一次FullGC的探索旅程
目录
1.缘起
2.搜查
3.寻找Root Cause
4.打破砂锅问到底
5.缘灭
1.缘起
某天我正在优雅地码着代码,突然收到线上告警,内容简要如下。JVM FullGC在5分钟达到50余次,居然这么频繁,肯定有什么幺蛾子。这是个老项目,代码已无人维护,还是自己动手,丰衣足食。
级别:P1
主机名:XXXXX
监控项:sum(#1) jvm.fullgc.count > 50
当前值:55
2.搜查
既然是有关FullGC的问题,脑袋里搜罗了一下思路。
1.可能是突发流量,导致QPS陡增,内存来不及回收,导致FullGC。
看了一下监控系统,发现流量比较平稳,排除
2.可能是内存产生了泄漏,导致老年代不断膨胀,产生FullGC
服务开启了OOM Dump和GC日志打印。登上服务器,发现并没有dump文件,只好去GC日志里面找找线索
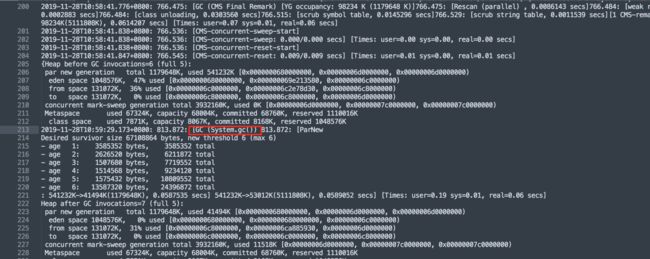
上图是截取的日志片段。大概浏览了一下,GC收集器用的是CMS,并且在发生FullGC时,有System.gc字样。
根据经验,这应该是应用代码在显式调用System.gc函数。然后去代码里全局搜索,发现项目里并没有显式调用。
本以为找到了问题,结果无功而返,衰:( 。看来只能另寻出路,既然事后案发现场没什么其他疑点,那去线上实时看一下呢。因为这是个采集任务,还是集群化,线上实时监控一台机器风险还是可控的(其实是迫不得已)。
一般Java线上查问题可以用Btrace,Arthas这些,但是代码不是我写的,看完代码逻辑,再凭直觉哪里可能出问题,btrace一下,这个流程有点慢,效率不高。干脆来个暴力点的,用Jprofiler--性能诊断利器。大致准备工作如下:
Linux上下载jprofiler,启动并让其监视JVM进程,类似一个agent角色。本地机器下载jprofiler,并开启GUI,连接上agent端口,就可以实时查看了。
下面就是等待告警再次发生时,查看jprofiler各项指标,寻找蛛丝马迹。先看GC情况,如下图
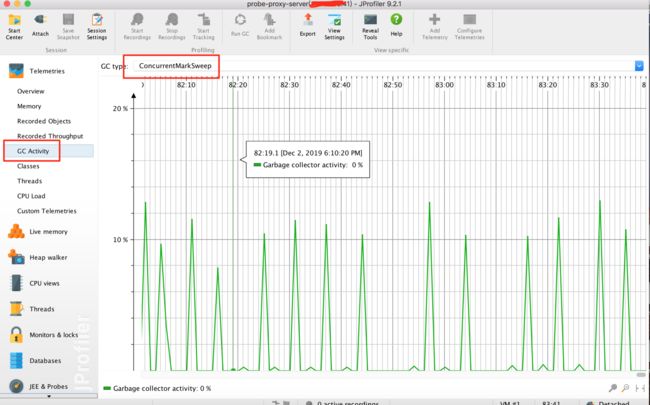
可以看到CMS GC、FullGC发生频繁,每隔几秒来一次,这有可能是堆内存不够了。那就看看heap情况,如下
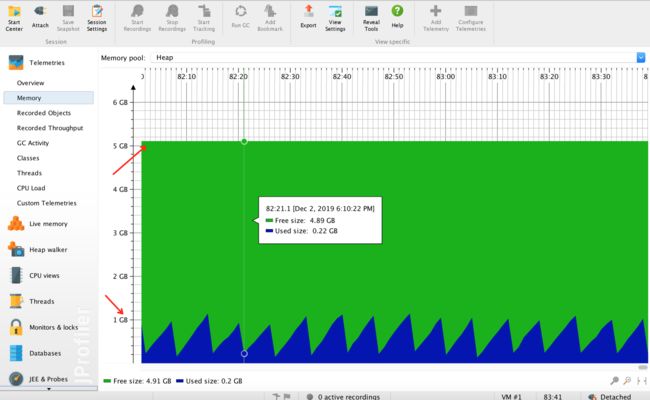
堆大小为5G,实际才用了1G,What???这还有80%的空间在呢,为啥还疯狂FullGC!
