MapReduce相关面试问题整理
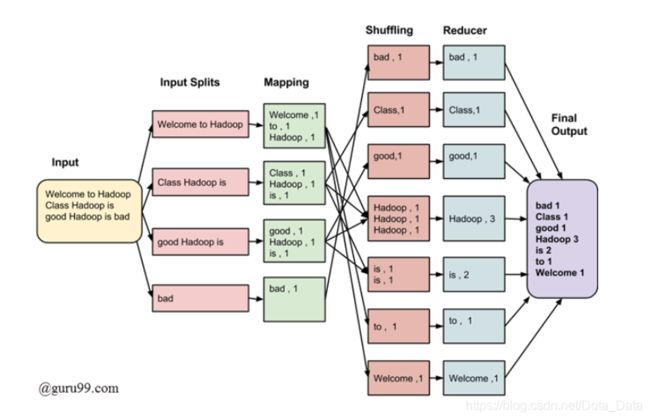
1. 以Word Count为例, 描述下MapReduce的执行过程.
Map阶段, 将每行的数据经过切分后, 得到
Reduce阶段, 经过Shuffle整合Mapping阶段输出的相关记录, 汇总整合Shuffle阶段的值并返回单个输出.
2. 对于MapReduce的各个阶段你觉得有什么优化空间?
数据输入
默认情况下TextInputFormat对任务的切片是按文件切, 无论文件大小, 都会给一个单独的切片, 交给一个maptask, 这时如果输入的是大量小文件, 就会产生大量的maptask, 处理效率极低.
最好的解决方法就是在预处理阶段将小文件合并, 再上传到HDFS处理分析.
但如果已经上传到HDFS了, 就可以用另一种切片方法来补救, CombineTextInputFormat, 它的切片逻辑和TextInputFormat不同, 可以将多个小文件从逻辑上规划到一个切片中, 然后把这些小文件交给一个maptask.
运行时间
启动一个MapReduce任务, map阶段和reduce阶段都会有并行的task共同处理任务, 这些task都需要开启JVM, 然后初始化, 而这些JVM任务是很花费空间的, 如果运行一个20-30s的任务需要进行开启, 初始化, 停止JVM操作很是浪费. 所以我们应该尽量把数据量控制在能让每个task运行1分钟以上.
数据倾斜
可以通过对原始数据进行抽样得到的结果集来预设分区
3. MapReduce 怎么实现 TopN?
可以自定义GroupingComparator,对结果进行最大值排序,然后再reduce输出时,控制只输出前n个数。就达到了TopN输出的目的。
4. 如何使用MapReduce实现两表的join?
1)reduce side join : 在map阶段,map函数同时读取两个文件File1和File2,为了区分两种来源的key/value数据对,对每条数据打一个标签(tag),比如:tag=0 表示来自文件File1,tag=2 表示来自文件File2。
2)map side join : Map side join 是针对以下场景进行的优化:两个待连接表中,有一个表非常大,而另一个表非常小,以至于小表可以直接存放到内存中。这样,我们可以将小表复制多份,让每个map task 内存中存在一份(比如存放到hash table 中),然后只扫描大表:对于大表中的每一条记录key/value,在hash table 中查找是否有相同的key 的记录,如果有,则连接后输出即可。
5. MapReduce中是如何定义并行度的?
一个job的map阶段并行度由客户端提交的job决定。
客户端对map阶段并行度的规划逻辑为:
将待处理数据执行逻辑切片。按照一个特定切片的大小,将待处理的数据划分成逻辑上的多个split,然后每一个split分配一个maptask实例,并进行处理。
reducetask 并行度同样影响整个 job 的执行并发度和执行效率,与maptask的并发数由切片数决定不同,Reducetask 数量的决定是可以直接手动设置:
job.setNumReduceTasks(4);
6. MapReduce中的切片机制
FileInputFormat默认的切片机制是:
- 按照文件内容长度进行切片
- 切片大小默认等于block大小
- 切片针对每个文件单独切片, 比如一个文件300M, 一个10M, 300M的默认会切成0-128, 128-256, 256-300三片, 而10M的文件只会切成0-10一片.
计算切片大小的逻辑是:
Math.max(minSize,Math.min(maxSize,blockSize))
7. MapReduce的Shuffle机制
https://blog.csdn.net/Dota_Data/article/details/91950966