Basic Paxos算法
背景
Paxos算法是Lamport于1990年提出的一种基于消息传递的一致性算法。由于算法难以理解起初并没有引起人们的重视,使Lamport在八年后重新发表到TOCS上。即便如此paxos算法还是没有得到重视,2001年Lamport用可读性比较强的叙述性语言给出算法描述。可见Lamport对paxos算法情有独钟。近几年paxos算法的普遍使用也证明它在分布式一致性算法中的重要地位。06年google的三篇论文初现“云”的端倪,其中的chubby锁服务使用paxos作为chubby cell中的一致性算法,paxos的人气从此一路狂飙。
Paxos是什么
Paxos 算法解决的问题是一个分布式系统如何就某个值(决议)达成一致。一个典型的场景是,在一个分布式数据库系统中,如果各节点的初始状态一致,每个节点都执行相同的操作序列,那么他们最后能得到一个一致的状态。为保证每个节点执行相同的命令序列,需要在每一条指令上执行一个“一致性算法”以保证每个节点看到的指令一致,是分布式计算中的重要问题。
Paxos的两个原则
安全原则---保证不能做错的事
1.只能有一个值被批准,不能出现第二个值把第一个覆盖的情况
2.每个节点只能学习到已经被批准的值,不能学习没有被批准的值
存活原则---只要有多数服务器存活并且彼此间可以通信最终都要做到的事
1.最终会批准某个被提议的值
2.一个值被批准了,其他服务器最终会学习到这个值
Paxos的两个组件
Proposer
提议发起者,处理客户端请求,将客户端的请求发送到集群中,以便决定这个值是否可以被批准。
Acceptor
提议批准者,负责处理接收到的提议,他们的回复就是一次投票。会存储一些状态来决定是否接收一个值
Paxos定义
接下来用举例的方式一步一步解释Paxos为了完成一致性,必须要解决的一些问题。这里为了方便解释,假设每一台服务器都是一个Proposer,也是一个Acceptor
一个Acceptor
首先从最简单的方式开始,假设只有一个Acceptor,让它做决定是否批准一个值:
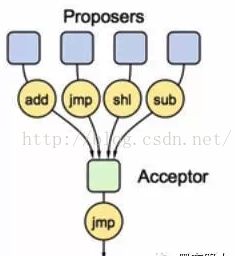
如上图,每一个proposer提议一个值给Acceptor来批准,然后Acceptor批准一个值作为最终的值。
但是这种简单的方式,没有办法解决Acceptor crash的问题,如果唯一的Acceptor crash了,就没有办法知道哪个值被选择了,就需要等待它重启,这一条违反了存活原则,这个时候有4台服务器存活,但已经没有办法工作了。
多个Acceptor
为了解决这个问题,就必须要用到一种多数选择的方法。使用一个Acceptor的集合。然后只有其中的多数批准了一个值,这个值才可以确实是被最终被批准的。为了达到目的也需要一些技巧。
批准第一个达到的值
首先规定每个Acceptor必须批准第一个到达的值。哪个值达到多数批准就是最终批准的值
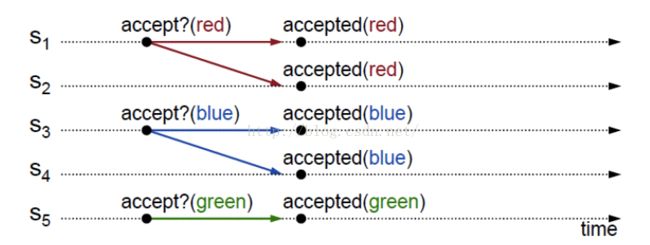
但是有一个问题,比如上图,因为没有值被多数批准,无法批准一个最终的值出来。这就需要Acceptor批准了一个值之后还要根据某种规则批准不同的值
批准每个提议的值
接下来规定Acceptor批准每个提议的值,但是这也会带来一个问题,可能会批准出多个值
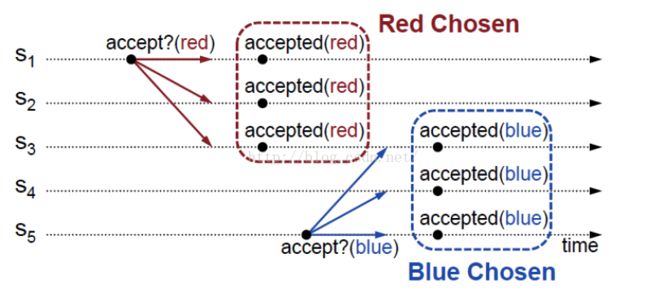
如图,S1发出提议,S1,S2,S3批准red为最终批准的值。S5随后发出提议,s3,S4,S5批准,blue又为最终批准的值。此时S1,S2最终批准red,S3,S4,S5最终批准blue,这就违背了我们的一致性原则,最终只有一个值被选择。
