一、Nginx架构
Nginx由内核和模块组成,从官方文档http://nginx.org/en/docs/下的Modules reference可以看到一些比较重要的模块,一般分为核心、基础模块以及第三方模块。
第三方模块意味着你也可以按照nginx标准去开发符合自己业务的模块插件。
核心主要用于提供Web Server的基本功能,以及Web和Mail反向代理的功能;还用于启用网络协议,创建必要的运行时环境以及确保不同的模块之间平滑地进行交互。
不过,大多跟协议相关的功能和某应用特有的功能都是由nginx的模块实现的。这些功能模块大致可以分为:事件模块、阶段性处理器、输出过滤器、变量处理器、协议、upstream和负载均衡几个类别,这些共同组成了nginx的http功能。事件模块主要用于提供OS独立的(不同操作系统的事件机制有所不同)事件通知机制如kqueue或epoll等。协议模块则负责实现nginx通过http、tls/ssl、smtp、pop3以及imap与对应的客户端建立会话。在Nginx内部,进程间的通信是通过模块的pipeline或chain实现的;换句话说,每一个功能或操作都由一个模块来实现。例如,压缩、通过FastCGI或uwsgi协议与upstream服务器通信,以及与memcached建立会话等。
二、nginx进程模型
2.1 多进程模型
Nginx之所以为广大码农喜爱,除了其高性能外,还有其优雅的系统架构。与Memcached的经典多线程模型相比,Nginx是经典的多进程模型。Nginx启动后以daemon的方式在后台运行,后台进程包含一个master进程和多个worker进程,具体如下图:
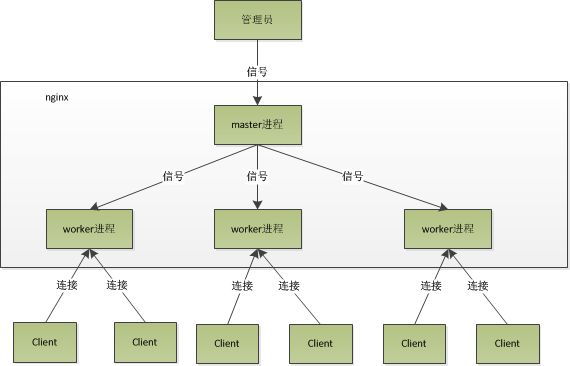
2.2 多进程模型的好处
对于每个worker进程来说,独立的进程,不需要加锁,所以省掉了锁带来的开销,同时在编程以及问题查找时,也会方便很多。其次,采用独立的进程,可以让互相之间不会影响,一个进程退出后,其它进程还在工作,服务不会中断,master进程则很快启动新的worker进程,并且独立的进程,可以让互相之间不会影响,一个进程退出后,其它进程还在,以上也是Nginx高效的另一个原因了。
2.3 master与worker功能
2.3.1 master进程主要用来管理worker进程,具体包括如下4个主要功能:
- 接收来自外界的信号。
- 向各worker进程发送信号。
- 监控woker进程的运行状态。
- 当woker进程退出后(异常情况下),会自动重新启动新的woker进程。
2.3.2 woker进程主要用来处理基本的网络事件:
- 多个worker进程之间是对等且相互独立的,他们同等竞争来自客户端的请求。
- 一个请求,只可能在一个worker进程中处理,一个worker进程,不可能处理其它进程的请求。
- worker进程的个数是可以设置的,一般我们会设置与机器cpu核数一致。更多的worker数,只会导致进程来竞争cpu资源了,从而带来不必要的上下文切换。而且,nginx为了更好的利用多核特性,具有cpu绑定选项,我们可以将某一个进程绑定在某一个核上,这样就不会因为进程的切换带来cache的失效。
三、进程控制方式
对Nginx进程的控制主要是通过master进程来做到的,主要有两种方式:
3.1 手动发送信号
从图1可以看出,master接收信号以管理众woker进程,那么,可以通过kill向master进程发送信号,比如kill -HUP pid用以通知Nginx从容重启。所谓从容重启就是不中断服务:master进程在接收到信号后,会先重新加载配置,然后再启动新进程开始接收新请求,并向所有老进程发送信号告知不再接收新请求并在处理完所有未处理完的请求后自动退出。
3.2 自动发送信号
