发布集群状态:发布成功数量达到该值
参数值设置:该值应该设置为(master_eligible/2+1)
5.5 流程概述
ZenDiscovery选主过程:
1. 每个节点计算最小的已知节点ID,该节点为临时Master,向该节点发送领导投票
2. 如果一个节点收到quorum值的投票数,并且该节点也为自己投票,那么它就确认是Master,开始选举集群元信息
5.6 流程分析
整体流程概括为:选举临时Master,如果本节点当选,则等待确立Master;如果其他节点当选,则尝试加入集群,然后启动节点失效探测器
5.6.1 选举临时Master
选举临时Master过程:
1. 每个节点ping所有节点,获取节点列表,ping结果不包含本节点,将本节点单独添加到结果中
2. 构建两个列表
activeMasters:活跃的Master列表。遍历第一步拿到的节点列表(自己除外),将节点认为的Master添加到该列表中,遍历过程中如果配置了discovery.zen.master_election.ignore_non_master_pings为true
(默认是false),而节点又不是Master_eligible节点那么跳过该节点
masterCandidates列表:Master候选者列表。遍历第一步拿到的节点列表,去掉不是Master_eligible的节点,添加到这个列表
3. 选举临时Master
如果activeMasters不为空那么从activeMasters中选举合适的节点作为Master;否则从masterCandidates中选举合适的节点为Master,可能选举成功,也可能选举失败
从masterCandidates中选主时,首先需要判断当前候选者人数是否达到quorum值,如果没达到那么选举失败;如果达到quorum值,那么选择ID值最小的节点作为Master节点
从activeMasters列表中选择,选择ID最小的节点作为Master节点
5.6.2 投票与得票的实现
发送投票就是发送加入集群请求,得票就是申请加入该节点的请求数量
当节点检查收到的投票是否足够时,就是检查加入它的连接数是否足够,其中会去掉不是Master_eligible节点的投票
5.6.3 确立Master或加入集群
选举出的临时Master有两种情况,自己是临时Master或者自己不是临时Master
自己是临时Master那么就等待确立Master,否则加入自己认为的临时Master
1. 如果自己是临时Master
1. 等待足够多的Master_eligible节点加入(投票达到法定数)
2. 超时(默认是30s)后还没有达到法定值的join请求,则选举失败,进行新一轮选举
3. 成功后发布集群状态
2. 如果自己不是临时Master
1. 不再接受其他节点的join请求
2. 向自己认为的临时Master发送加入请求,并等待回复
3. 最终当选的Master会先发布集群状态,才确认客户的join请求
5.7 节点失效检测
节点失效检测会监控节点是否离线,然后处理其中的异常
需要启动两种失效探测器:
在Master节点,启动NodesFD,定期探测加入集群的节点是否活跃
在非Master节点,启动MasterFD,定期探测Master节点是否活跃
失效探测都是定期(默认1S)发送ping请求探测节点是否正常,当失败达到一定次数(默认为3次),就认为节点离线,开始处理节点离开事件
5.7.1 NodesFD事件处理
检查当前集群master_eligible节点数是否达到quorum值,如果不足那么放弃Master身份,重新加入集群。目的是防止出现脑裂。
5.7.2 MasterFD事件处理
重新加入集群,本质就是在进行一次选主流程
第六章 数据模型
6.1 PacificA算法
主要由两部分组成:存储管理和配置管理
存储管理:负责数据的读取和更新,使用多副本的方式保证数据的可靠性和可用性
配置管理:对配置信息进行管理,维护所有配置信息的一致性
相关概念:
副本组:互为副本的数据集合。只有一个副本是主数据,其他为从数据
配置信息:配置信息描述了一个副本组有哪些副本,主副本是谁,以及各个副本都位于哪个节点
配置信息版本:每次配置信息发生变更时递增
Serial Number:代表写操作的顺序,每次写操作时递增。每个主副本维护自己递增的SN。
Prepared List:写操作准备序列。存储写请求的列表,将请求按照SN排序,向列表中插入的写请求的SN必须大于列中的最大的SN。每个副本都有自己的写操作准备序列。
Commited List:写操作提交序列。
6.1.1 数据副本策略
多个分片副本存在一个主副本和多个从副本。所有数据写入操作都进入主副本,当主副本出现故障无法访问时,系统从其他从副本中选择合适的副本作为新的主副本。
数据写入流程如下:
1. 写请求进入主副本,主副本执行写操作,并为写操作生成SN,使用SN创建UpdateRequest请求,将该请求放入写操作准备序列
2. 主副本节点将携带SN的UpdateRequest请求发送到从副本节点,从副本节点收到请求后执行写操作,并将请求插入写操作准备序列,插入后给主副本节点回复ACK
3. 主副本节点收到所有从副本节点的ACK后,确认数据成功写入所有从副本节点,此时认为可以提交了,将UpdateRequest写入提交序列,并将Commit Point向前移动
4. 主副本节点回复客户端更新成功,并向所有从副本节点发送提交请求,告诉从副本节点自己的commit point,从副本节点收到请求后,将自己的commit point移动到相同位置
主副本节点的写操作提交列表 < 从副本节点的写操作准备序列
从副本节点的写操作提交序列 < 主副本节点的写操作提交序列
6.1.2 配置管理
全局配置管理器负责管理所有副本组的配置,节点可以向管理器发送添加/移除副本的请求,该请求需要携带配置的版本号,只有携带的版本号和管理器记录的版本号一致才可以进行配置信息的修改,如果请求成功,那么配置会被赋予一个新的版本号
6.1.3 错误检测
分布式系统经常存在网络分区等情况,因此就会存在旧主副本和新主副本同时存在的情况,PacificA算法使用“租约”机制来避免产生该情况
“租约”机制: PacificA算法概念对应到ES: 6.2 ES的数据副本模型 6.2.1 基本写入模型 6.2.2 写故障处理 对于主分片自身错误的情况,它会发送一个消息给Master。这个写操作会等待(默认最多一分钟)Master提升一个副分片为主分片。这个操作会被转发给新的主分片。 当副分片操作发生错误,或者因为网络阻塞导致主分片无法将操作发送到副分片,主分片会向Master发送请求,将副分片从in-sync列表中移除,当Master成功移除副分片后,主分片会确认这次操作。Master移除副分片后 6.2.3 基本读取模型 6.2.4 读故障处理 6.2.6 系统异常 6.3 Allocation IDs 6.3.1 安全地分配主分片 创建新索引时,分配主分片有很大的灵活性,会将集群均衡和一些其他约束考虑在内。 分配已创建的分片副本情况比较少见,例如:集群完全重启所有分片副本都处于未分配状态、或者短期内所有分片副本都不可用。主节点会收集所有节点的分片信息,只有allocationID存在于in-sync列表中分片副本才可能 6.3.2 将分配标记为陈旧 6.3.4 不会丢失全部 6.4 Sequence IDs Primary Terms:由主节点分配,每次主分片发生变化时递增。通过它可以拒绝来自旧主分片迟到的操作 6.4.2 本地、全局检查点 全局检查点之前的操作保证都被所有分片副本处理完毕 6.4.3 用于快速恢复 6.5 _version 第七章 写流程 7.2 可选参数 参数如下: 7.3 Index/Bulk基本流程 7.4 Index/Bulk详细流程 7.4.1 协调节点流程 参数检查 处理pipeline请求 如果Index/Bulk请求中指定了pipeline参数,那么先用pipeline对文档数据进行处理。如果本节点不具备预处理资格,则将请求随机转发到具备预处理资格的节点。 创建索引请求会发送给主节点,当主节点创建索引成功并成功发布集群状态后会返回执行成功响应 对请求的预处理 合并请求,构建基于Shard的请求 路由算法 若自定义routing值不够随机,可以使用index.routing_partion_size配置来减少倾斜的风险,该配置值越大数据分布越均匀 7.4.2 主分片节点流程 检查请求 是否要延迟执行 判断主分片是否已经发生迁移 检测写一致性 写Lucene和translog flush translog 写副分片 处理副分片写入失败 7.4.3 副分片节点流程 7.5 IO异常处理 Engine的关闭过程: Master收到分片失败消息后,通过reroute转移失败的分片,并更新集群状态 7.5.3 异常流程总结 7.6 系统特性 第八章 GET流程 8.1 可选参数 8.2 GET基本流程 协调节点在选择分片副本节点时采用轮询算法达到负载均衡 8.3 GET详细分析 8.3.1 协调节点 8.3.2 数据节点 8.4 MGET流程分析 第九章 Search流程 9.1 索引和搜索 9.1.1 建立索引 分析器实现如下功能: 9.1.2 执行搜索 9.2 search type TODO 再次详看两者的区别??????? 9.3 分布式搜索过程 搜索涉及协调节点、数据节点 9.3.1 协调节点流程 9.3.2 执行搜索的数据节点 9.4 小结 第十章 索引恢复流程分析 索引恢复可以分为:主分片恢复和副分片恢复 索引恢复的触发条件包括:节点加入和离开、索引的_open操作等 恢复工作一般经历以下几个阶段: 10.1 相关配置 10.3 主分片恢复流程 10.4 副分片恢复流程 核心处理流程包括两个阶段 10.4.2 synced flush机制 10.4.3 副分片节点处理流程 10.4.4 主分片节点处理过程 phase1: phase2: 10.5 recovery速度优化 10.6 如何保证副分片和主分片一致 10.7 recovery相关监控命令 10.8 小结 第十一章 gateway模块分析 11.1 元数据 元数据又分为以下几种: 11.2 元数据的持久化 11.3 元数据的恢复 gateway的recovery模块负责找到正确的元数据,应用到集群 gateway模块负责集群层和索引层的元数据恢复 11.4 元数据恢复流程分析 11.4.1 选举集群级和索引级元数据 11.4.2 触发allocation 第十二章 allocation模块分析 新建索引、已有索引分片分配过程也不同。但是都由allocators、deciders完成。allocators尝试寻找最优的节点来分配分片,deciders负责判断并决定是否进行此次分配。 