作者:艾彦波,GrowingIO 服务端架构师,反应式架构践行者。负责 GrowingIO 亿级 DAU 技术架构与演进,目前专注在 Service Mesh 架构上。
GrowingIO 作为国内领先的数据运营解决方案供应商,为上千家企业提供基于用户行为的增长解决方案。
为满足企业的不同侧重与需求,GrowingIO 支持私有化和 SaaS 两种部署方式。两种部署方式的内容架构与交互设计不同,但相同的是产品底层逻辑,以及数据中心、用户库、产品分析、智能运营等产品线。
这些产品线在研发环境中,被设计为多个相互独立的微服务。为避免研发资源浪费,GrowingIO 需要确保同一批微服务可在不同部署模式的环境中均正常运行。
SaaS 与私有部署环境的差别
要解决这个问题,我们需要找到 SaaS 与私有部署之间的差别。根据我们的经验,总结了以下几个主要的差别:
- 云生态的差别:SaaS 产品部署在公有云环境里,能使用标准的接口管理资源(实例),也可以非常方便地使用公有云的产品生态去架构服务的高可用。在私有部署的环境里面,资源的访问方式,云平台的产品形态都不太一样。
- 数据隔离级别:SaaS 产品需要有非常完备且严格的多租户数据隔离方案。在私有部署的环境里面,数据隔离的级别会因为客户的需求有细微的区别。
- 用户访问量:SaaS 需要满足几千家客户业务需求,要支撑这些访问的可靠性,需要有一个可靠的集群。在私有部署的环境里,服务只需要满足 1 家客户的业务需求,客户对资源有一定的预算。
- 运维方式不同:SaaS 产品有公司专业的 SRE 负责,他们有非常丰富的故障处理经验,每个服务也有非常固定的上线流程。在私有环境里,客户可能不太熟悉服务的架构,服务升级会相对困难,处理故障不会那么快速。
针对上面的这些主要问题,我们在服务端分成 3 个方向去解决:
- 减少服务个数
- 减少中间件依赖
- 插件化个性需求
通过使用这 3 个方面的改进,我们能带来的好处是:降低了服务对最小资源的限制,高可用方案的复杂度,运维的困难性以及满足部分个性化的部署需求。
接下来,聊一聊 GrowingIO 具体是如何做到的:
1,减少服务个数 - 合并微服务独立进程
减少服务个数最简单直接的方式是,将原本在 SaaS 上独立运行的同构微服务,在私有部署的环境中让它们合并在一个进程上运行。这种既能独立又能合并运行的能力,在 Java 领域中已经有成熟的技术:
- OSGi - Java 动态模型系统,使用标准化原语,将应用程序以组件的方式自由组合运行。
- Servlet 容器技术 - 应用程序使用标准的 Servlet 接口,将自身以 web jar 的方式部署到像 Tomcat, Jetty 等 Servlet 容器中运行。
使用上面任何一种方案,对于现有的系统都存在这几个问题。首先,需要将现有的服务改造以实现 OSGi 或 Servlet 标准。另外,对于不能合并在一起运行的服务,希望能继续使用 gRPC 的方式进行服务间的通讯,需要找到一种方式能让它们支持发布 gRPC 服务。
因此,我们需要设计一个模块化系统,既能达成让服务一起运行的目标,又只花少量的时间改造。为了让效果更有成效,对这个模块化系统做了几点要求:
- 使用相同 HTTP 框架的服务(我们使用的框架有:akka-http, undertow, netty)共同使用一个 HTTP 端口
- 所有服务共同使用一个 gRPC 端口
- 运行在同一个 JVM 进程上的服务间通讯由 gRPC 远程调用切换成堆栈调用
- 不同 JVM 之间的服务调用方式保持不变
如下图所示:
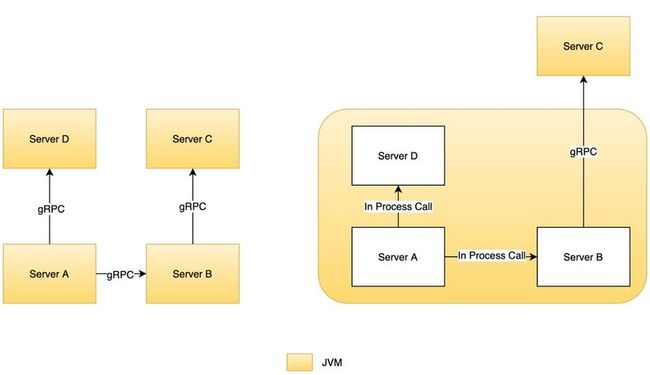
要实现这个模块化系统,我们需要想清楚一个问题:服务的本质是什么?在我看来,服务的本质不是一个 HTTP 或 gRPC 接口,服务的本质是真正的业务处理逻辑。HTTP 或 gRPC 只是对外通讯的一个手段而已。
当清楚服务的本质就是业务逻辑时,模块化的定义就变得非常清晰。然后,我们构建这个模块化的运行环境就能使得它们能在一起运行。要构建这个模块化运行环境不必要知道模块里具体实现了什么逻辑,只需要知道这个模块初始化需要什么,依赖了哪些服务,暴露的服务有哪些。根据这些具体的需求,能很清楚地用代码表示:
trait BoxerModule {
// 打开调试模式
def debug(): Unit
def injector: Injector
// 模块是否暴露 HTTP 服务,以及使用的 HTTP 框架
def httpEngine: Option[ServerEngine]
// 模块暴露的 gRPC 服务集合
def grpcServices: Set[BindableService]
// 模块的后台服务集合
def workers: Seq[ServiceBuilder]
// 模块的启动服务集合
def bootstraps: Seq[ServiceBuilder]
// 注入上下文信息
def aware(context: ModuleContext): Unit
}
trait ServiceBuilder {
def build(injector: Injector): Service
}
// 模块上下文信息
trait ModuleContext {
// gRPC 进程内通道
def grpcChannel: ManagedChannel
// 判断某个 gRPC 服务是否可以使用进程内调用
def isInProcessServiceStub(stubClass: Class[_]): Boolean
}在上面的代码中,我们主要描述了以下几个信息:
- 模块的上下文信息
- 模块暴露的服务集合
接下来,要解决的是将多个服务(也就是 ModuleContext)合并在一起运行。在这之前,我们还需要解决几个问题:
- 用什么样的方式将多个服务合并在一起?
- 在同一个 JVM 内,怎么保证模块之间的既能相互调用,又能保持相互独立?

如上图,Server A 与 Server B 都有 GlobalConfig 对象,它们的类路径一致,包含的字段属性也一致,但是它们字段属性的值却不一样。如果将这两个服务作为依赖的方式引入到同一个项目里面运行,这种方式虽然简单但是没有解决模块之间的隔离型问题。会发生 A 会覆盖 B 或者 B 覆盖 A 的问题。
那如何做到让它们保持相互独立呢?这时候,我们可以使用 JVM 的 ClassLoader 机制。在 JVM 中,两个非父子关系的 ClassLoader 加载到的内容是相互隔离的。所以,如果我们将不同的模块使用不同的 ClassLoader 加载就能让它们保持相互独立了。如下图:
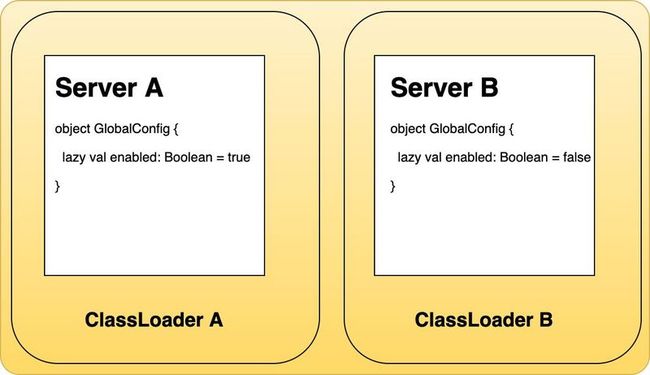
上图中的 ClassLoader 构造,可以使用下面的代码实现:
val classLoaderA = new URLClassLoader(serverA.libs, parent)
val classLoaderB = new URLClassLoader(serverB.libs, parent)模块被加载成 ClassLoader 了,初始化模块就变得简单许多了。参考 Java 9 模块化的设计,我们为每个微服务加入了模块描述文件,如下图:我们在 growing-insight 服务里面加入了 BoxerModuleInfo 文件描述模块内容。

上图中的 SimpleBoxerModule 是默认的模块内容描述,如果使用者用标准的模式开发服务,那么他只需要创建一个 BoxerModuleInfo 文件并继承 SimpleBoxerModule 就能完成模块注册。是使用方式及其简单。
class SimpleBoxerModule extends BoxerModule {
private[this] var moduleContext: ModuleContext = _
private[this] lazy val applicationContext = new ApplicationContextLoader(moduleContext).load(GlobalConfig.Server)
override def debug(): Unit = {}
override def injector: Injector = applicationContext.injector
override def httpEngine: Option[ServerEngine] = applicationContext.httpEngineOpt
override def grpcServices: Set[BindableService] = applicationContext.grpcServices
override def hooks: Seq[ApplicationHook] = applicationContext.hooks
override def workers: Seq[ServiceBuilder] = applicationContext.workers
override def bootstraps: Seq[ServiceBuilder] = applicationContext.bootstraps
override def aware(context: ModuleContext): Unit = moduleContext = context
}根据模块内容描述文件,用下面代码的方式能将 ClassLoader 初始化成一个一个服务模块:
val loader = new ModuleAppClassLoader(urls, parent)
val boxerModuleInfoClass = loader.loadClass("BoxerModuleInfo")
val module = boxerModuleInfoClass.newInstance().asInstanceOf[BoxerModule]得到了 Module 对象,就能依据它暴露的服务合并在一起发布一个新的服务列表了。接下来,要解决的是如何让原本通过远程调用的 gRPC 服务转换成进程内堆栈调用。这里就不得不提在 BoxerModule 定义中的 ModuleContext 了。通过使用它的 isInProcessServiceStub 方法判断某一个 gRPC 是否可以使用进程内调用,如果可以进程内调用,使用 grpcChannel 初始化 gRPC Stub 就能完成进程内调用了。
以上,是整个模块化系统设计与实现的核心逻辑。不过还能在 ClassLoader 的架构上更进一步,达到上文中提到的减少资源使用的目标。
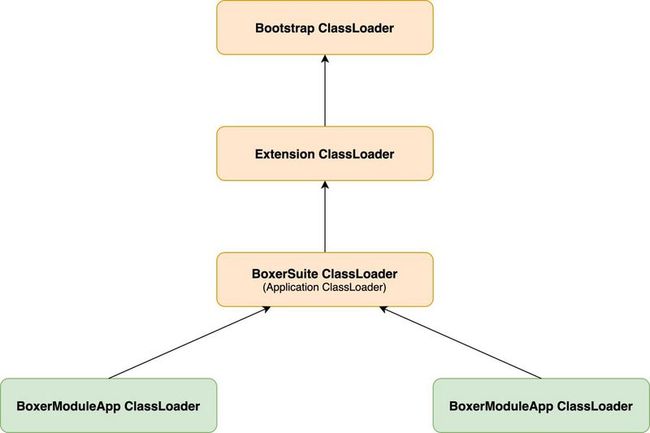
