基本统计
- 基本统计分析:描述性统计分析,用于概括事务整体状况以及树屋建联系(及事务的基本特征),以发现其内在规律的统计分析方法。
- 常用的统计指标 describe()
- 计数 size
- 求和 sum
- 平均值 mean
- 方差var
- 标准差std
data.score.describe()
data.score.size
data.score.max()
data.score.min()
data.score.sum()
data.score.mean()
data.score.var()
data.score.std()
#累计求和
data.score.cumsum()
#最大值和最小值所在位置
data.score.argmin()
data.score.argmax()
#百分位数排序数 (在30%的位置,没有找最近的)
data.score.quantile(
0.3,
interpolation="nearest"
)
分组分析
- 分组分析:是指根据分组字段,将分析对象划分成不同的部分,以进行对不分析各组之间的差异性的一种分析方法。
- 常用的统计指标
- 计数
- 求和
- 平均值
import numpy
import pandas
data = pandas.read_csv(
'/Users/cuiwenhao/Data_xxx/5.2/data.csv'
)
class,name,score
一班,朱志斌,120
一班,朱凤,122
一班,郑丽萍,140
一班,郭杰明,131
一班,许杰,122
二班,郑芬,119
二班,林龙,96
二班,林良坤,135
二班,黄志红,105
三班,方小明,114
三班,陈丽灵,115
三班,方伟君,136
三班,庄艺家,119
aggResult = data.groupby(
by=['class']
)['score'].agg({
'总分': numpy.sum,
'人数': numpy.size,
'平均值': numpy.mean
})
print(aggResult)
平均值 人数 总分
class
一班 127.00 5 635
三班 121.00 4 484
二班 113.75 4 455
分布分析

#按年龄分组统计每个年龄的人数
aggResult = data.groupby(
by=['年龄']
)['年龄'].agg({
'人数': numpy.size
})
#分组 组距
bins = [
min(data.年龄)-1, 20, 30, 40, max(data.年龄)+1
]
#分组名称
labels = [
'20岁以及以下', '21岁到30岁', '31岁到40岁', '41岁以上'
]
#进行数据分组
data['年龄分层'] = pandas.cut(
data.年龄,
bins,
labels=labels
)
print(data)
用户ID 注册日期 身份证号码 性别 出生日期 年龄 年龄分层
0 100000 2011/1/1 15010219621116401I 男 1962/11/16 52 41岁以上
1 100001 2011/1/1 45092319910527539E 男 1991/5/27 23 21岁到30岁
2 100002 2011/1/1 35010319841017421J 男 1984/10/17 30 21岁到30岁
3 100006 2011/1/1 37110219860824751B 男 1986/8/24 28 21岁到30岁
4 100010 2011/1/1 53042219860714031J 男 1986/7/14 28 21岁到30岁
5 100011 2011/1/1 32012519871028001B 男 1987/10/28 27 21岁到30岁
6 100012 2011/1/1 23030219930828581I 男 1993/8/28 21 21岁到30岁
7 100013 2011/1/1 42112619900301477J 男 1990/3/1 24 21岁到30岁
8 100015 2011/1/1 53012119811002001I 男 1981/10/2 33 31岁到40岁
#按年龄分层分组统计人数
aggResult1 = data.groupby(
by=['年龄分层']
)['年龄'].agg({
'人数': numpy.size
})
print(aggResult1)
人数
年龄分层
20岁以及以下 2061
21岁到30岁 46858
31岁到40岁 8729
41岁以上 1453
#变换为百分比
pAggResult = round(
aggResult/aggResult.sum(),
2
)*100
pAggResult['人数'].map('{:,.2f}%'.format)
年龄分层
20岁以及以下 3.00%
21岁到30岁 79.00%
31岁到40岁 15.00%
41岁以上 2.00%
交叉分析
- 交叉分析:通常用于分析两个或两个以上,分组变量之间的关系,以交叉表形式惊醒变量间关系的对比分析;
- 定量、定量分组交叉
- 定量、定性分组交叉
-
定性、定性分组交叉
Excel透视表
#分组 组距
bins = [
min(data.年龄)-1, 20, 30, 40, max(data.年龄)+1
]
#分组名称
labels = [
'20岁以及以下', '21岁到30岁', '31岁到40岁', '41岁以上'
]
#进行数据分组
data['年龄分层'] = pandas.cut(
data.年龄,
bins,
labels=labels
)
#年龄分层的男女比例
x=data.pivot_table(
values=['年龄'],
index=['年龄分层'],
columns=['性别'],
aggfunc=[numpy.size]
)
年龄
性别 女 男
年龄分层
41岁以上 111 1950
21岁到30岁 2903 43955
31岁到40岁 735 7994
20岁以及以下 567 886
结构分析
-
结构分析:是在分组以及交叉的基础上,计算各组成部分所占的比重,进而分析总体的内部特征的一种分析方法
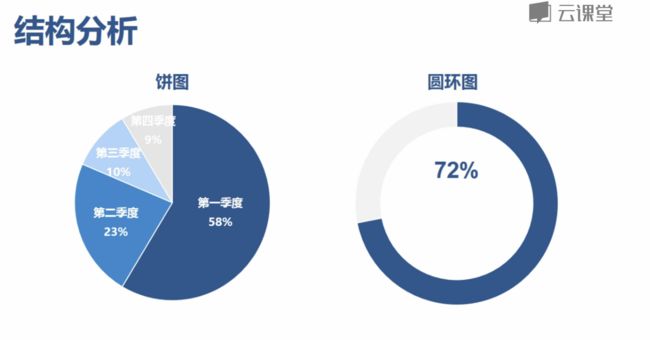
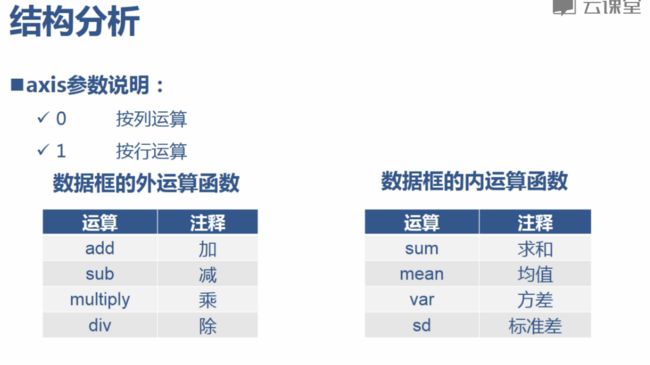 image.png
image.png
ptResult = data.pivot_table(
values=['年龄'],
index=['年龄分层'],
columns=['性别'],
aggfunc=[numpy.size]
)
年龄
性别 女 男
年龄分层
41岁以上 111 1950
21岁到30岁 2903 43955
31岁到40岁 735 7994
20岁以及以下 567 886
#按列
ptResult.sum(axis=0)
size 年龄 女 4316
男 54785
#按行
ptResult.sum(axis=1)
年龄分层
41岁以上 2061
21岁到30岁 46858
31岁到40岁 8729
20岁以及以下 1453
#列占行
ptResult.div(ptResult.sum(axis=1), axis=0)
年龄
性别 女 男
年龄分层
41岁以上 0.053857 0.946143
21岁到30岁 0.061953 0.938047
31岁到40岁 0.084202 0.915798
20岁以及以下 0.390227 0.609773
#行占列 行分组占男、女列
ptResult.div(ptResult.sum(axis=0), axis=1)
年龄
性别 女 男
年龄分层
41岁以上 0.025718 0.035594
21岁到30岁 0.672614 0.802318
31岁到40岁 0.170297 0.145916
20岁以及以下 0.131372 0.016172
相关分析
- 相关分析:是研究两个或两个以上随机变量之间相互依存关系的方向和密切程度的方法。

- 相关分析函数
- DataFrame.corr()
- Series.corr(other)
- 函数说明:
- 如果由数据框调用correct方法,那么将会计算每个列两两之间的相似度
- 有过由序列调用corr的方法,那么只是计算该序列与传入的序列之间的相关度
- 返回值
- DataFrame调用:返回DataFrame
- Series调用:返回一个数值型,大小为相关度
#原数据
小区ID,人口,平均收入,文盲率,超市购物率,网上购物率,本科毕业率
1, 3615, 3624, 2.1, 15.1, 84.9, 41.3
2,365,6315,1.5,11.3,88.7,66.7
3,2212,4530,1.8,7.8,92.2,58.1
4,2110,3378,1.9,10.1,89.9,39.9
5,21198,5114,1.1,10.3,89.7,62.6
6,2541,4884,0.7,6.8,93.2,63.9
7,3100,5348,1.1,3.1,96.9,56
8,579,4809,0.9,6.2,93.8,54.6
#先来看看如何进行两个列之间的相关度的计算
data['人口'].corr(data['文盲率'])
0.10762237339473261 #低度相关
#多列之间的相关度的计算方法
#选择多列的方法
data[[
'超市购物率', '网上购物率', '文盲率', '人口'
]]
data[[
'超市购物率', '网上购物率', '文盲率', '人口'
]].corr()
超市购物率 网上购物率 文盲率 人口
超市购物率 1.000000 -1.000000 0.702975 0.343643
网上购物率 -1.000000 1.000000 -0.702975 -0.343643
文盲率 0.702975 -0.702975 1.000000 0.107622
人口 0.343643 -0.343643 0.107622 1.000000