12.2 触发时机 12.4 allocators 12.5 核心reroute实现 12.6.1 集群启动时reroute的触发时机 12.6.2 流程分析 主分片分配完成后就进入recovery,副分片的recovery要等待主分片recovery完才进行 第十三章 Snapshot模块分析 13.1 仓库 13.2 快照 13.2.1 创建快照 ignore_unavailable:跳过不存在的索引,默认为false 13.2.2 获取快照信息 快照执行期间会经历以下几个阶段: 查询正在运行中的快照: 13.2.3 快照status 13.2.4 取消、删除快照和恢复操作 13.3 从快照恢复 恢复方式: 13.3.1 部分恢复 13.3.2 恢复过程中更改索引设置 13.3.3 创建快照实现原理 创建快照过程: 13.4.1 Lucene文件格式简介 13.4.2 协调节点流程 13.4.3 主节点流程 13.4.4 数据节点流程 特点分片快照实现: 13.5 删除快照实现原理 13.5.1 协调节点流程 13.5.2 主节点流程 快照删除: 数据节点取消过程: 检查标识的地方: 运行中的快照被取消后,复制到一半的数据由主节点负责清理,在主节点集群状态发布成功后的快照删除操作中执行 第十四章 Cluster模块分析 14.2 内部封装和实现 14.2.1 MasterService 14.2.2 ClusterApplierService 实现一个Applier(集群状态处理器) 实现一个Listener(集群状态监听器) 14.2.3 线程池 运行集群任务的线程池 应用集群状态的线程池 14.3 提交集群任务 14.3.1 内部模块如何提交任务 任务有很多种,比如:ClusterStateUpdateTask、AckedClusterStateUpdatedTask、LocalClusterUpdateTask等 以ClusterStateUpdateTask为例,该类实现了3个接口,分别是: 14.3.2 任务提交过程实现 提交过程中根据任务的batchingKey将任务添加到hashMap中 14.4 集群任务执行过程 14.5 集群状态发布过程 两阶段过程如下: 14.5.1 增量发布实现原理 14.5.2 二段提交总流程 14.5.3 发布过程 14.5.4 提交过程 14.6 应用集群状态 第十五章 Transport模块分析 15.1 配置信息 传输模块有一个专用的tracer日志,当它被激活时,日志系统会记录所有传入和传出的请求,可以通过动态设置org.elasticsearch.transport.TransportService.tracer为TRACE级别来开启,还可以使用include和exclude通配符来控制trace的内容,默认情况下除了ping请求之外会跟踪所有请求 15.1.2 通用网络配置 15.2 Transport总体架构 15.2.1 网络层 网络模块初始化 Netty4Transport Netty4HttpServerTransport 15.2.2 服务层 15.3 REST解析和处理 15.4 RPC实现 15.4.1 RPC的注册和映射 ActionModule类中注册 TransportService类中的注册 15.4.2 根据Action获取处理类 15.5 总结 第十六章 ThreadPool模块分析 16.1 线程池类型 16.1.1 fixed 16.1.2 scaling 16.1.3 direct 16.1.4 fixed_auto_queue_size 16.2 处理器设置 16.3 查看线程池 16.3.1 cat thread pool 当请求被拒绝执行时,客户端会收到429错误码,客户端应该进行重试 16.3.2 nodes info 节点信息API返回的信息非常大,其中与线程池相关的在thread_pool字段中 16.3.3 nodes stats 16.3.4 nodes hot threads 返回信息的结构: 16.3.5 JAVA的线程池结构 ThreadPoolExecutor几个重要参数如下: 16.4 ES的线程池实现 成员变量: 16.4.1 ThreadPool类结构和初始化 16.5 其他线程池 16.6 总结 第十七章 Shrink原理分析 17.1 准备源索引 17.2 缩小索引 17.2 Shrink工作原理 为什么要硬链接不能软链接 经过链接过程后,目的索引的主分片已经就绪,副分片还是空的,通过recovery将主分片数据复制给副分片 第十八章 写入速度优化 18.1 translog flush间隔 index.translog.sync_interval:120s,按照该参数设置的时间周期刷盘,默认是5s,不可低于100ms index.translog.flush_threshold_size:1024MB,达到该大小时刷盘以及产生新的分段 18.2 index refresh间隔 18.3 段合并优化 18.4 indexing buffer 这个buffer大小的配置需要除以这个节点上所有shard数量: 18.5 使用bulk请求 18.6 磁盘间分片均衡 18.7 节点间任务均衡 18.8 索引过程调整和优化 18.8.2 调整字段mappings 18.8.3 调整_source字段 18.8.4 禁用_all字段 禁用原因: 18.8.5 对Analyzed字段禁用Norms 18.8.6 index_options设置 第十九章 搜索速度优化 19.2 使用更快的硬件 19.3 文档模型 19.4 字段映射 19.5 避免使用脚本 19.6 优化日期搜索 19.7 为只读索引执行force merge 19.8 预热全局序号(global ordinals) 19.10 execution hint 19.11 预热文件系统cache 19.12 转换查询表达式 19.13 调节搜索请求中的batched_reduce_size 19.14 使用近似聚合 19.15 深度优先还是广度优先 19.16 采用自适应副本选择(ARS)提升ES响应速度 第二十章 磁盘使用量优化 20.1.2 索引映射参数 某些情况下,存储字段是有意义的: 20.2 优化措施 20.2.2 禁用doc values 20.2.3 不要使用默认的动态字符串映射 20.2.5 禁用_source 20.2.6 使用best_compression 20.2.7 Force Merge 20.2.8 Shrink Index 20.2.9 数值类型长度够用就好 20.2.10 在文档中以相同的顺序放置字段 第二十一章 综合应用实践 21.1.2 单节点还是多节点部署 21.1.3 移除节点 21.1.4 独立部署主节点 21.2 节点层 21.2.2 为系统cache保留一半物理内存 21.3 系统层 21.3.2 配置Linux OOM Killer 设置方式: 21.3.3 优化内核参数 TCP相关参数: TCP的接收窗口 4.vm相关参数 从系统缓存刷到磁盘的三种时机: 脏数据的刷盘阈值: 21.4 索引层 21.4.2 索引轮转 21.4.5 Force Merge POST /twitter/_forcemerge 21.4.8 延迟分配分片 21.4.9 小心地使用fielddata 21.5 客户端 1.5.2 注意429状态码 导致该问题的原因是写入并发量过多,应当降低写入并发 21.5.3 为读写请求设置比较长的超时时间 21.6 读写 21.6.2 避免索引巨大的文档 21.6.3 避免使用多个_type 21.6.4 避免使用_all字段 21.6.5 避免将请求发送到同一个协调节点 21.7 控制相关度 通过Painless脚本控制搜索评分 第二十二章 故障诊断 22.2 使用Explain API分析未分配的分片 22.2.1 诊断未分配的主分片 在指定主分片运行Explain API 22.3 节点CPU使用率高 22.4 节点内存使用率高 ES中占用内存比较大的数据结构: 22.5 Slow Logs 22.6 分析工具 进程级IO状态 去看linux性能调优 专章
主副本定期向从副本收取租约,那么就存在两种情况:
1. 主副本在一定时间内(master_level)没有收到从副本的租约回复,那么说明从副本异常,主副本向配置管理器发送请求,请求删除从副本,并将自己降级,不再作为主副本
2. 从副本在一定时间内(follower_level)没有收到主副本的租约请求,那么说明主副本异常,从副本向配置管理器发送请求,请求删除主副本,并将自己升级为主副本。如果有多个从副本,那么谁先执行成功谁就是主副本。
只要不存在时钟漂移,并且master_level
Master类似配置管理器,管理所有配置信息
集群状态类似副本组配置信息
SequenceNumber和CheckPoint类似SN和commit Point
写操作保持副本之间的数据同步,读操作从副本读取的过程称为数据副本模型
ES的数据副本模型基于主备模式,主分片是所有写操作的入口,它负责验证写操作是否有效。一旦主分片接受一个写操作,主分片的副分片也会接受该操作。
写入过程:
1. 请求到达协调节点,协调节点校验请求是否合法,如果不合法则拒绝,否则根据集群状态,将请求路由到对应的主分片节点
2. 主分片节点收到写请求后,在本地执行写操作,并且在执行过程中校验字段内容,如果字段内容不合规则拒绝操作(例如字段串的长度超过Lucene定义的长度)
3. 主分片本地执行成功后,把请求转发到in-sync列表中的从副本节点,如果有多个从副本节点那么并行转发
4. 所有从副本节点执行成功并回复主分片节点后,主分片节点告诉协调节点执行成功,协调节点告诉客户端执行成功
写入期间可能发生很多错误——硬盘损坏、节点离线,主分片必须汇报这些错误信息给主节点
Master同样会监控节点的健康,并且可能会主动降级主分片,这通常发生在主分片节点离线的时候
会重新分配一个新的副分片,让集群状态保持健康
读取基本流程如下:
1. 请求发送到协调节点,协调节点将请求转发到相应的分片节点
2. 转发请求时,会从每个分片的副本组中选择一个转发(不论是主分片还是副分片),ES默认使用轮询机制转发
3. 分片节点处理完请求后将结果返回给协调节点
4. 协调节点合并结果,返回给客户端。(注意,如果是根据ID查询文档的请求,那么没有这一步,因为只会将请求转发给一个分片)
当分片副本无法处理读请求时,协调节点会从分片的副本组中选择另外一个副本进行请求转发,当没有可用的分片副本时会导致错误。但是,在某些情况下,例如_search,ES会倾向于尽早响应,将部分结果返回,也不等待
问题被解决。
可以在响应结果的_shards字段中检查本次结果是完整的还是部分的。
单个缓慢的分区副本会影响整体副本组的写入效率以及单个副本的读取效率
ES从5.x版本开始引入Allocation IDs的概念,用于主分片选举。每个分片副本都会有一个唯一的Allocation ID,同时集群元信息中有一个列表,记录哪些分片副本拥有最新的数据。
分片分配决策过程在主节点完成,结果记录在集群状态中。分片分配决策包含两部分:哪个分片应该分配到哪个节点,以及哪个分片作为主分片、哪些分片作为副分片。
主节点广播集群状态到集群所有节点,这样每个节点都有了集群状态,它们就可以实现请求的智能路由。
选举为主分片。
处理写请求过程中,主分片执行成功,但是部分副分片执行失败,那么失败的副分片就会丢失一些数据,如果这些失败的副分片仍然可以被选举为主分片,那么当它们被选举为主分片时,就会丢失数据
解决该问题有两种方法:
1. 写请求失败,回滚所有已写的操作
2. 确保有差异的副分片不会被选举为主分片
ES选择第二种,保证写入的可用性:当副分片写入失败时,主分片会给主节点发送请求,请求将失败的副分片从In-sync列表中移除,当主分片收到主节点确认移除的响应后,向客户端确认写请求。
当in-sync列表中分片副本全部不可用时,ES不会将陈旧的副本提升为主副本,但是我们可以手动干预将陈旧的副本提升为主分片,这样会丢失一些更新的数据
ES也支持将空分片副本分配为主分片,这样会丢失所有数据
ES从6.0版本开始引入Sequence IDs,使用唯一的ID标记每个操作,通过这个ID有了索引操作的总顺序
SequenceID由Primary Terms、Sequence Numbers组成
Sequence Numbers:由主分片分配,每次写操作递增1,不同的主分片有各自的计数器
全局检查点的作用:比较分片副本之间的操作差异时直接从全局检查点后开始比较即可,这样比较的数据较少
每个分片副本都会维护一个自己的本地检查点,当所有本地检查点相同时推进全局检查点
当ES恢复一个分片时,需要保证和主分片数据一致。旧的恢复模式是复制主分片的整个Lucene分段,如果分段很大非常耗时。