服务与服务(即模块与模块)之间,除了业务逻辑以及需要隔离的类之外,剩下的框架部分绝大部分是一致的,框架部分的类没有隔离的必要性。如下图,将不需要隔离性的框架类通过 BoxerSuiteClassLoader 管理可以提高内存空间利用率,因为 JVM 类加载器有双亲委派机制,ClassLoader 会优先从父 ClassLoader 加载类信息。
2,减少中间件依赖 - 去掉中心化服务注册中心
在 GrowingIO 的 SaaS 环境中,我们使用 Consul +
Dryad(https://github.com/growingio/dryad我们开源的一个服务注册发现与配置管理组件) 实现服务的注册与发现。为了降低私有部署的环境复杂性,去掉 Consul 集群是一个有效的方式。因此选择了类似于 nginx 中 upstream 的方式实现服务集群的高可用。私有部署的用户访问流量比起 SaaS 上具有较强的可预测性,不需要经常性地做动态扩容。所以,使用这种方式并不会带来特别高的维护成本。
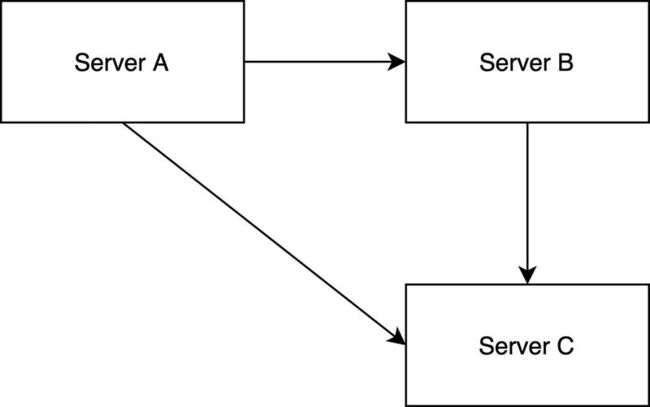
如上图所示,Server A 在本地维护了 Server B 与 Server C 的地址。在使用的过程中根据 Server Name 可以找到服务具体的地址。这一功能,已经在 Dryad 里开源出来了。使用的过程如下代码:
- 定义服务具体的地址
dryad {
cluster {
direct = true // 为 true 则直接使用本地的集群配置,为 false 则通过 consul 的方式注册与发现服务
events = [ // events 是服务的名称
{
address = "10.0.0.1"
port = 8080
},
{
address = "10.0.0.2"
port = 8080
}
]
}
}- 使用 io.growing.dryad.cluster.Cluster 的 roundRobin 接口获取服务信息
val server = cluster.roundRobin(Schema.GRPC, "events")3,个性化需求 - 插件化
GrowingIO 服务的 SaaS 版本与私有部署版本使用的是同一个代码分支,在面对私有部署版本中的个性化需求时,使用的是 “插件化” 的思想解决实现不一致的问题。
即使用标准化的接口允许多个不同的实现满足个性化需求。例如,在 SaaS 版本中为了满足多租户数据隔离的需求,有一个专门的服务去管理各个用户的数据作用域。在私有版本中,我们保留了支持多租户数据隔离的这个功能,但是简化了它的实现逻辑。
如下图,GrowingIO 使用接口 + 多个实现的方式满足个性化需求:
|- service // 接口定义
| - impl // SaaS 上的标准实现
| - extension // 私有部署上的个性化实现在服务启动时,通过配置可以决定需要加载哪种实现,这个过程是自动完成的,不需要在开发过程中干预。
extension {
enabled = true // 是否按照拓展的方式加载实现
key = "extension" // 加载的个性化需求地址(默认是 extension,如果有多个客户的实现不一样,修改 key 的值即可)
}总结
本文,我们讨论了 GrowingIO 是如何让微服务支持 SaaS 与私有部署 2 种不同的环境的。要去解决它们之间的兼容问题,就需要找到它们之间的差别。很多时候,这 2 个环境的许多部分都是相反的,我们要在架构设计中自顶向下去包容这种矛盾,不能哪里有问题就去解决哪里,这样只会让程序越来越复杂。