深入理解Raft
根据Raft作者Diego Ongaro的课件整理
论文
按照课件的讲述顺序,理解raft
Server States(状态)
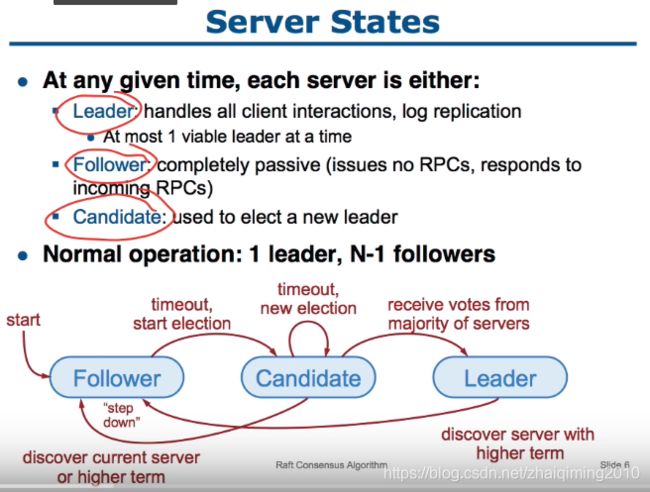
cluster成员的状态有三种:
- Leader:管理与CLient的交互;同一term中最多存在一个Leader
- Follower:接收Leader领导,无法发出请求,只能进行响应
- Candidate:Leader的候选,若选举成功则成为Leader
Term
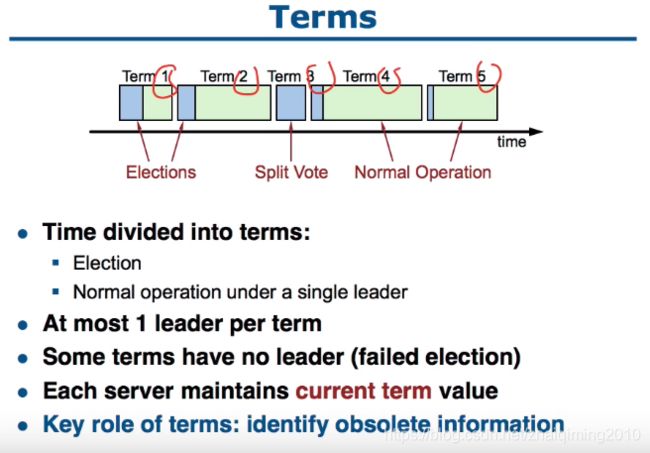
- Term分为选举期与正常工作期
- 一个Term中至多有一个Leader(可以没有 即选举失败了)
- 每个成员都保留Term的值,可以利用其识别过期的信息
Heartbeats and Timeouts

集群的初始状态下所有成员都是Follower,Follower要求每隔一段时间(几百ms左右)都能从Candidate或者Leader获取RPCs。
所以Leader必须每隔一段时间就要发送一个heartbeat(empty AppendEntries RPCs),以保持Leader的地位。
如果一个Follower在Timeout时间内没有接收到RPCs,那么这个Follower会认为Leader已经失效,这个Follower会变成Candidate并启动新一轮选举。
Election Basics

当启动新一轮选举后,首先Term + 1,Follower变为Candidate并投票给自己。然后Candidate会向其他所有的成员发送RequestVote RPC。
如果Candidate接收到大多数成员的投票,那么Candidate变成Leader并向其他所有成员发送AppendEntry heartbeat
如果接收到来自有效Leader的RPC那么Candidate重新变为Follower
如果没有Leader产生则Term+1继续新的一轮
Property :Safety and Liveness

Safety:每个成员只会进行一次投票,投给当前Term中第一次接收到的RequestVote RPC的源,并将投票保存在本地,这就保证了至多只有一个candicate可能得到majority
Liveness:为了防止无休止的选举,每个成员的election timeout时间在[T,2T]之间取随机,以此保证不会所有的follower同时发起选举,这个方法在RequestVote传播的时间远小于T时非常有效。
Log Structure