有了全局检查点之后,可以重放主分片translog中全局检查点之后的操作来恢复分片数据,因此应该多保留一些translog。
每个文档都有一个版本号(_version),当文档被修改时版本号递增。ES使用这个版本号保证变更以正确的顺序执行,如果旧版本号的操作在新版本号之后那么会被忽略
版本号还用来防止并发操作,类似乐观锁
7.1 对文档操作的定义
文档的操作类型有四种:
1. INDEX
2. CREATE
3. UPDATE
4. DELETE
INDEX:向索引"put"一个文档称为索引一个文档
CREATE:put请求设置op_type参数为create,代表创建文档。若文档已存在会报错。
UPDATE:默认情况下,put一个文档,若文档已存在那么更新文档。
DELETE:删除文档
Index API和Bulk API有一些可选参数。
1. version
文档的版本号,用来实现乐观锁
2. version_type
控制版本号比较机制。默认为internal,文档当前的版本号和请求的版本号相同时则写入;还有external,文档当前版本号小于请求的版本号时则写入。
3. op_type
可设置为create。文档不存在时创建,文档已存在时报错。
4. routing
ES默认使用文档ID进行路由,指定routing可使用routing值进行路由。
5. wait_for_active_shards
控制写一致性。当指定数量的分片副本可用时才执行写操作,默认为1,当主分片可用时就可以执行写操作
6. refresh
写入完毕后执行refresh,使其对搜索可见
7. timeout
请求超时时间,默认为1分钟
8. pipeline
指定事先创建好的pipeline的名称
写操作必须先在主分片执行成功后,才能复制到相关副分片执行。
写入单个文档的流程如下:
1. 客户端向Node1发送写请求
2. Node1根据文档的ID确定文档所属的分片,根据集群状态中的内容路由表找到该分片的主分片所在节点NODE3,将写请求转发到Node3
3. Node3写请求执行成功后,将请求并行转发到副分片节点NODE1和Node2,等待返回结果。当所有副分片都报告成功,NODE3向协调节点报告成功,协调节点向客户端报告成功
协调节点主要负责创建索引、转发请求到主分片节点、等待响应、回复客户端
收到客户端请求后,对请求的参数进行检查,有问题直接拒绝
校验的参数如下:
index:不可为空
type:不可为空
source:不可为空
contentType:不可为空
opType:如果操作类型为"create",则校验VersionType必须为internal且Version不可为MATCH_DELETED
resolvedVersion:校验解析的Version是否合法
versionType:不可为FORCE类型,此类型已废弃
id:不为空时,长度不可大于512
数据预处理通过定义pipeline和processers实现。pipeline是多个processor组成的链,processor按照声明的顺序依次执行。
如果配置为自动创建索引(默认允许),则对于请求中涉及的多个索引,若索引不存在则创建,对于创建失败的请求标记为失败,其他索引请求正常执行后面的过程
获取最新的集群状态,遍历所有请求,若id不存在生成一个UUID作为文档id
将用户的bulkRequest重新组织为基于shard的请求列表。这里并未确定主分片节点。
基于shard的请求结构如下:
Map
ShardId类包括所属索引和分区号
根据routine值计算目标shardID
一般公式如下:
shardID = hash(routine) % num_of_primary_shards。默认情况下,routine值是文档id。
使用该配置后,路由公式如下:
shardID = (hash(routing) + hash(_id) % routing_partition_size) % num_of_primary_shards
根据集群状态中的内容路由表确定主分片所在节点,转发请求并等待响应。
若某个分片部分doc写入失败,那么将异常信息填入响应,整体请求做成功处理
主分片负责在本地写入,写成功后转发给副分片节点,等待响应,回复协调者节点
检查要写的是不是主分片,AllocationID是否符合预期,索引是否处于关闭状态
判断请求是否要延迟执行,如果要那么放入延迟队列,否则继续下面的流程
如果已经发生迁移,那么将请求转发到迁移的节点
检测活跃的分片副本是否足够,如果不够拒绝写入。默认为1,只要主分片活跃即可。
遍历请求,处理动态字段映射,然后调用Engine的index方法写入doc
写入doc时,先写lucene后写translog
写入lucene前生成Sequence Number、Version
根据配置的translog刷盘策略进行刷盘。分为定时刷盘和立即刷盘。
将请求并行转发给副分片节点,并等待响应,无论响应是成功还是失败。然后告诉协调节点哪些请求成功了、哪些请求失败了。
主分片会给主节点发送请求,让主节点将副分片从in-sync列表中移除
主节点会发布新的集群状态,在新的集群状态中,写入失败的副分片将:
副分片节点流程和主分片节点流程相同,写完后回复主分片节点
IO层面的写入失败可能意味着磁盘损坏,会触发Engine类检查当前是否应该关闭Engine
一个shard上的CRUD操作都封装在Engine中
Get操作不会触发分片迁移
关闭分片并给Master发送分片失败消息
1. 如果是在协调节点转发请求时失败,那么等待集群状态更新,拿到更新后进行重试,如果重试失败,仍然等待集群状态更新,直到一分钟后超时,超时后整个请求失败
2. 主分片写入是一个阻塞的过程,若主分片写入失败那么不会将请求转发给从副本,请求直接失败。部分从副本写入失败,写入请求也算成功
3. 无论主分片还是副分片写入一个doc时,如果失败,那么会关闭本地分片并向Master报告,Master会将该分片从in-sync列表中删除以及进行分片转移
1. 数据可靠性
通过副本机制以及事务日志保证数据可靠
2. 服务可用性
在可用性和一致性之间,ES默认偏向于可用性,只要主分片可用就可以执行写入
3. 一致性
是弱一致性,只要主分片写成功,写入操作就算成功,因此主分片和副分片读取的数据可能不同
4. 原子性
索引的读写、别名更新都是原子操作,不会出现中间状态。但bulk不是原子操作。
5. 扩展性
主副分片都可以承担读请求,分担系统负载
ES的读取分为GET和Search,这两者差距较大。GET/MGET必须指定三元组:_index,_type,_id。GET/MGET是通过文档id从正排索引中获取数据,而Search是根据关键词从倒排索引中获取数据。
GET请求URI中可设置的一些参数:
1. realtime
默认为true。GET请求默认是实时的,不受索引刷新(refresh)影响,如果文档已经更新但还没有refresh,则GET API会发出一个refresh调用,使文档可见
2. source filtering
默认情况下,返回文档的全部内容(在_source字段中)。可以设置为false,不返回文档内容。同时可以设置_source_include和_source_exclude过滤返回的文档部分字段
3. stored Fields
对于索引设置中store设置为true的字段,指定返回哪些字段
4. _source
只返回文档原始内容,不返回_id等元信息
5. routing
自定义routing
6. preference
默认情况下,GET API从分片的多个副本中随机选择一个,通过该参数可以选择从主分片读取或者尝试从本地读取
7. refresh
默认为false,若设置refresh为true,则在读取之前先执行刷新操作,这对写入操作有负影响
8. version
指定文档版本号,当文档实际版本号和指定的版本号不同时,ES返回409错误
1. 客户端向协调节点Node1发送请求
2. Node1根据路由算法和文档的ID计算得出文档所在分片为分片0,根据集群状态中的内容路由表知道分片0有3个分片副本,选择一个分片副本所在节点Node2发送读请求
3. Node2将文档返回给协调节点,协调节点将内容返回给客户端
在读取时,文档可能已经存在于主分片,但还没有复制到副分片
GET/MGET流程涉及到两个节点:协调节点和数据节点
1. 内容路由
获取最新集群状态
根据路由算法计算目标分片ID
有了目标分片ID后,结合请求参数中指定的优先级和集群状态确定目标节点,由于分片可能存在多个副本,因此计算出的是一个列表。优先级只是把匹配到优先级的节点放到目标节点列表的前面。
2. 转发请求
向目标节点转发请求
如果目标节点是本节点,那么直接在本地处理请求获取数据,返回给协调节点
如果目标节点不是本节点,那么异步发送网络请求,并注册handler等待处理异步返回结果直至超时
若请求在目标节点处理失败,那么协调节点从目标节点列表中选择下一个节点转发
查询文档内容,根据参数对文档内容进行过滤,将过滤后的文档内容返回给协调节点ES5.x之前,如果开启realtime选项,刚写入的数据从translog中获取;ES5.X开始,只从Lucene中读取,实现机制变成执行refresh
1. 遍历请求中所有doc,计算出每个doc的路由信息,得到key为shardID的request Map
2. 循环处理好每个分片级请求,处理每个分片上的doc
3. 收集Response,全部Response返回后执行finishHim(),给客户端返回结果回复的文档顺序和请求的顺序一致。如果部分文档读取失败,不影响其他结果,查询失败的doc会在回复中指明
协调节点接受客户端请求,在协调节点,搜索任务被执行成两个阶段过程,即query then fetch,真正执行搜索的节点是数据节点
协调节点先将请求转发给索引的所有分片(某一个副本),然后协调节点合并所有分片的结果,再根据文档ID获取文档内容
ES中的数据可以分为两类:精确值和全文
精确值:比如日期、IP、用户ID等
全文:指文本内容。例如,一条日志、或者邮件的内容精确值在查询时,比较的是二进制,查询要么匹配,要么不匹配
全文在查询时,只能给出“看起来像”你要查询的东西,因此把查询结果按相似度排序,评分越高,相似度越大
如果是全文数据,使用ES中的分析器对文本内容进行分析
1. 字符过滤器
对字符串进行预处理。例如去除HTML、将&转换成and等
2. 分词器
将字符串分割成单个词元(Token)
3. 语言处理器
对词元进行处理。例如:删除停用词、将词元转换成小写、根据同义词表增加词元。输出的结果称为词(Term)
分析完毕后,将分析器输出的词传递给索引组件,生成倒排和正排索引,再存储到文件系统中
搜索调用Lucene完成,如果是全文搜索,则:
1. 使用查询字段的分析器对查询内容进行分析,得到Term列表
2. 根据查询语句构建语法树
3. 找到符合语法树的文档
4. 对匹配到的文档进行相关性评分,评分策略一般使用TF/IDF
5. 根据评分结果进行排序
ES目前有两种搜索类型:
DFS_QUERY_THEN_FETCH
QUERY_THEN_FETCH
两种类型的区别在于查询阶段,DFS查询阶段的流程要多一些,它使用全局信息获取更准确的评分
一次搜索请求只会命中所有分片副本组中的一个副本
Query阶段:
1. 客户端发送search请求到协调节点
2. 协调节点将请求转发给所有分片副本组中的一个副本
3. 每个分片副本节点本地执行查询并在本地进行打分,添加结果到大小为from+size的本地优先队列中
4. 每个分片副本节点返回各自本地优先队列中文档的ID和评分给协调节点,协调节点根据评分将结果添加到自己的本地优先队列中,产生一个全局排序后的列表协调节点在转发search请求时,也采用轮询的机制从分片副本组中选择一个分片副本
TODO 如果某一个分片执行搜索失败,那么整个搜索算不算失败????
Fetch阶段:
Query阶段协调节点只拿到了文档ID,并没有拿到文档数据这就是Fetch阶段要做的事
1. 协调节点针对FROM开始,Size个文档ID做GET查询,向相关Node发送GET请求。(这里没有在使用路由算法计算目标分片id,而是针对查询阶段中结果不为空的分片发送要查询的文档ID)
2. 分片节点向协调节点返回文档数据
3. 协调节点等待所有文档数据返回,然后返回给客户端
响应Query请求:
查询时,先看是否允许cache,由以下配置决定:Index.requests.cache.enable,默认为true,会把查询结果放到cache中,查询时优先从cache中取。这个cache由节点的所有分片共享,基于LRU算法:空间满的时候删除最近最少使用的数据
搜索过程:
execute():调用lucene实现搜索
rescorePhase:算分
suggestPhase:自动补全及纠错
aggregationPhase:实现聚合总结:
1. 慢查询Query日志的统计时间在于本阶段的处理时间
2. 聚合操作在本阶段实现,在Lucene搜索后完成
响应Fetch请求
根据文档ID获取文档内容,填充到SearchHits,返回结果
总结:
1. 慢查询Fetch日志的统计时间在于本阶段的处理时间
聚合是在ES中实现的,而非Lucene
Query请求和Fetch请求之间是无状态的,除非是scroll方式
分页搜索不会单独"Cache",cache和分页没有关系
搜索需要遍历lucene索引的所有分段,因此合并分段对搜索性能有好处
索引恢复是ES恢复数据的过程,恢复的数据是写入成功的,但是还未刷盘的lucene分段。例如,系统异常重启,写入磁盘的数据还存在文件系统缓存中还未刷盘,如果不把这些未刷盘的数据找回来,则会丢失一些数据。
另一方面,副分片数据要和主分片保持一致。
INIT:恢复尚未启动
INDEX:恢复Lucene文件,以及在节点间复制索引数据
VERIFY_INDEX:验证索引
TRANSLOG:启动engine,重放translog,建立lucene索引
FINALIZE:清理工作
DONE:完毕
indices.recovery.max_bytes_per_sec:主副分片之间传输数据的速度,默认为40M/S,设置为0则不限速
indices.recovery.retry_delay_state_sync:由于集群状态同步导致恢复失败时,重试前的等待时间,默认500ms
indices.recovery.retry_delay_network:由于网络导致恢复失败时,重试前的等待时间,默认为5s
indices.recovery.internal_action_timeout:某些RPC恢复请求的超时时间,默认为15min
1. INIT
分片标记为INIT状态
校验分片是否为主分片、分片状态是否异常
2. INDEX
从Lucene读取最后一次提交(刷盘)的分段信息,获取其中的版本号,更新当前索引版本
3. VERIFY_INDEX
验证当前分片是否损坏,是否验证取决于配置:index.shard.check_on_startup
配置有如下值:
false:默认值,不检查分片是否损坏
checksum:检查物理损坏
true:检查物理和逻辑损坏,这将消耗大量的内存和CPU
fix:检查物理和逻辑损坏。损坏的分段将被集群自动删除,这将导致数据丢失
4. TRANSLOG
Lucene索引内部维护了一个"提交点",该提交点记录了当前lucene索引刷入磁盘的分段。
根据最后一次提交信息确定事务日志中哪些数据需要重放,对事物日志做快照。重放事物日志的快照将新数据刷入磁盘。
5. FINALIZE
执行refresh操作,将缓冲的数据写入文件,但不刷盘
6. DONE
进入DONE阶段前再次执行refresh,然后更新分片状态为DONE至此,主分片恢复完成,对恢复结果进行处理。
如果恢复成功,向Master发送分片已启动的RPC请求。
如果恢复失败,关闭Engine,向Master发送分片失败的RPC请求。
副分片恢复的核心就是从主分片拉取lucene分段和translog进行恢复
1. phase1
在主分片获取translog保留锁,保证主分片translog不被删除。然后调用lucene接口对shard做快照,快照中的数据是已经刷到磁盘的数据,把这些快照数据复制到副本片。在阶段1结束之前,会告诉副分片启动engine,在阶段2之前,副分片就可以处理写请求。
2. phase2
对主分片的translog做快照,快照中包括从阶段1开始到执行快照期间的所有索引操作,将translog快照发送到副分片重放。由于阶段1要复制主分片的快照数据,所以非常漫长,在ES6.X中,有两个机会可以跳过phase1:
1. 如果可以基于恢复请求中的SequenceNumber进行恢复,则跳过phase1
2. 如果主副分片有相同的syncid且doc数相同,则跳过phase1
默认5分钟内如果索引没有任何写入操作,那么会执行synced flush,生成一个唯一的syncid,写入分片所有副本中
synced flush本质上就是一个普通的flush操作,只是在lucene的提交过程中多写入一个syncid。原则上,在没有数据写入的情况下,各分片在同一时间"flush"成功后,应该具有相同的lucene索引数据。
但是synced flush过程中不能有写入操作,如果syncer flush过程中有写入请求,那么ES选择写入可用性,让synced flush失败
分片上执行普通的flush操作会删除已有的syncid
副分片的VERITY_INDEX、TRANSLOG、FINALIZE三个阶段都由主分片发送的RPC调用触发
将分片状态设置为INIT
构建向主分片发送的StartRecoveryRequest请求,请求中包括syncid
INDEX阶段负责将主分片的Lucene数据复制到副分片节点
向主分片发送startRecovery请求,并阻塞当前线程,等待主分片响应,收到响应后直接进入DONE阶段
主分片执行完phase1后,向副分片发送prepare_translog的RPC请求。副分片对此请求的主要处理是启动Engine
副分片的VERIFY_INDEX、TRANSLOG两个阶段也是在对这个请求的处理中触发的
TRANSLOG阶段主要负责将主分片的TRANSLOG数据复制到副分片进行重放
主分片节点执行完phase2,向副分片发送recovery/finalize请求,副分片收到请求后先更新全局检查点,然后执行refresh操作
对恢复成功和失败的处理
主分片节点收到副分片发送的startRecovery请求后
1. 获取translog保留锁—保证translog不被删除
2. 判断请求的序列号是否小于主分片的localCheckPoint以及translog中的数据是否包含请求的序列号(数据是否足够恢复)。如果translog中的数据足够恢复,那么就通过请求的序列号恢复,跳过phase1,否则调用Lucene接口对分片做快照,执行phase1
3. phase1执行完后,向副分片发送prepare_translog请求,阻塞等待副分片启动Engine
4. 副分片启动Engine后,以startSquenceNumber为起始点,对translog做快照,开始执行phase2
5. 最后向副分片发送recovery/finzalize请求,告知对方开始清理工作,同时把全局检查点发送过去,等待对方执行成功,主分片更新全局检查点
先检查主副分片是否都有syncid,如果syncid相同并且doc数相同,则跳过phase1;否则,对比文件差异,发送差异文件(副分片缺失的以及不同的)
将translog批量发送到副分片节点
提升索引恢复速度方法:
1. cluster.routing.allocation.node_concurrent_recoveries:单个节点执行副分片恢复的最大并发数,默认为2,提供此值可以提高恢复的并发数
2. indices.recovery.max_bytes_per_sec:节点间复制数据的限速
3. cluster.routing.allocation.node_initial_primaries_recoveries:单个节点主分片恢复的最大并发数,默认为4
4. 重启集群之前,停止写入端,执行sync flush,让恢复过程有机会跳过phase1
5. 适当多保留translog,配置index.translog.retention.size默认最大保留512M,index.translog.retention.age默认不超过12小时。调大这两个配置,有机会跳过phase1.
6. 合并Lucene分段,较少的Lucene分段可以减少phase1中的文件对比,降低传输的数据量
通过文档的版本号解决,更新、删除操作时候操作的版本号必须大于当前lucene中的版本号,否则放弃本次操作
1. _cat/recovery
列出活跃的和已完成的recovery信息
2. {index}/_recovery
展示特定索引的recovery阶段
3. _stats
给出分片级信息,包括分片的sync_id、local_checkpoint、global_checkpoint
1. 主分片恢复的主要阶段是TRANSLOG
2. 副分片恢复的主要阶段是INDEX、TRANSLOG
3. 只有phase1有限速配置,phase2不限速
4. Lucene的"提交"就是将文件系统的缓存数据刷到磁盘
gateway模块负责集群元信息的存储和集群重启时的恢复
ES中存储的数据有以下几种:
1. 元数据信息
2. Lucene生成的索引文件
3. translog事务日志
1. 集群层面元信息。主要是clusterUUID、settings、templates等
2. 索引层面元信息。主要是numberOfShards、mappings等
3. 分片层面元信息。主要是version、indexUUID、primary等持久化的元信息不包括内容路由表。集群完全重启时,依靠gateway的recovery过程重建内容路由表。
只有Master_eligible节点和Data节点可以持久化元信息。当收到主节点发布的集群状态时,节点判断元信息是否发生变化,如果发生变化,则将其持久化到磁盘中
集群元信息和索引元信息都来自集群状态
元信息的写入都分为三步:写临时文件、刷盘、move成目标文件
各个节点保存的元数据信息可能不同,此时需要选择正确的元数据作为权威元数据
当集群完全重启,达到recovery条件时,进入元数据恢复流程,一般情况下,recovery由三个配置控制:
1. gateway.expected_nodes:预期的节点数,加入集群的节点数(Master_eligible节点或数据节点)达到这个数量后立即开始gateway恢复。默认为0。
2. gateway.recover_after_time:如果没有达到预期的节点数,那么再次尝试恢复的等待时间。
3. gateway.recover_after_nodes:再次尝试,加入集群的节点数达到该值,开始进行恢复。
在Gateway将集群层、索引层元数据选举完毕后,开始执行allocation模块的reroute。
1. Master选举成功后,判断其持有的集群状态中是否存在STATE_NOT_RECOVERED_BLOCK,如果不存在,则说明元数据已经恢复,否则恢复元数据
2. Master从master_eligible节点主动获取元数据信息
3. 从获取的元数据信息中选择版本号最大的作为最新元数据,包括集群级、索引级
4. 两者确定后,调用allocation模块的reroute对未分配的分片进行分配,主分片分配过程中异步获取分片级元数据,默认超时为13s
1. 获取master_eligible节点元数据信息
2. 通过版本号选举索引级、集群级元信息
当集群级、索引级元信息选举完毕后,提交一个集群任务,该任务异步执行分片元数据恢复,以及分片分配
12.1 什么是allocation
分配决策由主节点完成,分配决策包含两方面:
1. 哪些分片应该分配给哪些节点
2. 哪个分片作为主分片,哪些分片作为副分片
1. 对于新建索引。allocators负责找出分片数最少的节点列表,然后deciders遍历节点列表,并判断是否把分片分配到该节点。需要注意的是,allocators只关心节点上的分片数,并不管每个分片的大小,这恰好是deciders工作的一部分,即阻止将分片分配到超出节点磁盘容量阈值的节点上
2. 对于已有索引。要区分是主分片还是副分片。对于主分片,allocators会找出拥有分片完整数据的节点。对于副分片,allocators会找出拥有该分片数据的节点,无论分片数据是否完整。
触发分片分配有以下几种情况:
1. index增删
2. node增删
3. 手工reroute
4. replica数量改变
5. 集群重启
allocators细分为3种:
1. primaryShardAllocator:找到拥有最新分片数据的节点
2. replicaShardAllocator:找到拥有分片数据的节点
3. BalanceShardAllocator:找到拥有分片数量最少的节点
reroute主要有两种allocator:
1. gatewayAllocator:分配现实已存在的分片
2. shardsAllocator:平衡分片在节点间的分布
gateway结束前提交一个异步任务,该异步任务中调用allocation模块的reroute方法
主节点收集每个节点特定分片的元信息,allocator选择分片副本的allocationID在集群元信息的inSyncAllocationID列表中的分片副本作为主分片节点,然后通过decider决定是否分配(如果多个都可以分配那么选择第一个)
其他分片副本就作为副分片
快照模块是ES备份、迁移数据的重要手段。支持增量备份,支持多种类型的仓库存储,仓库用来存储快照。
要使用快照,首先应该注册仓库,快照存储在仓库中
仓库用于存储快照1. 注册一个仓库
PUT /_snapshot/my_backup
{
"type": "fs",
"settings": {
"location": "/mnt/my_back_up"
}
}
type是指定存储类型,fs代表共享文件系统
共享文件系统支持如下配置:
location:已挂载的目的地址
compress:是否开启压缩。仅对元数据(mapping、settings)进行压缩,不对数据文件进行压缩,默认为true。
chunk_size:传输文件时数据被分解为块,此处配置块大小,单位为字节,默认为null(无限大)
max_snapshot_bytes_per_sec:快照操作时节点间限速值,默认为40MB
max_restore_bytes_per_sec:从快照恢复时节点间限速值,默认为40MB
readonly:设置仓库为只读,默认为false
2. 获取仓库配置信息
GET /_snapshot/my_backup
3. 获取多个仓库信息
GET /_snapshot/repo*,*backup*
4. 获取全部仓库信息
GET /_snapshot
5. 删除快照
DELETE /_snapshot/my_backup/snapshot1
6. 删除仓库
DELETE /_snapshot/my_backup
当仓库被删除时,ES只是删除快照的仓库位置引用信息,快照本身没有删除
7. 共享文件系统
当使用共享文件系统时,需要将同一个共享存储挂载到集群每个节点的同一路径,包括所有数据节点和主节点。然后将这个挂载路径配置到elasticsearch.yml的path.repo字段。
快照是对整个集群做快照,每个快照都有唯一的名称
PUT /_snapshot/my_backup/snapshot_1?wait_for_completion=true
wait_for_completion参数是可选项,默认为false,快照命令立即返回,任务在后台执行,如果想等待任务完成才返回那么可以设置为true
上述命令会为所有open状态的索引创建快照,如果想对部分索引创建快照,那么可以在参数indices中指定,如下:
{
“indices”:“index1,index2”,
“ignore_unavailable”: true,
“include_global_state”: true
}
include_global_state:快照集群状态,默认为false
快照操作在主分片上执行,快照执行期间不影响集群正常读写操作。在快照开始前,会执行一次flush操作,将操作系统缓存中的数据刷盘,因此通过快照可以获取从成功执行快照时间点开始,磁盘中存储的lucene数据,不包括后续新增内容。但每次快照都是增量的,下一次快照只会包含增量内容。
执行快照期间,被快照的分片不能移动到另一个节点
GET /_snapshot/my_backup/snapshot_1
IN_PROGRESS:快照正在运行
SUCCESS:快照创建成功,所有分片都存储成功
FAILED:快照创建失败,没有存储任何数据
PARTIAL:全局集群状态已存储,但至少有一个分片的数据没有存储成功。在返回的failure字段中包含了关于未正确处理分片的详细信息
INCOMPATIBLE:快照与当前集群版本不兼容
GET /_snapshot/my_backup/_current
_status API用于返回快照的详细信息
_snapshot/_status 返回正在运行的全部快照详细状态信息
_snapshot/my_backup/_status 返回指定仓库中正在运行的全部快照详细状态信息
_snapshot/my_backup/snapshot_1/_status 返回指定快照的详细信息,即使已经执行完成
快照和恢复在同一个时间点只能运行一个,如果想终止正在运行的快照,可以使用删除快照来终止它。
删除快照会先检查是否有正在运行的快照操作,如果有那么终止它,否则删除指定快照
要恢复一个快照,目标索引必须处于关闭状态
默认情况下,所有索引都被恢复,可以通过参数恢复指定索引
POST /_snapshot/my_backup/snapshot_1/_restore
{
“indices”: “index1, index2”
}
快照恢复只会对恢复的索引的影响,对其他的索引没有影响
partial参数可以控制是否部分恢复索引,设置为false那么参与恢复的一个索引出现恢复问题那么整个恢复操作失败;设置为true则允许部分恢复成功。
大部分索引配置在索引恢复时可以更改
POST /_snapshot/my_backup/my_snapshot1/_restore
{
“indices”: “index_1, index_2”,
“index_settings”: {
“index.number_of_replicas”: 0
}
}
主分片数配置不能进行更改
ES的快照创建是基于Lucene快照实现的
Lucene快照负责获取最新的、已刷盘的分段文件列表,并保证这些文件不被删除,这个文件列表就是ES要执行复制的文件
ES负责数据复制、仓库管理、增量备份、快照删除
1. 协调节点:收到客户端请求,将请求转发给主节点
2. 主节点:将创建快照的请求信息放到集群状态中广播到数据节点
3. 数据节点:负责将lucene文件复制到仓库
一个index包含一系列documents
一个document包含一系列fields
一个field包含一系列terms
一个term包含一系列bytes
lucene索引由多个分段组成,每个分段是一个单独的索引,可以单独进行搜索
产生新分段的两种情况:
lucene索引执行搜索时,要遍历所有分段
每个分段所有文件都有相同文件名和不同的扩展名
接收客户端请求,将请求解析成CreateSnapshotRequest,然后判断本节点是否是主节点,如果是那么将请求交给snapshot线程处理,否则将请求发送给Master节点
主节点收到创建快照请求后,解析请求提交一个异步任务进行处理,异步任务中先检查当前是否有正在进行的快照如果有那么抛异常,否则将快照信息封装在集群状态中广播到数据节点,集群状态会下发两次,第一次的
状态为INIT数据节点收到后进行一些初始化操作,第二次的状态为STARTED下发第二次前主节点将全局元信息和索引元信息写入仓库,数据节点收到第二次集群状态后开始执行真正的快照操作
数据节点对第一次下发的集群状态没有什么有意义的处理操作,对第二次下发的集群状态是真正的核心处理
第二次下发的集群状态包含要进行快照的主分片列表,数据节点收到后过滤一下本地有哪些分片,构建一个新的列表,后续要进行快照的分片就在这个列表中,然后遍历这个分片列表,在snapshot线程池中并行处理,处理完毕后向主节点发送请求更新相应分片的快照状态
Lucene快照:获取一个提交点,通过该提交点可以获取Lucene分段文件列表,这个列表中的文件都不会被删除,直到释放提交点
ES快照:
根据lucene提交点获取全部lucene分段文件,计算出两个列表:新增文件列表;当前快照使用的全部文件列表
遍历新增文件列表,将文件复制到仓库,在复制的同时计算文件校验和,复制完毕后比对计算的校验和与文件元数据中的校验和是否一致
生成快照文件,该文件中包含快照的描述以及所有相关的lucene分段文件
协调节点:接受客户端请求,转发到主节点
主节点:将删除快照信息放到集群状态中广播下去,数据节点负责取消运行中的快照创建任务,主节点负责删除已创建完毕的快照,当数据文件不被任何快照引用时,将数据文件删除
数据节点:取消正在运行的快照创建任务
接收客户端请求,解析成DeleteSnapshot请求,转发给主节点
主节点收到删除快照请求后,提交异步任务将请求信息放到集群状态中广播到数据节点,数据节点收到后检查是否有正在运行的快照任务,如果有则取消,否则不做任何操作,集群状态发布成功后,主节点删除快照
获取不删除的快照列表,将该列表传入finzalize方法,finalize方法会遍历仓库中所有的文件列表将不被快照列表引用的文件删除
数据节点根据快照信息的State字段判断是启用快照还是停止快照,State为Aborted则停止
停止快照是设置一个abort中止标识,运行中的快照会在多处检查这个标识
计算需要复制的lucene分段文件列表时
开始执行复制之前
开始复制数据后的读取数据过程中
14.1 集群状态
可以通过_cluster/state获取集群状态
两个重要的类:MasterService、ClusterApplierService
MasterService:负责集群任务管理、运行。对外提供接口提交任务,内部维护一个线程池执行任务。
只有主节点才会这个类的方法,执行集群任务
管理各个模块对集群状态的处理和应用
子类实现ClusterStateApplier接口,实现applyClusterState方法
在子类中调用addStateApplier将类的实例添加到Applier列表中
子类实现ClusterStateListner接口,实现clusterChanged方法,这样就可以感知到最新的集群状态
在子类中调用addListener将实例添加到Listerner列表中
运行集群任务、应用集群状态都在各自的线程池执行,线程池大小都是1
线程池为单个线程的线程池,所以集群任务是串行执行的
线程池的任务队列是带优先级的阻塞队列
应用集群状态的线程池也是单个线程的线程池,所以任务是串行执行的
任务队列也是带优先级的阻塞队列
下列情况会提交集群任务:
集群拓扑发生变化
模板、索引map、别名发生变化
索引的创建、删除、open、close
pipeline的增删
脚本的删除
gateway模块发布选举出的集群状态
分片分配
快照、reroute api等
submitStateUpdateTask(String source, T updateTask),该方法第一个参数是任务源,第二个参数是提交的具体任务
ClusterStateTaskListener:提交任务时的一些回调,执行成功的回调和执行失败的回调
ClusterStateTaskExecutor:定义要执行的任务,每个任务执行时会传入当前的集群状态,任务执行完毕后会返回新的集群状态
ClusterStateTaskConfig:任务的配置信息,包括超时和优先级
任务提交的核心就是将任务交给线程池执行,但是在此之前根据任务的Executor对象做了去重
提交多个任务时,只将第一个任务放到线程池任务队列中,所有的任务以ClusterStateTaskExecutor为key存储在一个HashMap中,当线程池队列中的任务执行完后将结果赋给Hashmap中key相同的所有任务
去重的本质不是将任务从任务队列中删除,而是在任务执行完后给所有executor相同的任务赋予相同的结果
1. 构建任务列表
根据任务的batchingKey从hashMap中获取要执行的任务列表,用这个列表中尚未执行的任务构建新的真正要执行的任务列表,如果列表不如空那么执行第一个任务
2. 执行任务
执行任务前先判断本节点是否是主节点,然后将当前的集群状态传给任务执行函数,任务执行失败回调OnFailure通知Listener,任务执行成功产生新的集群状态发布集群状态
3. 发布集群状态
通过clusterStatePubliser发布集群状态,并在成功或失败后通知相关回调函数
发布集群状态是一个分布式事务操作,ES使用二阶段提交来实现分布式事务。基本过程是:把信息发下去,但不应用,如果得到多数节点的确认,则再发送一个应用请求要求各节点应用
这里的多数取决于配置:discovery.zen.minimum_master_nodes
1. 发布阶段:发布集群状态,等待响应,如果节点在discovery.zen.commit_timeout时间内没有收到提交请求那么拒绝收到的集群状态
2. 应用阶段:收到的响应数量大于minimun_master_nodes数量,发送commit请求,主节点等待响应,直到收到全部响应或者达到discovery.zen.publish_timeout超时,整个发布流程结束