二段提交原则
要解决这个问题,就要S5在发送自己的提议之前,优先检查有没有已经被批准的值,如果有应该提议已经被批准的值而放弃自己的值,也就是放弃自己的blue改为提议red,这样最终只有一个值被批准就是red。这个就是经典的二段提交原则。
不幸的是,二段提交还是存在另一个问题。
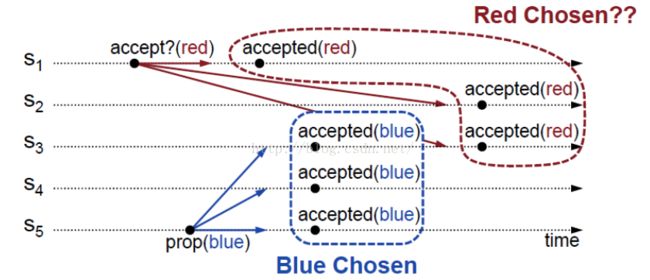
如图,S1在发送提议之前,检查没有值被批准,因此提议red。但同时在所有Acceptor批准之前,S5也要进行提议,这个时候也检查出没有值被批准,所以它也把自己的blue作为提议发送给acceptor。接下来S5的提议优先到达S3,S4,S5,这些Acceptor先批准了blue,达到多数所以blue最终被批准了。但是随后S1,S2,S3接收到了red进行批准。所以又出现了批准出多个值的问题。
提议排序
这个问题要解决,就需要一旦Acceptor批准了某个值,其他有冲突的值都应该被拒绝。也就是说S3随后到达的red应该被拒绝,为了做到这一点。需要对Proposer进行排序,将排序在前的赋予高优先级,Acceptor批准优先级高的值,拒绝排序在后的值。
为了将提议进行排序,可以为每个提议赋予一个唯一的ID,规定这个ID越大,优先级越高
在提议者发送提议之前,就需要生成一个唯一的ID,而且需要比之前使用的或者生成的都要大
提议ID生成算法
在Google的Chubby论文中给出了这样一种方法:假设有n个proposer,每个编号为ir(0<=ir
proposer已知的最大值来自两部分:proposer自己对编号自增后的值和接收到acceptor的reject后所得到的值
以3个proposer P1、P2、P3为例,开始m=0,编号分别为0,1,2
1.P1提交的时候发现了P2已经提交,P2编号为1 > P1的0,因此P1重新计算编号:new P1 = 1*3+0 = 4
2.P3以编号2提交,发现小于P1的4,因此P3重新编号:new P3 = 1*3+2 = 5
Paxos算法
到此阶段,要保证Paxos的两个原则已经都满足了,Paxos也就顺利的实现了。
二段提交
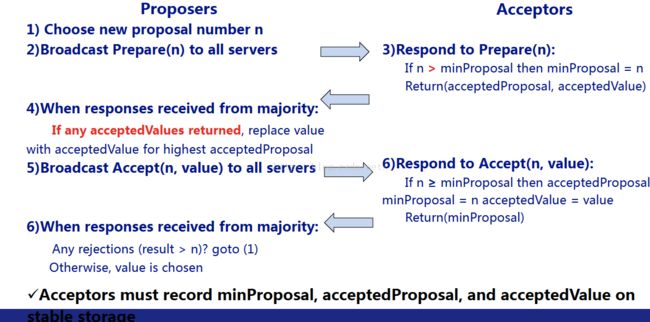
prepare 阶段:
1.Proposer 选择一个提案编号 n 并将 prepare 请求发送给 Acceptors 中的一个多数派;
2.Acceptor 收到 prepare 消息后,如果提案的编号大于它已经回复的所有 prepare 消息,则 Acceptor 将自己上次接受的提案回复给 Proposer,并承诺不再回复小于 n 的提案;
acceptor阶段:
1.当一个 Proposer 收到了多数 Acceptors 对 prepare 的回复后,就进入批准阶段。它要向回复 prepare 请求的 Acceptors 发送 accept 请求,包括编号 n 和根据 prepare阶段 决定的 value(如果根据 prepare 没有已经接受的 value,那么它可以自由决定 value)。
2.在不违背自己向其他 Proposer 的承诺的前提下,Acceptor 收到 accept 请求后即接受这个请求。
prepare阶段有两个目的,第一检查是否有被批准的值,如果有,就改用批准的值。第二如果之前的提议还没有被批准,则阻塞掉他们以便不让他们和我们发生竞争,当然最终由提议ID的大小决定。整个过程如下图: