3.Dstream 创建
Spark Streaming 原生支持一些不同的数据源。一些“核心”数据源已经被打包到 Spark
Streaming 的 Maven 工件中,而其他的一些则可以通过 spark-streaming-kafka 等附加工件获取。
每个接收器都以 Spark 执行器程序中一个长期运行的任务的形式运行,因此会占据分配给应用
的 CPU 核心。此外,我们还需要有可用的 CPU 核心来处理数据。这意味着如果要运行多个接
收器,就必须至少有和接收器数目相同的核心数,还要加上用来完成计算所需要的核心数。例如,
如果我们想要在流计算应用中运行 10 个接收器,那么至少需要为应用分配 11 个 CPU 核心。
所以如果在本地模式运行,不要使用 local 或者 local[1]。
3.1 文件数据源
3.1.1 用法及说明
文件数据流:能够读取所有 HDFS API 兼容的文件系统文件,通过 fileStream 方法进行读取,
Spark Streaming 将会监控 dataDirectory 目录并不断处理移动进来的文件,记住目前不支持嵌套目
录。
streamingContext.textFileStream(dataDirectory)
注意事项:
1)文件需要有相同的数据格式;
2)文件进入 dataDirectory 的方式需要通过移动或者重命名来实现;
3)一旦文件移动进目录,则不能再修改,即便修改了也不会读取新数据;
3.1.2 案例实操
(1)在 HDFS 上建好目录
[lxl@hadoop102 spark]$ hadoop fs -mkdir /fileStream
(2)在/opt/module/data 创建三个文件
[lxl@hadoop102 data]$ touch a.tsv
[lxl@hadoop102 data]$ touch b.tsv
[lxl@hadoop102 data]$ touch c.tsv
添加如下数据:
Helloatguigu
Hellospark
(3)编写代码
package com.lxl import org.apache.spark.SparkConf import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.streaming.dstream.DStream object FileStream { def main(args: Array[String]): Unit = { //1.初始化 Spark 配置信息 val sparkConf = new SparkConf().setMaster("local[*]") .setAppName("StreamWordCount") //2.初始化 SparkStreamingContext val ssc = new StreamingContext(sparkConf, Seconds(5)) //3.监控文件夹创建 DStream val dirStream = ssc.textFileStream("hdfs://hadoop102:9000/fileStream") //4.将每一行数据做切分,形成一个个单词 val wordStreams = dirStream.flatMap(_.split("\t")) //5.将单词映射成元组(word,1) val wordAndOneStreams = wordStreams.map((_, 1)) //6.将相同的单词次数做统计 val wordAndCountStreams = wordAndOneStreams.reduceByKey(_ + _) //7.打印 wordAndCountStreams.print() //8.启动 SparkStreamingContext ssc.start() ssc.awaitTermination() } }
(4)启动程序并向 fileStream 目录上传文件
[lxl@hadoop102 data]$ hadoop fs -put ./a.tsv /fileStream [lxl@hadoop102 data]$ hadoop fs -put ./b.tsv /fileStream [lxl@hadoop102 data]$ hadoop fs -put ./c.tsv /fileStream
(5)获取计算结果
------------------------------------------- Time: 1539073810000 ms ------------------------------------------- ------------------------------------------- Time: 1539073815000 ms ------------------------------------------- (Hello,4) (spark,2) (atguigu,2) ------------------------------------------- Time: 1539073820000 ms ------------------------------------------- (Hello,2) (spark,1) (atguigu,1) ------------------------------------------- Time: 1539073825000 ms -------------------------------------------
3.2 RDD 队列
3.2.1 用法及说明
测试过程中,可以通过使用 ssc.queueStream(queueOfRDDs)来创建 DStream,每一个推送到
这个队列中的 RDD,都会作为一个 DStream 处理。
3.2.2 案例实操
1)需求:循环创建几个 RDD,将 RDD 放入队列。通过 SparkStream 创建 Dstream,计算 WordCount
2)编写代码
package com.atguigu import org.apache.spark.SparkConf import org.apache.spark.rdd.RDD import org.apache.spark.streaming.dstream.{DStream, InputDStream} import org.apache.spark.streaming.{Seconds, StreamingContext} import scala.collection.mutable object RDDStream { def main(args: Array[String]) { //1.初始化 Spark 配置信息 val conf = new SparkConf().setMaster("local[*]").setAppName("RDDStream") //2.初始化 SparkStreamingContext val ssc = new StreamingContext(conf, Seconds(4)) //3.创建 RDD 队列 val rddQueue = new mutable.Queue[RDD[Int]]() //4.创建 QueueInputDStream val inputStream = ssc.queueStream(rddQueue,oneAtATime = false) //5.处理队列中的 RDD 数据 val mappedStream = inputStream.map((_,1)) val reducedStream = mappedStream.reduceByKey(_ + _) //6.打印结果 reducedStream.print() //7.启动任务 ssc.start() //8.循环创建并向 RDD 队列中放入 RDD for (i <- 1 to 5) { rddQueue += ssc.sparkContext.makeRDD(1 to 300, 10) Thread.sleep(2000) } ssc.awaitTermination() } }
3)结果展示
------------------------------------------- Time: 1539075280000 ms ------------------------------------------- (4,60) (0,60) (6,60) (8,60) (2,60) (1,60) (3,60) (7,60) (9,60) (5,60) ------------------------------------------- Time: 1539075284000 ms ------------------------------------------- (4,60) (0,60) (6,60) (8,60) (2,60) (1,60) (3,60) (7,60) (9,60) (5,60) ------------------------------------------- Time: 1539075288000 ms ------------------------------------------- (4,30) (0,30) (6,30) (8,30) (2,30) (1,30) (3,30) (7,30) (9,30) (5,30) ------------------------------------------- Time: 1539075292000 ms -------------------------------------------
3.3 自定义数据源
3.3.1 用法及说明
需要继承 Receiver,并实现 onStart、onStop 方法来自定义数据源采集。
3.3.2 案例实操
1)需求:自定义数据源,实现监控某个端口号,获取该端口号内容。
2)自定义数据源
package com.lxl
import java.io.{BufferedReader, InputStreamReader} import java.net.Socket import java.nio.charset.StandardCharsets import org.apache.spark.storage.StorageLevel import org.apache.spark.streaming.receiver.Receiver
class CustomerReceiver(host: String, port: Int) extends Receiver[String](StorageLevel.MEMORY_ONLY) { //最初启动的时候,调用该方法,作用为:读数据并将数据发送给 Spark override def onStart(): Unit = { new Thread("Socket Receiver") { override def run() { receive() } }.start() } //读数据并将数据发送给 Spark def receive(): Unit = { //创建一个 Socket var socket: Socket = new Socket(host, port) //定义一个变量,用来接收端口传过来的数据 var input: String = null //创建一个 BufferedReader 用于读取端口传来的数据 val reader = new BufferedReader(new InputStreamReader(socket.getInputStream, StandardCharsets.UTF_8)) //读取数据 input = reader.readLine() //当 receiver 没有关闭并且输入数据不为空,则循环发送数据给 Spark while (!isStopped() && input != null) { store(input) input = reader.readLine() } //跳出循环则关闭资源 reader.close() socket.close() //重启任务 restart("restart") } override def onStop(): Unit = {} }
3)使用自定义的数据源采集数据
package com.atguigu
import org.apache.spark.SparkConf import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.streaming.dstream.DStream
object FileStream { def main(args: Array[String]): Unit = { //1.初始化 Spark 配置信息 Val sparkConf = new SparkConf().setMaster("local[*]").setAppName("StreamWordCount")
//2.初始化 SparkStreamingContext val ssc = new StreamingContext(sparkConf, Seconds(5))
//3.创建自定义 receiver 的 Streaming val lineStream = ssc.receiverStream(new CustomerReceiver("hadoop102", 9999))
//4.将每一行数据做切分,形成一个个单词 val wordStreams = lineStream.flatMap(_.split("\t"))
//5.将单词映射成元组(word,1) val wordAndOneStreams = wordStreams.map((_, 1))
//6.将相同的单词次数做统计 val wordAndCount = wordAndOneStreams.reduceByKey(_ + _)
//7.打印 wordAndCountStreams.print()
//8.启动 SparkStreamingContext ssc.start() ssc.awaitTermination() } }
3.4 Kafka 数据源
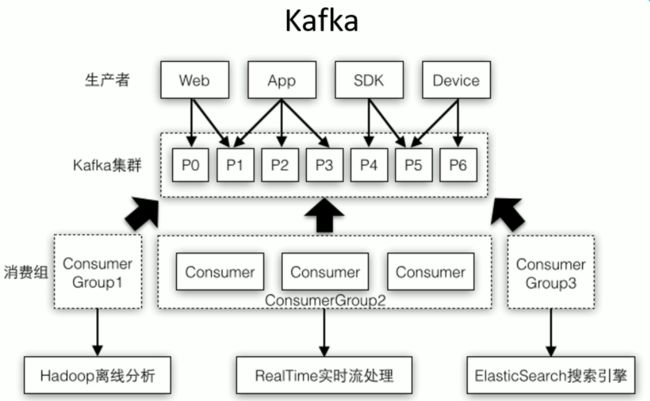
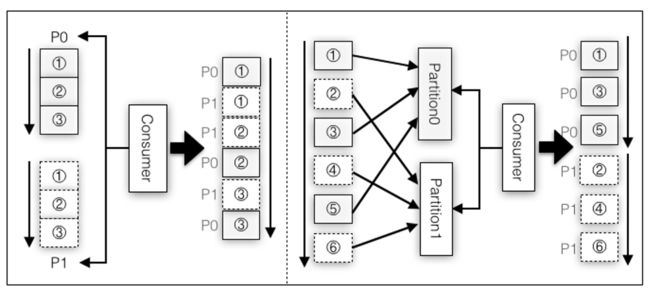
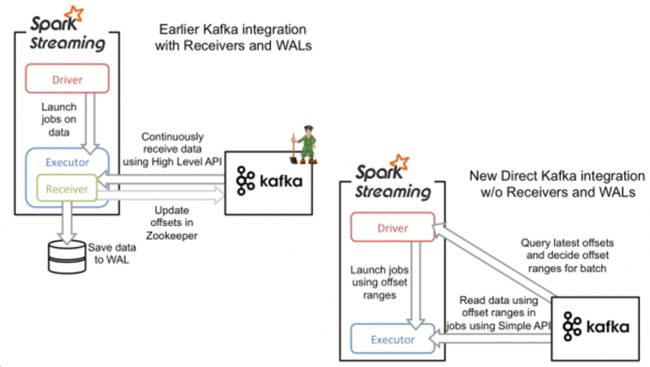
3.4.1 用法及说明
在工程中需要引入 Maven 工件 spark- streaming-kafka_2.10 来使用它。包内提供的
KafkaUtils 对象可以在 StreamingContext 和 JavaStreamingContext 中以你的 Kafka 消息创建出
DStream。由于 KafkaUtils 可以订阅多个主题,因此它创建出的 DStream 由成对的主题和消息
组成。要创建出一个流数据,需要使用 StreamingContext 实例、一个由逗号隔开的 ZooKeeper
主机列表字符串、消费者组的名字(唯一名字),以及一个从主题到针对这个主题的接收器线程数
的映射表来调用 createStream() 方法。
3.4.2 案例实操
1)需求 1:通过 SparkStreaming 从 Kafka 读取数据,并将读取过来的数据做简单计
算(WordCount),最终打印到控制台。
(1)导入依赖
org.apache.spark
spark-streaming-kafka_2.11
1.6.3
org.apache.kafka
kafka-clients
0.10.2.1
(2)编写代码
package com.lxl
import kafka.serializer.StringDecoder import org.apache.kafka.clients.consumer.ConsumerConfig import org.apache.spark.SparkConf import org.apache.spark.rdd.RDD import org.apache.spark.storage.StorageLevel import org.apache.spark.streaming.dstream.ReceiverInputDStream import org.apache.spark.streaming.kafka.KafkaUtils import org.apache.spark.streaming.{Seconds, StreamingContext}
object KafkaSparkStreaming { def main(args: Array[String]): Unit = {
//1.创建 SparkConf 并初始化 SSC val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("KafkaSparkStreaming") val ssc = new StreamingContext(sparkConf, Seconds(5))
//2.定义 kafka 参数 val zookeeper = "hadoop102:2181,hadoop103:2181,hadoop104:2181" val topic = "source" val consumerGroup = "spark"
//3.将 kafka 参数映射为 map val kafkaParam: Map[String, String] = Map[String, String]( ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer", ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer", ConsumerConfig.GROUP_ID_CONFIG -> consumerGroup, "zookeeper.connect" -> zookeeper )
//4.通过 KafkaUtil 创建 kafkaDSteam val kafkaDSteam: ReceiverInputDStream[(String, String)] = KafkaUtils.createStream[String, String, StringDecoder, StringDecoder]( ssc, kafkaParam, Map[String, Int](topic -> 3), StorageLevel.MEMORY_ONLY )
//5.对 kafkaDSteam 做计算(WordCount) kafkaDSteam.foreachRDD { rdd => { val word: RDD[String] = rdd.flatMap(_._2.split(" ")) val wordAndOne: RDD[(String, Int)] = word.map((_, 1)) val wordAndCount: RDD[(String, Int)] = wordAndOne.reduceByKey(_ + _) wordAndCount.collect().foreach(println) } }
//6.启动 SparkStreaming ssc.start() ssc.awaitTermination() } }
笔记:
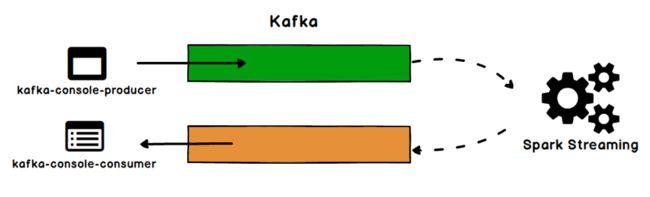
//启动kafka [lxl@hadoop102 ~]$ /opt/module/kafka/bin/kafka-server-start.sh /opt/module/kafka/config/server.properties [lxl@hadoop103 ~]$ /opt/module/kafka/bin/kafka-server-start.sh /opt/module/kafka/config/server.properties [lxl@hadoop104 ~]$ /opt/module/kafka/bin/kafka-server-start.sh /opt/module/kafka/config/server.properties //创建topic *source [lxl@hadoop102 ~]$ /opt/module/kafka/bin/kafka-topics.sh --zookeeper hadoop102:2181 --create --replication-factor 1 --partitions 2 --topic source //启动生产者 [lxl@hadoop102 ~]$ /opt/module/kafka/bin/kafka-console-producer.sh --broker-list hadoop102:9092 --topic source //创建topic *target [lxl@hadoop102 ~]$ /opt/module/kafka/bin/kafka-topics.sh --zookeeper hadoop102:2181 --create --replication-factor 1 --partitions 2 --topic target //启动消费者 [lxl@hadoop102 ~]$ /opt/module/kafka/bin/kafka-console-consumer.sh --zookeeper hadoop102:2181 --from-beginning --topic target
package com.atlxl.kafkaStreaming import java.util.Properties import org.apache.commons.pool2.impl.{DefaultPooledObject, GenericObjectPool} import org.apache.commons.pool2.{BasePooledObjectFactory, PooledObject} import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord} class KafkaProxy(brokers:String){ //存放配置文件 private val pros:Properties = new Properties() pros.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,brokers) pros.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer") pros.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer") val kafkaConn = new KafkaProducer[String,String](pros) def send(topic:String,key:String,value:String): Unit ={ kafkaConn.send(new ProducerRecord[String,String](topic,key,value)) } def send(topic:String,value:String): Unit ={ kafkaConn.send(new ProducerRecord[String,String](topic,value)) } def close: Unit ={ kafkaConn.close() } } class KafkaProxyFactory(brokers:String) extends BasePooledObjectFactory[KafkaProxy]{ //创建实例 override def create(): KafkaProxy = new KafkaProxy(brokers) //将池中对象封装 override def wrap(t: KafkaProxy): PooledObject[KafkaProxy] = new DefaultPooledObject[KafkaProxy](t) } object KafkaPool { //声明一个连接池对象 var kafkaPool: GenericObjectPool[KafkaProxy] = null // def apply(brokers:String): GenericObjectPool[KafkaProxy] ={ if (kafkaPool == null){ KafkaPool.synchronized{ if (kafkaPool == null){ kafkaPool = new GenericObjectPool[KafkaProxy](new KafkaProxyFactory(brokers)) } } } kafkaPool } }
package com.atlxl.kafkaStreaming import kafka.serializer.StringDecoder import org.apache.kafka.clients.consumer.ConsumerConfig import org.apache.spark.SparkConf import org.apache.spark.streaming.kafka.KafkaUtils import org.apache.spark.streaming.{Seconds, StreamingContext} object KafkaStreaming { def main(args: Array[String]): Unit = { //conf val conf = new SparkConf().setAppName("kafka").setMaster("local[*]") val ssc = new StreamingContext(conf,Seconds(5)) //kafka的参数 val brokers = "hadoop102:9092" val zookeeper = "hadoop102:2181,hadoop103:2181,hadoop104:2181" val sourceTopic = "source" val targetTopic = "target" val consumerGroup = "consumer01" //封装kafka参数 val kafkaParams = Map[String,String]( ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers, ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer", ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer", ConsumerConfig.GROUP_ID_CONFIG -> consumerGroup ) val kafkaDStrem = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc,kafkaParams,Set(sourceTopic)) kafkaDStrem.foreachRDD{rdd => rdd.foreachPartition{rddPar => //创建生产者 val kafkaPool = KafkaPool(brokers) val kafkaConn = kafkaPool.borrowObject() //写出到Kafka(targetTopic) // val value = rddPar.map(x => x._2) for (item <- rddPar){ //生产者发送数据 kafkaConn.send(targetTopic,item._2) } //关闭生产者 kafkaPool.returnObject(kafkaConn) } } /*//测试 val result = kafkaDStrem.map(x => (x._1, x._2)).reduceByKey(_+_) result.print()*/ ssc.start() ssc.awaitTermination() } }