可以通过带命令行参数启动新进程来发送信号给master进程,比如./nginx -s reload用以启动一个新的Nginx进程,而新进程在解析到reload参数后会向master进程发送信号(新进程会帮我们把手动发送信号中的动作自动完成)。当然也可以这样./nginx -s stop来停止Nginx。
四、守护线程 daemon
4.1 守护线程
nginx在启动后,在unix系统中会以daemon的方式在后台运行,后台进程包含一个master进程和多个worker进程。当然nginx也是支持多线程的方式的,只是我们主流的方式还是多进程的方式,也是nginx的默认方式。
五、网络事件模块
Nginx(多进程)采用异步非阻塞的方式来处理网络事件,类似于Libevent(单进程单线程),具体过程如下图:
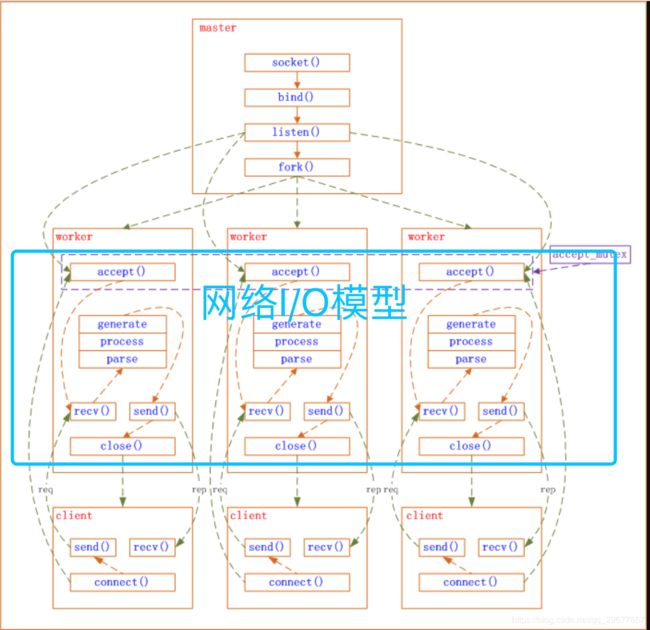
master进程先建好需要listen的socket后,然后再fork出多个woker进程,这样每个work进程都可以去accept这个socket。当一个client连接到来时,所有accept的work进程都会受到通知,但只有一个进程可以accept成功,其它的则会accept失败。Nginx提供了一把共享锁accept_mutex来保证同一时刻只有一个work进程在accept连接,从而解决惊群问题。当一个worker进程accept这个连接后,就开始读取请求,解析请求,处理请求,产生数据后,再返回给客户端,最后才断开连接,这样一个完成的请求就结束了。
对于一个基本的web服务器来说,事件通常有三种类型,网络事件、信号、定时器。从上面的讲解中知道,网络事件通过异步非阻塞可以很好的解决掉。如何处理信号与定时器?
- 信号的处理。(待补充)
- 定时器。nginx里面的定时器事件是放在一颗维护定时器的红黑树里面,每次在进入epoll_wait前,先从该红黑树里面拿到所有定时器事件的最小时间,在计算出epoll_wait的超时时间后进入epoll_wait。(待补充)
六、惊群现象
6.1 什么事惊群现象
惊群简单来说就是多个进程或者线程在等待同一个事件,当事件发生时,所有线程和进程都会被内核唤醒。唤醒后通常只有一个进程获得了该事件并进行处理,其他进程发现获取事件失败后又继续进入了等待状态,在一定程度上降低了系统性能。具体来说惊群通常发生在服务器的监听等待调用上,服务器创建监听socket,后fork多个进程,在每个进程中调用accept或者epoll_wait等待终端的连接。
6.2 nginx的惊群现象
每个worker进程都是从master进程fork过来。在master进程里面,先建立好需要listen的socket之 后,然后再fork出多个worker进程,这样每个worker进程都可以去accept这个socket(当然不是同一个socket,只是每个进程 的这个socket会监控在同一个ip地址与端口,这个在网络协议里面是允许的)。一般来说,当一个连接进来后,所有在accept在这个socket上 面的进程,都会收到通知,而只有一个进程可以accept这个连接,其它的则accept失败。
6.3 nginx如何处理惊群
内核解决epoll的惊群效应是比较晚的,因此nginx自身解决了该问题(更准确的说是避免了)。其具体思路是:不让多个进程在同一时间监听接受连接的socket,而是让每个进程轮流监听,这样当有连接过来的时候,就只有一个进程在监听那肯定就没有惊群的问题。具体做法是:利用一把进程间锁,每个进程中都尝试获得这把锁,如果获取成功将监听socket加入wait集合中,并设置超时等待连接到来,没有获得所的进程则将监听socket从wait集合去除。这里只是简单讨论nginx在处理惊群问题基本做法,实际其代码还处理了很多细节问题,例如简单的连接的负载均衡、定时事件处理等等。
核心的代码如下
void ngx_process_events_and_timers(ngx_cycle_t *cycle){
...
//这里面会对监听socket处理
//1、获得锁则加入wait集合,没有获得则去除
if (ngx_trylock_accept_mutex(cycle) == NGX_ERROR) {
return;
}
...
//设置网络读写事件延迟处理标志,即在释放锁后处理
if (ngx_accept_mutex_held) {
flags |= NGX_POST_EVENTS;
}
...
//这里面epollwait等待网络事件
//网络连接事件,放入ngx_posted_accept_events队列
//网络读写事件,放入ngx_posted_events队列
(void) ngx_process_events(cycle, timer, flags);
...
//先处理网络连接事件,只有获取到锁,这里才会有连接事件
ngx_event_process_posted(cycle, &ngx_posted_accept_events);
//释放锁,让其他进程也能够拿到
if (ngx_accept_mutex_held) {
ngx_shmtx_unlock(&ngx_accept_mutex);
}
//处理网络读写事件
ngx_event_process_posted(cycle, &ngx_posted_events);
}
七、相对于线程,采用进程的优点
- 进程之间不共享资源,不需要加锁,所以省掉了锁带来的开销。
- 采用独立的进程,可以让互相之间不会影响,一个进程退出后,其它进程还在工作,服务不会中断,master进程则很快重新启动新的worker进程。
- 编程上更加容易。
八、多线程的问题
而多线程在多并发情况下,线程的内存占用大,线程上下文切换造成CPU大量的开销。想想apache的常用工作方式(apache 也有异步非阻塞版本,但因其与自带某些模块冲突,所以不常用),每个请求会独占一个工作线程,当并发数上到几千时,就同时有几千的线程在处理请求了。这对 操作系统来说,是个不小的挑战,线程带来的内存占用非常大,线程的上下文切换带来的cpu开销很大,自然性能就上不去了,而这些开销完全是没有意义的。
九、异步非阻塞
9.1. 什么是异步?
异步的概念和同步相对的,也就是不是事件之间不是同时发生的。
9.2 什么事阻塞非阻塞?
非阻塞的概念是和阻塞对应的,阻塞是事件按顺序执行,每一事件都要等待上一事件的完成,而非阻塞是如果事件没有准备好,这个事件可以直接返回,过一段时间再进行处理询问,这期间可以做其他事情。但是,多次询问也会带来额外的开销。