- Log中保存Term和命令信息,使用index索引
- Log保存在稳定存储设备上,有利于故障恢复
- 如果命令在多数成员上commit那么就认为此命令成功commit,如图中index 1-7
Normal Operation

正常工作的流程:
1.client发送命令给leader
2.leader将命令加入自己的Log并发送AppendEntry RPC给follower
3.如果大多数成员response ok 那么就认为当前命令已经执行成功,Leader会response ok to client,并且会发送appendEntry通知follower在本地commit
- Leader会不断send message to crashed and slow follows
Log Consistency
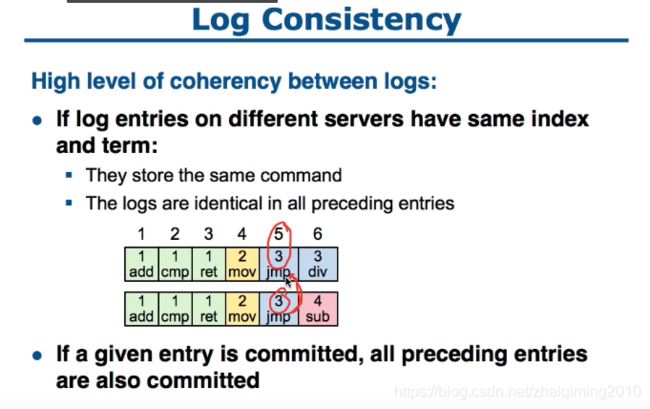
- raft通过唯一的 index和term组合 来唯一确定一条命令
- 不同的机器上在 相同的 index和term组合 之前的Log全部相同
- 当前位置的Log如果已经Commit,那么它前面的Log也已经Commit
AppendEntry Consistency Check

每个AppendEntry RPC中都会保存前一个RPC使用的term和index,这使得一致性检测成为可能。对于Follower,只有当一个AppendEntry RPC保存的前一个term 与 前一个index 都与follow匹配时,follow才接受这个RPC并返回成功响应。
这个特性保证了,只要follow接受AppendEntry RPC了,就说明在Follower中当前位置前面的Log与Leader完全匹配
Leader Changes

在leader变化后,clean up Log不应该立即进行,因为有些机器可能是crash的,如果一直等待恢复 来进行clean up会严重影响性能。clean up 应该放到Normal operation中进行。
在Normal operation中converge log的方法是,假设Leader拥有的Log永远是正确的,所以Leader的工作就是让Follower的Log与Leader的Log能够match
那么在Normal operation中如何实现converge的呢。我们知道只有那些commit的数据是有效的,未commit的数据的情况client是不知道的,所以我们只需要关心commit的数据,具体方法?
Safety Requirement