每个集群状态都有自己唯一的版本号,ES在相邻版本号之间只发送增量内容
在发布之前的准备工作中,先准备发送的目的节点列表,这个列表是在已知集群列表中移除了自己
遍历目的节点列表,如果上次节点发布成功了那么准备增量信息,否则准备全量信息
遍历目的节点列表,异步发送全量或增量集群状态信息,在第一个请求的响应处理中检查是否达到发送第二个请求的条件
如果达到commit_timeout还没有达到第二个请求的条件则抛出异常,否则向目的节点列表发送第二个请求
如果达到publish_timeout还没有收到所有节点的响应那么抛出异常
每收到一个节点的响应,计时器的值减1,当计数器的值为0或者达到commit_timeout时发布过程结束
计数器的初始值为minimum_master_nodes-1(不包含本节点)
每收到一个节点的响应,计数器的值减1,当计数器的值为0提交过程结束
计时器的初始值为目的节点列表的大小
检查应用的集群状态是否与上一个相同,如果相同则不应用,否则调用各模块的Listener和Applier,并更新本节点存储的集群状态
传输模块用于集群内节点之间的通信,传输机制是完全异步的,意味着没有阻塞线程等待响应,使用异步通信的好处是解决了C10K问题
15.1.1 传输模块配置
TCP transport是传输模块基于TCP的实现,相关配置如下:
1. transport.tcp.port:绑定的端口范围
2. transport.publish_port:与集群中其他节点通信的端口,当transport.tcp.port不可从外部直接访问时使用该参数
3. transport.bind_host:绑定的主机地址,默认是transport.host
4. transport.publish_host:节点在集群中发布的主机地址,其他节点连接这个地址,默认是transport.host
5. transport.host:传输的主机地址
6. transport.tcp.connect_timeout:套接字连接超时设置,默认为30秒
7. transport.tcp.compress:设置为true,在所有节点之间启用压缩(LZF),默认为false
8. transport.ping_schedule:定期发送ping消息,确保连接是活跃的。客户端默认5秒,设置为-1为禁用
1. network.host
节点将绑定到此主机名或IP地址
2. discovery.zen.ping.unicast.hosts
为了加入集群,节点需要知道集群中其他节点的主机名或IP地址
3. http.port
接受HTTP请求的端口,可以是单个值或范围,如果是范围那么是范围中第一个可用的端口,默认为9200·9300
4. transport.tcp.port
节点间通信使用的端口,默认为9300~9400
TCP传输模块有三大用处:节点间通信、JAVA API客户端、以及节点发现。HTTP模块负责处理用户的REST请求。
网络层是对内部各种传输模块的抽象,使得上层发送/接收数据时不必关心底层实现。在内部实现中,TCP传输模块和HTTP模块统一封装到NetworkModule类中。
该类的几个重要数据成员:
1. Transport
负责RPC请求
2. HttpServerTransport
负责HTTP请求
3. TransportInterceptor
传输层拦截器,在发送和接收数据时进行拦截
主要对外提供的方法:
1. getTransportSupplier
返回注册的TCP传输模块
2. getHttpTransportSuppier
返回注册的HTTP传输模块
3. getTransportInterceptor
返回注册的传输拦截器
NetworkModule内部成员变量是通过插件的方式初始化的,在该类的构造函数中会传入NetworkPlugin列表,根据传入的插件列表和定义好的REST处理器初始化NetworkModule
用于RPC等内部通信,在初始化时构建了Client和Server
用于响应REST请求,在Netty4HttpServerTransport的doStart方法中创建一个HTTP Server监听端口,当收到用户请求时,调用dispatchRequest对不同的请求执行相应的处理,哪个请求被哪个类处理注册在ActionModule类中
基于网络层提供的Transport收/发数据
节点间通信使用TransportService类实现,在网络模块提供的Transport基础上,该类提供连接到节点、发送数据、注册事件响应函数等方法
1. 连接到节点
默认配置下,每个节点都会和其他节点保持13个长连接,每个连接各有用途
本节点和其他节点完成连接后,内部维护一个NodeChannels对象,该类中包含多个TCP连接(默认为13个),并记录了每个连接的用途,当发送数据时,根据请求类型找到对应的连接来发送数据
建立连接过程中,如果13个连接中有一个连接建立失败,那么整体认为失败,关闭已建立的连接
2. 发送请求
检查本节点是否是目的节点,如果是那么直接通过action获取对应的Handler,调用对应的处理函数
当需要发送到网络时,先根据请求类型获取对应的连接,某种类型如果有多个连接,那么轮询选择连接,然后进行发送
3. 定义对Response的处理
TransportResponseHandler负责定义对Response的处理,在发送请求的sendRequest函数的最后一个参数中定义
在ES中,REST请求和RPC请求都被称为Action
当Netty收到REST请求后,根据请求的URI获取对应的Action处理类,对请求进行处理
发送方调用TransportService的sendRequest发送请求,发送时传入定义好的ResponseHander,TransportService的sendRequest方法调用Netty4Transport的sendRequest方法发送请求,当远程节点处理完毕,Netty4Transport的handleResponse方法最终回调发送请求时定义的ResponseHandler
接收方收到请求,根据Action获取对应的处理类,最终调用TransportRequestHandler处理
一个RPC请求与处理模块的对应关系在两方面维护:
* 在ActionModule类中注册Action与处理类的映射
* 在TransportService中注册Action名称与对应处理器的映射
注册函数的第一个参数是Action类,该类包含Action的名称和返回响应;第二个参数是TransportAction类,该类定义了对Action的具体处理
在创建TransportAction类时,注册action的名称和对应处理器的映射关系
根据action的名称找到对应的处理器,处理器中调用TransportAction的doExecute方法执行真正的处理逻辑
1. REST请求触发
某些REST请求会触发内部的RPC请求,通过ActionModule获取对应的处理类
2. TcpTransport的RPC请求
从TCP传输层(9300端口)收到一个RPC请求,通过TransportService获取对应的处理器
默认情况下,每个节点要和其他节点建立13个长连接,若集群规模较大,例如达到1000个节点,这种情况下重启集群,会在短时间内建立大量的连接,则新建连接的请求可能会被系统认为是SYN攻击
每个节点都会创建一系列线程池来执行任务,每个线程池都有与其相关的任务队列
线程池要处理的任务类型可以分为两类:CPU密集型、IO密集型。对于不同类型的任务,要设置不同的线程数。
线程池的大小可以参考如下配置,其实N为CPU的个数:
对于CPU密集型的任务,线程池大小可以设置为N+1
对于IO密集型的任务,线程池大小可以设置为2N+1
对于CPU密集型任务,线程池的线程数量不应该超过N+1,过多的线程会导致更高的线程上下文切换开销,+1的目的是为了防止线程出现偶尔的故障或者出现偶尔的IO操作,这个额外的线程可以保证CPU时钟不被浪费
IO密集型任务,线程数可以多一些,因为线程大部分时间阻塞在IO操作,加大线程数可以增加并发处理能力,此时上下文切换带来的开销并不敏感。但不一定是2N+1,IO阻塞时间越长线程数越大,IO阻塞时间越短线程数越小,可以套用公式 (线程IO时间+线程CPU时间)/线程CPU时间*CPU个数
线程数固定,当线程空闲时不会销毁线程,当所有线程都繁忙时将任务添加到任务队列中
thread_pool.search.size:控制线程数量
thread_pool.search.queue_size:控制任务队列大小,-1表示无限制。当任务队列满时,拒绝请求
线程数是动态的,介于core和max之间。最小线程数是core,当core数量的线程全都忙碌时,线程数逐步增加至max。当线程空闲时会销毁线程,线程数从max降至core。
keep_alive参数用来控制线程的最大空闲时间
thread_pool.warmer.core:1
thread_pool.warmer.max:2
thread_pool.warmer.keep_alive:2m
特殊类型的线程池,在调用者线程中执行任务
线程数固定,但是队列大小不固定
默认情况下,ES自动探测处理器数量,各个线程池根据这个数量初始化线程数,也可以通过processors参数指定处理器数量
ES提供了丰富的API查看节点中的线程池状态
查看每个节点中的所有线程池的状态,包括:
1. active:正在执行任务的线程数量
2. queue:任务队列中等待处理的任务数量
3. rejected:由于任务队列已满,被拒接的请求数
节点信息API可以返回每个节点线程池的类型和配置信息,例如线程数量、队列大小等
API如下:
1. 查看所有节点:/_nodes
2. 查看指定节点:/_nodes/node1, node2
节点统计信息API
/nodes/_stats
/nodes/node1,node1/_stats
线程池信息在thread_pool字段中
查看一个或者全部节点的热点线程
当发现某个节点的ES进程占用CPU很高时,可以通过hot threads API查看是哪些热点线程导致的
/_nodes/hot_threads
/_nodes/node1,node2/hot_threads
支持以下参数:
1. threads:返回热点线程数,默认为3
2. interval:ES对线程做两次检查,计算线程花费时间的百分比,该参数就是指定检查间隔,默认为500ms
3. type:检查的线程状态类型,默认是CPU,还可以是阻塞(block)、等待时间
4. ignore_idle_threads:如果设置为true,那么忽略空闲线程。默认为true。
1. 第一行包括节点的ID和地址
2. 接下来列出占用CPU百分比最多的线程
3. 最后是该线程的堆栈信息
JAVA内部的线程池称为Executor框架,几个基本的类如下:
1. Runable:定义要执行的任务
2. Executor:提供一个execute方法,执行一个任务
3. ExecutorService:继承Executor,提供shutdown、shutdownNow关闭线程池的方法
4. ThreadPoolExecutor:继承ExecutorService,维护线程创建、线程生命周期、任务队列等
5. EsThreadPoolExecutor是ES对ThreadPoolExecutor的扩展实现
1. corePoolSize:核心池大小
2. maxPoolSize:最大池大小
3. keepAliveTime:线程最大空闲时间
4. unit:时间单位
5. workQueue:任务队列
6. threadFactory:线程工厂
7. handler:当任务队列满时,请求的拒绝处理函数
在ThreadPool类中创建了各个模块要使用的全部线程池
要使用线程池的模块会引用ThreadPool对象,通过其对外提供的executor方法,根据线程池的名称获取对应的线程池引用,进而执行某个任务
重要方法如下:
1. executor:根据线程池名称获取对应的线程池实例
2. schedule:在指定线程池中延迟一定时间后执行一个任务,只执行一次,不是周期性
3. shutdown:关闭线程池,不再接收新任务,待现有任务执行完关闭线程池
4. shutdownNow:关闭线程池,不再接收新任务,停止当前任务,并返回未执行完的任务列表
5. stats:获取线程池状态
1. executors:保存线程池名称和线程池实例的映射
2. scheduler:JDK中ScheduledThreadPoolExecutor实例,用于延迟执行任务
ThreadPool类对象在节点启动时初始化
在ThreadPool类的构造函数中初始化全部线程池
所有线程池初始化完成后保存到一个map中(executors),key是线程池名称,value是线程池实例