9.3 Nginx采用异步非阻塞的好处?
- 不需要创建线程,每个请求只占用少量的内存
- 没有上下文切换,事件处理非常轻量
淘宝tengine团队说测试结果是“24G内存机器上,处理并发请求可达200万”。
十、libevent 概览
支持Libevent运转的就是一个大循环,这个主循环体现在event_base_loop(Event.c/1533)函数里,该函数的执行流程如下:
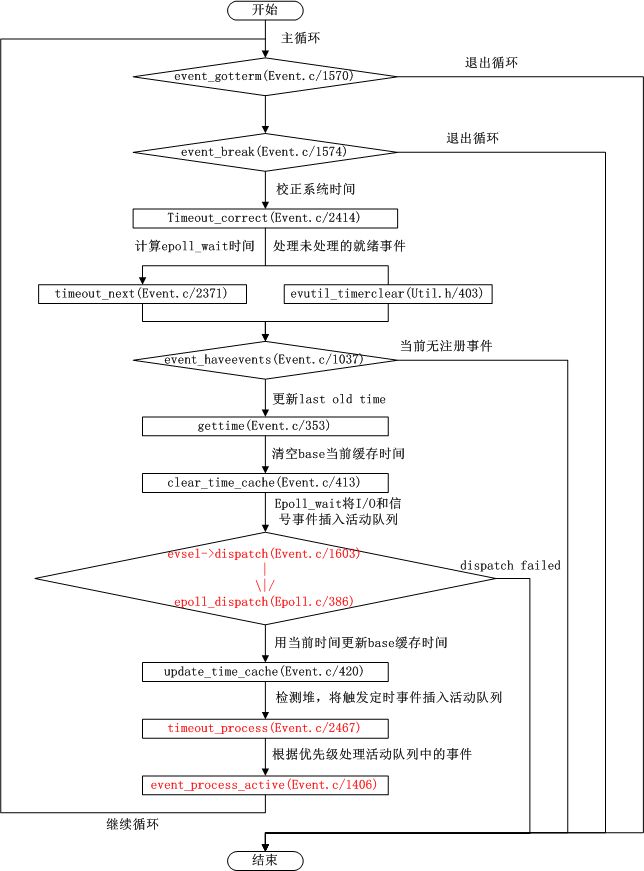
上图的简单描述就是:
- 校正系统当前时间。
- 将当前时间与存放时间的最小堆中的时间依次进行比较,将所有时间小于当前时间的定时器事件从堆中取出来加入到活动事件队列中。
- 调用I/O封装(比如:Epoll)的事件分发函数dispatch函数,以当前时间与时间堆中的最小值之间的差值(最小堆取最小值复杂度为O(1))作为Epoll/epoll_wait(Epoll.c/dispatch/407)的timeout值,在其中将触发的I/O和信号事件加入到活动事件队列中。
- 调用函数event_process_active(Event.c/1406)遍历活动事件队列,依次调用注册的回调函数处理相应事件。
附上event_base_loop源码如下:
int event_base_loop(struct event_base *base, int flags)
{
const struct eventop *evsel = base->evsel;
struct timeval tv;
struct timeval *tv_p;
int res, done, retval = 0;
/* Grab the lock. We will release it inside evsel.dispatch, and again
* as we invoke user callbacks. */
EVBASE_ACQUIRE_LOCK(base, th_base_lock);
if (base->running_loop) {
event_warnx("%s: reentrant invocation. Only one event_base_loop"
" can run on each event_base at once.", __func__);
EVBASE_RELEASE_LOCK(base, th_base_lock);
return -1;
}
base->running_loop = 1;
clear_time_cache(base);
if (base->sig.ev_signal_added && base->sig.ev_n_signals_added)
evsig_set_base(base);
done = 0;
#ifndef _EVENT_DISABLE_THREAD_SUPPORT
base->th_owner_id = EVTHREAD_GET_ID();
#endif
base->event_gotterm = base->event_break = 0;
while (!done) {
base->event_continue = 0;
/* Terminate the loop if we have been asked to */
if (base->event_gotterm) {
break;
}
if (base->event_break) {
break;
}
timeout_correct(base, &tv);
tv_p = &tv;
if (!N_ACTIVE_CALLBACKS(base) && !(flags & EVLOOP_NONBLOCK)) {
timeout_next(base, &tv_p);
} else {
/*
* if we have active events, we just poll new events
* without waiting.
*/
evutil_timerclear(&tv);
}
/* If we have no events, we just exit */
if (!event_haveevents(base) && !N_ACTIVE_CALLBACKS(base)) {
event_debug(("%s: no events registered.", __func__));
retval = 1;
goto done;
}
/* update last old time */
gettime(base, &base->event_tv);
clear_time_cache(base);
res = evsel->dispatch(base, tv_p);
if (res == -1) {
event_debug(("%s: dispatch returned unsuccessfully.",
__func__));
retval = -1;
goto done;
}
update_time_cache(base);
timeout_process(base);
if (N_ACTIVE_CALLBACKS(base)) {
int n = event_process_active(base);
if ((flags & EVLOOP_ONCE)
&& N_ACTIVE_CALLBACKS(base) == 0
&& n != 0)
done = 1;
} else if (flags & EVLOOP_NONBLOCK)
done = 1;
}
event_debug(("%s: asked to terminate loop.", __func__));
done:
clear_time_cache(base);
base->running_loop = 0;
EVBASE_RELEASE_LOCK(base, th_base_lock);
return (retval);
}
写在最后
点关注,不迷路;持续更新!!!!