- Leader曾经commit过的Log必须在之后的所有Leader中出现
要实现这一点可以限制commit或者限制选举?
Pick The Best Leader
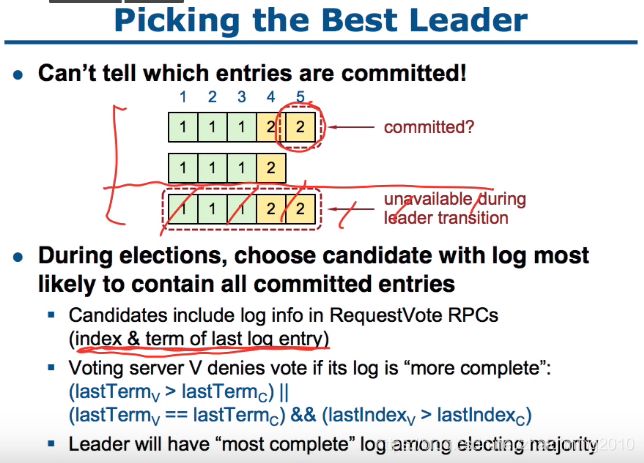
通过在Candidate中选择最完整的“most complete”来保证commit的log都在新leader中
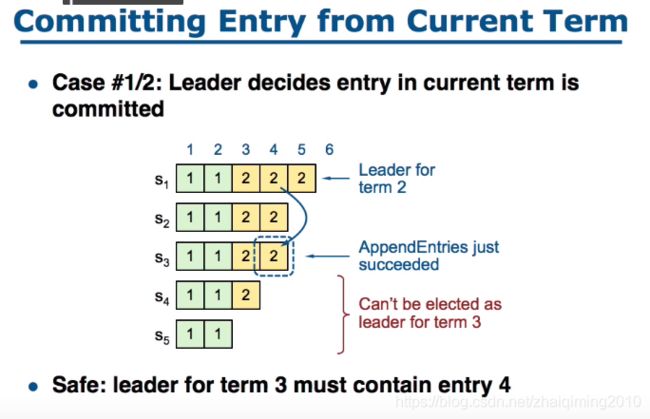
Committing Entry from Current Term
Committing Entry from Earlier Term
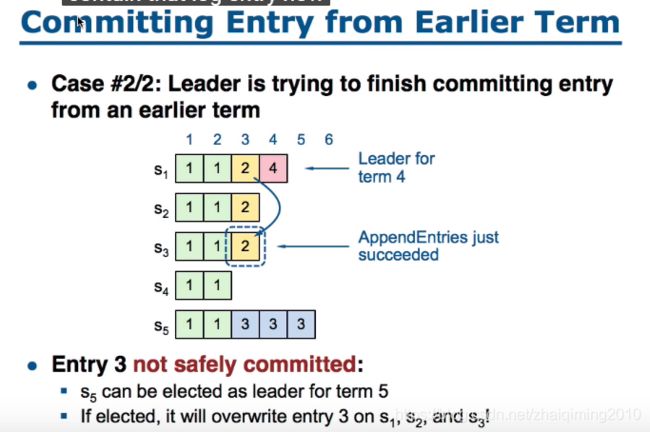
上图中若s5当选,如果按照原来的commit规则,已经commit的黄色的2会丢失。所以我们需要修改commit规则
New rule
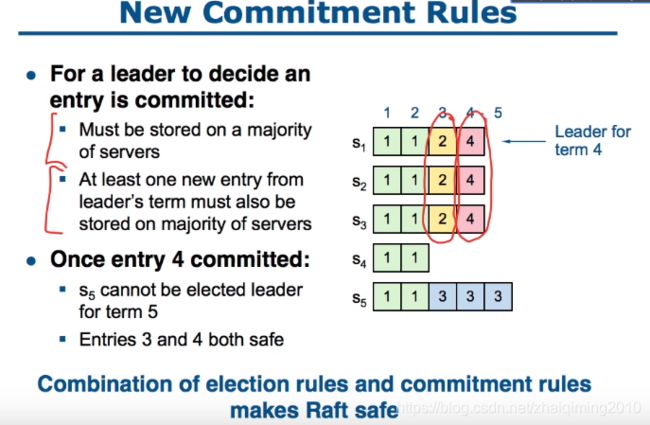
只有在Leader领导的term中出现commit后,以前的term中的log才可以提交commit
Log Inconsistencies

Leader的目的将一直是补上上图中的缺口,删除extra的部分,即Repair?
Repair Follower Logs
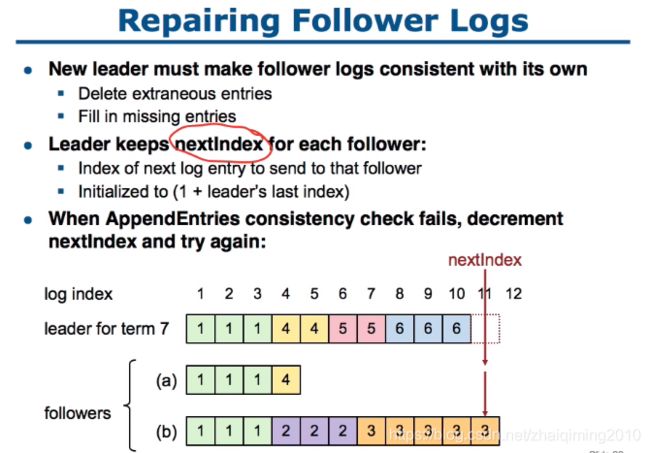
一开始设置相同的nextIndex,如果失败就-1,然后继续匹配,直到寻找到合适的nextIndex,然后按照每个成员特有的nextIndex发送appendEntry RPC
!