除了ThreadPool中封装的线程池,还有一种支持优先级的线程池:PriorityEsThreadPoolExetor,该线程池有固定大小,线程数为1,任务队列是支持优先级的队列,初始大小为11,最大为Interger.MAX_Value-8相当于无限
Shrink API是ES5.0之后的功能,可以缩小主分片数,但并不是对源索引进行缩小,而是使用与源索引相同的配置创建一个新索引,仅降低主分片数。新索引的主分片数必须是源索引主分片数的因数,比如源索引主分片数是8,那么新索引主分片数只能是4,2,1,如果源索引主分片数是素数那么只能缩小为1
将源索引标记为只读,以及将源索引所有分片迁移至指定节点
PUT /source_index/_settings
{
“settings”: {
“index.routing.allocation.require._name”:“node-idea”
“index.blocks.write”: true
}
}
执行shrink操作
/source_index/_shrink/target_index
{
“settings”: {
“index.number_of_shards”: 1
}
}
以上操作会生成含有一个主分片的目的索引target_index
1. 以相同的配置创建目标索引,但是减小主分片数
2. 将源索引所有分片的lucene分段硬链接到目标索引,如果系统不支持硬链接,那么复制所有分段文件到目标索引,将会花费大量时间
3. 对目标索引执行恢复操作
硬链接保证Shrink后源索引和目的索引是完全独立的,读写和删除都互不影响。如果使用软链接,删除源索引则目的索引的数据也会被删除
提升写入速度可以从以下几方面入手:
1. 加大translog flush间隔,目的是降低iops、writeblock
2. 加大index refresh间隔,降低IO以及降低segment merge频率
3. 调整bulk请求
4. 将shard尽量均匀分布到物理主机的各个磁盘
5. 将分片尽量均匀分布到各个节点
6. 优化Lucene层建立索引过程,目的是降低CPU使用率以及IO,例如:禁用_all字段
默认情况下,translog持久化策略是每个请求都"flush"
对应配置:index.translog.durability: request
这是影响ES写入的最大因素,但是只有这样写操作才是可靠的,如果可以允许一定概率丢失数据,可以调整持久化策略为周期性和一定大小的时候“flush”,例如:index.translog.durability: async
默认情况下索引刷新间隔是1S,即写入的数据1s后可以被搜索到,每次索引刷新都会产生新的lucene分段,过多的lucene分段会导致频繁的分段merge操作,如果不需要这么高的实时性,可以考虑增大刷新间隔
例如:index.refresh_interval:120s
index.merge.scheduler.max_thread_count:段合并最大线程数
最大线程数默认是Math.max(1, Math.min(4, Runtime.getRuntime().availableProcessors()/2) )
如果只有一块硬盘并且非SSD,则应该把线程数设置成1,因为在旋转存储介质上并发写,由于寻址原因,只会降低写入速度
写入doc为doc建立索引时,会将doc写入index buffer,当缓冲满时,刷入磁盘并生成一个新的segment
每个shard都有自己的索引缓冲
indices.memory.index_buffer_size:默认为整个堆空间的10%
indices.memory.min_index_buffer_size:默认为48M
indices.memory.max_index_buffer_size:默认为无限制
批量写比写单个文档效率高得多,但是要注意bulk请求的整体字节数不要超过几十兆,否则可能会给集群带来内存压力
如果在path.data配置多个路径使用多块磁盘,那么ES在分配分片时,落到磁盘上的分片可能不均匀
ES提供两种策略:
1. 简单轮询:这个在系统初始阶段,简单轮询是最均匀的
2. 可用空间加权轮询:以可用空间为权重,在磁盘间加权轮询
客户端将请求轮询发送到集群的节点上
18.8.1 自动生成DOC ID
写入DOC时如果指定了ID,则ES先尝试读取原来DOC的版本号,以判断是否需要更新,这就涉及一次磁盘读取操作,通过自动生成doc ID可以避免这个环节
1. 减少字段数量,不需要建立索引的字段不写入ES
2. 将不需要建立索引的字段index属性设置为not_analyzed或者no
3. 减少字段内容长度
4. 使用不同的分析器,不同的分析器在索引过程中的运算复杂度有很大差别
_source字段用来存储文档原始内容,对于不需要存储的字段,可以使用exclude过滤
从ES6.0开始禁用_all字段,_all字段包含所有字段分词后的term,作用是在搜索时不用指定特定字段,从所有字段中搜索
1. 要复制所有字段分词后的词,占用非常大的空间
2. _all字段有自己的分词器,查询时,结果可能不符合预期,因为没有跟要搜索的字段使用同一个分词器
3. 由于数据重复额外建立索引的开销
4. 有些用户不知道这个字段,造成查询混乱
Norms在搜索时计算doc评分,如果不需要评分,可以禁用Norms
“title”: {
“type”: “string”,
“Norms”: {“enabled”: false}
}
控制建立倒排索引时,哪些内容被添加到倒排索引中
例如doc数量、词频、positions、offsets
19.1 为文件系统cache预留足够的内存
应用程序的读写都会被操作系统缓存,cache保存在物理内存中,命中cache可以降低磁盘的访问量,应该至少为系统缓存预留一半的物理内存
使用SSD会比使用旋转存储介质好得多
嵌套(nested)会使查询慢几倍,父子关系会使查询慢几百倍,如果使用非规范化(denomalnized)文档,可以显著提高搜索速度
有些字段的内容是数值,但是将它们映射成keyword可能会比数值类型更好
一般来说,应该避免使用脚本。如果一定要用,那么优先考虑painless和expressions
使用日期范围搜索时,使用now的查询通常命中不了缓存,因为范围一直在变化
但是可以对时间进行四舍五入,例如:四舍五入到分钟,增加时间间隔,这样就容易命中缓存
但是也不能四舍五入太厉害,否则间隔太大影响用户体验
为只读索引执行force merge,会将lucene索引的所有lucene分段合并成一个分段,这样当搜索时只需要搜索一个分段即可,不需要遍历多个分段搜索并且合并搜索结果,可以提高搜索效率,对索引恢复也有好处
全局序号用于keyword字段运行terms聚合,它使用一个数值代表字段的字符串值,然后为每一个数值分配一个bucket,将相同数值的doc扔到同一个bucket中。这需要一个对全局序号和bucket的构建过程,默认是延迟构建因为ES不知道哪些字段会进行聚合,但也可以通过配置mappings在索引refresh时预先加载全局序号
PUT index {
“mappings”: {
“type”: {
“properties”: {
“foo”: {
“type”: “keyword”,
“eager_global_ordinals”: true
}
}
}
}
}
terms有两种聚合方式:
直接使用字段值聚合每个桶的数据(map)
给每个不同的字段值分配一个全局序号,并为每一个全局序号分配一个bucket(global_ordinals)
默认使用全局序号的方式,这种方式速度快;当查询只会匹配少量文档时,可以考虑使用map
默认在脚本中进行聚合时使用map方式,因为字段值没有全局序号
可以使用index.store.preload设置,通过指定文件扩展名,显示告诉操作系统应该将这些文件加载到内存
例如,配置到elasticsearch.yml
index.store.pre_load: [“nvd”, “dvd”]
bool查询的多个逻辑组合查询,可以进行等价转换
该字段是搜索请求中的一个参数,默认情况下,聚合操作在协调节点需要等待所有分片都返回结果才进行聚合,使用该参数可以不等待所有分片返回结果,而是在指定数量分片返回结果后就先处理一部分。这样可以避免协调节点在聚合全部分片数据时占用大量内存,极端情况下产生OOM,该参数默认值512
牺牲少量精确度,提高聚合效率,降低内存使用
ES有两种不同的聚合方式,深度优先和广度优先,默认是深度优先
ES的ARS实现:对每个搜索请求,将分片的所有副本进行排序,选择“最佳”副本发送请求
排序规则:按照副本所在节点的压力和健康程度
ARS从ES6.1开始支持,默认关闭;ES7.0开始默认开启
20.1 预备知识
20.1.1 元数据字段
比如_index、_type、_id
_source:原始json文档数据
_all:索引所有其他字段值的一种通用字段,允许在搜索时不指定字段名,_all字段有自己的分词器,会对字段值进行分词,但是该字段的store属性默认是false,因此查询后不能取回
1. index:控制字段是否被索引,只有被索引的字段才能进行搜索,设置为false不能进行搜索但是可以进行聚合,除非禁用doc_values。默认为true
2. doc_values:排序、聚合以及脚本中访问字段的值,不仅需要根据term找到对应的文档列表,还要获取文档中字段的值,这些值就存储在doc_values中。默认开启
3. store:默认情况下,字段值被索引可以进行搜索,但不会被存储。意味着可以根据字段值查询,但不能取回原值
1. 文档字段多,只希望返回少数字段,不希望从_source字段中提取字段值
2. 用于不在_source中出现的字段(例如copy_to)
20.2.1 禁用对你来说不需要的特性
text类型字段会在索引时存储归一因子,用来算分,如果不关心算分,那么可以将字段的norms设置为false
text类型字段默认情况下在索引中存储词频和位置,词频用于算分,位置用于邻近查询和短语查询,可以通过index_options参数设置存储的内容
如果不需要对字段进行聚合、排序以及从脚本中访问字段的值,那么可以禁用doc values,节省磁盘空间
默认的动态字符串映射会将字符串类型映射成text和keyword,这显然是一种浪费
要么禁用动态字符串映射,显示指定字符串类型;要么在动态模板中,将字符串映射成text或keyword
_source存储文档原始内容,如果不需要可以禁用。
但是禁用_source字段后,无法使用以下API:
update、update_by_query、reindex
高亮搜索
重建索引
调试聚合查询功能,需要对比原始数据
_source和store设置为true的字段在存储时都会进行压缩,默认使用LZ4压缩算法
可以通过使用best_compression使用压缩比更高的压缩算法,但是这会占用更多的CPU
PUT index
{
“settings”: {
“index”: {
“codec”: “best_compression”
}
}
}
使用_forcemerge API对分段进行合并,通常将多个分段合并为一个分段,max_num_segments=1
减少索引主分片数
整形可以选择byte、short、integer、long,浮点型可以选择scaled_float、float、double、half_float,不同数据类型长度不同,选择最小的够用的数据类型,节省磁盘空间
21.1 集群层
21.1.1 规划集群规模
根据具体业务情况评分初始集群大小,包括:
数据总量,每天的增量
查询类型和搜索并发、QPS
SLA级别
另外,需要控制最大集群规模和数据总量:
1. 节点总数不能太多,最好控制在100个左右
2. 单个分片不要超过50G,最大集群分片总数控制在几十万级别。太多分片会增加主节点管理负担,而且集群重启恢复时间长。
ES不建议将JVM配置超过32G内存,因为超过32G时,JAVA内存指针压缩失效,会浪费一部分内存,降低CPU性能,GC压力也比较大,因此推荐设置为31G
-Xmx31G -Xms31G
确保堆内存最小值和最大值相同,防止程序在运行时动态改变堆内存大小,这是很消耗系统资源的过程
当由于坏盘、维护等故障需要下线一个节点时,需要先将该节点的数据迁移,这可以通过分配过滤器实现
例如下线node-1:
1. 将node-1的数据迁移出去
PUT _cluster/settings
{
“transient”: {
“cluster.routing.allocation.exclude._name” : “node-1”
}
}
2. node-1要重新上线,取消排除配置,以便后续数据可以分配到node-1
PUT _cluster/settings
{
“transient”: {
“cluster.routing.allocation.exclude._name” : “”
}
}
将主节点和数据节点分开部署最大的好处就是Master切换过程可以迅速完成,有机会跳过gateway和分片重新分配过程。