怀疑人生的同时,以为这监控工具有问题,就去线上机器,实时jstat一下gc情况。如下图:

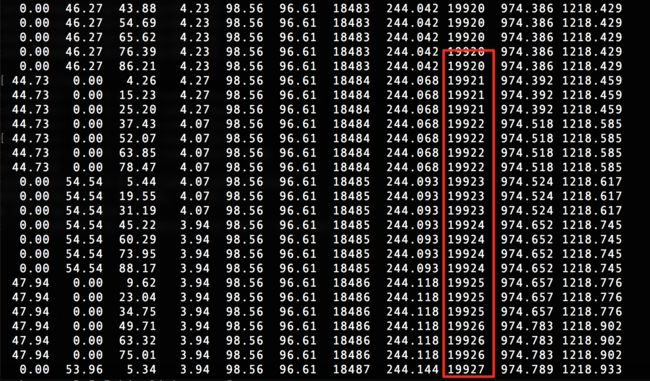
情况确实是这样,两种方式都佐证了当前的现象。
看来要重新思考。想想之前的现象,虽然System.GC 在项目自身代码没有找到,但是这个现象确实用 System.gc 解释得通啊。
当应用层调用 System.gc() 函数后,JVM 不会立即执行 FullGC,这个只是建议 JVM 应该去做 GC了,那至于 JVM 何时去做,控制权在 JVM 。但是个人觉得,如果应用层如此频繁的建议JVM进行垃圾回收,就算堆内存还很充足,JVM也得给点面子,不会对我们显式的GC视而不见吧 :)
按照这个想法,有没有可能第三方库做的呢?
带着疑问,全局搜了下System.gc的地方,比较有趣的是:JDK里面居然有个类,存在显式的调用。如下图,
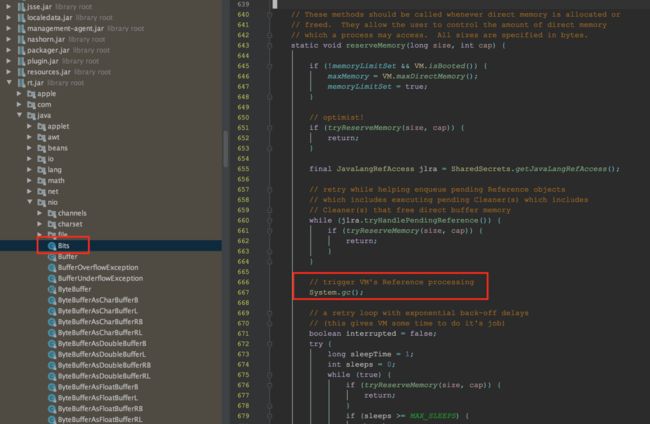
看样子跟Direct Memory有些渊源,但是似乎和这个程序没多大关系。
束手无策的我,只能去看看堆栈stack信息有没有帮助。jstack一下,然后搜索system.gc字眼。嚯!居然还真有。
看着如此亲切而又陌生的System.gc,兴奋之情溢于言表。真是踏破铁鞋无觅处,得来全不费工夫!
仔细看看这个调用栈,不难发现 jetty.websocket。原来是这玩意调用的,应用层最后一个函数调用是:BufferUtil.allocateDirect。原来是去开辟Direct Memory---直接堆外内存。最贴近System.gc()调用的栈函数是Bits.reserveMemory(),这不正是刚才看到JDK中那段调用代码吗。全都对上了!
3.寻找Root Cause
原因已经找到了,项目里面使用了jetty的websocket。Jetty发现外界连接并发多了后,会去申请堆外内存,就会显式调用System.gc,正好VM启动参数没有配 +DisableExplicitGC,故显式GC生效。然后就看到FullGC在堆内存完全够用的情况下频繁发生。
4.打破砂锅问到底
现在问题来了,JDK 在分配堆外内存的时候,为什么要强制进行 System.gc,吃饱了没事撑了?显然大佬们不会犯这个错。网上搜索了一下,找了大牛你假笨(江湖人称:寒泉子)的一段称述:
对于System.gc,它会对新生代和老生代都进行内存回收,这样会比较彻底地回收DirectByteBuffer对象以及他们关联的堆外内存,我们dump内存发现DirectByteBuffer对象本身其实是很小的,但是它后面可能关联了一个非常大的堆外内存,因此我们通常称之为『冰山对象』,我们做ygc的时候会将新生代里的不可达的DirectByteBuffer对象及其堆外内存回收了,但是无法对old里的DirectByteBuffer对象及其堆外内存进行回收,这也是我们通常碰到的最大的问题,如果有大量的DirectByteBuffer对象移到了old,但是又一直没有做cms gc或者full gc,而只进行ygc,那么我们的物理内存可能被慢慢耗光,但是我们还不知道发生了什么,因为heap明明剩余的内存还很多(前提是我们禁用了System.gc)。
还有一位
这时,就只能靠前面提到的申请额度超限时触发的system.gc()来救场了。但这道最后的保险其实也不很好,首先它会中断整个进程,然后它让当前线程睡了整整一百毫秒,而且如果gc没在一百毫秒内完成,它仍然会无情的抛出OOM异常。还有,万一,万一大家迷信某个调优指南设置了-DisableExplicitGC禁止了system.gc(),那就不好玩了。
所以,堆外内存还是自己主动点回收更好,比如Netty就是这么做的。
原来通过JDK ByteBuffer分配(allocateDirect) 出去的堆外内存也是被JVM GC负责的。但是负责的粒度没有那么大,只会根据堆外内存在堆内指针引用的对象是否存活来判断是否回收,而不会去管这个对象究竟有多大。所以,JDK为了确保堆外内存受控,会及时回收垃圾,显式进行GC操作。当然显式GC带来内存回收好处的同时,也会对应用程序造成很大延时,这是用户所不愿看到的。所以JDK提供Unsafe来让开发者全权掌控堆外内存的分配和释放。
5.缘灭
由一个FullGC引出了这么多内容,不禁感慨:写代码容易,调代码难,调人家代码更难!!
话说回来,做学问还是要深究,究着究着,会发现自己学的越来越多,懂的却越来越少。
路漫漫其修远兮,吾将上下而求索!!!