一旦某个位置重写,那么当前位置后的就全部删除
Neutralize Old Leader

对于old leader的处理?
与client的交互


系统配置相关

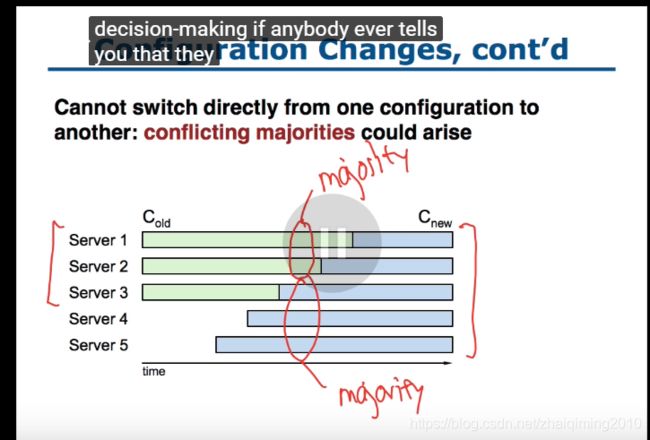
?更新配置时的延迟导致出现不同的majority
所以需要用2-phase解决
distributed decision 需要2-phase解决
使用2-phase
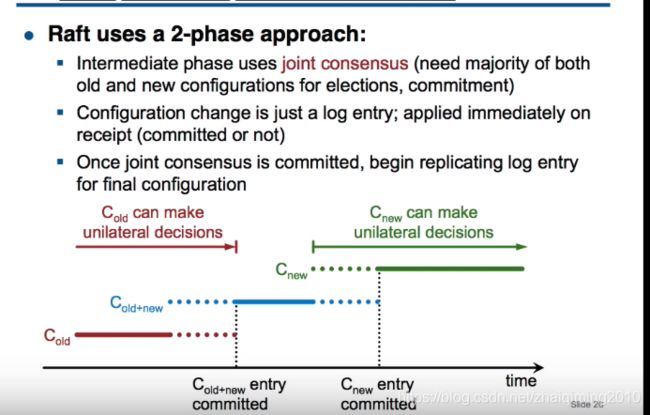
raft将第一个阶段作为中间阶段叫做:joint consensus,在这个阶段old configuration 和 new configuration都使用,commit和election必需分别在old cluster和new cluster 中都获得majority
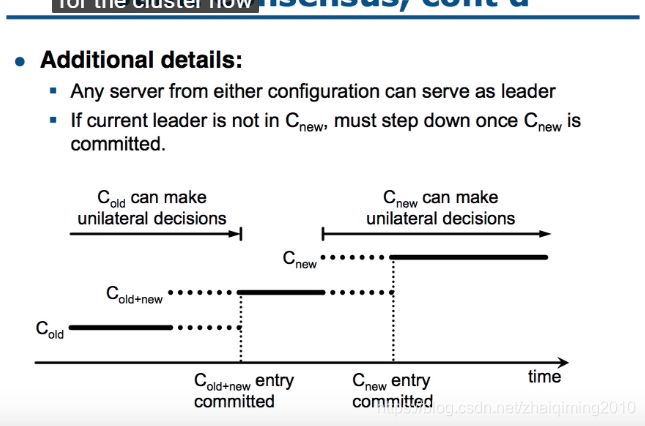
end!