将Master_eligible节点和Data节点分开部署,新主当选后由于有最新的集群状态所以可以跳过gateway,由于新主上没有分片所以可以跳过分片重分配
21.2.1 控制线程池的队列大小
不要为bulk和search分配过大的队列,队列中缓存的数据越多,GC压力越大,默认的队列大小基本够用
搜索很依赖系统cache的命中,标准建议是把50%的可用内存作为ES的堆内存,为Lucene保留剩余的50%,用作系统cache
21.3.1 关闭swap
因为当服务程序在交换分区上缓慢运行时,往往会出现更多的不可预知的错误,所以当程序申请内存遇到内存不足时,宁可让它直接失败
一般在安装操作系统时就关闭交换分区,或者使用swapoff命令来关闭
因为进程申请的内存不一定全都使用,所以系统在给进程分配内存时,采用"过度分配"策略,比如:物理内存1G,两个进程分别申请1G内存,当某个进程实际将内存消耗完时,系统就需要杀掉一些进程保障系统的运行,这就触发了OOM Killer。
默认情况下,杀掉占用内存最多的进程
如果ES和其他的服务混合部署在一台机器上就可能被系统杀掉,可以设置进程的oom_score_adj参数为-17(越小越不容易被杀)
sudo echo -17 > /proc/1849/oom_score_adj
调节内核参数两种方式:
1. 临时设置,系统重启后失效,通过sysctl -w
2. 永久设置,将参数写入配置文件/etc/sysctl.conf,然后sysctl -p使其生效
1. net.ipv4.tcp_syn_retries
syn包发送重试次数,默认是6,参考值是2。syn包发送是tcp建立连接三次握手的第一步
因为ES集群的节点一般都位于一个子网,网络连接良好,可以降低重试次数
2. net.ipv4.tcp_synack_retries
syn+ack包发送重试次数,默认是5,参考值是2。syn+ack包是tcp建立连接三次握手的第二步
3. net.ipv4.tcp_tw_reuse
默认值为0,建议值为1。是否将处于time_wait状态的socket用于新的连接。该参数只有在开启tcp_timestamps的情况下才会生效
4. net.core.somaxconn
默认为128,建议值为2048.定义每一个端口上最大连接队列长度,当集群节点数较多时,集群完全重启时会建立大量连接,默认的连接队列长度可能不够
5. net.ipv4.tcp_max_syn_backlog
默认为128,建议值为8192
内核会为服务端连接建立两个队列
已完成三次握手连接的队列,最大长度由somaxconn控制
完成三次握手的前两次握手,等待客户端返回ACK连接的队列,最大长度由tcp_max_syn_backlog控制
6. net.ipv4.tcp_max_tw_buckets
默认为4096,建议值为180000
系统同时保持TIME_WAIY套接字的最大数量,超过这个数,则TIME_WAIT套接字被清楚
TIME_WAIT产生原因是服务端主动关闭连接
7. net.ipv4.tcp_max_orphans
默认为4096,参考值为262144.最大孤儿套接字,孤儿套接字是指未依附到任何用户文件句柄的套接字。
流量控制(接收窗口),为了确保接收者可以接收数据
拥塞控制,为了管理网络带宽
流量控制就是在接收方告诉发送方发送窗口大小,避免发送方发送过多数据,接收方无法接收
写文件是将数据先写到系统缓存,然后在定期异步地将缓存中的数据刷到磁盘,存储在系统缓存中但未刷盘的数据叫做脏数据,系统缓存可以提高写IO的效率,但是存在丢失数据的风险
1. 可用物理内存低于特定阈值时,给系统腾出空闲内存
2. 脏页驻留时间超过特定阈值时,避免脏页永久驻留
3. 用户手动调用sync、fsync
系统执行刷盘有两种写入策略:
异步刷盘:不阻塞用户IO
同步刷盘:阻塞用户IO,直到脏页低于阈值
1. vm.dirty_backgroud_ratio:默认值为10.当内存中的脏数据超过这个百分比后,系统使用异步方式刷盘。
2. vm.dirty_ratio:默认值为30.当内存中的脏数据超过这个百分比后,系统使用同步的方式刷盘,写请求被阻塞,直到脏数据低于dirty_ratio。如果还高于dirty_backgroud_ratio,那么采用异步刷盘。
3. 除了通过百分比控制,还可以通过字节大小控制。例如dirty_background_bytes、dirty_bytes
4. vm.dirty_expire_centisecs:默认是3000(30秒),定义脏数据过期时间,超过这个时间后,脏数据被异步刷到磁盘
5. vm.dirty_writeback_centisecs:默认是500(5秒),系统周期性地检查是否需要刷盘,该参数定义检查周期
透明大页默认是开启的,透明大页可以略微提升程序性能,但是也可能带来严重的内存泄漏,为了避免这些问题,应该禁用它
查看是否开启:
cat /sys/kernel/mm/transparent_hugepage/enabled
always代表开启,可以通过下面的命令禁止
echo never | sudo tee /sys/kernel/mm/transparent_hugepage/enabled
21.4.1 使用全局索引模板
将索引的公共配置写到全局索引模板中,全局索引模板的匹配方式是*即匹配所以新创建的模板,全局索引模板的order值为0即可以被所有自定义索引模板覆盖
如果一个索引每天都有新增内容,那么不要让这个索引持续增大,建议按照日期等规则周期性生成新索引,将索引配置写入索引模板,让模板匹配这一系列索引
搜索时,可以使用索引名称前缀进行搜索例如data_*。当需要删除旧数据时,直接按日期进行删除索引,删除索引会立即释放磁盘空间。如果只是删除部分doc,不会立即释放空间,会依赖lucene段合并才能释放空间
对冷索引执行Force Merge有许多好处:
1. 单一分段比众多分段占用的磁盘空间更小一些
2. 可以大幅减少进程需要打开的文件句柄
3. 可以加快搜索速度
4. 单个分段加载到内存也比多个分段更节省内存占用
5. 加快索引恢复速度
节点离线后,ES通常会重新确定主分片,并立即分配缺失的副分片。
节点离线,重新分配副分片的代价是很大的,涉及到大量的数据复制,而节点离线后一般可以很快恢复,所以可以延迟分片分配,这样在延迟结束前节点恢复就不需要重新分配了
聚合时,ES通过doc_values获取文档中字段的值,但是text类型不支持doc_values。当在text类型字段上聚合时,就依赖fielddata数据结构,fielddata默认关闭因为它会消耗很多堆空间,并且在text类型字段上聚合也没什么意义
21.5.1 注意429状态码
bulk请求被放入
bulk请求被放入ES的队列,当队列满时,新请求被拒绝,并给客户端返回429错误码,客户端需要处理bulk请求中部分成功、部分失败的情况。这种情况产生在协调节点转发基于分片的请求到数据节点时,数据节点bulk队列满而拒绝写操作,其他数据节点正常处理。客户端针对写失败的数据应该进行重试
客户端断开连接后,服务器仍然会继续处理请求,如果超时时间较短,客户端会在短时间建立大量的请求,导致服务器压力过大
21.6.1 避免搜索操作返回巨大的结果集
目的是降低协调节点合并各数据节点返回数据的压力
因为大型文档会给内存、磁盘、网络造成巨大的压力
处理办法:例如存储书本,书本的内容会很大,那么就不要存储书本内容,只需要存储章节内容,然后在章节中添加一个书籍字段记录该章节属于哪本书即可,这样不仅避免了大文档问题,还提高了搜索速度
从ES7.0开始完全废弃了_type概念,_type只有一个值即_doc
JAVA客户端默认会将请求轮询发送到协调节点
1. 编写脚本
脚本中通过doc[‘name’].value获取字段值
return position_score*0.6+similar_score
2. 将脚本写入ES
POST _scripts/user_info_score
{
“script”: {
“lang”: “painless”
“source”: “脚本内容”
}}
3. 在function score中脚本计算新的评分
4. function score是控制评分的最终武器,可以使用内置函数或脚本计算新的分数,其中script_score指定脚本,params用来往脚本中传参数
boost_mode用来指定新分数和老分数的结合方式,有:multiply、replace、sum、avg、max、min
22.1
显示分片的详细信息,每个分片都被分配一个唯一的ID,ID的格式为[nodeID][indexName][shardID],每个分片包含三部分,分别是:query、rewrite_time、collector
Query段组成部分:
query_type:查询类型,此处是BooleanQuery,因为多个关键字匹配查询,因此被分成两个Term查询
lucene:启动查询的lucene方法
time:Lucene执行此查询所用的时间,单位是毫秒
children:子查询信息,Bool查询中的每个查询都可以作为一个单独的查询
match查询的时候,会将查询文本分解成多个词进行查询,将一个查询重写成多个查询组合的时间称为Rewrite Time
在Lucene中,收集器负责收集原始结果,并对他们进行组合、过滤、排序等处理。例如查询中size为0,那么就会使用"totalHitCountCollector"收集器,只会收集文档个数不会收集文档内容
该API会解决以下两个问题:
1. 对于未分配的分片,给出没有分配的具体原因
2. 对于已分配的分片,给出为什么将分片分配给特点节点的原因
通过Explain API获取未分配原因解释
GET /_cluster/allocation/explain
返回信息摘要:
1. current_state:分片当前状态
2. allocate_explanation:分配解释信息
3. node_allocation_decisions:每个节点的分配决定信息
GET /_cluster/allocation/explain
{
“index”: “test_index”,
“shard”: 0,
“primary”: true
}
返回信息摘要:
1. current_node:分片分配的节点
当节点CPU使用率高时,需要通过线程的堆栈信息定位是什么任务导致的
两种方式:
1. 通过hot threads API查看热点线程,以及该线程的堆栈信息
2. 通过top+jstack,top查看占用CPU高的线程ID,配合jstack查看线程的堆栈信息
通常是用jmap导出一个堆,加载到MAT中进行分析,可以精确定位数据结构占用内存大小
1. bulk队列:通过_cat API查看bulk队列当前的任务数,bulk队列使用的内存量就是任务数*bulk请求占用的内存大小。默认值为200,一般够用了。
2. Netty缓冲:Netty收到客户端请求时,为连接创建内存池,将客户端请求的数据存储在内存池中,当ES处理完上层逻辑,回复客户端时,才会将内存释放。如果执行bulk请求时,请求超时设置的过短,客户端断开连接,此时服务器仍然在处理请求,客户端立即发送下一次请求,这样反反复复会导致Netty的内存池中存储过多的请求数据
3. indexing buffer:ES执行写操作时,会将索引好的文档存储在indexing buffer,当indexing buffer满时会生成一个新的lucene分段。由于全部分片共享一个indexing buffer,加大该缓冲会造成比较大的GC压力
4. 超大数据集的聚合:协调节点对数据节点返回的数据进行聚合,如果聚合的数据过大可能会导致OOM
5. FieldData Cache:当要对text类型字段进行排序、聚合时,需要开启fielddata,默认是关闭的,如果开启了,默认fielddata cache大小没有上限
6. Shard request cache:分片级别的请求缓存。每个分片独立缓存查询结果,默认大小是堆内存的1%,采用LRU淘汰策略。默认只缓存size为0的查询,并不会缓存命中结果(hits),只会缓存hits.total,suggestion,aggretions
7. Node Query Cache:节点查询缓存由节点上所有分片共享,也是一个LRU缓存,只缓存在过滤器上下文中使用的查询,默认开启,大小为堆内存的10%
ES记录了两种类型的慢日志:
1. 慢搜索日志
记录哪些查询比较慢,"慢"的程度由程序自己定义,每个节点可以设置不同的阈值,ES的搜索由两阶段组成:query、fetch。慢搜索日志给出每个阶段花费的时间,以及整个查询花费的时间。
2. 慢索引日志
记录哪些索引操作比较慢,阈值同样可以自己设置
22.6.1 IO信息
iostat是用来分析IO状态的常用工具
使用1s间隔采样:
iostat -xd 1
详细指标查一下
iostat提供磁盘级的IO状态,可以使用pidstat或者iptop给出每个进程的读写速度